Xiyou Linux Group 2017,2018,2019面试题
西邮Linux2017纳新题
1.
//分析下列程序的输出
int main(int argc, char *argv[])
{
int t = 4;
printf("%lu\n", sizeof(t--));
printf("%lu\n", sizeof("ab c\nt\012\xa1*2"));
return 0;
}
//输出为4 11
分析:
1.sizeof测量的是数据类型的大小 ,而不是输出数据的值
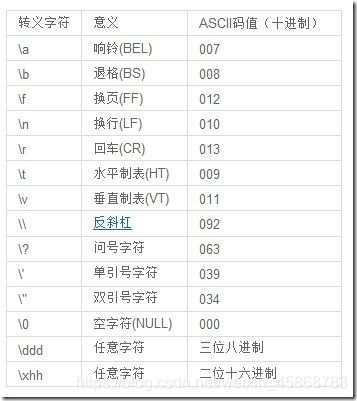
2. \0可以代表字符串的结尾,也可以代表一个八进制数
\x代表十六进制数
3.%lu输出的是无符号长整型 (unsigned long int )
4. 对于任意的三位八进制数,二位十六进制数均占一个字节
所以\012,\xa1,均占一个字节
5.sizeof计算字符串长度时,会加上\0
strlen计算字符串长度是字符串实际的长度
所以在计算字符串长度是strelen(str)+1=sizeof(str)
2.
2. 下面代码会输出什么?
int main(int argc, char *argv[])
{
int a = 10, b = 20, c = 30;
printf("%d %d\n", b = b*c, c = c*2) ;
printf("%d\n", printf("%d ", a+b+c));
return 0;
}
//输出: 1200 60
// 5
总结:
1.printf的返回值是返回所打印的字符的数目,读取从右到左
所以先去计算c=c2,再计算b=bc
2.printf 的嵌套会返回所有的打印字符,包括空格和不可见的换行字符
3.scanf返回成功读入的项目个数,当期望得到一个数字却输入非数字字符,那么scanf的返回值为0
3.
//下面代码使用正确吗?若正确,请说明代码的作用;
//若不正确,请指出错误并修改。
void get_str(char *ptr)
{
ptr = (char*)malloc(17);
strcpy(ptr, "Xiyou Linux Group");
}
int main(int argc, char *argv[])
{
char *str = NULL;
get_str(str);
printf("%s\n", str);
}
//修改后
#include总结:
1.局部变量在调用函数时分配内存,出函数内存释放
2.若手动分配内存,电脑不会为你释放内存,需要自己手动释放,所以可以跨函数使用
4.
size_t q(size_t b)
{
return b;
}
size_t (*p(char *str))(size_t a)
{
printf("%s\n", str);
return q;
}
int main(int argc, char *argv[])
{
char str[] = "XiyouLinuxGroup";
printf("%lu\n", p(str)(strlen(str)));
return 0;
}
总结:
1.size_t类型 简单理解为unsigned int 就行
2.优先级问题要考虑全面
5.static 全局变量与普通的全局变量有什么区别?
static 局部变量和普通局部变量有什么区别? static
函数与普通函数有什么区别?
static局部变量属于静态存储区,作用域为所存在的函数
普通局部变量属于自动存储期,作用域为所存在的代码块
静态存储期的变量在程序执行期间一直占用内存
当使用多文件执行c程序时,static 函数只能在所存在的文件中使用
6
int main(int argc, char *argv[])
{
int a[][2] = {0, 0, 0, 0, 0, 0, 0, 0};
for(int i = 0; i <= 2; i++)
{
printf("%d\n", a[i][i]);
}
return 0;
}
//输出的是1 4 7 位上的0
总结:
1.数组在进行读取是并不是我们所想的去找行列,数据是在内存条中是线性存放,也是线性读取。
2.自我认为二维数组读取方式:定义一个二维数组 int a[3][4]
因为一维有三个int型,跨越整个一维需要34B
二维有四个int型 ,跨越整个二维需要44B
例如 : 读取a[1][2] 代表拿到a的首地址,给其首地址+1 * 12+2 * 4
即前进了20个字节 得到a[1][2]的地址,读值
3. 按照2中的想法本题中的
| 位置 | 地址 | 含义 |
|---|---|---|
| a[0][0] | a+0 | 第1个元素 |
| a[1][1] | a+1* 2* 4 B+1*4B | 第4个元素 |
| a[2][2] | a+2* 2* 4 B+2*4B | 第7个元素 |
8
说说 #include<> 和 #include" " 有什么区别?为
什么需要使用 #include ?
1、#include<> 包含的是头文件,读取的是编译器中有的头文件
2、#include " " 包含的也是头文件,但该头文件是你自己写的,可以存放在一个c的源文件中
9
9. 说明下面程序的运行结果。
int main(int argc, char *argv[])
{
int a, b = 2, c = 5;
for(a = 1; a < 4; a++)
{
switch(a)
{
b = 99;
case 2:
printf("c is %d\n", c);
break;
default:
printf("a is %d\n", a);
case 1:
printf("b is %d\n", b);
break;
}
}
return 0;
}
输出:b is 2
c is 5
a is 3
b is 2
总结:
1.进入switch语句后,会直接找case语句 ,所以b=99在该题中没用
但如果放在default后面,在进行第3次循环时,会将b的值改为99
因为没有break 会继续执行后面的语句 知道找到break
2.只要switch里有要找的case 机器会跳过所有语句 直接找到该case 知道break
10
//. 下面的代码输出什么 ? 为什么 ?
int main(int argc, char *argv[])
{
unsigned int a = 10;
int b = -20;
if (a + b > 0)
{
printf("a+b = %d\n", a+b);
}
else
{
printf("a = %d b = %d\n", a, b);
}
return 0;
}
//输出 :a+b=-10
总结:
1.在计算a+b中 ,会进行强制类型转换
int ->unsigned int -> long ->unsigned long ->long long -> unsigned long long
-> float -> double ->long double
2.在输出时 因为是按照%d的格式输出,为一般整数的输出形式,所以b仍按-10进行计算
11
// 以下程序运行结果是什么?
int main(int argc, char *argv[])
{
int nums[5] = {2, 4, 6, 8, 10};
int *ptr = (int *)(&nums+1);
printf("%d, %d\n", *(nums+1), *(ptr-1));
return 0;
}
//输出: 4,10
总结:
1.&nums+1 代表的意思是跨越整个数组长度 即在nums地址的基础上+20B 如果nums+1 才代表nums[1]
2. 对于指针的加减每次跨越的长度要看他具体的类型
12
int main(int argc, char *argv[])
{
while(1)
{
fprintf(stdout, "Group ");
fprintf(stderr, "XiyouLinux");
getchar();
}
return 0;
}
总结:
1、stdout(标准输出),输出方式是行缓冲。输出的字符会先存放在缓冲区,等遇到换行或按下回车键时才进行实际的I/O操作。
2、stderr(标准错误),是不带缓冲的,这使得出错信息可以直接尽快地显示出来。
3、若在group后加上\n,输出格式将改变为
group
xiyoulinux
13
int main(int argc, char *argv[])
{
char str[512];
int i;
for (i = 0; i < 512; ++i)
{
str[i] = -1 - i;
}
printf("%lu\n", strlen(str));
return 0;
}
总结:
1、字符型数据占据1B 最大的接受数据为8位二进制 为255
而int为4B,读取时不能全部读取,linux是小端机器,所以只会读取最后的8位二进制
2、读取到255时 ,int型的后9位二进制为1 0000 0000,字符型数据只会读取后8位 所以转义后为‘\0’
3、字符型接收数据时,后面直接跟数字将转化为ascii码表对应的数据
带上 ’ ’ 将接收字符
14
void swap(int *a, int *b)
{
int temp = *a;
*a = *b;
*b = temp;
}
总结:
1.修改为宏函数 ,宏函数不在意数据的类型,可以进行简单的操作
#define swap(a,b){a=a+b;b=a-b;a=a-b;}
2、使用if语句给予参数设置条件
17
//输出结果是什么,原因
struct node
{
char a;
short b;
int c;
};
int main(int argc, char *argv[])
{
struct node s;
memset(&s, 0, sizeof(s));
s.a = 3;
s.b = 5;
s.c = 7;
struct node *pt = &s;
printf("%d\n", *(int*)pt);
printf("%lld\n", *(long long *)pt);
return 0;
}
//结果:5003
70005003
struct node
{
int a;
double b;
int d;
};
//a会占0,1,2,3字节 b占7,8,9,10,11,12,13,14字节 d占 16,17,18,19字节
总结:
1、内存对齐
假设s的首地址为0 ,则a占了0字节,b占2,3字节,c占4,5,6,7字节
结构体变量的每个成员相对于结构体首地址的偏移量都应该是该成员大小于对其基数中较小者的整数倍
结构体变量的总大小为结构体最宽基本类型成员大小与对齐基数中== 较小者==的整数倍
2、内存对齐的原因
* 1.平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
* 2.性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
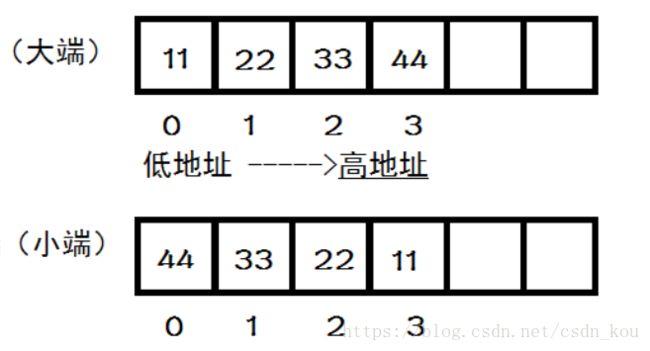
3、大小端
大端: 低位对高地址,高位对低地址
小端:高对高 ,低对低
2018面试题
4.
下面是一个 C 语言程序从源代码到形成可执行文件的过程,请解释图
中的 ABCD 分别表示什么,在每个阶段分别完成了什么工作?

1、预处理就是将要包含(include)的文件插入原文件中、将宏定义展开、根据条件编译命令选择要使用的代码,最后将这些代码输出到一个“.i”文件中等待进一步处理。
2、编译就是把C/C++代码(比如上面的".i"文件)“翻译”成汇编代码。
3、汇编就是将第二步输出的汇编代码翻译成符合一定格式的机器代码,在Linux系统上一般表现位ELF目标文件(OBJ文件)。
4、链接就是将汇编生成的OBJ文件、系统库的OBJ文件、库文件链接起来,最终生成可以在特定平台运行的可执行程序。
8
&: 二进制“与”(都为1时,结果是1,否则是0。)
|: 二进制“或”(有1时,结果是1,都是0时,结果为0。)
int f(unsigned int num)
{
for (unsigned int i = 0; num; i++) {
num &= (num - 1);
}
return i;
}
该程序计算一个数转化为二进制后1的个数
9
int main(int argc, char *argv[])
{
char n[] = { 1, 0, 0, 0 };
printf("%d\n", *(int *)n);
return 0;
}
1、操作系统在访问内存数据时是从低地址向高地址的顺序进行的,所以,对于大端模式就是从高位开始,而对于小端模式则从低位开始。
2、现在的计算机基本都是小端存储,所以最终将1存在了最低位,其他位都是0
3、n先于(int *)结合,进行强制类型转换,又因为n是一个地址,所以进行解引用读值
10
10. 分析以下代码段,解释输出的结果。
#define YEAR 2018
#define LEVELONE(x) "XiyouLinux "#x"\n" #define LEVELTWO(x) LEVELONE(x)
#define MULTIPLY(x,y) x*y
int main(int argc, char *argv[])
{
int x = MULTIPLY(1 + 2, 3);
printf("%d\n", x);
printf(LEVELONE(YEAR));
printf(LEVELTWO(YEAR));
}
1、宏定义里面有个##表示把字符串联在一起。
2、宏定义中的#表示将其变为字符串。
3、使用#把宏参数变为一个字符串,用##把两个宏参数贴合在一起.
4、##是一个连接符号,用于把参数连在一起 例如:
> #define FOO(arg) my##arg 则
> FOO(abc) 相当于 myabc
14
编码题
不使用任何库函数,将字符串转化为整型数。
函数原型:int Convert(const char* num);
例子:char *str = “12345”; int res = Convert(str);
结果:res 应当为 12345。
#include15
- 编码题
输入一个整型数组,实现一个函数来调整该数组中数字的顺序,使
得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。
#include2019面试题
1、
int main(int argc, char *argv[]) {
for (unsigned int i = 3; i >=0; i--)
putchar('=');
}
总结:
1、当i减到-1时,本应退出循环,但是由于i为unsigned int ,将最高位的符号位当做了数据位进行读取,所以会是一个很大的数,再次减到-1又会继续变成一个很大的数,进行无限循环
2
交换数值的三种方法
(1) */ int c = a; a = b ; b = c;
(2) */ a = a - b; b = b + a; a = b - a;
(3) */ a ^= b ; b ^= a ; a ^= b
^位异或运算 同为0异为1
4
1、printf 的嵌套会返回所有的打印字符,包括空格和不可见的换行字符
2、scanf返回成功读入的项目个数,当期望得到一个数字却输入非数字字符,那么scanf的返回值为0
5
& 表示按位与。1&1=1 1&0=0
| 表示按位或 1|1=1 1|0=1
^位异或运算 同为0异为1
11
11.斐波那契数列是这样的一串数列:1,1,2,3,5,8,13,…。在这串数列中,第一项、第二项
为 1,其他项为前两项之和,该数列的第 x 项可以表示为下面的函数。请根据描述,写出一个程
序,使之输入 x 后,能够输出斐波那契数列的第 x 项(其中 x<30)。当你完成之后,你可以尝试
使用递归解决这个问题。
() = {
1, = 1 = 2
( − 1) + ( − 2), ≥ 3
( ∈ +)
#include13
13.请简单叙述两种字节序(大端、小端)的概念,你的机器是什么字节序?试着写一个 C 语言程
序来验证,如果你没有思路,你可以尝试着使用联合体或者指针。
数据从低地址向高地址存储
#include