近20年3867篇AI论文大调研:有缺陷的指标被滥用,好的指标被忽视

来源:AI科技评论
本文约5400字,建议阅读6分钟。
论文调查告诉你评估机器学习模型中的不足。
“用于评估AI和机器学习模型的常用指标不足以反映这些模型的真实性能”,来自维也纳医科大学人工智能与决策支持研究所的研究人员通过调查3,867篇AI论文,得出了这个结论。
基准测试是AI研究进展的重要推动力。任务和与之相关的度量可以被视为科学界旨在解决的问题的抽象。基准数据集被概念化为模型要解决的固定代表样本。
这些论文来自基于开放源代码的Papers with Code平台(PWC)。尽管科学家们已经建立了涵盖机器翻译、目标检测或问答等一系列任务的基准,但维也纳医科大学的研究者表示,有些指标例如准确率,会强调模型表现的某些方面,而忽视其他方面。
这些论文的基准测试中很少使用其他更合适的指标,仅使用那些常用的有问题的指标。例如准确率、BLEU分数等指标的使用频率高的惊人,而它们都存在评估片面性缺陷,而那些被证明更有用的指标,例如MCC、FM等,基本没有出现在分析的论文中。
并且这些论文对指标的描述经常出现不一致且不明确的地方,导致对结果的优越性判断模棱两可,尤其是指标名称可能被过度简化,例如把不同的AUC统一表述为AUC。
Papers with Code最近20年论文调查
研究人员调查了2000年至2020年6月之间发表的3,867篇论文中2,298份数据集中的32,209个基准结果。从统计数据中,我们也可以大致了解AI二十年来的发展概况。

表1:分析数据集的统计概况(表中3,883应为失误,编者注)
值得一提的是,对Papers with Code的论文调查也反映出,自2012年来,AI论文数量呈指数增长趋势。
 图1:Papers with Code每年发表论文数量,y轴对数缩放
图1:Papers with Code每年发表论文数量,y轴对数缩放
在这些论文中,研究对象集中于图像、语言和一些更基础的流程(包括迁移和元学习等)。图2显示了每个AI子流程的基准数据集数量。 其中,“视觉流程”、“自然语言处理”和“基础AI流程”是关联基准数据集数量最多的三个子流程。
 图2:每个AI子流程的基准数据集数量,x轴按对数比例缩放
图2:每个AI子流程的基准数据集数量,x轴按对数比例缩放
在这些论文中,总共使用了187个不同的top-level(最常用)指标。图3展示了选定的指标的层次结构。
 图3:指标层次结构。图左显示了top-level指标列表部分;图右显示了“准确率”的子指标列表部分
图3:指标层次结构。图左显示了top-level指标列表部分;图右显示了“准确率”的子指标列表部分
到目前为止,分类指标是关联基准数据集数量最多的类型。在下图中,top-level指标根据其通常应用于的任务类型进行分类,例如 “准确率”被归类为”分类”,“均方误差”被归类为“回归”,“BLEU”被归类为“自然语言处理”。

图4:每种top-level指标的数量(蓝色条)以及使用至少一个相应top-level指标的不同基准数据集的数量(灰色条),x轴按对数比例缩放
最常用的指标近乎过度使用
在这187个指标中,最常用的指标是准确率(accuracy), 占基准数据集的38%。 第二和第三最常报告的指标是F分数(F-score,精度和召回率的加权平均值),以及精度(precision)。如果考虑子指标,F1分数是最常用的F分数。
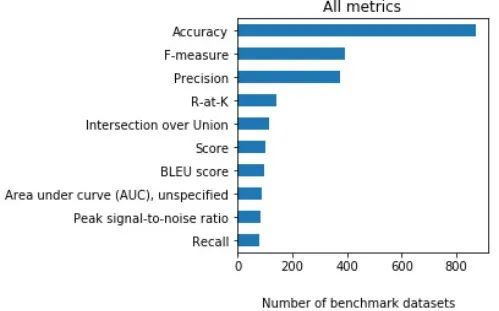
图5
在分类指标中,最常用的指标也是准确率、F分数和精度。
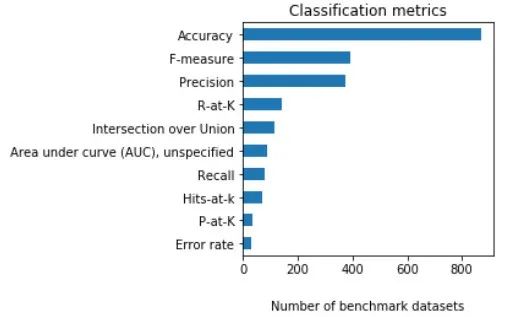
图6
令人惊讶的是,有三分之二(77.2%)的已分析基准数据集,仅报告了一个top-level指标。14.4%的基准数据集具有两个top-level指标,6%的基准数据集具有三个top-level指标。
每个基准数据集的不同top-level指标的最小和最大数量分别为1和6,不同top-level指标的中位数为1。
报告了准确率的基准数据集的83.1%,没有报告其他top-level指标。报告了F分数的基准数据集的60.9%,没有报告其他top-level指标。
考虑子指标时,统计信息会略有变化。 仅报告单个top-level指标的基准数据集的比例下降到70.4%,而使用两个或多个top-level指标的基准数据集的比例则略有增加。
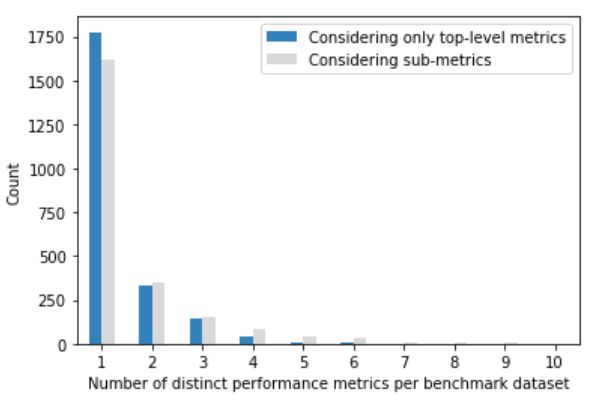 图7:仅将top-level指标视为不同指标(蓝色条)时,以及将子指标视为不同指标(灰色条)时,不同指标数的基准数据集的计数
图7:仅将top-level指标视为不同指标(蓝色条)时,以及将子指标视为不同指标(灰色条)时,不同指标数的基准数据集的计数
自然语言处理(NLP)是一个非常广泛的领域,涵盖了广泛的不同任务,因此用于基准数据集性能比较的指标显示出很大的多样性。
命名实体识别和词性标记通常被视为分类任务,使用的也是分类任务的相关指标。需要不同评估指标的其他更复杂的任务包括机器翻译、问答和摘要。 针对这些任务设计的指标通常旨在评估机器生成的文本与人为生成的参考文本之间的相似性。
在自然语言处理的论文中,三个最常报告的指标是BLEU得分、ROUGE指标和METEOR。与BLEU和ROUGE相比,METEOR在NLP基准数据集中很少用作性能指标(13次)。

图8
BLEU分数用于各种NLP基准测试任务,例如机器翻译、问答、摘要和文本生成。ROUGE指标主要用于文本生成、视频说明和摘要任务,而METEOR主要用于图像和视频说明、文本生成和问答任务。
IBM在2001年提出了BLEU分数,作为机器翻译任务的指标。它基于n-gram精度(即,匹配的n-gram与所生成的n-gram总数的比例),并应用所谓的“简洁惩罚”,使翻译文本长度相比参考译文不会太短。
虽然由于其n-gram的几何平均,最初的BLEU分数不能用于句子级别的比较,但后来人们提出了一种用于句子级别比较的称为“Smoothed BLEU”(BLEUS)的变体来解决此问题。
研究人员指出,在80.2%的论文中,仅使用了BLEU分数,而ROUGE指标更常与其他指标一起使用,在24篇论文中只有9篇单独使用ROUGE。METEOR至少和一项其他指标一起使用。
某些指标被过度简化
研究人员指出,在所确定的指标报告中存在不合规使用行为,主要是过度简化指标名称。例如将“曲线下面积”过度简化为“ AUC”。 曲线下面积是对准确率的一种度量,可以根据是精度和召回率(recall)的AUC(PR-AUC),还是召回率和假阳性率的AUC(ROC-AUC)以不同的方式进行解释。
同样,有几篇论文提到了自然语言处理基准ROUGE,但未指定使用的是哪种变体,例如ROUGE-1、ROUGE-L,通常只简化成“ROUGE”。
如果考虑子指标,ROUGE-1、ROUGE-2和ROUGE-L是最常用的ROUGE变体,而BLEU-4和BLEU-1是最常用的BLEU变体。但是对于大部分BLEU和ROUGE指标的注释,都未指定子变量。
研究人员认为,ROUGE具有精度和召回率相关的子变量,尽管召回率子变量更为常见,但是在比较论文之间的结果时可能会导致模棱两可。
其他性能指标也存在类似的不一致和歧义,例如分数的加权或宏观和微观平均值,可能缺少标准化定义。 在某些情况下,无法从原始论文中确定用于报告结果的指标。
最常用的指标存在缺陷
研究人员说,被调查论文中使用的许多指标都是有问题的。 准确率通常用于评估二分类器和多分类器模型,但是当处理不平衡的数据集时,即每个类的实例数量存在很大差异时,准确率无法提供有用的结果。
如果分类器在所有情况下都预测出多数类别,则准确率等于全部类别中多数类别的比例。例如,如果给定的“类别A”占所有实例的95%,则始终预测“类别A”的分类器的准确率将为95%。
精度(预测为正的样本中真正样本的比例)和召回率(样本中的正例被预测正确的比例)也有局限性,两者都忽略了模型准确预测负样本的能力。至于F分数,有时精度相比召回率有更大的权重,为偏向于预测多数类的分类器提供了误导性的结果。 除此之外,它们只能用于一个类别。
所以后来,人们提出了这些指标的变体以用于多类别分类,有多种形式,例如不同指标各自的“微观”和“宏观”平均值。
但是对于多类别分类任务,F1分数的定义还是存在不一致之处。Opitz和Burst(2019)发现当前使用两个不同的公式来计算宏观F1分数,仅在极少数情况下才会产生相等结果。
这些有缺陷的指标不仅使用的频繁,还经常一起使用,至于它们之间是否有互补的关系,研究人员并没有提到。图9展示了10个最常用的top-level分类指标的共现矩阵。准确率通常与F分数一起出现。此外,F分数、精度和召回率经常一起出现。
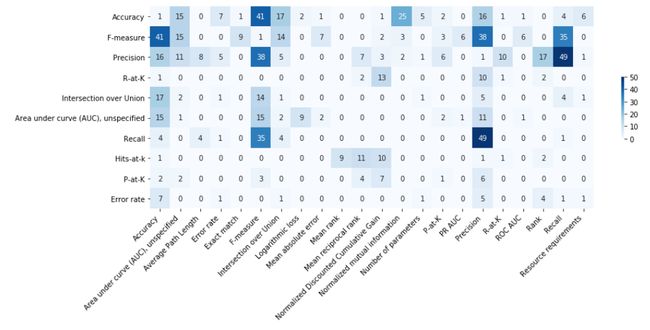 图9:10个最常用的top-level分类指标的共现矩阵
图9:10个最常用的top-level分类指标的共现矩阵
此外,这些分数的几个特定于任务的扩展已被概念化。 例如,弛化F1分数也考虑了不精确的匹配,并且在自然语言处理任务(例如命名实体识别)中有应用。其他NLP指标可以看作是精度和召回率的特殊变体,包括BLEU、NIST、ROUGE和METEOR。与简单分类相比,由于语言增加了复杂性,因此将分别进行讨论。
在自然语言处理领域,研究人员强调了诸如BLEU和ROUGE等基准测试的问题。BLEU仅关注n-gram精度而不会考虑召回率,并且依赖n-gram的精确匹配。
研究人员还讨论了BLEU和NIST的属性,NIST是BLEU分数的一种变体,它赋予较稀有的n-gram更大的权重,这两个度量均未显示与人类对机器翻译质量的判断必然高度相关。
虽然最初人们建议将ROUGE用于摘要任务,但ROUGE指标的子集(即ROUGE-L、ROUGE-W和ROUGE-S)也已显示在机器翻译评估任务中表现良好。
但是,ROUGE没有充分涵盖依赖大量文本释义的任务,例如文本摘要和多发言者的摘录(例如会议记录)。
近年来,人们提出了几种新的变体,它们有的利用词嵌入(ROUGE-WE),有的基于图的方法(ROUGE-G),或具有附加词汇特征的扩展(ROUGE 2.0)。研究人员发现,ROUGE-1、ROUGE-2和ROUGE-L是用作指标的最常见ROUGE子指标。
同样,这些有缺陷的指标不仅使用的频繁,还经常一起使用。图10展示了10个最常用的NLP指标的共现矩阵。BLEU最常与ROUGE、METEOR一起使用,反之亦然。
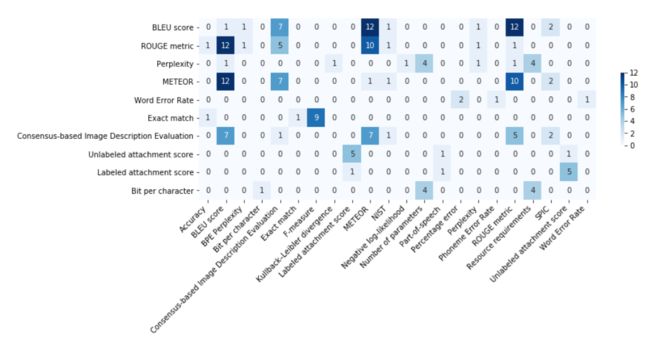 图10:10个最常用的NLP指标的共现矩阵
图10:10个最常用的NLP指标的共现矩阵
由于当前使用的评估指标存在各种缺点,因此针对语言生成任务的指标开发是一个开放的研究问题。 甚至在一年一度的机器翻译会议上,指标评估也作为一项独立任务被引入。
实际上,大多数NLP指标最初是针对非常特定的应用而概念化的,例如用于机器翻译的BLEU和METEOR,或用于评估机器生成的文本摘要的ROUGE。
但在之后就被引入其他几个NLP任务作为指标,例如问答。有研究表明这些指标不能任意迁移到其他任务。人们比较了几种指标(例如ROUGE-L、METEOR、BERTScore、BLEU-1、BLEU-4、条件BERTScore等),基于三个问答数据集评估生成性问答任务。他们建议在这些评估的指标中,最好使用METEOR,并指出,最初引入的用于评估机器翻译和摘要的指标在评估问答任务中不一定有很好的表现。
最后,许多NLP指标使用非常特定的特征集,例如特定的词嵌入或语言元素,这可能会使可比性和可复现性复杂化。为了解决可复制性的问题,人们已经针对某些指标发布了参考开源实现,例如ROUGE。
好的指标被忽视
研究人员发现,在他们分析的任何论文中都没有使用更好的度量,例如Matthews相关系数(MCC)和Fowlkes-Mallows指数(FM),这些度量标准解决了准确率和F分数的一些缺点。 实际上,83.1%的基准数据集仅报告了准确率指标,但没有报告其他任何top-level指标,并且F分数是60.9%的数据集中使用的唯一指标。
在研究不平衡数据集时,一些研究人员认为MCC是最有用的指标之一。有人对比过六个不同模拟场景下的MCC、F1分数和准确率,他们得出的结论是,MCC在所有情况下都能始终如一地提供信息性响应,无论数据集是否平衡。尽管MCC具有良好的性能,但研究人员发现,在分析的论文中人们未将其用作任何基准数据集中的指标。
Fowlkes–Mallows指数(FM)定义为精度和召回率的几何平均值。由于FM考虑并平衡了分类器在正类和负类上的准确率,因此,当处理不平衡数据集时,人们建议将FM作为替代指标。 同样,在分析的论文中人们未将其用作任何基准数据集中的指标。
在分析的所有论文中,METEOR仅使用了13次,而这个指标被证明与人类跨任务判断高度相关。GLEU仅出现了3次,该指标旨在评估生成文本与“正常”语言用法的符合程度。 这与其他常用指标不同,后者通常侧重于生成的文本反映参考文本的程度。
NLP研究社区已经提出了其他NLP指标,但在分析的论文中未作为性能指标,包括TER、TER-Plus、LEPOR、Sentence Mover的相似度和BERTScore。
BERTScore在2019年被提议为与任务无关的性能指标。它基于token的上下文嵌入之间的余弦相似度之和计算两个句子的相似度(BERT)。BERTScore在机器翻译和图像说明任务中表现优于已有指标,例如BLEU、METEOR和ROUGE-L。当将其应用于对抗性释义检测任务时,它也比其他指标更强大。但是,BERT作者还指出,BERTScore的配置应适合任务特定的需求,因为没有单一的配置能够始终跨任务胜过所有其他配置。
在这些论文中未出现的其他分类指标包括平衡准确率(balanced accuracy)、宏观平均算术(MAvA)、Cohen的κ系数、Cramér的V和K度量。
追捧最新技术是一种坏习惯
本文介绍的结果基于可从PWC数据库获得的大量机器学习论文,PWC数据库是当前最大的可用注释数据库。该数据库既包含在arXiv上发表的论文的预印本,又包括在同行评审期刊上发表的论文。研究人员承认,分析预印本可能会歪曲研究结果。
尽管可以说arXiv预印本不能代表科学期刊文章,但有研究表明77%的arXiv预印本随后会在同行评审期刊发表。
在分析中,研究人员重点关注分类指标,以及用于评估NLP任务的性能指标。研究人员没有讨论用于点估计任务的性能指标。在分析的论文中,很少出现回归任务的指标,例如均方误差(MSE)、平均绝对误差(MAE)、均方根偏差(RMSD)和R²,只有5%的基准数据集使用。 最后,研究人员没有讨论使用包括适当评分规则的概率来衡量偏差的分类指标。
也就是说,目前的比较评估研究基本仅考虑一小部分指标,并专注于特定的NLP任务,跨多个任务的大型比较研究尚未完成。
但是,研究人员仍然相信,当前用于评估AI基准测试任务的大多数指标存在问题,它们可能导致分类器性能结果无法充分反映某些有用属性,尤其是在评估不平衡数据集时。虽然人们已经提出了替代指标,但目前在基准测试任务中很少使用,仅使用那些常用的有问题的指标。由于语言和特定任务的复杂性,NLP任务给指标设计带来了额外的挑战。
越来越多的学者呼吁将重点放在AI的科学进步上,而不是在基准上取得更好的性能。在今年6月的一次采访中,Google Brain团队研究员Denny Britz表示,他认为追捧最新技术是一种坏习惯,因为存在太多令人困惑的指标,并且它们通常更有利于大型、资金充足的实验室,例如 DeepMind和OpenAI。
卡内基梅隆大学助理教授Zachary Lipton和加利福尼亚大学伯克利分校统计系成员Jacob Steinhardt在最近提出,AI研究人员需要将更多的精力投入研究性能差的方法的原理和原因,并在研究过程中进行更多的错误分析、消融研究和鲁棒性检查。
参考链接:
https://venturebeat.com/2020/08/10/researchers-find-inconsistent-benchmarking-across-3867-ai-research-papers/
https://arxiv.org/ftp/arxiv/papers/2008/2008.02577.pdf
编辑:黄继彦
校对:杨学俊
