Oracle 基础知识
Oracle基础知识
-
Oracle是关系型的数据库,支持多用户、大事务量的事务处理。 Oracle基于客户端、服务器端。分布式、可移植。
-
表空间是数据库中最大的逻辑单位,一个Oracle数据库至少包含一个表空间,就是名为System的系统空间。
每个表空间是由一个或多个数据文件组成的,一个数据文件只能与一个表空间相关联。表空间的大小等于构成该表空间的所有数据文件大小之和。 -
Oracle默认用户,SYS超级管理员,SYSTEM普通管理员,SCOTT普通用户(很多权限无,需要SYSTEM给)。
-
数据定义语言(DDL):create alter drop
数据操纵语言(DML):insert select detele update truncate
事务控制语言(TCL):commit rollback savepoint
数据控制语言(DCL):grant revoke -
VACHAR(10); //字符串,存5个中文
NUMBER(7,2); //5个整数位,两个小数位
//创建用户名 密码
create user mar identified by mar;
//给用户修改密码
alter user mar identified by mmm;
//删除用户。如果用户创建了表,用cascade级联删除。
drop user mar;
drop user mar cascade;
//mar 登录,无连接权限session,给mar链接的权限,撤销连接的权限.
grant connect to mar;
revoke connect from mar;
//查询部分字段,且支持字段运算
select sal*12,ename from emp; //(员工姓名和一年工资)
//字符串的拼接
select '编号是'||empno||'工资是'||sal||'的员工姓名是'||ename from emp;
//重复列的清除(DISTINCT)
select distinct job,deptno from emp
带条件的查询
//不等于的两种写法
select *from emp where sal!=3000;
select *from emp where sal<>3000;
//查询子段位为空 或 不为空
select * from emp where comm is not null;
select * from emp where comm is null;
//查询 与或非
select * from emp where sal>1500 or comm is not null;
select * from emp where not (sal>1500 and comm is not null);
// in 替代 or, between and 替代 and.
select * from emp where empno in (7369,7521,7839);
select * from emp where sal between 1500 and 3000;
//对结果进行排序(默认升序ASC,降序DESC)
select * from emp order by sal ASC;
select ename from emp ORDER BY sal DESC,hiredate ASC;
模糊查询like,查询百分号%
//like 模糊查询(’_‘表示单个长度,’%'表示若任意长度)
select * from emp where ename like'_O%';
select * from emp where ename like'%O%';
select * from emp where ename like '%\%%' escape '\';
select * from emp where ename like '%:%%' escape ':';
三种给字段取别名的方式
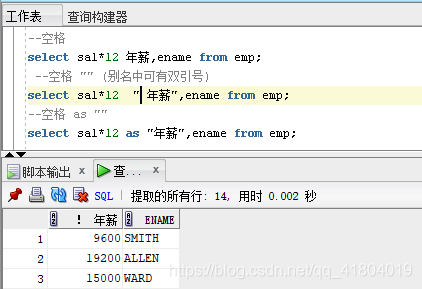
单行函数
伪表 dual ( sys用户下,一个字段。返回一行一列,仅供查询使用)
select upper('hello') 大写 from dual;
select lower('abc') 小写 from dual;
dual中不存在ename,必须使用emp表
select ename,lower(ename) from emp;
select * from emp where ename=upper('smith');
INITCAP()函数,首字母大写。
select ename,initcap(ename) from emp;
select initcap('i love you') from dual;
------------------------------
I Love You
CONCAT(’ ‘,’ ')函数,拼接。
select concat('hello','world') from dual;
select concat('hello',ename) from emp;
---------------------------
helloworld
helloSMITH
可以套用
select initcap(concat('hello',' world')) from emp;
--------------------------
Hello World
substr(‘ ’,起始位置,长度)截取字符串
JAVA是 substring(’ ',0,终止位置) )
select substr(ename,1,1) from emp;
//从后面取三个
select substr(ename,-3,3) from emp;
length() 字符串的长度
lengthb()字节数,一个中文占两个字节
select ename,length(ename),lengthb(ename) from emp;
replace(列或表达式,原始内容,替换内容)
select replace('hello','o','wz')from dual;
select ename,replace(ename,'A','a')from emp;
--------------------------------
hellwz
WARD WaRD
instr() 查找位置(起始位从1开始)
select instr('this is a book','s')from dual;
-----------------------
4
lpad() 左补齐,rpad()右补齐
select lpad('i love you',15,'*'),rpad('ilove you',15,'*') from dual;
--------------------------
*****i love you ilove you******
若位置不够,一律从字符串右侧砍掉
```sql
select lpad('i love you',5,'*'),rpad('ilove you',1,'*') from dual;
--------------------------
i lov i
round() 四舍五入
```sql
select round(48.8) from dual;
select round(48.4450032434,2) from dual; //(取两位小数)
---------------------
49
48.45
trunc 直接截取
select trunc(48.48) from dual;
select trunc(48.4899999,3) from dual;
---------------
48
48.489
select round(123.458,-1) from dual; //个位四舍五入
select trunc(199.358.-1) from dual; //不四舍五入
-------------------------
120
190
mod(10,3) 取模。若除数为0,返回被除数。
select mod(10,3) from dual;
select mod(10,0) from dual;
----------------------
1
10
sysdate 日期,显示当前时间
select sysdate from dual;
--------------------
08-4月 -20
//日期-数字=日期
select sysdate-10 from dual;
//日期+数字=日期
select sysdate+10 from dual;
//日期-日期=数字(天数)
select sysdate-hiredate "入职天数" from emp
MONTHS_BETWEEN() 精确计算月份
select MONTHS_BETWEEN(sysdate,hiredate) from emp;
ADD_MONTHS(SYSDATE,月份) 加上指定月份后的日期
select ADD_MONTHS(SYSDATE,2) FROM DUAL;
----------------
08-6月 -20
NEXT_DAY(SYSDATE,下一个‘星期一’) 返回下个日期。
select next_day(sysdate,1) from dual;
select next_day(sysdate,'星期日') from dual;
last_day(sysdate) 返回当前月的最后一天
select last_day(sysdate) from dual;
//查询每月倒数第三天入职的员工信息
select * from emp where hiredate=last_day(hiredate)-2;
转换函数:to_char to_number to_date
TO_CHAR() 将内容转换为字符串类型
SELECT HIREDATE,TO_CHAR(HIREDATE,'YYYY')年,
TO_CHAR(HIREDATE,'MM') 月,
TO_CHAR(HIREDATE,'DD') 日 FROM EMP;
//fm去掉前面的0
TO_CHAR(HIREDATE,'fmMM') 月;
SELECT TO_CHAR('1991-1-1','YYYY-MM:DD hh:mi:ss') from dual;
SELECT TO_CHAR(12345678,'$999,999,999') from dual;
--------------------------
$12,345,678
//做一个查询,产生下面的结果
king,17-jun-87,Monday,the twenty-first of December,1987
SELECT ENAME "LAST_NAME",HIREDATE "HIRE_DATE",TO_CHAR(HIREDATE,'DAY ",THE" DDSPTH"OF" MONTH ","YYYY') FROM EMP;
day----将日期转换为星期几
ddsph-------转换为英文的几月几日
month-------将日期转换为月份
TO_NUMBER() 将内容转换为数字
select to_number('3')+to_number('2') from dual;
select '3'+'2' from dual;
---------------------
结果都是5
TO_DATE() 将内容转换为日期
select to_date('2000-1-1','yyyy-mm-dd') from dual;
NVL(a,b)函数 若a时空值nul,则l变为 b。
在oracle中 ’ ’ 和 null 表示空。
//空null和任何值加,结果为null
select ename,sal+comm from emp;
select ''+3 from emp;
-------------------------------
null
//如果为空,则赋值为0
select ename,sal+nvl(comm,0) from emp;
日期比较
select * from emo where hiredate>to_date('1981-1-1','yyyy-mm-dd');
select * from emo where hiredate>'1-1月-81';
decode
decode(字段或表达式,0,‘content 0’,1’content 1’,2,‘content 2’,‘content n’);
select decode(10,0,‘content 0’,1’content 1’,‘content n’) from dual;
decode 面试题

select decode(yuwen/10,8,'优秀',9,'优秀',10,'优秀',6,'及格',7,'及格','不及格') "语文",
decode(shuxue/10,8,'优秀',9,'优秀',10,'优秀',6,'及格',7,'及格','不及格') "数学",
decode(yingyu/10,8,'优秀',9,'优秀',10,'优秀',6,'及格',7,'及格','不及格') "英语" from student;
case when then when then else end
SELECT CASE WHEN yuwen>=80 THEN '优秀'
WHEN yuwen<60 THEN '不及格'
else '及格' END 语文,
CASE WHEN yingyu>=80 THEN '优秀'
WHEN yingyu<60 THEN '不及格'
else '及格' END 英语 FROM student;
等价连接
SELECT * FROM emp,dept WHERE emp.deptno=dept.deptno;
表的别名
SELECT empno FROM emp e,dept d where e.deptno=d.deptno;
–要求查询出每个雇员的编号,姓名,工作,雇员的直接上级领导的编号和姓名。
select e.empno 员工编号,e.ename 员工姓名,e.job 员工职位,p.empno 领导编号,p.ename 领导姓名
from emp e,emp p where e.mgr=p.empno;
不等价连接
–查询员工姓名、工资及等级
select e.ename,e.sal.s.grade from emp e,salgrads where e s.sal between s.losal and s.hisal.
内连接 同时满足条件的值查出来
外连接 :
左连接:同时满足条件的值查出来,左表的值也查出来。
- JAVA 语法(+)出现在等号的右边
select e.ename,p.ename from emp e,emp p where e.mgr=p.empno(+)
- 1999语法
select * from emp e left outer JOIN dept d ON e.deptno=d.deptno;
2.右连接:同时满足条件的值查出来,右表的值也查出来。
- JAVA 语法(+)出现在等号的左边
select e.ename,p.ename from emp e,emp p where e.mgr(+)=p.empno
- 1999语法
select * from emp e tight outer JOIN dept d ON e.deptno=d.deptno;
3.全连接:同时满足条件的值查出来,左右表中不满足的值也查出来。
- 1999语法
select * from emp e full outer JOIN dept d ON e.deptno=d.deptno;
1999语法
交叉连接“CROSS JOIN”,产生笛卡尔积。
select * from emp CROSS JOIN dept;
自然连接 “NATURALJOIN”,自动进行关联字段的匹配。
select * from emp NATURAL JOIN dept;
select * from emp JOIN dept USING deptno;
select * from emp e JOIN dept d ON e.deptno=d.deptno;
组函数:COUNT( ) , SUM( ) , MAX( ) , MIN( ) , AVG( )
COUNT( ) 记录的行数,都可以去掉空值
SELECT COUNT(*) FROM EMP;
SELECT COUNT(EMPNO) FROM EMP;
没有group by , select后面出现组函数,后面不允许有其他字段
分组统计:当一个表中出现了重复内容的时候才会考虑到分组
分组统计的简单原则:只有一列上存在重复的内容,就可以考虑到分组
SELECT count(*) 雇员数量,d.deptno 部门编号,d.dname 部门名称,MAX(SAL),MIN(SAL),AVG(SAL),SUM(SAL)
from emp e,dept d
WHERE e.deptno=d.deptno
GROUP by d.dname,d.deptno;
组函数的过滤要用 having
having 后必须是组函数,不能使用别名
SELECT AVG(SAL) FROM EMP GROUP BY DEPTNO HAVING AVG(SAL)>2000 ;
当组函数嵌套,select 后不能加分组条件
//错误
select max(avg(sal)) from emp e,dept d where e.deptno=d.deptno group by dname;
笔试题:横向输出

select sum(count(*)) total,
sum(decode(to_char(hiredate,'yyyy'),1980,1,0)) "1980",
sum(decode(to_char(hiredate,'yyyy'),1981,1,0)) "1981",
sum(decode(to_char(hiredate,'yyyy'),1982,1,0)) "1982",
sum(decode(to_char(hiredate,'yyyy'),1987,1,0)) "1987"
from emp ;
Select count(*) total ,
sum(case to_char(hiredate,'yyyy') when '1980' then 1 End) "1980",
sum(case to_char(hiredate,'yyyy') when '1981' then 1 End) "1981",
sum(case to_char(hiredate,'yyyy') when '1982' then 1 End)"1982",
sum(Case to_char(hiredate,'yyyy') when '1987' then 1 End)"1987"
from emp
子查询
子查询:在一个查询中包含另外一个嵌套的查询,用()将查询语句括起来
select * from emp where sal > (select sal from emp where empno=7521);
要求查询出部门中员工数里高于各部门平均人数的部门编号及员工的数量
select count(*),deptno from emp group by deptno having count(*)
>select avg(count(*)) from emp group by deptno;
子查询可以放在 from 后面
select e.* from dept,(select deptno,count(*),avg(sal) from emp
group by deptno) e where e.deptno=dept.deptno;
ORACLE数据类型
常用的伪列 ROWID 和 ROWNUM
ROWID :(自动生成)是表中行的存储地址,改地址可以唯一的标识数据库中的一行,ROWID的值不能重复。
ROWNUM:用来查询返回的结果集中行的序号,可以用它限制查询返回的行数。
伪列只能查询,不能查询、更新、删除,oracle独有。
rownum查询必须包含第一行
//错误
select * from emp where rownum>=5 and rownum<=10;
薪资倒序排序取出5-10
select * from(select e.*,rownum rn from (select * from emp order by sal DESC) e where rownum<=10) where rn>5;
多行子查询
多行子查询用 in (返回的值不是一个)
select * from emp where empno in (select distinct mgr from emp);
ANY操作符
"> ANY,大于返回结果最小值
< ANY 小于返回结果最大值,(比任意一个结果小即可)
=ANY,与 in 相同
ALL操作符
=ALL 无意义
集合操作符
UNION 去掉重复值
UNION ALL 不去掉重复值
INTERSECT 取交集
MINUS 叉集 (前面减后面)
select deptno from dept union all select deptno from emp;
select deptno from emp minus select deptno from dept;
select empno from emp minus select mgr from emp;
数据操作及事务控制
create 复制
create table emp1 as select * from emp; //完全复制
create table emp2 as select empno,ename,hiredate from emp; //部分复制
create table emp3 as select * from emp where 1=2; //有字段,空表
insert 插入的时候要提交事务,如果不提交,操作的是缓存。(在当前连接能看到效果)
insert into dept1 values(1,'财务','NEWYORK') ; //完全插入
insert into emp1 values(insert into emp1 values(1001,'tom','sales',null.to_date('1999-08-13',YYYY-MM-DD),1002,100,10);
insert into emp1 select * from emp where sal>3000; //查询表的记录插入
整数部分精度超过不能插入,小数位超出精度可以插入 number(7,2);
insert into emp1 values(1001,'tom','sales',null.sysdate,100223.56,100,10);
不完全插入
insert into emp1 (empno,ename,sal) values (1002,'merry',2000)
update 修改数据,关键字 set (根据主键,修改其他的值)
update emp1 set comm=null,mgr=null where empno in (7369,8899,7788);
detele 删除数据,关键字 from (需要提交事务,DDL语句)
delete from emp1 where empno=7369;
truncate 截断 (删除表的所有行,不需要提交事务,DML语句)
truncate table emp3;
oracle数据类型
表的创建:创建表时,必须为各个列指定数据类型
oracle数据类型:字符、数值、日期时间、RAW/LONG RAW、LOB
- NUMBER(m) , m位长度数字。
- VARCHAR2() ,可变长度。数据类型的大小在1~4000个长度中。
- CHAR数据类型,固定长度的字符串。 long类型最多能存储2GB。
create table t1(tname char(10),tlog varchar2(10));
insert into t1 values('a','a');
select length(tname),length(tlog) from t1
-----------------------------
10,1
日期时间数据类型存储日期和时间值,DATE–最高精确到秒
TIMESTAMP,秒值精确到小数点后六位
存储图片 CLOB,BLOB,BFILE
快速建立表,约束不会同步。
创建表,默认性别为男
create table person (pid NUMBER(4),name VARCHAR2(10),birthday DATE,sex VARCHAR2(4) default '男');
insert into person(pid,name,birthday) values(11,'haha',sysdate)
显示表的结构 DESC
DESC person;
-------- -- ------------
名称 空值 类型
PID NUMBER(4)
NAME VARCHAR2(10)
BIRTHDAY DATE
SEX VARCHAR2(4)
表的修改
alter 修改,将表增加两个列
alter table person add(age number(3) default 10,address varchar2(50));
-表里数据10000条,改一个字段的值,效率最高的方法:删除字段,加default
// 修改长度和默认值
alter table person modify (sex varchar2(3),age number(3) default 25);
//已存数据,不能更改数据类型。(必须清空数据)
alter table person modify(sex number(5));
删除列。alter table 表明 drop column 列名
alter table person drop column salary;
约束
主键约束(主码):唯一性,非空性。三种方式
create table person (pid number(4) primary key);
----------------------
create table person (pid number(4) ,constraint pk_pid(约束名字) primary key(pid) );
在外面添加约束
alter table emp1 add constraint pk_emono primary key(empno);
两列同时重复,不可以。单个重复可以
constraint pk_grade primary key(sporterid,itemid);
唯一约束:字段不可以有重复的值。可以为空,关键字UNIQUE。可以null,null可以重复,同上
create table person (pid number(4) unique);
非空约束:字段不可以为空。只能在列的后面定义。(特殊)
create table person (pid number(4) not null);
检查约束:对记录进行限定
create table person (age number(3) check(age between 1 and 100),
sex varchar2(4) defaullt '男' check (sex in('男','女') ) ;
-----------
create table person (age number(3) ,sex varchar2(4) default '男' ,
constraint ck_age check(age between 1 and 100);
constraint ck_sex check (sex in('男','女'))) ;
外键约束:产生于两个表之间的限定。先有主键才有外键
alter table emp3 add constraint pk_3 foreign key(deptno)
references dept1(deptno); //指向另一张表的主键
dept1是主表,emp3是从表。
主表的数据被从表引用,数据不能删,如下。
delete from dept1 where deptno=10;
删除外键
alter table emp3 drop constraint pk_3;
此时如果删除主表数据,从表对应数据更改为null.
alter table emp3 add constraint pk_3 foreign key(deptno)
references dept1(deptno) on delete set null;
cascade 级联删除
alter table emp3 add constraint pk_3 foreign key(deptno)
references dept1(deptno) on delete cascade;
表和表的关系
一对一:用的少 (主贴 / 回帖)
一对多:部门表 主表,员工表 从表。主外键关联,多里面的外键指向1里面的主键
多对一:员工表 从表,部门表 主表。主外键关联,多里面的外键指向1里面的主键
多对多:中间表 两个外键分别指向两张表的主键
笔试题
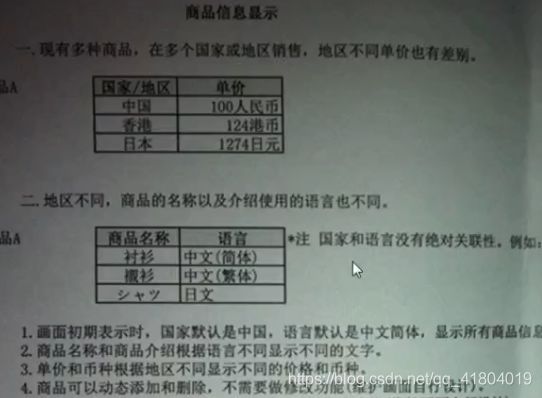
建表语句
create table Goods ( gid number(5) primary key);
create table country ( cid number(5) primary key,cname varchar2(10),bizhong varchar2(10));
create table language ( lid number(10) primary key,lname varchar2(10));
create table G_c (cid number(5),gid number(5),price number(10,2),
constraint fk_cid foreign key(cid) references country(cid) on delete cascade,
constraint fk_gid foreign key(gid) references Goods(gid) on delete cascade);
create table G_l (lid number(10),gid number(5),gname varchar2(10),ginfo varchar2(10),
constraint fk_lid foreign key(lid) references language(lid) on delete cascade,
constraint fk_gid2 foreign key(gid) references Goods(gid) on delete cascade);
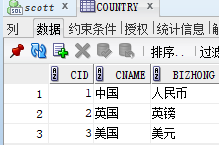
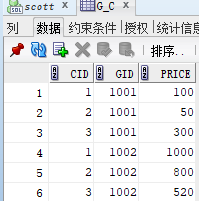



数据库对象
- 最基本的数据库对象是表。
- 数据库对象包括:同义词、序列、视图、索引
- 同义词:现有对象的一个别名。dual ,sys用户下的表,同义词。
公用同义词–可被所有的数据库用户访问。
私有同义词–只能在其模式内访问 且 不能与当前模式的对象同名。(无意义,自己的表) //若 system 想看 scott
的表,产生一个公用的同义词 ( 简化 sql )
select * from scott.emp;
简化了sql语句
create public synonym emp for scott.emp;
只有管理员能创建同义词,除非管理员grant用户权限
grant dba to scott; dba仅次于system权限
公有同义词和私有存储位置不一样。
创建和删除同义词
create or replace public synonym ems for scott.emp;
drop synonym ems;
drop public synonym ems;
序列:升序或降序。
nextval 返回下一个值
currval 返回当前值
//创建一个序列
create sequence sql;
select sql.nextval from dual;
//先启动,再调用当前值
select sql.currval from dual;
创建和使用序列
create sequence 名字
start with 10 --起始值
increment by 10 --增量(步长) //也可为负值,递减
maxvalue 2000
minvalue 10 --最小值,起始值
nocycle --不循环
cache 10 --缓存5个,效率高
insert into dept1 values (sql.nextval,'bb','bb'); ----序列名.nextval
更改和删除序列
alter sequence dept_id_seq maxvalue 2000 cycle;
drop sequence dept_id_seq;
视图 :虚拟表,提供另外一种级别的表安全性,隐藏了数据的复杂性。
创建视图依据的表是基表
创建视图
此时delete from v_emp1会删除基表
create view v_emp1 as select empno,ename,sal from emp1;
select * from v_emp1;
此时无法对只读视图进行DML操作
create view v_emp1 as select empno,ename,sal from emp1 with read only;
不允许改创建视图的条件
不允许改创建视图的条件
create or replace view v_emp2 as select * from emp1 where sal>2000 with check option;
select * from v_emp2;
update v_emp2 set sal=3000 where empno=7566;
update v_emp2 set sal=1000 where empno=7566;-----错误
强制创建一个不存在基表的视图
create or replace force view v_emp3 as select * from ss;
视图的用法:把复杂的语句变成视图
create view v_lianxi as
select g.gid,gname,ginfo,gc.price,c.bizhong,c.cname,l.lname
from goods g,language l,country c,g_c gc,g_l gl
where g.gid =gc.gid
and g.gid=gl.gid
and l.lid=gl.lid
and c.cid=gc.cid with read only;
-----------------
select * from v_lianxi where cname='英国' and lname='简体中文';
索引:类似于目录,查询方便、快捷。
索引的类型:唯一索引、组合索引、反向键索引、位图索引、基于函数的索引
建立标准索引,为列添加索引。主键和unique自动加上索引
create index index_ename on emp1(ename);
create unique index index_ename on emp1(ename); --唯一索引
重建索引,修改索引
alter index index_ename rebuild;
组合索引,在表的多个列上创建索引。如果where子句引用上包含的大多数列,则提高查询效率。
create index in_salcommename on emp3(sal,comm,ename);
反向键索引,建立在连续增长的列上,使数据均匀地分在整个索引上。
create index in_empno on emp3(empno) reverse;
位图索引适合创建在低基数列上。(数据少)。XE版oracle不支持位图索引
create bitmap index bit_sex on emp3(sex);
基于函数的索引
create index in_name on person(upper(name))
数据库的三范式是什么?(数据库的设计遵循什么规范)
第一范式:强调的是列的原子性,及数据库表的每一项都是不可分割的原子数据项
第二范式:要求实体的属性完全依赖于主关键字,所谓完全依赖是指不能仅依赖主关键字一部分的属性。(解决多对多的关系)
第三范式:任何非主属性不依赖于其他非主属性。(解决一对多)
ACID是什么?事务的特性?
Atomicity原子性:事务不可分割
Consistency一致性:
Isolation隔离性:并发的事物不会相互影响
Durability持久性:事务处理结束后,对事物的修改是永久的
oracle 导出 cmd命令:exp scott/scott@orcl file=c:\scott.dmp owner=scott
oracle 导入 cmd命令:imp scott/scott@orcl file=c:\scott.dmp full=y ignore=y
MYSQL
MYSQL实现分页
0+1的位置 start 5 几条 (cur-1)*size size
SELECT * FROM EMP LIMIT 5,2 ;
分页查询处g_detail表中姓李的记录,每页五条,取第二页的结果
SELECT * FROM emp WHERE ename LIKE 'M%' LIMIT 5,5;
连续插多行
insert into 'dept' ('deptno','dname','loc')
values(1,'11','11'),(2,'11','22');
mysql有自动增长列
- oracle用子查询rownum分页,MySQL用limit
- oracle日期格式,MySQL日期支持字符串