https://blog.csdn.net/qq_37334135/article/details/78359506
Azkaban是由Linkedin开源的一个批量工作流任务调度器。用于在一个工作流内以一个特定的顺序运行一组工作和流程。
Azkaban Web服务器
azkaban-web-server-2.5.0.tar.gz
Azkaban执行服务器
azkaban-executor-server-2.5.0.tar.gz
目前azkaban只支持 mysql,需安装mysql服务器
将安装文件上传到集群,最好上传到安装 hive、sqoop的机器上,方便命令的执行
Azkaban主要的组成:
- 关系型数据库——MySQL
- AzkabanWebServer
- AzkabanExcutorServer
使用MySQL存储状态,AzkabanWebServer和AzkabanExcutorServer访问数据库。
AzkabanWebServer主要管理者Azkaban,主要进行了项目管理、身份验证、调度和监控执行。并且为用户界面。
使用方法:
登录Azkaban环境登录账号和密码之后将会看到一个项目列表界面。
点击创建项目就可以创建安新的项目,创建名称可以第一次命名之后不能再次改变,项目描述可以改变。创建好项目之后,就会进入项目界面,如果没有相关按钮,则说明用户没有相关权限,现在为一个空项目。
上传项目,点击Upload就可以上传项目,项目可以上zip文件,zip里需要包含*.job文件和其他需要运行的job。Job名称必须唯一。
创建流程:
Job为一条在Azkaban中运行的进程。这些Job可以依赖于其他Job。一组Job和他们的所依赖构成了Flow
先创建job文件,文件后缀为*.job。
https://my.oschina.net/u/2000675/blog/792903
https://blog.csdn.net/hblfyla/article/details/74384915
Command类型单一job示例
1、创建job描述文件
vi command.job
#command.job
type=command
command=echo 'hello'
2、将job资源文件打包成zip文件
zip command.job
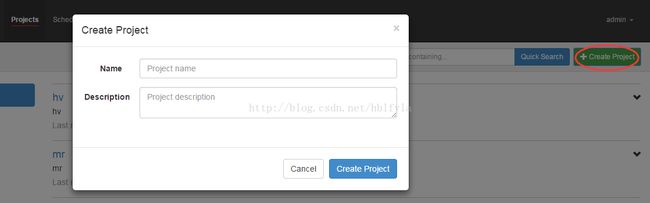
3、通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
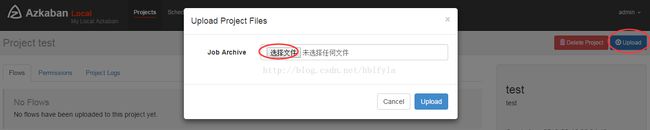
上传zip包
4、启动执行该job

Command类型多job工作流flow
1、创建有依赖关系的多个job描述
第一个job:foo.job
# foo.job
type=command
command=echo foo
第二个job:bar.job依赖foo.job
# bar.job
type=command
dependencies=foo
command=echo bar
2、将所有job资源文件打到一个zip包中

3、在azkaban的web管理界面创建工程并上传zip包
4、启动工作流flow
HDFS操作任务
1、创建job描述文件
# fs.job
type=command
command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop fs -mkdir /azaz
2、将job资源文件打包成zip文件
3、通过azkaban的web管理平台创建project并上传job压缩包
4、启动执行该job
MAPREDUCE任务
Mr任务依然可以使用command的job类型来执行
1、创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的examplejar)
# mrwc.job
type=command
command=/home/hadoop/apps/hadoop-2.6.1/bin/hadoop
jar hadoop-mapreduce-examples-2.6.1.jar
wordcount /wordcount/input /wordcount/azout
2、将所有job资源文件打到一个zip包中

3、在azkaban的web管理界面创建工程并上传zip包
4、启动job
HIVE脚本任务
l 创建job描述文件和hive脚本
Hive脚本: test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',';
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest;
Job描述文件:hivef.job
# hivef.job
type=command
command=/home/hadoop/apps/hive/bin/hive -f 'test.sql'
2、将所有job资源文件打到一个zip包中
3、在azkaban的web管理界面创建工程并上传zip包
4、启动job
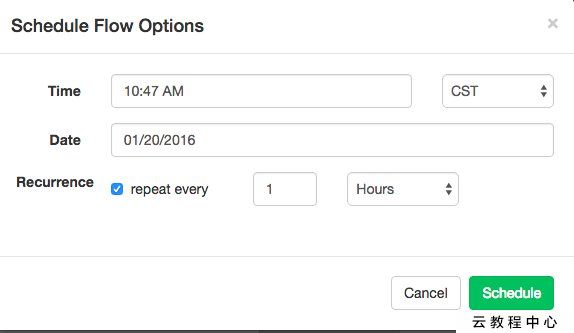
定时任务: