pytorch_optim_学习率调整策略
PyTorch学习率调整策略通过torch.optim.lr_scheduler接口实现。PyTorch提供的学习率调整策略分为三大类,分别是
a. 有序调整:等间隔调整(Step),按需调整学习率(MultiStep),指数衰减调整(Exponential)和 余弦退火CosineAnnealing。
b. 自适应调整:自适应调整学习率 ReduceLROnPlateau。
c. 自定义调整:自定义调整学习率 LambdaLR
torch.optim.lr_scheduler.LambdaLrlamda计算torch.optim.lr_scheduler.StepLR等间隔梯度下降torch.optim.lr_scheduler.MultiStepLR指定step_list梯度下降torch.optim.lr_scheduler.ExponentialLR指数下降torch.optim.lr_sheduler.CosineAnnealingLR余弦下降torch.optim.lr_scheduler.ReduceLROnPlateautorch.optim.lr_scheduler.CyclicLRlr_scheduler.CosineAnnealingWarmRestarts
# 准备环境
import torch
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision.models import AlexNet
import matplotlib.pyplot as plt
model = AlexNet(num_classes=2)
optimizer = optim.SGD(params=model.parameters(), lr=0.05)
torch.optim.lr_scheduler.LambdaLr
可以为不同参数组,设定不同的学习率
指定lamda匿名函数,lr=base_lr∗lmbda(self.last_epoch)
'''
参数 lr_lambda 给定一个lambda函数,将epoch作用于该函数,生成scale*init_lr,可以用来定义自己的lamda函数
Args:
optimizer (Optimizer): Wrapped optimizer.
lr_lambda (function or list): A function which computes a multiplicative factor given an integer parameter epoch, or a list of such functions, one for each group in optimizer.param_groups.
last_epoch (int): The index of last epoch. Default: -1.
'''
# epoch//30 * init_lr(0.05)
lambda1 = lambda epoch: epoch // 30
# lambda2 = lambda epoch: 0.95 ** epoch
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda= lambda1)
plt.figure()
x = list(range(100))
y = []
for epoch in range(100):
scheduler.step()
lr = scheduler.get_lr()
y.append(scheduler.get_lr()[0])
plt.plot(x, y)
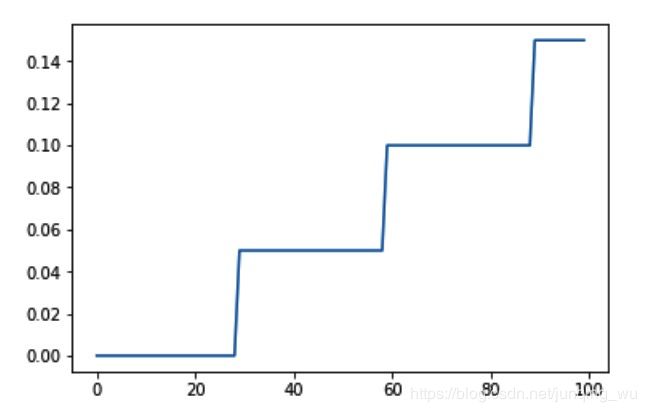
2. lr_scheduler.StepLR/MultiStepLR
两者都是阶梯递降学习率,其中StepLR 需要指定[step_size,gamma],step_size为下降频率,gamma为decay比率,而MultiStepLR 则指定一个step_list,每个指定的step则乘以 衰减系数,milestones=[30,60,80]
# milestones = [step for step in step_list] gamma 衰减系数
#scheduler = lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.5)
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[30,60,80],gamma= 0.5)
plt.figure()
x = list(range(100))
y = []
for epoch in range(100):
scheduler.step()
lr = scheduler.get_lr()
y.append(scheduler.get_lr()[0])
plt.plot(x, y)
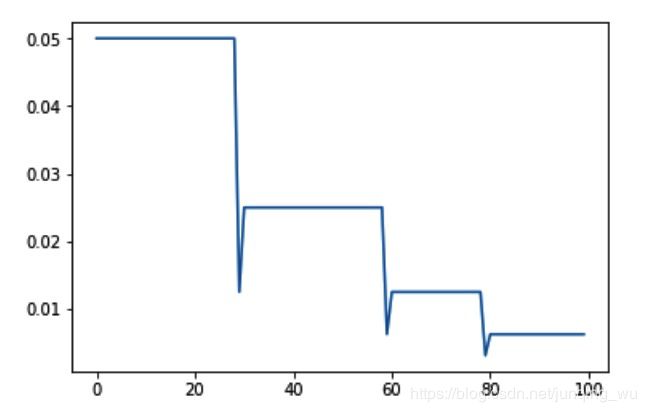
4 torch.optim.lr_scheduler.ExponentialLR
指数衰减 gamma 衰减系数
scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.8)
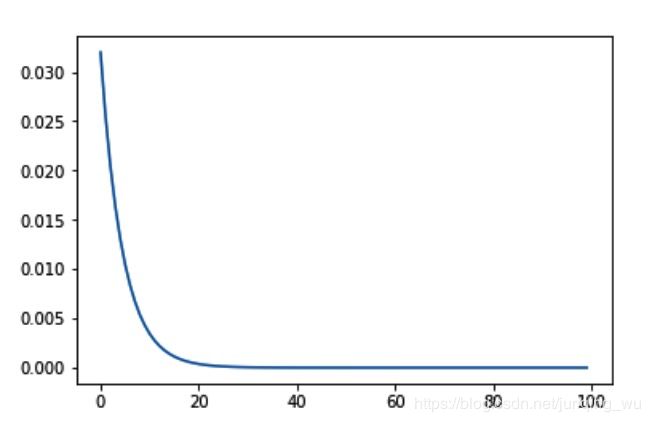
5. torch.optim.lr_sheduler.CosineAnnealingLR
Args:
T_max: 每次cosine的epoch数,既 cos函数 周期eta_min: 每个周期衰减的最小学习率,一般设置为1e-5之类的小学习率
scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=20,eta_min = 0)
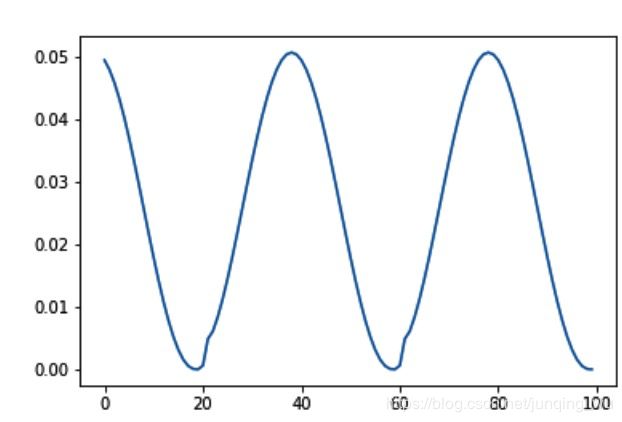
6. torch.optim.lr_scheduler.ReduceLROnPlateau
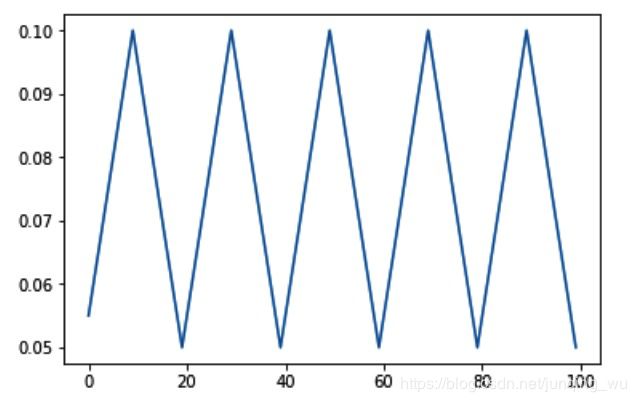
7.自定义调整学习率:CyclicLR https://arxiv.org/pdf/1506.01186.pdf

scheduler = lr_scheduler.CyclicLR(optimizer,base_lr=0.05,max_lr=0.1,step_size_up=10,step_size_down=10)
plt.figure()
x = list(range(100))
y = []
for epoch in range(100):
scheduler.step()
lr = scheduler.get_lr()
y.append(scheduler.get_lr()[0])
plt.plot(x, y)
lr_scheduler.CosineAnnealingWarmRestarts
https://arxiv.org/abs/1608.03983
动态调整cos周期的 温和的cos 学习调整函数
其实这个有很多变体,还有动态调整 base_lr ,类似于T0的调整策略,
base_lr = base_lr* lr_mullr_mul 为base_lr的调整步长
# https://arxiv.org/abs/1608.03983
# To 初始周期
# T_mult 每次循环 周期改变倍数 T_0 = T_0*T_mult
'''
def __init__(self, optimizer, T_0, T_mult=1, eta_min=0, last_epoch=-1):
if T_0 <= 0 or not isinstance(T_0, int):
raise ValueError("Expected positive integer T_0, but got {}".format(T_0))
if T_mult < 1 or not isinstance(T_mult, int):
raise ValueError("Expected integer T_mul >= 1, but got {}".format(T_mul))
self.T_0 = T_0
self.T_i = T_0
self.T_mult = T_mult
self.eta_min = eta_min
super(CosineAnnealingWarmRestarts, self).__init__(optimizer, last_epoch)
self.T_cur = last_epoch
'''
scheduler = lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=10,T_mult=2,eta_min=0)
plt.figure()
x = list(range(100))
y = []
for epoch in range(100):
scheduler.step()
lr = scheduler.get_lr()
y.append(scheduler.get_lr()[0])
plt.plot(x, y)
