Python基础笔记
Python基础笔记
声明:本文内容主要来源于中国大学MOOC嵩天老师的课程Python语言程序设计
文章目录
- Python基础笔记
- 计算机与程序设计
- 保留字
- 基础
- 数据类型
- 字符串
- 程序的分支结构
- 程序的循环结构
- 函数与代码复用
- 组合数据类型之集合类型
- 组合类型之序列类型
- 组合类型之字典类型
- 文件和数据格式化
- 文件的使用
- 一维数据的格式化和处理
- 二维数据的格式化和处理
- 程序设计方法
- 设计方法
- 设计思维
- 计算生态
- 用户体验与软件产品
- 程序设计模式
- Python第三方库安装
- Python计算生态概览
- 从数据处理到人工智能
- 1.Python库之数据分析
- 2.Python库之数据可视化
- 3.Python库之文本
- 4.Python之机器学习
- 从Web解析到网络空间
- 5.Python库之网络爬虫
- 6.Python库之Web信息提取
- 7.Python库之Web网站开发
- 8.Python库之网络应用开发
- 从人机交互到艺术设计
- 9.Python库之图形用户界面
- 10.Python库之游戏开发
- 11.Python库之虚拟现实
- 12.Python库之图形艺术
计算机与程序设计
计算机是根据指令操作数据的设备
- 功能性 对数据的操作表现为数据计算、输入输出处理和结果存储等
- 可编程性 根据一系列指令自动地、可预测地、准确地完成操作者的意图
计算机的发展 参照摩尔定律,表现为指数方式
- 计算机硬件所依赖的集成电路规模参照摩尔定律
- 运行速度因此也接近几何级数快速增长
- 高效支撑的各类运算功能不断丰富发展
摩尔定律 计算机发展历史上最重要的预测法则
- Intel公司创始人之一 戈登摩尔在1965年提出
- 单位面积集成电路上可容纳晶体管的数量约每两年翻一番
- CPU/GPU、内存、硬盘、电子产品价格等都遵循摩尔定律
- 当今世界唯一长达50年有效且按照指数发展的技术领域
- 计算机深刻改变人类社会,甚至可能改变人类本身

程序设计 计算机可编程性的体现
- 深度应用计算机的主要手段
- 当今社会需求量最大的职业技能之一,许多岗位都将被计算机程序接管
- 程序设计将是生存技能
程序设计语言 一种用于人类与计算机之间交互的人造语言,亦称编程语言,比自然语言更简单、更严谨、更精确
- 编程语言超过了600种,绝大部分不再被使用
- C语言诞生于1972年,是第一个被广泛使用的编程语言
- Python语言诞生于1990年,是最流行最好用的编程语言
编程语言的执行方式 编译和解释
- 源代码:采用某种编程语言编写的计算机程序,人类可读 如
result = 1+1 - 目标代码:计算机可直接执行,人类不可读,专家除外。如
11010010 00111011
编译 将源代码一次性转换成目标代码的过程,执行编译过程的程序叫作编译器
解释 将源代码逐条转换成目标代码同时逐条运行的过程,执行解释过程的程序叫作解释器

编译: 一次性翻译,之后不再需要源代码,类似英文翻译
解释:每次程序运行时随翻译随执行,类似实时同声传译
静态语言
- 使用编译器执行的编程语言,如C/C++语言、Java语言
- 编译器一次性生成目标代码,优化更充分,程序运行速度快
动态语言
- 使用解释器执行的编程语言,如Python语言、JavaScript语言、PHP语言
- 执行程序时需要源代码,维护更灵活
程序的基本编写方法 IPO
- I :Input 输入,程序的输入
文件输入、网络输入、控制台输入、交互界面输入、内部参数输入等 - P:Process处理,程序的主要逻辑
程序最重要的部分,处理的方法统称为算法,是一个程序的灵魂 - O:Output输出,程序的输出
控制台输出、图形输出、文件输出、网络输出、操作系统内部变量输出等
Python语言诞生 创立者 Guido van Rossum
- python 蟒蛇,命名来源于喜剧组合 Python Monkey
- 2002年,Python2.x
- 2008年,Python3.x
- Python 语言是一个有开放、开源精神的编程语言
保留字
| and | elif | if | or | with |
|---|---|---|---|---|
| as | else | import | pass | yield |
| assert | except | in | raise | del |
| break | finally | lambda | return | False |
| class | for | not | try | |
| continue | from | nonlocal | True | |
| def | global | None | while |
基础
- python大小写敏感
- python注释语句以#号开头,使用’’’ ‘’'进行注释块
- : 后是代码块,缩进4个空格或1个Tab
- 强制缩进的坏处是复制粘贴不好用
- 变量命名规则:大小写字母、数字、下划线和汉字等字符组合,大小写敏感、首字符不能是数字、不与保留字相同
数据类型
- 整数可正可负,没有取值范围限制
四种表示形式:十进制,二进制0b或0B开头
八进制以0o或0O开头
十六进制以0x或0X开头 - 浮点数取值范围和小数精度存在限制,取值范围数量级为-10308~10308,
精度数量级为10^-16,inf表示无限大。
浮点数间计算存在不确定尾数,不是bug,可以round()函数四舍五入处理
科学计数法使用字母e或E作为幂表示,以10为基数,如e表示 a ∗ 1 0 b a*10^b a∗10b - 复数类型 c = a + b j c=a+bj c=a+bj 其中实部用
c.real获得,虚部用c.imag获得 - 布尔值:True False
- 空值:None
- 数值运算符 /(精确除法) ,//(地板除), %(取余数),**(幂次方)
- 数值运算函数
abs(x)x的绝对值divmod(x,y)商余,如divmod(10,3) 结果为(3,1)
pow(x,y[,z])幂余, 表示(x**y)%z
round(x,y)四舍五入
max(x1,x2,...,xn)返回最大值
min(x1,x2,...,xn)返回最小值
int(x)将x变为整数,舍弃小数部分,如int(123.45) int("123")
float(x)将x变为浮点数,增加小数部分
字符串
- 索引 :返回字符串中单个字符 <字符串>[M]
切片:返回字符串中一段字符子串 <字符串>[M:N(:步长)] - 字符串 转义字符 \,r’ ’ 示不能转义,”’…”’多行内容
“\b” 回退 "\n"换行(光标移动到下行首) "\r"回车(光标移动到本行首) - 字符串操作符
x+y连接两个字符串
n*x或x*n复制n次字符串x
x in s如果x是s的子串,返回True,否则返回False - 字符串处理函数
len(x)返回字符串x的长度
str(x)与eval(x)相反,将x加上引号变为字符串
hex(x)或oct(x)整数x的十六进制或八进制
chr(u)或ord(x)Unicode与单字符的互相转换
十二星座:ch(9800)~chr(9812)=>♈♉♊♋♌♍♎♏♐♑♒♓ - 字符串处理方法
str.lower(),str.upper()返回字符串的副本,全部字符小写/大写
str.split(seq=None)返回一个列表,由str根据sep被分隔的部分组成
str.count(sub)返回子串sub在str中出现的次数
str.replace(old,new)返回字符串副本,所有old子串被替换成new
str.center(width[,fillchar])字符串str根据宽度width居中,fillchar可选
如"python".center(20,"=") 结果为 '======python======='
str.strip(chars)从str中去掉在其左侧和右侧chars中列出的字符
如"= python =".strip(" =np") 结果为 "ytho"
str.join(iter)在iter变量除最后元素外每个元素后增加一个str,主要用于字符串分隔
如",".join("12345") 结果为"1,2,3,4,5"
str1.index(str2[,begin[,end]])从字符串str1的begin到end位置时搜索到字符串str2时返回在str1的索引。
str2 = "exam"
print (str1.index(str2))
print (str1.index(str2, 10))
print (str1.index(str2, 40))
结果为
15
15
Traceback (most recent call last):
File "" , line 1, in <module>
print(str1.index(str2, 16))
ValueError: substring not found
- 字符串格式化
用法:<模板>.format(<逗号分隔的参数>)
注意槽的变化
"{}:计算机{}的CPU占用率为{}%".format("2018-10-10","C",10)
0 1 2 0 1 2
结果为:"2018-10-10:计算机C的CPU占用率为10%"
"{1}:计算机{0}的CPU占用率为{2}%".format("2018-10-10","C",10)
结果为:"C:计算机2018-10-10的CPU占用率为10%"
槽内部对格式化的配置方式
{<参数序号>:<格式控制标记>}
| : | <填充> | <对齐> | <宽度> | <,> | <.精度> | <类型> |
|---|---|---|---|---|---|---|
| 引导符号 | 用于填充的单个字符 | <为左对齐 >为右对齐 ^居中对齐 | 槽设定的输出宽度 | 数字的千位分隔符 | 浮点数小数精度或字符串最大输出长度 | 整数类型b,c,d,o,x,X浮点数类型e,E,f,% |
程序的分支结构
- 单分支 if 二分支 if-else 及 适用于简单表达式的二分支紧凑形式
"对" if guess==99 else "错" - 多分支 if-elif-else 及条件之间关系
- not and or > >= == <= < !=
- 异常处理 try-except-else-finally
异常处理一
try:
<语句块1>
except <异常类型,可针对响应>:
<语句块2>
异常处理二,直接抛出
raise <异常名称>
三、异常发生,finally中语句正常执行
try:
<语句块1>
(except (<异常类型,可针对响应>):
<语句块>)
finally:
<语句块2>
四、异常不发生时会执行else中语句
try:
<语句块1>
except <异常类型>:
<语句块2>
else:
<语句块3>
finally:
<语句块4>
五、自定义异常
自定义一个MyException类,继承Exception。
class MyException(Exception):
def __init__(self,message):
Exception.__init__(self)
self.message=message
如果输入的数字小于10,就引发一个MyException异常:
a=input("please input a num:")
if a<10:
try:
raise MyException("my excepition is raised ")
except MyException,e:
print e.message
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| SystemExit | Python 解释器请求退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
程序的循环结构
- for … in 遍历循环:计数、字符串、列表、文件
- while 无限循环
- continue 和 break 保留字:中止和退出当前循环层次
- 循环else 的高级用法:与break有关
当循环没有被break语句退出时,执行else语句,视作”正常“完成循环的奖励
用法与异常处理中else用法类似
for <变量> in <遍历结构>:
<语句块1>
else:
<语句块2>
--------------------------
while <条件>:
<语句块1>
else:
<语句块2>
函数与代码复用
- 函数是一段具有特定功能的、可重用的语句组
- 函数是一种功能的抽象,一般函数表达特定功能
- 函数的两个作用:降低编程难度和代码复用
函数定义
def <函数名>(<参数(0个或多个)>):
<函数体>
return <返回值>
- 函数定义时,所指定参数是一种占位符
- 函数定义后,如果不经调用,不会被执行
- 函数定义时,参数是输入、函数体是处理、结果是输出(IPO)
函数调用
- 参数传递 函数可以有参数,也可以没有,但必须保留括号
- 可选参数 函数定义时可以为某些参数指定默认值,构成可选参数
如:
def fact(n,m=1):
s=1
for i in range(1,n+1):
s *=i
return s//m
>>>fact(10)
3628800
>>>fact(10,5)
725760
- 可变参数传递 函数定义时可设计可变数量参数,即不确定参数总数量
如:
def fact(n,*b):
s=1
for i in range(1,n+1):
s*=i
for item in b:
s*=item
return s
>>>fact(10,3)
10886400
>>>fact(10,3,5,8)
435456000
- 函数调用时,参数可以按照位置或名称传递
- 函数的返回值,可以有也可以没有,可传递0个返回值,也可传递任意多个返回值
多个返回值会以元组类型返回
局部变量和全局变量
- 局部变量是函数内部的占位符,与全局变量可能重名但不同
- 函数运算结束后,局部变量被释放
- 可以使用
global保留字在函数内部使用全局变量 - 局部变量为组合数据类型且未创建,等同于全局变量
ls =['F','f'] #全局变量列表ls
def func(a):
ls.append(a) #此处ls是列表类型,未真实创建,等同于全局变量
return
func('C')
print(ls)
>>>
['F','f','C']
组合数据类型之集合类型
1.集合定义
- 集合是多个元素的无序组合,与数学中的集合概念一致
- 元素之间无序,每个元素唯一,不存在相同元素
- 集合元素不可更改,不能是可变数据类型
2.集合表示
- 用大括号{}表示,元素间用逗号分隔
- 建立集合类型用{}或set(),建立空集合类型必须使用set()
>>> A={"python",123,('python',123)}
>>> A
{123, 'python', ('python', 123)}
>>> B=set("pypy1233")
>>> B
{'3', 'y', '1', '2', 'p'}
>>> C={"python",123,"python",123}
>>> C
{123, 'python'}
3.集合间操作
S|T 并集 包括在集合S和T中的所有元素
S-T差集 包括在S但不在T中的元素
S&T交集 包括同时在S和T中的元素
S^T补集 包括S和T的非相同元素
S<=T 或 S
S>=T 或 S>T 返回True/False,判断S和T的包含关系
- 增强操作符
S|=T S&=T S^=T S-=T
>>> A={'p','y',123}
>>> B=set("pypy123")
>>> A-B
{123}
>>> B-A
{'3', '1', '2'}
>>> A&B
{'p', 'y'}
>>> A^B
{'3', '1', 123, '2'}
>>> A|B
{'3', 'y', '1', '2', 'p', 123}
4.集合处理方法
S.add(x) 如果x不在集合S中,将x增加到S
S.discard(x) 移除S中元素x,如果x不在集合S中,不报错
S.remove(x) 移除S中元素x,如果x不在集合S中,产生KeyError异常
S.clear()移除S中所有元素
S.pop() 随机取出S的一个元素,更新S,若S为空产生KeyError异常
S.copy()返回S的一个副本
len(S)返回集合S的元素个数
x in S 与 x not in判断S中元素x是否存在,返回True/False
set(x)将其他类型变量x转变为集合类型
try:
while True:
print(A.pop(),end="")
except:
pass
p123y
>>>A
set()
#此方法等价于for...in
5.集合类型应用场景
- 包含关系比较
- 数据去重 利用集合无重复元素特点
>>> A
set()
>>> "p" in {'p','y',123}
True
>>> {'p','y'} >={'y',123}
False
>>> ls=['p','p','y',231,'y']
>>> s=set(ls)
>>> s
{231, 'p', 'y'}
>>> lt=list(s)
>>> lt
[231, 'p', 'y']
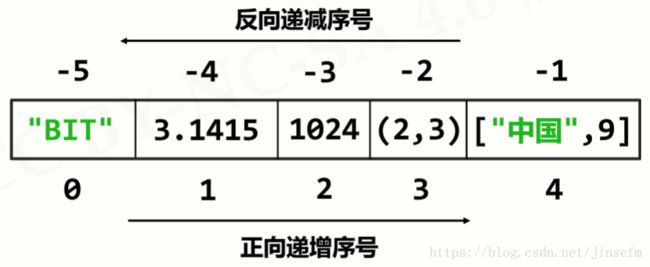
组合类型之序列类型
1.序列类型定义
- 序列是具有先后关系的一组元素
- 序列是一维元素向量,元素类型可以不同
- 类似熟悉元素序列: S 0 , S 1 , . . . , S n − 1 S_0,S_1,...,S_n-1 S0,S1,...,Sn−1
- 元素间由序号引导,通过下表
序列是一个基类类型
包含字符串类型/元组类型/列表类型
2.序列处理函数及方法
-
序列类型通用操作符
x in s和x not in s判断x是否为s序列的元素
s+t连接两个序列s和t
s*n或n*s将序列复制n次
s[i]索引,返回s中第i个元素
s[i:j]或s[i:j:k]切片,返回序列s中第i到j以k为步长的元素子序列 -
序列类型通用函数和方法
len(s)返回序列s的长度
min(s)或max(s)返回序列s的最小或最大值,s中元素需可比较
s.index(x)或s.index(X,i,j)返回序列s从i开始到j位置中第一次出现元素X的位置
s.count(x)返回序列中出现x的总次数
3.元组类型及操作
元组是序列类型的一种扩展
- 元组是一种序列类型,一旦创建就不能被修改
- 使用小括号()或
tuple()创建,元素间用逗号,分隔 - 可以使用或不使用小括号
def func():
return 1,2
- 元组继承了序列类型 的全部通用操作
- 因为创建后不能修改,因此没有特殊操作
>>> creature='cat','dog','tiger','human'
>>> creature[::-1]
('human', 'tiger', 'dog', 'cat')
>>> color=(0x001100,'blue',creature)
>>> color
(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
>>> color[-1][2]
'tiger'
4.列表类型定义
- 列表是一种序列类型,创建后可以随意被修改
- 使用方括号[]会list() 创建,元素间用逗号,分隔
- 列表中各元素类型可以不同,无长度限制
>>> ls=['cat','dog','tiger',1024]
>>> ls
['cat', 'dog', 'tiger', 1024]
>>> lt=ls
>>> lt
['cat', 'dog', 'tiger', 1024]#方括号[]真正创建一个列表,赋值仅传递引用
- 列表类型操作函数和方法
ls[i]=x替换列表ls第i元素为x
ls[i:j:k]=lt用列表lt替换切片后所对应元素子列表
del ls[i]删除列表ls中第i元素
del ls[i:j:k]删除列表ls中第i到j以k为步长的元素
ls +=lt更新列表ls,将列表lt元素增加到列表ls中
ls *=n更新列表ls,其元素重复n次
>>> ls=['cat','dog','tiger',1024]
>>> ls[1:2]=[1,2,3,4]
>>> ls
['cat', 1, 2, 3, 4, 'tiger', 1024]
>>> del ls[::3]
>>> ls
[1, 2, 4, 'tiger']
>>> ls*2
[1, 2, 4, 'tiger', 1, 2, 4, 'tiger']
ls.append(x)在列表ls最后增加一个元素
ls.clear()删除列表ls中所有元素
ls.copy()生成一个新列表,赋值ls中所有元素
ls.insert(i,x)在列表ls的第i位置增加元素x
ls.pop(i)将列表元素ls中的第i位置元素取出并删除元素
ls.remove(x)将列表ls中出现的第一个元素x删除
ls.reverse()将列表ls中的元素反转
5.序列类型应用场景
- 表示一组有序数据,进而操作他们
- 元素遍历
- 数据保护
lt=tuple(ls)
组合类型之字典类型
1.字典类型定义
- 映射是一种键(索引)和值(数据)的对应
- 内部颜色蓝色,外部颜色红色
- 序列类型由0…N整数作为数据默认索引,映射类型则由用户为数据定义索引,键是数据索引的扩展
- 字典类型是“映射”的体现,字典是键值对的集合,键值对之间无序
- 采用大括号{}和
dict()创建,键值对用冒号:表示
"streetAddr":"中关村南大街1号"
"City":"北京市"
{<键1>:<值1>,<键2>:<值2>,...}
2.字典类型的用法
- [] 用来向字典变量中索引或增加元素
type(x)返回变量x的类型
>>> d={"中国":"北京","美国":"华盛顿","法国":"巴黎"}
>>> d
{'中国': '北京', '美国': '华盛顿', '法国': '巴黎'}
>>> d['中国']
'北京'
>>> de={}
>>> de
{}
>>> type(de)
<class 'dict'>
>>> d
{'中国': '北京', '美国': '华盛顿', '法国': '巴黎', '日本': '东京'}
3.字典处理函数及方法
del d[k]删除字典d中键k对应的数据k in d判断键k是否在字典d中,如果在返回True,否则Falsed.keys()返回字典d中所有的键信息d.values()返回字典d 中所有的值信息d.items()返回字典d中所有键值对信息
>>> '中国' in d
True
>>> d.keys()
dict_keys(['中国', '美国', '法国', '日本'])
>>> d.values()
dict_values(['北京', '华盛顿', '巴黎', '东京'])
>>> d.items()
dict_items([('中国', '北京'), ('美国', '华盛顿'), ('法国', '巴黎'), ('日本', '东京')])
d.get(k,键k存在,则返回相应值,不在则返回值) d.pop(k,键k存在,则取出相应值,不在则返回值) d.popitem()随机从字典d中取出一个键值对,以元组形式返回d.clear()删除所有键值对len(d)返回字典d中元素的个数
>>> d.get('中国','上海')
'北京'
>>> d.get('韩国','上海')
'上海'
>>> d.popitem()
('日本', '东京')
>>> d
{'中国': '北京', '美国': '华盛顿', '法国': '巴黎'}
4.字典类型应用场景
- 映射无处不在,键值对无处不在
例如:统计数据出现的次数,数据是键,次数是值 - 主要他们键值对数据,进而操作他们
文件和数据格式化
- 字符串格式化
“{}{}{}”.format()将字符串按照一定规格和式样进行规范 - 数据格式化 将一组数据按照一定规格和式样进行规范:表示、存储、运算等
文件的使用
文件类型
- 文件是数据的抽象和集合
- 文件是存储在辅助存储器上的数据序列,是数据存储的一种形式
- 文件展现形态:文本文件和二进制文件
文本文件 VS 二进制文件
- 文本文件和二进制文件只是文件的展示形式
- 本质上,所有文件都是二进制形式存储
- 形式上,所有文件采用两种方式展示
文本文件由单一特定编码组成的文件,如UTF-8编码,由于存在编码,也被看成是存储着的长字符串,适用于例如:.txt文件、.py文件等
二进制文件直接有比特0和1组成,没有统一字符编码,一般存在二进制0和1的组织结构,即文件格式,适用于如:.png文件、.avi文件等
#f.txt文件保存:“中国是个伟大的国家!”
>>>
tf=open("f.txt","rt") # 文本形式打开文件
print(tf.readline())
tf.close()
>>>
中国是个伟大的国家!
>>>
bf=open("f.txt","rb") # 二进制形式打开文件
print(bf.readline())
bf.close()
>>>
b'\xd6\xd0\xb9\xfa\xca\xc7\xb8\xf6\xce\xb0\xb4\xf3\xb5\xc4\xb9\xfa\xbc\xd2\xa3\xa1'
文件的打开关闭
步骤:打开 -->操作–>关闭
<变量名> =open(<文件名>,<打开模式>)
- 变量名 文件句柄
- 文件名 源文件同目录可省路径
D:\\PYE\\f.txtf.txt<=> ‘./PYE/f.txt’ - 打开模式 文本 or 二进制 读 or 写
<变量名>.close()
| 打开模式 | 描述 |
|---|---|
| ‘r’ | 只读模式,默认值,如果文件不存在,返回FileNotError |
| ‘w’ | 覆盖写模式,文件不存在则创建,存在则完全覆盖 |
| ‘x’ | 创建写模式,文件不存在则创建,存在则返回FileExistError |
| ‘a’ | 追加写模式,文件不存在则创建,存在则在文件最后追加内容 |
| ‘b’ | 二进制文件模式 |
| ‘t’ | 文本文件模式,默认值 |
| ‘+’ | 与r/w/x/a一同使用,在原功能基础上增加,使其同时具备读写功能 |
f=open('f.txt') -文本形式、只读模式、默认值
f=open('f.txt','rt') -文本形式、只读模式、默认值
f=open('f.txt','w') -文本形式、覆盖写模式
f=open('f.txt','a+') - 文本形式、追加写模式+读文件
f=open('f.txt','x') - 文本形式、创建写模式
f=open('f.txt','b') - 二进制形式、只读模式
f=open('f.txt','wb') - 二进制形式、覆盖写模式
文件内容的读取
| 操作方法 | 描述 |
|---|---|
f.read(size=-1) |
读取全部内容,如果给出参数,读入前size长度>>>s=f.read(2)中国 |
f.readline(size=-1) |
读入一行内容,如果给出参数,读入该行前size长度>>>s=f.readline()中国是个伟大的国家 |
f.readlines(hint=-1) |
读入文件所有行,以每行为元素形成列表,如果给出参数,读入前hint行>>>s=f.readlines()['中国是个伟大的国家'] |
文件的全文本操作
- 遍历全文本: 一次读入,统一处理
按数量读入,逐步处理
fname = input('请输入要打开的文件名称:')
fo = open(fname,'r')
txt = fo.read()
#对全文txt进行处理 -一次读入,统一处理,弊端是大文件占用内存,耗资源,代价很大
fo.close()
fname = input('请输入要打开的文件名称:')
fo = open(fname,'r')
txt = fo.read(2)
while txt != "":
#对txt进行处理 - 按数量读入,逐步处理
txt=fo.read(2)
fo.close()
- 逐行遍历文本:一次读入,分行处理
分行读入,逐行处理
fname = input('请输入要打开的文件名称:')
fo = open(fname,'r')
for line in fo.readlines():
print(line)
fo.close()
fname = input('请输入要打开的文件名称:')
fo = open(fname,'r')
for line in fo:
print(line)
fo.close()
数据的写入
| 操作方法 | 描述 |
|---|---|
f.write(s) |
向文件写入一个字符串或字节流>>>f.write("中国是一个伟大的国家") |
f.writelines(lines) |
将一个元素全为字符串的列表写入文件,写入的数据为列表所有元素拼接成字符串后大字符串>>>ls=['中国','德国','美国']>>>f.writelines(s)中国德国美国 |
f.seek(offset) |
改变当前文件操作指针的位置,offset含义如下:0-文件开头;1-当前位置 2-文件结尾>>>f.seek(0) #回到文件开头 |
fo=open('output.txt','w+')
ls=['中国','法国','美国']
fo.writelines(ls)
fo.seek(0)//没有seek回到文件开头的话,输出为空
for line in fo:
print(line);
fo.close()
注意: window环境,打开文件默认编码为gbk,写入的数据流如果可能不是gbk编码,而是utf-8,就会报’gbk’ codec can’t encode character 错误。
需要改变文件的编码
f=open('output.txt','w',encoding='utf-8')
一维数据的格式化和处理
一维数据 由对等关系的有序或无序数据构成,采用线性方式组织
- 对于列表、数组和集合概念
二维数据 由多个一维数据构成,是一维数据的组合形式
- 表格是典型的二维数据
- 其中,表头是二维数据的一部分
多维数据 由一维或二维数据在新维度上扩展形成
高维数据 仅利用最基本的二元关系展示数据间的复杂结构
{
"firstName" : "Mingzi" ,
"lastName" : "Xingshi" ,
"address" :{
"streeAddr" : "某某村某某街",
"city" : "Beijing",
"zipcode" : "10081"
}
"professsional" : ["Computer Networking","Security"]
}
数据的操作周期
存储 <-> 表示 <-> 操作
一维数据的表示
- 如果数据间有序:使用列表类型
- 如果数据间无序:使用集合类型
一维数据的存储
空格分隔
- 使用一个或多个空格分隔进行存储,不换行
- 缺点:数据本身不能存在空格
逗号分隔
- 使用英文半角逗号分隔数据进行存储,不换行
- 缺点:数据本身不能存在英文逗号
*特殊符号分隔
- 使用其他符合组合分隔,建议采用特殊符号
- 缺点:需要根据数据特点定义,通用性较差
一维数据的处理
空格分隔
读取 txt=open(fname).read();ls=txt.split()
写入 f.write(' '.join(ls))
逗号分隔
读取 txt=open(fname).read();ls=txt.split(',')
写入 f.write(','.join(ls))
二维数据的格式化和处理
二维数据的表示
- 列表类型可以表达二维数据
- 使用二维列表
- 使用两层for循环遍历每个元素
- 外层列表中每个元素可以对应一行,也可以对应一列
CSV格式与二维数据存储
CSV :Comma-Separated Values
- 国际通用的一二维数据存储格式,一般.csv扩展名
- 每行一个一维数据,采用逗号分隔,无空行
- Excel软件可读入输出,一般编辑软件都可以生成

CSV数据存储格式
- 如果某个元素确实,逗号仍要保留
- 二维数据的表头可以作为数据存储,也可另行存储
- 逗号为英文半角逗号,逗号和数据之间无额外空格
二维数据的存储
- 按行存或者按列存都可以,具体由程序决定
- 一般索引习惯:ls[row][column],先行后列
- 根据一般习惯,外层列表每个元素是一行,按行存
二维数据的处理
- 读取
fo =open(fname)
ls =[]
for line in fo:
line=line.replace('\n','')
ls.append(line.split(','))
fo.close()
- 写入
ls =[[],[],[]]
f= open(fname,'w')
for item in ls:
f.write(','.join(item)+'\n')
f.close()
- 逐一
ls =[[],[],[]]
for row in ls:
for column in row:
print(ls[row][column])
程序设计方法
设计方法
自顶向下 解决复杂问题的有效方法
- 将一个总问题分解为若干个小问题组成的形式
- 使用同样方法进一步分解小问题
- 直至,小问题可以用计算机简单明了的解决
自底向上 逐步组建复杂系统的有效测试方法
- 分单元测试,逐步组装
- 按照自顶向下相反的路径操作
- 直至,系统各部分以组装的思路都经过测试和验证
设计思维
逻辑思维 推理和演绎,数学为代表,A->B B->C A->C
实证思维 实验和验证,物理为代表,引力波<- 实验
计算思维 设计和构造,计算机为代表,汉诺塔递归
计算思维 Computational Thinking
- 特征 抽象和自动化
- 抽象问题的计算过程,利用计算机自动化求解
- 计算思维基于计算机强大的算力和海量数据



- 抽象计算过程,关注设计和构造,而非因果
- 编程是将计算思维变为现实的手段

计算生态
计算生态 以开源项目为组织形式,充分利用“共识原则”和“社会利他”组织人员,在竞争发展、相互依存和迅速更迭中完成信息技术的更新换代,形成技术的自我演化路径。

计算生态 没有顶层设计、以功能为单位、具备三个特点
- 竞争发展
- 相互依存
- 迅速更迭
计算生态的价值在于创新,跟随创新,集成创新和原始创新
Python语言与计算生态
- 以开源项目为代表的大量第三方库
python语言提供>14万个第三方库 - 库的建设经过野蛮生长和自然选择 同一个功能,python语言提供了2个以上的第三方库
- 库之间相互关联使用,依存发展 python库间广泛联系,逐级封装
- 社区庞大,新技术更迭迅速 AlphaGa深度学习算法采用Python语言开源
计算生态的运用
- 编程的起点不是算法而是系统
- 编程如同搭积木,利用计算生态位主要模式
- 编程的目标是快速解决问题
刀耕火种 -> 站在巨人的肩膀上
用户体验与软件产品
实现功能 -> 关注用户体验
- 用户体验指用户对产品建立的主观感受和认识
- 关注功能的实现,更要关心用户体验,才能做出好产品
- 编程只是手段,不是目的,程序最终为人类服务
提高用户体验的方法
进度展示
- 如果程序需要计算时间,可能产生等待,请增加进度展示
- 如果程序有若干步骤,需要提示用户,请增加进度展示
- 如果程序可能存在大量次数循环,请增加进度展示
异常处理
- 当获得用户输入,对合规性需要检查
- 当读写文件时,对结果进行判断
- 当进行输入输出时,对运算结果进行判断
其他类方法
- 打印输出:特定位置,输出程序运行的过程信息
- 日志文件: 对程序异常及用户使用进行定期记录
- 帮助信息:给用户多种方式提供帮助信息
软件程序->软件产品:用户体验是程序到产品的关键环节
程序设计模式
- IPO :Input,Process,Output
- 自顶向下
- 模块化设计
通过函数或对象封装和将程序划分为模块及模块间的表达,具体包括:主程序、子程序和子程序之间的关系,体现了一种分而治之,分层抽象、体系化的设计思想。
模块内部紧耦合、模块之间松耦合。紧耦合:相互间交流多,无法独立存在;松耦合则相反。 - 配置化设计
引擎+配置:程序执行和配置分离,将可选参数配置化,将程序开发变成配置文件编写,扩展功能而不修改程序。关键在于接口设计,需清晰明了、灵活可扩展
应用开发的四个步骤
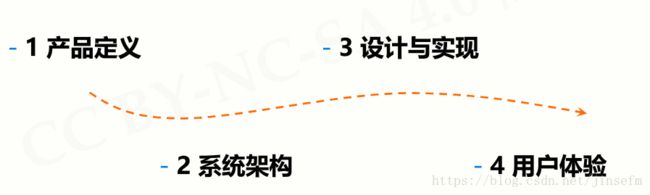
- 产品定义 对应用需求充分理解和明确定义
产品定义,而不仅是功能定义,要考虑商业模式 - 系统架构 以系统方式思考产品的技术实现
系统架构,关注数据流、模块化、体系架构 - 设计与实现 结合架构完成关键设计及系统实现
结合可扩展性、灵活性等进行设计优化 - 用户体验 从用户角度思考应用效果,用户至上,体验优先,以用户为中心
Python第三方库安装
Python社区
- 14万个第三方库
- PyPI Python Package Index
- PSF维护的展示全球Python计算生态的主站
- 学会检索并利用PyPI,找到合适的第三方库开发程序

安装第三方库
1.pip安装方法 主要方法,适合99%以上情况,适合windows、Mac和linux等操作系统
常用的pip命令
D:\>pip install <第三方库名> - 安装指定的第三方库
D:\>pip install -U <第三方库名> - 使用-U标签更新已安装的指定第三方库
D:\>pip uninstall <第三方库名> -卸载指定的第三方库
D:\>pip download <第三方库名> -下载但不安装指定的第三方库
D:\>pip show <第三方库名> - 列出某个指定第三方库的详细信息
D:\>pip search <关键词> - 根据关键词在名称和介绍中搜索第三方库
D:\>pip list -列出当前系统已经安装的第三方库
2.集成安装方法 结合特定Python开发工具的批量安装
Anaconda
- 支持近800个第三方库
- 包含多个主流工具
- 适合数据计算领域开发
3.文件安装方法
- 某些第三方库pip下载后,需要编译后再安装
- 如果操作系统没有编译环境,则能下载但不能安装
- 可以直接下载编译后的版本进行安装
- 在UCI页面上搜索第三方库,下载对应版本编译好的文件,使用pip install <文件名>安装
Windows系统第三方库编译后的版本 UCI页面
Python计算生态概览
从数据处理到人工智能
- 数据表示 采用合适方式用程序表达数据
- 数据清理 数据归一化、数据转换、异常值处理
- 数据统计 数据的概要理解,数量、分布、中位数等
- 数据可视化 直观展示数据内涵的方式
- 数据挖掘 从数据分析获得知识,产生数据外的价值
- 人工智能 数据/语言/图像/视觉等方面深度分析与决策
1.Python库之数据分析
Numpy 表达N维数组的最基础库
- Python接口使用,C语言实现,计算速度优异
- Python数据分析及科学计算的基础库,支撑Pandas等
- 提供直接的矩阵运算、广播函数、线性代数等功能

Pandas Python数据分析高层次应用库
- 提供了简单易用的数据结构和数据分析工具
- 理解数据类型与索引的关系,操作索引即操作数据
- Python最主要的数据分析功能库,基于Numpy开发

Scipy 数学、科学和工程计算功能库
- 提供了一批数学算法及工程数据运算功能
- 类似Matlab,可用于如傅里叶变换、信号处理等应用
- Python最主要的科学计算功能库,基于Numpy开发

2.Python库之数据可视化
Matplotlib 高质量的二维数据可视化功能库
- 提供了超过100种数据可视化展示效果
- 通过
matplotlib.pyplot子库调用各可视化效果 - Python最主要的数据可视化功能库,基于Numpy开发
Seaborn 统计类数据可视化功能库
- 提供了一批高层次的统计类数据可视化展示效果
- 主要展示数据间分布、分类和线性关系等内容
- 基于Matplotlib开发,支持Numpy和Pandas

Mayavi 三维科学数据可视化功能库
- 提供了一批简单易用的3D科学计算数据可视化展示效果
- 目前版本是Mayavi2,三维可视化最主要的第三方库
- 支持Numpy、TVTK、Traits、Envisage等第三方库

3.Python库之文本
PyPDF2 用来处理pdf文件的工具集
- 提供了一批处理PDF文件的计算功能
- 支持获取信息、分隔、整合文件、加密解密等
- 完全Python语言实现,不需要额外依赖,功能稳定
from PyPDF2 import PdfFileReader, PdfFileMerger
merger = PdfFileMerger()
input1 = open("document1.pdf","rb")
input2 = open("document2.pdf","rb")
merger.append(fileobj = input1,pages = (0,3))
merger.merge(position = 2,fileodj = input2,pages = (0,1))
output = open("document-output.pdf","wb")
merger.write(output)
NLTK 自然语言文本处理第三方库
- 提供了一批简单易用的自然语言文本处理功能
- 支持语言文本分类、标记、语法句法、语义分析等
- 最优秀的Python自然语言处理库
from nltk.corpus import treebank #将自然语言文本转化为树形结构
t = treebank.parsed_sents('wsj_0001.mrg')[0]
t.draw()
Python-docx 创建或更新Microsoft Word文件的第三方库
- 提供创建或更新.doc .docx等文件的计算功能
- 增加并配置段落、图片、表格、文字等,功能全面
from docx import Document
document = Document()
document.add_heading('Document Title',0)
p = document.add_paragraph('A plain paragraph having some')
document.add_page_break()
document.save('demo.docx')
4.Python之机器学习
Scikit-learn 机器学习方法工具集
- 提供了一批统一化的机器学习方法功能接口
- 提供聚类、分类、回归、强化学习等计算功能
- 机器学习最基本且最优秀的Python第三方库

Tensorflow AlphaGo背后的机器学习计算框架
- 谷歌公司推动的开源机器学习框架
- 将数据流图作为基础,图节点代表运算,边代表张量
- 应用机器学习方法的一种方式,支撑谷歌人工智能应用
import tensorflow as tf
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
res=sess.run(result)
print('result:',res)

MXNet 基于神经网络的深度学习计算框架
- 提供可扩展的神经网络及深度学习计算功能
- 可用于自动驾驶、机器翻译、语音识别等众多领域
- Python最重要的深度学习计算框架
从Web解析到网络空间
5.Python库之网络爬虫
Requests 最友好的网络爬虫功能库
- 提供了简单易用的类HTTP协议网络爬虫协议
- 支持连接池、SSL、Cookies、HTTP(S)代理等
- Python最主要的页面级网络爬虫功能库

import requests
r = requests.get('https://api.github.com',auth=('user','pass'))
r.status_code
r.headers['content-type']
r.encoding
r.text
Scrapy 优秀的网络爬虫框架
- 提供了构建网络爬虫系统的框架功能,功能半成品
- 支持批量和定时网页爬取、提供数据处理流程等
- Python最主要且最专业的网络爬虫框架

pyspider 强大的Web页面爬取系统
- 提供了完整的网页爬取系统构建功能
- 支持数据库后端、消息队列、优先级、分布式架构等
- Python重要的网络爬虫类第三方库
6.Python库之Web信息提取
Beautiful Soup HTML和XML的解析库
- 提供了解析HTML和XML等Web信息的功能
- 又名beautifulsoup4或bs4,可以加载多种解析引擎
- 常与网络爬虫库搭配使用,如Scrapy、Requests等
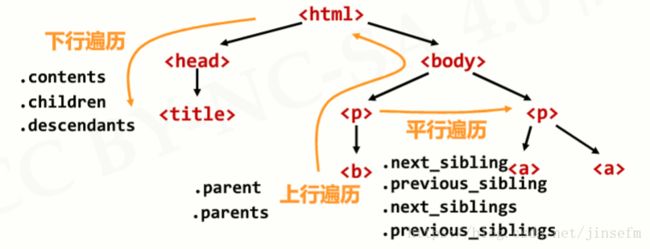
Re 正则表达式解析和处理功能库
- 提供了定义和解析正则表达式的一批通用功能
- 可用于各类场景,包括定点的Web信息提取
- Python最主要的标准库之一,无需安装

Python-Goose 提取文章类型Web页面的功能库
- 提供了对Web页面中文章信息、视频等元数据的提取功能
- 针对特定类型Web页面,应用覆盖面较广
- Python最主要的Web信息提取库
from goose import Goose
url = 'http://www.elmundo.es/elmundo/2012/10/28/espana1351388909.html'
g = Goose({'use_meta_language':False,'target_language':'es'})
article = g.extract(url=url)
article.cleaned_text[:150]
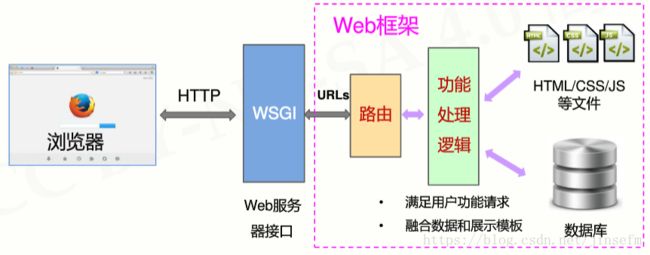
7.Python库之Web网站开发
Django 最流行的Web应用框架
- 提供了构建Web系统的基本应用框架
- MTV模式:模型(model)/模板(template)/视图(Views)
- Python 最重要的Web应用框架,略微复杂的应用框架
Pyramid 规模适中的Web应用框架
- 提供了简单方便构建Web系统的应用框架
- 不大不小,规模适中,适合快速构建并适度扩展类应用
- Python产品级Web应用框架,起步简单可扩展性好
from wsgiref.simple_server import make_server
from pyramid.config import Configurator
from pyramid.response import Response
def hello_world(request):
return Response('Hello World!')
if _name_ =='_main_':
with Configurator() as config:
config.add_route('hello','/')
config.add_view(hello_world,route_name='hello')
app = config.make_wsgi_app()
server = make_server('0.0.0.0',6543,app)
server.serve_forever()
Flask Web应用开发微框架
- 提供了最简单构建Web系统的应用框架
- 特点:简单、规模小、快速
- Django > Pyramid > Flask
from flask import Flask
app = Flask(_name_)
@app.route('/')
def hello_world():
return 'Hell0,World!'

8.Python库之网络应用开发
WeRoBot 微信公众号开发框架
- 提供了解析微信服务器消息及反馈消息的功能
- 建立微信机器人的重要技术手段
import werobot
robot = werobot.WeRoBot(token='tokenhere')
@robot.handler
def hello(message):
return 'Hello World!'#对微信每个消息反馈一个Hello World
aip 百度AI开发平台接口
- 提供了访问百度AI服务的Python功能接口
- 语音、人脸、OCR、NLP、知识图谱、图像搜索等领域
- Python百度AI应用的最主要方式

MyQR 二维码生成第三方库
- 提供了生成二维码的系列功能
- 基本二维码、艺术二维码和动态二维码

从人机交互到艺术设计
9.Python库之图形用户界面
PyQt5 Qt开发框架的Python接口
- 提供了创建Qt5程序的Python API接口
- Qt 是非常成熟的跨平台桌面应用开发系统,完备GUI
- 推荐的Python GUI开发第三库
wxPython 跨平台GUI开发框架
- 提供了专用于Python的跨平台GUI开发框架
- 理解数据类型与索引的关系,操作索引即操作数据
- Python最主要的数据分析功能库,基于Numpy开发
import wx
app = wx.App(False)
frame = wx.Frame(None,wx.ID_ANY,"Hello World")
frame.show(True)
app.MainLoop()

PyGObject 使用GTK+开发GUI的功能库
- 提供了整合GTK+、WebKitGTK+等库的功能
- GTK+:跨平台的一种用户图形界面GUI框架
- 实例:Anaconda采用该库构建GUI
import gi
gi.require_version("Gtk","3.0")
from gi.repository import Gtk
window = Gtk.Window(title="Hello World")
window.show()
window.connect("destory",Gtk.main_quit)
Gtk.main()
10.Python库之游戏开发
PyGame 简单的游戏开发功能库
- 提供了基于SDL的简单游戏开发功能及实现引擎
- 理解游戏对外部输入的响应机制及角色构建和交互机制
- Python游戏入门最主要的第三方库
Panda3D 开源、跨平台的3D渲染和游戏开发库
- 一个3D游戏引擎,提供Python和C++ 两种接口
- 支持很多先进特性:法线贴图、光泽贴图、卡通渲染等
- 由迪士尼和卡尼基梅隆大学共同开发

cocos2d 构建2D游戏和图形界面交互式应用的框架
- 提供了基于OpenGL的游戏开发图形渲染功能
- 支持GPU加速,采用树形结构分层管理游戏对象类型
- 适用于2D专业级游戏开发
11.Python库之虚拟现实
VR Zero 在树莓派上开发VR应用的Python库
- 提供大量与VR开发相关的功能
- 针对树莓派的VR开发库,支持设备小型化,配置简单化
- 非常适合初学者实践VR开发及应用

pyovr Oculus Rift的Python开发接口
- 针对Oculus VR设备的Python开发库
- 基于成熟的VR设备,提供全套文档,工业级应用设备
- Python+虚拟现实领域探索的一种思路

Vizard 基于Python的通用VR开发引擎
- 专业的企业级虚拟现实开发引擎
- 提供详细的官方文档
- 支持多种主流的VR硬件设备,具有一定的通用性
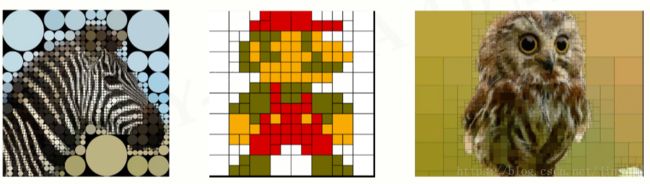
12.Python库之图形艺术
Quads 迭代的艺术
- 对图片进行四分迭代,形成像素风
- 可以生成动图或静图图像
- 简单易用,具有很高展示度
ascii_art ASCII 艺术库
- 将普通图片转为ASCII艺术风格
- 输出可以是纯文本或彩色文本
- 可采用图片格式输出

turtle 海龟绘图体系
