前言
最近刚刚入门深度学习,在B站看的吴恩达老师的Deep Learning教程,五门课看完以后真的手痒痒,于是决定做一个对话机器人练练手,网上相关教程很多,但是能完成一整个工程,又比较容易入门的文章其实不多,之前查了很多篇博客,不想让后人再重复走我的弯路,所以写了这篇文章,希望能帮到各位和我一样刚入门的萌新
参考的文章:
- keras教程:手把手教你做聊天机器人(上)
- keras教程:手把手教你做聊天机器人(下)
- 中文NLP笔记:13 用 Keras 实现一个简易聊天机器人
- 吴恩达深度学习第五课序列模型的编程练习
数据集下载
萌新不知道干啥用的可以参考第一篇文章keras教程:手把手教你做聊天机器人(上)
1.原始数据集 密码: mqu9

data是训练语料,只有100条,数量很少,做出来也就图一乐,真要做成能用的机器人还得几十万条数据
word_vector是训练好的词向量,大家也可以换成自己的
2.我处理过的,已经做好的训练集,可以直接跳过数据预处理阶段直接开始训练
处理好的数据集 分享码:9lyq
开始干活
1.先安装相应拓展
我用的是python 3.6.5+tensorflow1.9.0+keras
- jieba
- gensim
- numpy
- pickle
pickle是自带的还是要下的?我有点忘了
2.对原始文本进行数据处理
新建一个python文件utils.py,该文件专门用于数据处理
import jieba
import re
from gensim.models import word2vec
import os
import numpy as np
定义一个函数generate_segments,该函数使用jieba分词将原始文本进行分词
def generate_segments(input_file,output_file):
data = open(input_file,'rb')
output = open(output_file,'a+',encoding="utf-8")
lines = data.readlines()
for line in lines:
line = line.strip()
seglist = jieba.cut(line)
segments = ''
for word in seglist:
segments = segments + ' ' + word
segments = segments + '\n'
segments = segments.lstrip()
output.write(segments)
data.close()
output.close()
函数写好以后,运行一次,生成分好词的文本文件
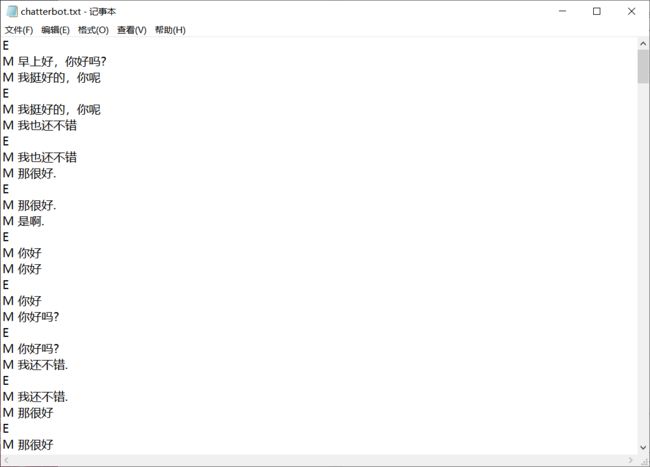
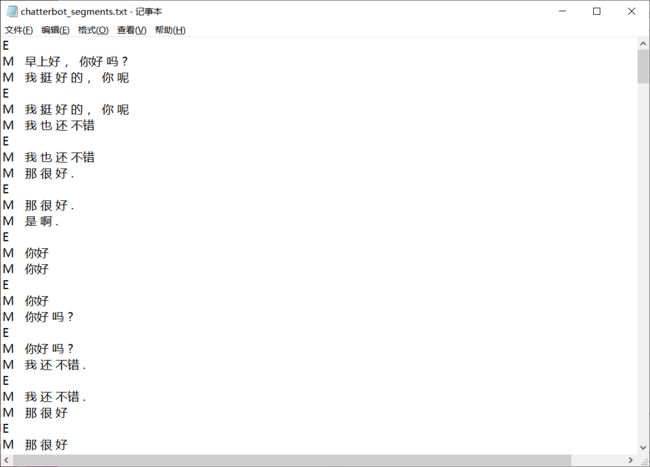
分好词以后,我们需要将原数据里的问句和答句分开,生成输入X和标签Y
def generate_XY(segments_file):
f = open(segments_file,'r',encoding='utf-8')
data = f.read()
X = []
Y = []
conversations = data.split('E')
for q_a in conversations:
if re.findall('.*M.*M.*',q_a,flags=re.DOTALL):
q_a = q_a.strip()
q_a_pair = q_a.split('M')
X.append(q_a_pair[1].strip())
Y.append(q_a_pair[2].strip())
f.close()
return X,Y
获取到X和Y后,我们需要将它们向量化,这就需要之前下载的词向量模型了,转为词向量后,我们还需要将样本的长度进行统一,统一长度为15,在最后插入终止符全1向量,短的句子需要用全1向量补齐,长的句子需要截断
def XY_vector(X,Y):
print("加载词向量模型")
model = word2vec.Word2Vec.load("word_vector/Word60.model")
X_vector = []
Y_vector = []
for sentence in X:
x = sentence.split(" ")
x_vec = [model[w] for w in x if w in model.wv.vocab]
X_vector.append(x_vec)
for sentence in Y:
y = sentence.split(" ")
y_vec = [model[w] for w in y if w in model.wv.vocab]
Y_vector.append(y_vec)
word_dim = len(X_vector[0][0])
end_word = np.ones(shape=(word_dim,))
#将长度统一
for vector in X_vector:
if len(vector) > 14:#大于14的情况
vector[14:] = []
vector.append(end_word)
else:
for i in range(15 - len(vector)):
vector.append(end_word)
for vector in Y_vector:
if len(vector) > 14:#大于14的情况
vector[14:] = []
vector.append(end_word)
else:
for i in range(15 - len(vector)):
vector.append(end_word)
return X_vector,Y_vector
最后还有一步是比较关键的,我们这次使用的是seq2seq结构,在训练decoder时,我们本需要将前一个单元的输出作为后一个单元的输入,但是这么做在训练时容易引起梯度爆炸,所以这次我们直接将答句作为decoder的输入,并且开头输入全零,其他词语延后一个时间步长,理解不了的可以看我的灵魂画图
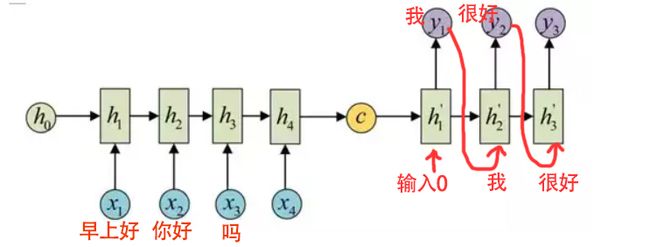
这么做其实也不是最优解,更好的方法是一开始先直接输入答句,到后来再逐渐将输入换为前一个RNN单元的输出,这种方法叫作scheduled sampling,不过由于我还不太熟悉keras,这次就先算了
定义一个函数,根据标签Y,生成用于训练时的decoder_input
def generate_decoder_input(decoder_output):#生成解码器的输入序列,输出序列的第一个词是输入序列的第二个词,输入序列的第一个单词为全零向量
word_dim = len(decoder_output[0][0])
word_start = np.zeros(shape=(word_dim,))#全0
decoder_input = []
if not(decoder_input is decoder_output):
for example in decoder_output:
input_example = example[:14]
input_example.insert(0,word_start)
decoder_input.append(input_example)
return decoder_input
函数全部定义好以后,先生成分词好的文本文件,再生成训练集,保存到data.npz文件中
if __name__ == "__main__":
output_file = "data/chatterbot_segments.txt"
X,Y = generate_XY(output_file)
X_vector,Y_vector = XY_vector(X,Y)
Y_input = generate_decoder_input(Y_vector)
print(Y_vector[0][:2])#测试用
print(Y_input[0][:2])#测试用
np.savez("data",data_X=X_vector,data_input_Y=Y_input,data_output_Y=Y_vector)
3.编写训练模型
新建一个python文件,叫做train.py,先引入要用的模块
import warnings
warnings.filterwarnings('ignore')#用于消除警告的,可以不加
from keras.models import Model
from keras.layers import Input, LSTM, Dense,TimeDistributed
from keras.optimizers import Adam
import numpy as np
import pickle
import utils
然后将处理好的训练集读入,这里你可以用我提供的,也可以自己做
data = np.load("data.npz",allow_pickle=True)
data_X = data["data_X"]
data_input_Y = data["data_input_Y"]
data_output_Y = data["data_output_Y"]#准备数据
m_X = len(data_X)
m_Y = len(data_input_Y)
word_dim = len(data_X[0][0])
word_Tx = len(data_X[0])
print("X的样本数",m_X)
print("X每句话长度",word_Tx)
print("X维数",data_X.shape)
print("Y的样本数",m_Y)
print("Y维数",data_input_Y.shape)
print("Y输出维数",data_output_Y.shape)
print("词向量维数",word_dim)
print("Y输入第一个词",data_input_Y[0][0])
print("Y输出第一个词",data_output_Y[0][0])
模型使用LSTM,先定义编码器(encoder),将问句作为输入,保存编码器的最终状态,再定义解码器(decoder),用编码器的最终状态作为解码器的起始状态,在解码器的输出上再套一层全连接层,将输出映射为词向量长度,注意这里的全连接层激活函数为"linear",不能用tanh,relu,softmax等其他激活函数
hidden_dim = 256#LSTM隐藏层维数
encoder_input = Input(shape=(None,word_dim),name='encoder_input')#输入是维度为行,样本长度为列
encoder = LSTM(hidden_dim,return_state=True,name='encoder')
encoder_output,state_h,state_c = encoder(encoder_input)
encoder_state = [state_h,state_c]
decoder_input = Input(shape=(None,word_dim),name='decoder_input')
decoder = LSTM(hidden_dim,return_sequences=True,return_state=True,name='decoder')
decoder_output,_,_ = decoder(decoder_input,initial_state=encoder_state)
decoder_dense = TimeDistributed(Dense(output_dim=word_dim,activation='linear'),name='densor')
outputs = decoder_dense(decoder_output)
train_model = Model(inputs=[encoder_input,decoder_input],outputs=outputs)
设置一些训练的超参数,注意损失函数用的是mse,不是categorical_crossentropy,因为这不是一个分类问题,训练3000轮,这个值可能有点大,会引起过拟合,建议多试试其他数,训练好的模型保存到硬盘里
opt = Adam(lr=0.005,decay=0.01)
train_model.compile(optimizer=opt, loss='mse', metrics=['accuracy'])
train_model.fit([data_X,data_input_Y],data_output_Y,epochs=3000,batch_size=32)
train_model.save('train_model.h5')
train.py 完整代码
import warnings
warnings.filterwarnings('ignore')#用于消除警告的,可以不加
from keras.models import Model
from keras.layers import Input, LSTM, Dense,TimeDistributed
from keras.optimizers import Adam
import numpy as np
import pickle
import utils
data = np.load("data.npz",allow_pickle=True)
data_X = data["data_X"]
data_input_Y = data["data_input_Y"]
data_output_Y = data["data_output_Y"]#准备数据
m_X = len(data_X)
m_Y = len(data_input_Y)
word_dim = len(data_X[0][0])
word_Tx = len(data_X[0])
print("X的样本数",m_X)
print("X每句话长度",word_Tx)
print("X维数",data_X.shape)
print("Y的样本数",m_Y)
print("Y维数",data_input_Y.shape)
print("Y输出维数",data_output_Y.shape)
print("词向量维数",word_dim)
print("Y输入第一个词",data_input_Y[0][0])
print("Y输出第一个词",data_output_Y[0][0])
hidden_dim = 256#LSTM隐藏层维数
encoder_input = Input(shape=(None,word_dim),name='encoder_input')#输入是维度为行,样本为列
encoder = LSTM(hidden_dim,return_state=True,name='encoder')
encoder_output,state_h,state_c = encoder(encoder_input)
encoder_state = [state_h,state_c]
decoder_input = Input(shape=(None,word_dim),name='decoder_input')
decoder = LSTM(hidden_dim,return_sequences=True,return_state=True,name='decoder')
decoder_output,_,_ = decoder(decoder_input,initial_state=encoder_state)
decoder_dense = TimeDistributed(Dense(output_dim=word_dim,activation='linear'),name='densor')
outputs = decoder_dense(decoder_output)
train_model = Model(inputs=[encoder_input,decoder_input],outputs=outputs)
opt = Adam(lr=0.005,decay=0.01)
train_model.compile(optimizer=opt, loss='mse', metrics=['accuracy'])
train_model.fit([data_X,data_input_Y],data_output_Y,epochs=3000,batch_size=32)
train_model.save('train_model.h5')

最后loss大概0.01,acc大概0.41
4.编写预测模型,并进行预测
新建一个predict.py文件,首先引入模块,并设置好一些参数,载入训练好的模型
import warnings
warnings.filterwarnings('ignore')
from keras.models import Model,load_model
from keras.layers import Input, LSTM, Dense,TimeDistributed
from keras.optimizers import Adam
from gensim.models import word2vec
import numpy as np
import jieba
import pickle
print("加载模型中")
model = load_model("train_model.h5")
word2vec_model = word2vec.Word2Vec.load("word_vector/Word60.model")
Ty = 30#回答的最长长度
hidden_dim = 256
word_dim = 60#超参数设置
虽然预测模型使用的还是之前训练模型里的结构,但是在预测时,我们会将decoder前一个单元的输出作为下一个decoder单元的输入,所以还需要重新定义一下网络。在这个模型里,我们使用for循环将前一单元的输出作为下一个单元的输入,并把每个单元的输出放进一个list里
def predict_model(encoder_layer,decoder_layer,time_densor,word_dim,Ty):
X0 = Input(shape=(None,word_dim),name="sentence_input")
_,state_h,state_c = encoder_layer(X0)#获得编码器最终状态
decoder_states_inputs = [state_h, state_c]
decoder_input = Input(shape=(1,word_dim),name='decoder_initial_input')
X = decoder_input
outputs = []
for i in range(Ty):
decoder_output,h,c = decoder_layer(X,initial_state=decoder_states_inputs)
output = time_densor(decoder_output)
decoder_states_inputs = [h,c]
X = output
outputs.append(output)
model = Model(input=[X0,decoder_input],outputs=outputs)
return model
这个函数需要接收模型的encoder_layer,decoder_layer,time_densor后面会说到怎么获取这几个实例
定义两个函数,一个用于将人输入的问句向量化,另一个将机器输出的序列转换为文字
1.输入向量化
def input_sentence_vector(sentence,word2vec_model):#将加载好的模型当做参数传入,加快运行速度
sentence = sentence.strip()
word_list = jieba.cut(sentence)
word_vector = [word2vec_model[w] for w in word_list if w in word2vec_model.wv.vocab]#转为词向量
word_dim = len(word_vector[0])
word_end = np.ones(shape=(word_dim,))#设置停止词
if len(word_vector) > 14:#裁剪句子
word_vector[14:] = []
word_vector.append(word_end)
else:
for i in range(15 - len(word_vector)):
word_vector.append(word_end)
return np.array([word_vector])
该函数将人的输入问句转为词向量序列,将加载好的词向量模型作为参数接收,而不在函数里加载模型,避免每次调用函数时都要加载一次模型
2.输出序列转文字
def vec2Sentence(answer_sequence,word2vec_model):
answer_list = [word2vec_model.most_similar([answer_sequence[i][0][0]])[0] for i in range(Ty)]
answer = ''
for index,word_tuple in enumerate(answer_list):
if word_tuple[1]>0.75:#当置信度小于75%时,就不把这个词加入回答中
answer += str(word_tuple[0])
return answer
这里有个需要注意的地方,由于全1向量不一定是词向量模型中的停止词,而且网络也不会输出纯粹的全1向量,为了避免输出大量的无意义结果,我做了一个处理,只将置信度大于75%的单词加入到回答中
主函数部分,先获取predict_model需要的三个参数,并初始化模型。get_layer()函数里的字符串是网络层的名字,名字是在原来train.py创建网络层时用参数name指定的,如果你起的名字和我不一样,或者你没写name的话应该会出问题
#sentence = np.zeros(shape=(1,15,60),dtype=float)#测试用的
print("加载模型层")
encoder = model.get_layer('encoder')#编码器生成编码状态
decoder = model.get_layer('decoder')
densor = model.get_layer('densor')
decoder_model = predict_model(encoder,decoder,densor,word_dim,Ty)
最后就是问答的代码了,predict_model里还是需要一个decoder_input的输入,我试过不用,但是会莫名其妙报错,最后只能手动指定一个全零的默认值传进去了
while(True):
sentence = input("问:")
sentence_vec = input_sentence_vector(sentence,word2vec_model)
X = np.zeros(shape=[1,1,word_dim])#decoder默认输入,为零就好
answer_sequence = decoder_model.predict([sentence_vec,X])#输出回答
print("答:",vec2Sentence(answer_sequence,word2vec_model))
predict.py完整代码
import warnings
warnings.filterwarnings('ignore')
from keras.models import Model,load_model
from keras.layers import Input, LSTM, Dense,TimeDistributed
from keras.optimizers import Adam
from gensim.models import word2vec
import numpy as np
import jieba
import pickle
print("加载模型中")
model = load_model("train_model.h5")
word2vec_model = word2vec.Word2Vec.load("word_vector/Word60.model")
Ty = 30#回答的最长长度
hidden_dim = 256
word_dim = 60#超参数设置
def predict_model(encoder_layer,decoder_layer,time_densor,word_dim,Ty):
X0 = Input(shape=(None,word_dim),name="sentence_input")
_,state_h,state_c = encoder_layer(X0)#获得编码序列
decoder_states_inputs = [state_h, state_c]
decoder_input = Input(shape=(1,word_dim),name='decoder_initial_input')
X = decoder_input
outputs = []
for i in range(Ty):
decoder_output,h,c = decoder_layer(X,initial_state=decoder_states_inputs)
output = time_densor(decoder_output)
decoder_states_inputs = [h,c]
X = output
outputs.append(output)
model = Model(input=[X0,decoder_input],outputs=outputs)
return model
def input_sentence_vector(sentence,word2vec_model):#将加载好的模型当做参数传入,加快运行速度
sentence = sentence.strip()
word_list = jieba.cut(sentence)
word_vector = [word2vec_model[w] for w in word_list if w in word2vec_model.wv.vocab]#转为词向量
word_dim = len(word_vector[0])
word_end = np.ones(shape=(word_dim,))#设置停止词
if len(word_vector) > 14:#裁剪句子
word_vector[14:] = []
word_vector.append(word_end)
else:
for i in range(15 - len(word_vector)):
word_vector.append(word_end)
return np.array([word_vector])
def vec2Sentence(answer_sequence,word2vec_model):
answer_list = [word2vec_model.most_similar([answer_sequence[i][0][0]])[0] for i in range(Ty)]
answer = ''
for index,word_tuple in enumerate(answer_list):
if word_tuple[1]>0.75:#当置信概率小于75%时,就不把这个词加入回答中
answer += str(word_tuple[0])
return answer
#sentence = np.zeros(shape=(1,15,60),dtype=float)#测试用的
print("加载模型层")
encoder = model.get_layer('encoder')#编码器生成编码状态
decoder = model.get_layer('decoder')
densor = model.get_layer('densor')
decoder_model = predict_model(encoder,decoder,densor,word_dim,Ty)
while(True):
sentence = input("问:")
sentence_vec = input_sentence_vector(sentence,word2vec_model)
X = np.zeros(shape=[1,1,word_dim])#decoder默认输入,为零就好
answer_sequence = decoder_model.predict([sentence_vec,X])#输出回答
print("答:",vec2Sentence(answer_sequence,word2vec_model))
运行测试一下

完全按训练集问大部分能答上来,但是语序稍微不一样,或者问别的问题就拉胯了,这也没有办法,毕竟网络比较简单,训练集里数据也不够,如果能用几十万条数据训练应该会好很多
总结
由于网络比较简单,训练集数据量也很少,作为入门实践还是相当不错的,以后想尝试更高级点的东西,把attention机制、beam search、scheduled sampling啥的都给安排上,再换个百度贴吧对话数据集来训练,不过不知啥时才能做成了,咕咕咕