场景文本检测(一)-可微分二值化在基于语义分割方法的场景文本检测中的应用
2020年AAAI的oral文章。
动机和Contributions
因为语义分割模型是pixel-level prediction,能够检测各种各样shape的文本区域,所以基于语义分割方法的场景文本检测目前非常流行。抛开语义分割网络,处理segmentation result相当关键了,目前现存的很多方法使用了不同的post-processing,但使用了类似的post-processing pipeline,即将pixel-level prediction通过设置固定阀值进行二值化,然后使用一些heuristic techniques(如 pixel clustering)进行pixel-level grouping操作转为bounding boxes/regions。
因为标准的二值化函数是不可微分的(分段常量函数),所以在论文中,作者提出了一个近似函数,实现了可微分的二值化。作者采用的pipeline是在segmentation network中插入一个binarization operation进行联合优化,在图片每个位置的阀值是能够自适应地被预测。
从作者的实验中得出传统的post-processing及其复杂且耗费大量时间,本文提出的Differentiable Binarization (DB)方法作为post-processing即能提高精度也能提高速度。同时也使得加入二值化后网络能够end-to-end training,相比于其他很多fast scene text detectors不能检测arbitrary shape,此论文提出的DB方法不仅能够更快检测而且能够检测任意shape文本、在multi-language text detection task上也非常鲁棒效果好。
现存方法
最近几年的场景文本检测方法大致可以分为regression-based方法和segmentation-based方法。它们意在解决场景文本的multi-scale和multi-shape、long text挑战。
regression-based方法的post-processing很简单,仅仅可能只需要非最大值抑制,但大部分这类方法不能够很好地处理不规则的shape文本,例如curve text。segmentation-based方法总是结合语义分割结果和post-processing algorithms去得到bounding boxes,所以正如上述动机和Contributions小节所述,segmentation-based方法与regression-based方法的优缺点正好相反。
Methodology
Pipeline
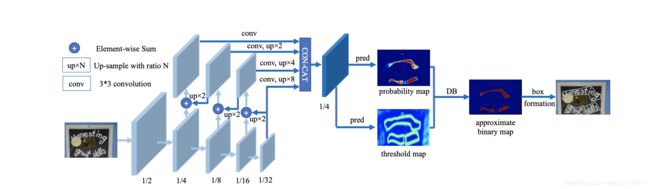
整体架构就是在pyramid network产生的features基础上增加了convolution operation和deconvolution操作来预测probability map和threshold map,然后通过DB算法生成approximate binary map。
DB
这是文中最重要的module,有了它就能够预测adaptively threshold,能够将二值化嵌入segmentation network中进行共同训练。公式如下:
B ^ i , j = 1 1 + e − k ( P i . j − T i , j ) \hat{B}_{i,j}=\frac{1}{1+e^{-k(P_{i.j}-T_{i,j})}} B^i,j=1+e−k(Pi.j−Ti,j)1
其中 k k k被设置为50。 P i , j P_{i,j} Pi,j和 T i , j T_{i,j} Ti,j分别是probability map prediction和threshold map prediction, B ^ i , j \hat{B}_{i,j} B^i,j是approximate binary map prediction。标准的二值化和DB函数的比较如下图(更正一下蓝色为DB)
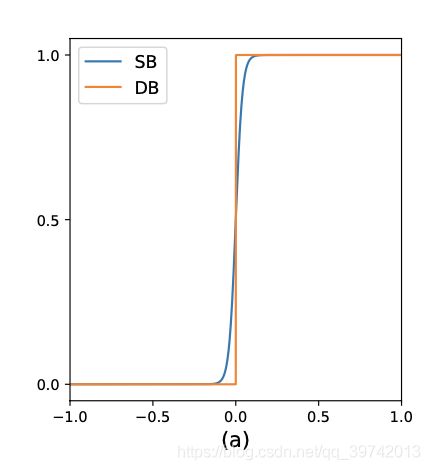
可见几乎一致,DB函数取值范围为 ( 0 , 1 ) (0,1) (0,1),且DB还可微分。
为什么DB能够提高表现?
文中作者以梯度的后向传播解释。用binary cross-entropy loss作为例子,正负类的损失分别可表示为如下(实质上下图式子就是论文提出的框架的approximate binary map的损失函数表达式)
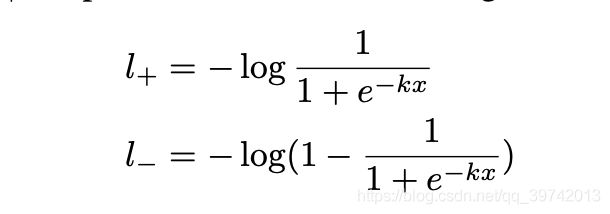
其中 x = P i , j − T i , j x=P_{i,j}-T_{i,j} x=Pi,j−Ti,j,损失函数的目的是:正类label对应的实例的 x x x结果应当越大越好即learned probability大于learned threshold;负类label对应的实例则相反。上述式子对 x x x求导可得到如下式子
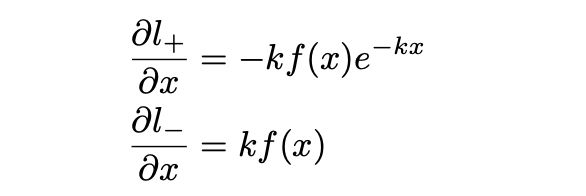
其中 f ( x ) = 1 1 + e − k x f(x)=\frac{1}{1+e^{-kx}} f(x)=1+e−kx1,导数的图像如下(上图为正类损失函数导数)

从导数式子和图像我们可以观察到DB算法的优点:
- 随着k的增大,对于正类,当probability小于threshold时,梯度值被加强,而对于probability大于threshold时,梯度值被减弱。对于负类,当probability大于threshold时,梯度值被加强,而对于probability小于threshold时,梯度值被减弱。
- 由导数式子可知,正负类的优化是伴随着不同scale的,差了一个 e − k x e^{-kx} e−kx,当false positive那么正类梯度相对负类更大,而true positive反之。
- 在分类结果很糟糕时,梯度显著增大,有利于优化;
在背景和前景之间的区域 P P P的梯度会被 T T T缩放和影响。
Traing period & inference period
在训练阶段,分别对三个map进行监督训练。probability map的label标注跟随PSENet论文中的处理,使用了shrunk polygon;approximate binary map使用了probability map的相同标注;threshold map 需要对dilated polygon的区域根据1减归一化像素到original polygon最近segment的距离进行标注(代码实现中threshold mask是将dilated polygon的区域内像素标注为1,其余为0,所以threshold map的标注可以简化为在dilated polygon最小包围盒中进行。对于出现dilated polygon相交的情况,就取交集中的点到不同original polygon最小归一化距离作为标注,并不是最小实际距离),最后将threshold map标注值调整到[0.3,0.7]。经过作者的ablation实验结果表明对threshold map进行监督能够产生更好的结果。如果不对threshold map监督训练,习得的threshold可视化出来会高亮显示text border region(如下图左上为原图,右上为probability map,左下为无监督的threshold图,右下为有监督的threshold图),这说明border-like threshold map能够使得最终结果更好,这也给出了如何标注threshold map label。在训练阶段并不需要生成boxes。(PS:详细实验细节包括学习率、finetune、augmentation等请阅读原论文)

在测试阶段,经过作者实验,直接使用probability map和使用approximate binary map效果一样,为了减少耗费去掉了threshold分支,直接使用probability map。形成boxes通过三个步骤:设置0.2的固定threshold二值化probability map(或者approximate binary map);从二值图里面获得shrunk text regions;将shrunk regions进行放大。
Optimization
损失函数是三个map losses的加权和,如下
L = L s + L b + 10 ∗ L t L=L_s+L_b+10*L_t L=Ls+Lb+10∗Lt
其中 L s , L b , L t L_s,L_b,L_t Ls,Lb,Lt分别是loss for the probability map,loss for the binary map,loss for the threshold。常量参数则是根据实验得到的。
L s , L b L_s,L_b Ls,Lb是 binary cross-entropy (BCE) loss。为了解决positive和negative不均横问题,以positive:negative=1:3比例进行sampling the hard negatives,得到如下loss表达式
L s = L b = − [ ∑ i ∈ S l y i log x i + ( 1 − y i ) log ( 1 − x i ) ] L_s=L_b=-[\sum_{i\in S_l}y_i\log x_i+(1-y_i)\log(1-x_i)] Ls=Lb=−[i∈Sl∑yilogxi+(1−yi)log(1−xi)]
S l S_l Sl就为采样后的集合(base on pixel because of segmentation-based method)。
对于 L t L_t Lt则采用了L1 distances的和形式,如下
L t = ∑ i ∈ R d ∣ y i − x i ∣ L_t=\sum_{i \in R_d}|y_i-x_i| Lt=i∈Rd∑∣yi−xi∣
其中 R d R_d Rd是在dilated text polygon region里面的像素索引集合。
Deformable convolution
图片中可能因为尺寸、姿态、视角、部分变形等导致Geometric variations,在目标检测领域是个很有挑战性的任务,该Deformable convolution(v1&v2)均是在解决这样的问题。对于场景文本检测领域来说,它能够提供灵活的感受野,有利于解决场景文本中的极端的aspect ratios text instances。
从最后的实验结果来看,deformable convolution在损失一点速度的情况下比较大地提高了最终模型的表现。
总结
在模型训练时作者使用了保持aspect-ratio且固定尺寸640×640进行训练,而测试时则固定一边为某一个长度,同时保持aspect-ratio,从结果来看,input image的size会影响实验结果,越小效果越差,速度会越快,需要trade-off,可见对size还是很敏感的。同时,在文中作者也提到了proposed method依然不能解决segmentation-based method方法共有的问题,那就是’text in center region of another text’不能很好处理。
包含DB module的architecture即保留或提高了速度且同时提高了精度。实质上伴随着threshold map supervision的DB架构最终是使得probability map更加强和鲁棒。
Ref
- Liao, M.; etc. 2020. Real-time Scene Text Detection with Differentiable Binarization. In Proc. AAAI.
- heuristic techniques. https://en.wikipedia.org/wiki/Heuristic