语音识别学习日志 2019-7-17 语音识别基础知识准备6 {维特比算法(Viterbi Algorithm)}
HMM 维特比算法(Viterbi Algorithm)详细解释参考:http://www.52nlp.cn/hmm-learn-best-practices-six-viterbi-algorithm-1
http://www.52nlp.cn/hmm-learn-best-practices-six-viterbi-algorithm-2
http://www.52nlp.cn/hmm-learn-best-practices-six-viterbi-algorithm-3
http://www.52nlp.cn/hmm-learn-best-practices-six-viterbi-algorithm-4
http://www.52nlp.cn/hmm-learn-best-practices-six-viterbi-algorithm-5
寻找最可能的隐藏状态序列(Finding most probable sequence of hidden states)
对于一个特殊的隐马尔科夫模型(HMM)及一个相应的观察序列,我们常常希望能找到生成此序列最可能的隐藏状态序列。
1.穷举搜索
我们使用下面这张网格图片来形象化的说明隐藏状态和观察状态之间的关系:
我们可以通过列出所有可能的隐藏状态序列并且计算对于每个组合相应的观察序列的概率来找到最可能的隐藏状态序列。最可能的隐藏状态序列是使下面这个概率最大的组合:
Pr(观察序列|隐藏状态的组合)
例如,对于网格中所显示的观察序列,最可能的隐藏状态序列是下面这些概率中最大概率所对应的那个隐藏状态序列:
Pr(dry,damp,soggy | sunny,sunny,sunny), Pr(dry,damp,soggy | sunny,sunny,cloudy), Pr(dry,damp,soggy | sunny,sunny,rainy), . . . . Pr(dry,damp,soggy | rainy,rainy,rainy)
这种方法是可行的,但是通过穷举计算每一个组合的概率找到最可能的序列是极为昂贵的。与前向算法类似,我们可以利用这些概率的时间不变性来降低计算复杂度。
2.使用递归降低复杂度
给定一个观察序列和一个隐马尔科夫模型(HMM),我们将考虑递归地寻找最有可能的隐藏状态序列。我们首先定义局部概率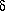 ,它是到达网格中的某个特殊的中间状态时的概率。然后,我们将介绍如何在t=1和t=n(>1)时计算这些局部概率。
,它是到达网格中的某个特殊的中间状态时的概率。然后,我们将介绍如何在t=1和t=n(>1)时计算这些局部概率。
这些局部概率与前向算法中所计算的局部概率是不同的,因为它们表示的是时刻t时到达某个状态最可能的路径的概率,而不是所有路径概率的总和。
2a.局部概率's和局部最佳途径
考虑下面这个网格,它显示的是天气状态及对于观察序列干燥,湿润及湿透的一阶状态转移情况:

对于网格中的每一个中间及终止状态,都有一个到达该状态的最可能路径。举例来说,在t=3时刻的3个状态中的每一个都有一个到达此状态的最可能路径,或许是这样的:

我们称这些路径局部最佳路径(partial best paths)。其中每个局部最佳路径都有一个相关联的概率,即局部概率或。与前向算法中的局部概率不同,是到达该状态(最可能)的一条路径的概率。
因而(i,t)是t时刻到达状态i的所有序列概率中最大的概率,而局部最佳路径是得到此最大概率的隐藏状态序列。对于每一个可能的i和t值来说,这一类概率(及局部路径)均存在。
特别地,在t=T时每一个状态都有一个局部概率和一个局部最佳路径。这样我们就可以通过选择此时刻包含最大局部概率的状态及其相应的局部最佳路径来确定全局最佳路径(最佳隐藏状态序列)。
2b.计算t=1时刻的局部概率's
我们计算的局部概率是作为最可能到达我们当前位置的路径的概率(已知的特殊知识如观察概率及前一个状态的概率)。当t=1的时候,到达某状态的最可能路径明显是不存在的;但是,我们使用t=1时的所处状态的初始概率及相应的观察状态k1的观察概率计算局部概率;即
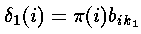
——与前向算法类似,这个结果是通过初始概率和相应的观察概率相乘得出的。
2c.计算t>1时刻的局部概率's
现在我们来展示如何利用t-1时刻的局部概率计算t时刻的局部概率。
考虑如下的网格:
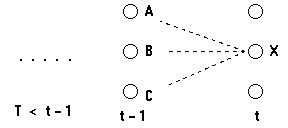
我们考虑计算t时刻到达状态X的最可能的路径;这条到达状态X的路径将通过t-1时刻的状态A,B或C中的某一个。
因此,最可能的到达状态X的路径将是下面这些路径的某一个
(状态序列),...,A,X
(状态序列),...,B,X
或 (状态序列),...,C,X
我们想找到路径末端是AX,BX或CX并且拥有最大概率的路径。
回顾一下马尔科夫假设:给定一个状态序列,一个状态发生的概率只依赖于前n个状态。特别地,在一阶马尔可夫假设下,状态X在一个状态序列后发生的概率只取决于之前的一个状态,即
Pr (到达状态A最可能的路径) .Pr (X | A) . Pr (观察状态 | X)
与此相同,路径末端是AX的最可能的路径将是到达A的最可能路径再紧跟X。相似地,这条路径的概率将是:
Pr (到达状态A最可能的路径) .Pr (X | A) . Pr (观察状态 | X)
因此,到达状态X的最可能路径概率是:
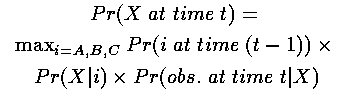
其中第一项是t-1时刻的局部概率,第二项是状态转移概率以及第三项是观察概率。
泛化上述公式,就是在t时刻,观察状态是kt,到达隐藏状态i的最佳局部路径的概率是:
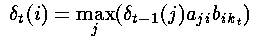
这里,我们假设前一个状态的知识(局部概率)是已知的,同时利用了状态转移概率和相应的观察概率之积。然后,我们就可以在其中选择最大的概率了(局部概率)。
2d.反向指针, 's
's
考虑下面这个网格
在每一个中间及终止状态我们都知道了局部概率,(i,t)。然而我们的目标是在给定一个观察序列的情况下寻找网格中最可能的隐藏状态序列——因此,我们需要一些方法来记住网格中的局部最佳路径。
回顾一下我们是如何计算局部概率的,计算t时刻的's我们仅仅需要知道t-1时刻的's。在这个局部概率计算之后,就有可能记录前一时刻哪个状态生成了(i,t)——也就是说,在t-1时刻系统必须处于某个状态,该状态导致了系统在t时刻到达状态i是最优的。这种记录(记忆)是通过对每一个状态赋予一个反向指针完成的,这个指针指向最优的引发当前状态的前一时刻的某个状态。
形式上,我们可以写成如下的公式
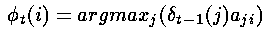
其中argmax运算符是用来计算使括号中表达式的值最大的索引j的。
请注意这个表达式是通过前一个时间步骤的局部概率's和转移概率计算的,并不包括观察概率(与计算局部概率's本身不同)。这是因为我们希望这些's能回答这个问题“如果我在这里,最可能通过哪条路径到达下一个状态?”——这个问题与隐藏状态有关,因此与观察概率有关的混淆(矩阵)因子是可以被忽略的。
2e.维特比算法的优点
使用Viterbi算法对观察序列进行解码有两个重要的优点:
1. 通过使用递归减少计算复杂度——这一点和前向算法使用递归减少计算复杂度是完全类似的。
2.维特比算法有一个非常有用的性质,就是对于观察序列的整个上下文进行了最好的解释(考虑)。事实上,寻找最可能的隐藏状态序列不止这一种方法,其他替代方法也可以,譬如,可以这样确定如下的隐藏状态序列:
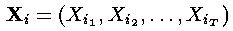
其中
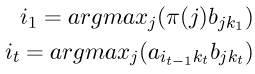
这里,采用了“自左向右”的决策方式进行一种近似的判断,其对于每个隐藏状态的判断是建立在前一个步骤的判断的基础之上(而第一步从隐藏状态的初始向量 开始)。
开始)。
这种做法,如果在整个观察序列的中部发生“噪音干扰”时,其最终的结果将与正确的答案严重偏离。
相反, 维特比算法在确定最可能的终止状态前将考虑整个观察序列,然后通过指针“回溯”以确定某个隐藏状态是否是最可能的隐藏状态序列中的一员。这是非常有用的,因为这样就可以孤立序列中的“噪音”,而这些“噪音”在实时数据中是很常见的。
3.小结
维特比算法提供了一种有效的计算方法来分析隐马尔科夫模型的观察序列,并捕获最可能的隐藏状态序列。它利用递归减少计算量,并使用整个序列的上下文来做判断,从而对包含“噪音”的序列也能进行良好的分析。
在使用时,维特比算法对于网格中的每一个单元(cell)都计算一个局部概率,同时包括一个反向指针用来指示最可能的到达该单元的路径。当完成整个计算过程后,首先在终止时刻找到最可能的状态,然后通过反向指针回溯到t=1时刻,这样回溯路径上的状态序列就是最可能的隐藏状态序列了。
1、维特比算法的形式化定义
维特比算法可以形式化的概括为:
对于每一个i,i = 1,... ,n,令:
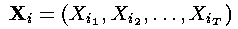
——这一步是通过隐藏状态的初始概率和相应的观察概率之积计算了t=1时刻的局部概率。
对于t=2,...,T和i=1,...,n,令:
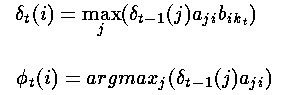
——这样就确定了到达下一个状态的最可能路径,并对如何到达下一个状态做了记录。具体来说首先通过考察所有的转移概率与上一步获得的最大的局部概率之积,然后记录下其中最大的一个,同时也包含了上一步触发此概率的状态。
令:

——这样就确定了系统完成时(t=T)最可能的隐藏状态。
对于t=T-1,...,1
令:
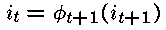
——这样就可以按最可能的状态路径在整个网格回溯。回溯完成时,对于观察序列来说,序列i1 ... iT就是生成此观察序列的最可能的隐藏状态序列。
2.计算单独的's和's
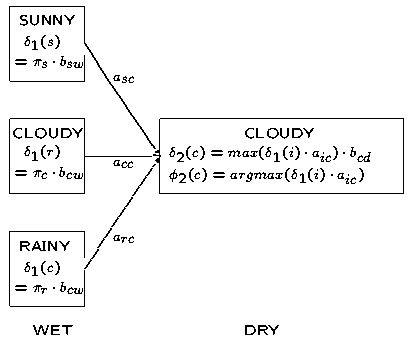
维特比算法中的局部概率's的计算与前向算法中的局部概率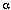 's的很相似。下面这幅图表显示了's和's的计算细节,可以对比一下前向算法3中的计算局部概率's的那幅图表:
's的很相似。下面这幅图表显示了's和's的计算细节,可以对比一下前向算法3中的计算局部概率's的那幅图表:
(注:本图及前向算法3中的相似图存在问题,具体请见前向算法3文后评论,非常感谢读者YaseenTA的指正)
唯一不同的是前向算法中计算局部概率's时的求和符号( )在维特比算法中计算局部概率's时被替换为max——这一个重要的不同也说明了在维特比算法中我们选择的是到达当前状态的最可能路径,而不是总的概率。我们在维特比算法中维护了一个“反向指针”记录了到达当前状态的最佳路径,即在计算's时通过argmax运算符获得。
)在维特比算法中计算局部概率's时被替换为max——这一个重要的不同也说明了在维特比算法中我们选择的是到达当前状态的最可能路径,而不是总的概率。我们在维特比算法中维护了一个“反向指针”记录了到达当前状态的最佳路径,即在计算's时通过argmax运算符获得。
总结(Summary)
对于一个特定的隐马尔科夫模型,维特比算法被用来寻找生成一个观察序列的最可能的隐藏状态序列。我们利用概率的时间不变性,通过避免计算网格中每一条路径的概率来降低问题的复杂度。维特比算法对于每一个状态(t>1)都保存了一个反向指针(),并在每一个状态中存储了一个局部概率()。
局部概率是由反向指针指示的路径到达某个状态的概率。
当t=T时,维特比算法所到达的这些终止状态的局部概率's是按照最优(最可能)的路径到达该状态的概率。因此,选择其中最大的一个,并回溯找出所隐藏的状态路径,就是这个问题的最好答案。
关于维特比算法,需要着重强调的一点是它不是简单的对于某个给定的时间点选择最可能的隐藏状态,而是基于全局序列做决策——因此,如果在观察序列中有一个“非寻常”的事件发生,对于维特比算法的结果也影响不大。
这在语音处理中是特别有价值的,譬如当某个单词发音的一个中间音素出现失真或丢失的情况时,该单词也可以被识别出来。