import pandas as pd
import jieba
import re
from collections import Counter
from itertools import chain
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
import numpy as np
def get_stopword():
stopword = pd.read_csv(r"stopword.txt", header=None, quoting=3, sep="a")
return set(stopword[0].tolist())
def clear(text):
return re.sub("[\s\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", text)
def cut_word(text):
return jieba.cut(text)
def remove_stopword(words):
stopword = get_stopword()
return [word for word in words if word not in stopword]
def preprocess(text):
text = clear(text)
word_iter = cut_word(text)
word_list = remove_stopword(word_iter)
return word_list
def get_word_index_dict(words):
count = Counter(words).most_common(10000 - 2)
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary) + 2
return dictionary
def word2index(li, dic):
return [dic.get(word, 1) for word in li]
data = pd.read_csv(r"movie.csv")
data["label"] = data["label"].map({"pos": 1, "neg": 0})
data["comment"] = data["comment"].apply(lambda text: preprocess(text))
data["comment"].head()
0 [英雄, 自给自足, 超能力, 造就, 酷, 科技, 以人为本, 发展, 硬道理]
1 [男人, 嫌, 女人, 太, 聪明, 是因为, 牛, 逼]
2 [这是, 搞笑, 爱, 臭屁, 喋喋不休, 英雄, 噢, 结尾, 那句, IamIronMa...
3 [没想到, 这侠, 那侠, 要好看, 小时, 片子, 不觉, 长, 紧凑, 爽快, 意犹未尽]
4 [想起, 铁臂, 阿木童]
Name: comment, dtype: object
c = chain.from_iterable(data["comment"].tolist())
words = list(c)
dictionary = get_word_index_dict(words)
data["comment"] = data["comment"].apply(lambda li: word2index(li, dictionary))
data["comment"].head()
0 [4, 689, 194, 732, 315, 22, 1428, 290, 535]
1 [38, 1429, 235, 17, 205, 276, 91, 54]
2 [187, 128, 24, 101, 518, 4, 553, 102, 291, 243...
3 [330, 857, 898, 1310, 270, 21, 2697, 434, 129,...
4 [316, 476, 3177]
Name: comment, dtype: object
X = keras.preprocessing.sequence.pad_sequences(data["comment"],
value=0, padding='post', maxlen=70)
y = data["label"].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(class_weight="balanced")
lr.fit(X_train, y_train)
print(lr.score(X_train, y_train))
print(lr.score(X_test, y_test))
C:\anaconda\envs\tensorflow\lib\site-packages\sklearn\linear_model\logistic.py:433: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
0.5768967288919336
0.5615206781402517
C:\anaconda\envs\tensorflow\lib\site-packages\sklearn\svm\base.py:931: ConvergenceWarning: Liblinear failed to converge, increase the number of iterations.
"the number of iterations.", ConvergenceWarning)
model = keras.Sequential()
model.add(keras.layers.Embedding(10000, 16))
model.add(keras.layers.GlobalAveragePooling1D())
model.add(keras.layers.Dense(16, activation=tf.nn.relu))
model.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))
model.summary()
model.compile(optimizer=tf.train.AdamOptimizer(),
loss='binary_crossentropy', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=100, batch_size=512,
validation_data=(X_test, y_test), verbose=1)
Train on 11678 samples, validate on 3893 samples
WARNING:tensorflow:From C:\anaconda\envs\tensorflow\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Epoch 1/100
11678/11678 [==============================] - 1s 46us/sample - loss: 0.6856 - acc: 0.6305 - val_loss: 0.6729 - val_acc: 0.7460
Epoch 2/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.6623 - acc: 0.7470 - val_loss: 0.6507 - val_acc: 0.7460
Epoch 3/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.6385 - acc: 0.7470 - val_loss: 0.6255 - val_acc: 0.7460
Epoch 4/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.6121 - acc: 0.7470 - val_loss: 0.5993 - val_acc: 0.7460
Epoch 5/100
11678/11678 [==============================] - 0s 24us/sample - loss: 0.5875 - acc: 0.7470 - val_loss: 0.5786 - val_acc: 0.7460
Epoch 6/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.5708 - acc: 0.7470 - val_loss: 0.5683 - val_acc: 0.7460
Epoch 7/100
11678/11678 [==============================] - 0s 24us/sample - loss: 0.5641 - acc: 0.7470 - val_loss: 0.5658 - val_acc: 0.7460
Epoch 8/100
11678/11678 [==============================] - 0s 27us/sample - loss: 0.5624 - acc: 0.7470 - val_loss: 0.5654 - val_acc: 0.7460
Epoch 9/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.5616 - acc: 0.7470 - val_loss: 0.5651 - val_acc: 0.7460
Epoch 10/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.5608 - acc: 0.7470 - val_loss: 0.5648 - val_acc: 0.7460
Epoch 11/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.5601 - acc: 0.7470 - val_loss: 0.5644 - val_acc: 0.7460
Epoch 12/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.5593 - acc: 0.7470 - val_loss: 0.5641 - val_acc: 0.7460
Epoch 13/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.5585 - acc: 0.7470 - val_loss: 0.5637 - val_acc: 0.7460
Epoch 14/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.5575 - acc: 0.7470 - val_loss: 0.5633 - val_acc: 0.7460
Epoch 15/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.5566 - acc: 0.7470 - val_loss: 0.5629 - val_acc: 0.7460
Epoch 16/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.5555 - acc: 0.7470 - val_loss: 0.5624 - val_acc: 0.7460
Epoch 17/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.5543 - acc: 0.7470 - val_loss: 0.5618 - val_acc: 0.7460
Epoch 18/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.5527 - acc: 0.7470 - val_loss: 0.5610 - val_acc: 0.7460
Epoch 19/100
11678/11678 [==============================] - 0s 24us/sample - loss: 0.5503 - acc: 0.7470 - val_loss: 0.5597 - val_acc: 0.7460
Epoch 20/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.5470 - acc: 0.7470 - val_loss: 0.5580 - val_acc: 0.7460
Epoch 21/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.5416 - acc: 0.7470 - val_loss: 0.5554 - val_acc: 0.7460
Epoch 22/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.5347 - acc: 0.7473 - val_loss: 0.5524 - val_acc: 0.7460
Epoch 23/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.5261 - acc: 0.7478 - val_loss: 0.5488 - val_acc: 0.7457
Epoch 24/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.5157 - acc: 0.7489 - val_loss: 0.5450 - val_acc: 0.7460
Epoch 25/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.5040 - acc: 0.7517 - val_loss: 0.5416 - val_acc: 0.7465
Epoch 26/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.4920 - acc: 0.7568 - val_loss: 0.5384 - val_acc: 0.7470
Epoch 27/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.4801 - acc: 0.7637 - val_loss: 0.5352 - val_acc: 0.7475
Epoch 28/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.4673 - acc: 0.7728 - val_loss: 0.5333 - val_acc: 0.7513
Epoch 29/100
11678/11678 [==============================] - 0s 28us/sample - loss: 0.4550 - acc: 0.7803 - val_loss: 0.5319 - val_acc: 0.7547
Epoch 30/100
11678/11678 [==============================] - 0s 24us/sample - loss: 0.4434 - acc: 0.7905 - val_loss: 0.5322 - val_acc: 0.7539
Epoch 31/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.4337 - acc: 0.7932 - val_loss: 0.5340 - val_acc: 0.7547
Epoch 32/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.4221 - acc: 0.8032 - val_loss: 0.5326 - val_acc: 0.7534
Epoch 33/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.4127 - acc: 0.8080 - val_loss: 0.5345 - val_acc: 0.7519
Epoch 34/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.4037 - acc: 0.8167 - val_loss: 0.5366 - val_acc: 0.7513
Epoch 35/100
11678/11678 [==============================] - 0s 22us/sample - loss: 0.3945 - acc: 0.8221 - val_loss: 0.5392 - val_acc: 0.7498
Epoch 36/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.3870 - acc: 0.8302 - val_loss: 0.5453 - val_acc: 0.7542
Epoch 37/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.3786 - acc: 0.8337 - val_loss: 0.5477 - val_acc: 0.7511
Epoch 38/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.3716 - acc: 0.8394 - val_loss: 0.5498 - val_acc: 0.7449
Epoch 39/100
11678/11678 [==============================] - 0s 23us/sample - loss: 0.3642 - acc: 0.8431 - val_loss: 0.5537 - val_acc: 0.7439
Epoch 40/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.3574 - acc: 0.8471 - val_loss: 0.5588 - val_acc: 0.7465
Epoch 41/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.3517 - acc: 0.8495 - val_loss: 0.5648 - val_acc: 0.7465
Epoch 42/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.3451 - acc: 0.8533 - val_loss: 0.5678 - val_acc: 0.7421
Epoch 43/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.3393 - acc: 0.8572 - val_loss: 0.5737 - val_acc: 0.7429
Epoch 44/100
11678/11678 [==============================] - 0s 27us/sample - loss: 0.3334 - acc: 0.8593 - val_loss: 0.5794 - val_acc: 0.7424
Epoch 45/100
11678/11678 [==============================] - 0s 28us/sample - loss: 0.3283 - acc: 0.8605 - val_loss: 0.5852 - val_acc: 0.7411
Epoch 46/100
11678/11678 [==============================] - 0s 27us/sample - loss: 0.3233 - acc: 0.8639 - val_loss: 0.5901 - val_acc: 0.7370
Epoch 47/100
11678/11678 [==============================] - 0s 27us/sample - loss: 0.3188 - acc: 0.8640 - val_loss: 0.5953 - val_acc: 0.7344
Epoch 48/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.3135 - acc: 0.8682 - val_loss: 0.6011 - val_acc: 0.7321
Epoch 49/100
11678/11678 [==============================] - 0s 30us/sample - loss: 0.3091 - acc: 0.8733 - val_loss: 0.6075 - val_acc: 0.7336
Epoch 50/100
11678/11678 [==============================] - 0s 24us/sample - loss: 0.3044 - acc: 0.8739 - val_loss: 0.6139 - val_acc: 0.7316
Epoch 51/100
11678/11678 [==============================] - 0s 27us/sample - loss: 0.3003 - acc: 0.8763 - val_loss: 0.6196 - val_acc: 0.7290
Epoch 52/100
11678/11678 [==============================] - 0s 28us/sample - loss: 0.2973 - acc: 0.8778 - val_loss: 0.6252 - val_acc: 0.7223
Epoch 53/100
11678/11678 [==============================] - 0s 32us/sample - loss: 0.2928 - acc: 0.8808 - val_loss: 0.6345 - val_acc: 0.7316
Epoch 54/100
11678/11678 [==============================] - 0s 30us/sample - loss: 0.2902 - acc: 0.8801 - val_loss: 0.6378 - val_acc: 0.7200
Epoch 55/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.2857 - acc: 0.8821 - val_loss: 0.6450 - val_acc: 0.7218
Epoch 56/100
11678/11678 [==============================] - 0s 33us/sample - loss: 0.2826 - acc: 0.8841 - val_loss: 0.6525 - val_acc: 0.7249
Epoch 57/100
11678/11678 [==============================] - 0s 32us/sample - loss: 0.2796 - acc: 0.8859 - val_loss: 0.6607 - val_acc: 0.7285
Epoch 58/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2759 - acc: 0.8871 - val_loss: 0.6635 - val_acc: 0.7169
Epoch 59/100
11678/11678 [==============================] - 0s 32us/sample - loss: 0.2724 - acc: 0.8888 - val_loss: 0.6706 - val_acc: 0.7190
Epoch 60/100
11678/11678 [==============================] - 0s 28us/sample - loss: 0.2691 - acc: 0.8905 - val_loss: 0.6766 - val_acc: 0.7154
Epoch 61/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2665 - acc: 0.8922 - val_loss: 0.6856 - val_acc: 0.7213
Epoch 62/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2649 - acc: 0.8901 - val_loss: 0.6912 - val_acc: 0.7082
Epoch 63/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2621 - acc: 0.8937 - val_loss: 0.6998 - val_acc: 0.7210
Epoch 64/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.2596 - acc: 0.8948 - val_loss: 0.7032 - val_acc: 0.7180
Epoch 65/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.2562 - acc: 0.8956 - val_loss: 0.7088 - val_acc: 0.7115
Epoch 66/100
11678/11678 [==============================] - 0s 32us/sample - loss: 0.2543 - acc: 0.8977 - val_loss: 0.7199 - val_acc: 0.7195
Epoch 67/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2509 - acc: 0.8963 - val_loss: 0.7245 - val_acc: 0.7180
Epoch 68/100
11678/11678 [==============================] - 0s 24us/sample - loss: 0.2485 - acc: 0.8978 - val_loss: 0.7284 - val_acc: 0.7144
Epoch 69/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2464 - acc: 0.8989 - val_loss: 0.7392 - val_acc: 0.7182
Epoch 70/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.2450 - acc: 0.9005 - val_loss: 0.7417 - val_acc: 0.7090
Epoch 71/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.2419 - acc: 0.9020 - val_loss: 0.7492 - val_acc: 0.7156
Epoch 72/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2400 - acc: 0.9035 - val_loss: 0.7631 - val_acc: 0.7208
Epoch 73/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.2385 - acc: 0.9015 - val_loss: 0.7634 - val_acc: 0.7036
Epoch 74/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.2370 - acc: 0.9044 - val_loss: 0.7696 - val_acc: 0.7156
Epoch 75/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.2341 - acc: 0.9042 - val_loss: 0.7773 - val_acc: 0.7149
Epoch 76/100
11678/11678 [==============================] - 0s 30us/sample - loss: 0.2324 - acc: 0.9054 - val_loss: 0.7814 - val_acc: 0.7102
Epoch 77/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2302 - acc: 0.9073 - val_loss: 0.7898 - val_acc: 0.7151
Epoch 78/100
11678/11678 [==============================] - 0s 31us/sample - loss: 0.2285 - acc: 0.9070 - val_loss: 0.7946 - val_acc: 0.7079
Epoch 79/100
11678/11678 [==============================] - 0s 27us/sample - loss: 0.2270 - acc: 0.9095 - val_loss: 0.8019 - val_acc: 0.7118
Epoch 80/100
11678/11678 [==============================] - 0s 30us/sample - loss: 0.2253 - acc: 0.9094 - val_loss: 0.8113 - val_acc: 0.7154
Epoch 81/100
11678/11678 [==============================] - 0s 27us/sample - loss: 0.2245 - acc: 0.9109 - val_loss: 0.8192 - val_acc: 0.7159
Epoch 82/100
11678/11678 [==============================] - 0s 30us/sample - loss: 0.2215 - acc: 0.9125 - val_loss: 0.8211 - val_acc: 0.7074
Epoch 83/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.2199 - acc: 0.9133 - val_loss: 0.8282 - val_acc: 0.7090
Epoch 84/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2191 - acc: 0.9136 - val_loss: 0.8340 - val_acc: 0.7051
Epoch 85/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2173 - acc: 0.9142 - val_loss: 0.8411 - val_acc: 0.7092
Epoch 86/100
11678/11678 [==============================] - 0s 24us/sample - loss: 0.2148 - acc: 0.9145 - val_loss: 0.8541 - val_acc: 0.7146
Epoch 87/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2137 - acc: 0.9152 - val_loss: 0.8540 - val_acc: 0.7085
Epoch 88/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2135 - acc: 0.9157 - val_loss: 0.8660 - val_acc: 0.7138
Epoch 89/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.2117 - acc: 0.9178 - val_loss: 0.8668 - val_acc: 0.7041
Epoch 90/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2099 - acc: 0.9179 - val_loss: 0.8778 - val_acc: 0.7133
Epoch 91/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.2102 - acc: 0.9176 - val_loss: 0.8854 - val_acc: 0.7136
Epoch 92/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.2074 - acc: 0.9169 - val_loss: 0.8861 - val_acc: 0.7054
Epoch 93/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.2057 - acc: 0.9186 - val_loss: 0.8926 - val_acc: 0.7015
Epoch 94/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.2044 - acc: 0.9194 - val_loss: 0.8999 - val_acc: 0.7085
Epoch 95/100
11678/11678 [==============================] - 0s 25us/sample - loss: 0.2031 - acc: 0.9205 - val_loss: 0.9101 - val_acc: 0.7118
Epoch 96/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.2024 - acc: 0.9201 - val_loss: 0.9120 - val_acc: 0.7028
Epoch 97/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.2010 - acc: 0.9219 - val_loss: 0.9180 - val_acc: 0.7023
Epoch 98/100
11678/11678 [==============================] - 0s 29us/sample - loss: 0.2002 - acc: 0.9234 - val_loss: 0.9249 - val_acc: 0.7033
Epoch 99/100
11678/11678 [==============================] - 0s 28us/sample - loss: 0.1984 - acc: 0.9234 - val_loss: 0.9320 - val_acc: 0.7067
Epoch 100/100
11678/11678 [==============================] - 0s 26us/sample - loss: 0.1977 - acc: 0.9221 - val_loss: 0.9374 - val_acc: 0.7028
t = model.predict(X_test)
t = np.where(t >= 0.5, 1, 0)
print(pd.Series(t.flatten()).value_counts())
1 3177
0 716
dtype: int64
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()

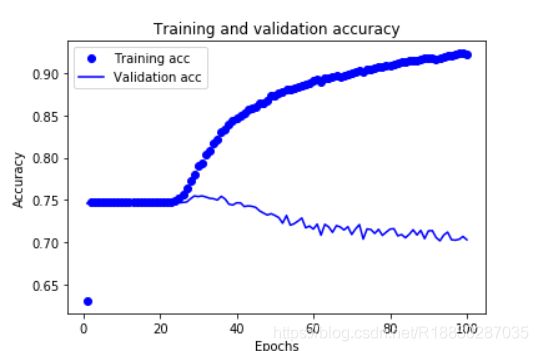
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
x = chain.from_iterable([[1, 2, 3], [4, 5]])
list(x)
[1, 2, 3, 4, 5]