Hadoop与Spark技术入门
1 Hadoop系统概述
1.1 Hadoop简介
Hadoop最初起源于搜索引擎子项目Nutch,是Apache基金会的开源大数据计算平台,其核心组件设计包含有分布式文件系统HDFS及分布式计算框架MapReduce。随着Hadoop项目的开源发展,逐渐扩展成为一个包含Zookeeper、Hive等众多子系统的大数据生态系统。
1.2 分布式文件系统HDFS
HDFS采用Master/Slave的主从式架构设计,为Hadoop平台下的其他子系统提供基础存储支撑。它基于各slave节点的本地文件系统,构建一个逻辑上表现为整体的分布式文件系统。
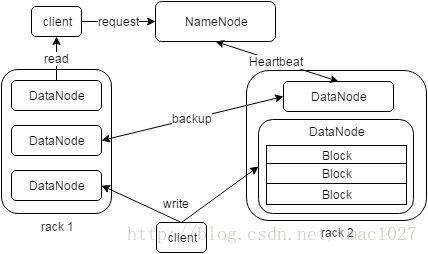
如图所示为HDFS架构图,HDFS中,负责管理控制的节点称为NameNode,主要存储元数据信息,而其他负责存储数据的节点称为DataNode。另外还有定时备份NameNode数据的节点称为SencondaryNameNode。
HDFS通过数据块的冗余复制实现文件系统的容错机制,并通过机架感知降低节点间的通信带宽和读取延时,所有文件块的复制都由NameNode管理,其通过心跳机制监控各DataNode状况,保证数据的安全可靠。当客户端执行读操作时,向NameNode发送数据请求,并获取文件到对应数据块的映射信息,进而到距离最近的DataNode读取相应的块数据。当客户端执行写操作时,需要先向NameNode发送请求以检查文件是否存在,然后由NameNode分配数据节点,之后写入的数据被拆分成块,先后写入并复制到各个DataNode。
1.3 分布式计算框架MapReduce
1. MapReduce作业执行流程
Hadoop MapReduce与HDFS一样,采用主从式的架构设计,由单一负责分配具体任务的JobTracker主控节点,以及众多负责执行对应任务的从节点TaskTracker组成。为了让任务尽量本地化计算,DataNode与TaskTracker合并设置,而NameNode与JobTracker既可以在一个节点上也可以分开设置。
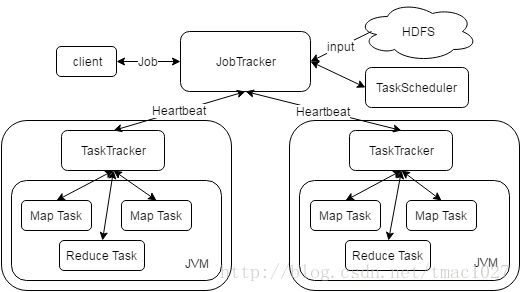
如图所示为MapReduce架构图,客户端提交MapReduce Job后,从HDFS获取输入数据并产生切分文件,交到JobTracker进行作业初始化和作业运行状态的跟踪,由TaskScheduler负责任务的调度,之后TaskTracker准备好运行环境,执行对应的Map Task或Reduce Task,期间周期性的通过Heartbeat机制向JobTracker汇报Task的运行状况。
2. MapReduce实现过程
MapReduce的编程思想基于(key,value)的键值对实现,其使得并行计算程序的编写变得简单,用户仅关心map函数和reduce函数具体操作即可实现。
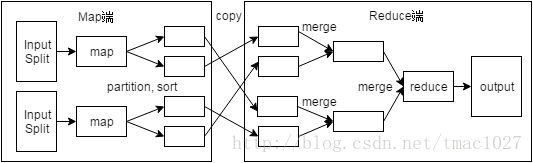
如图为MapReduce编程模型图,MapReduce的具体实现可以细分为以下过程:
(1)map
作业的输入文件在map任务执行前被切分为多个InputSplit,一个InputSplit对应一个map输入,map函数处理输入的键值对,产生新的中间键值对,并将最终临时结果存放于内存或本地磁盘。
(2)shuffle
shuffle阶段介于map阶段与reduce阶段之间,其作用是将map阶段产生的数据送到对应的reduce task执行,通过减少跨节点数据传输过程中的带宽消耗,实现对MapReduce的优化。
map端的shuffle过程可分为partitioner、sort和combiner。partitioner对map的输出进行了重新整理分区,决定了键值对应该被交由哪个reduce task处理。sort对每个partition内部的键值对集合进行基于key的排序。combiner则将具有相同主键的中间结果数据进行合并处理。以上各阶段操作解决了reduce端计算过程中数据相关性的问题。
reduce端的shuffle过程可分为copy和merge。Copy过程从各个map端简单地拉取数据,之后将从不同map端copy来的数据进行merge,当reduce端的输入数据形成时,整个shuffle阶段最终结束。
(3)reduce
reduce过程处理传入的键值对,合并中间结果列表,输出最终结果,并保存到HDFS中。
1.4 下一代MapReduce框架YARN
MapReduce的第一代框架中,JobTracker被赋予作业控制和资源调度两大模块,造成了单节点的性能瓶颈问题,同时这种离线处理框架已不能满足后来多样的计算框架,从而催生了下一代MapReduce框架YARN的出现。
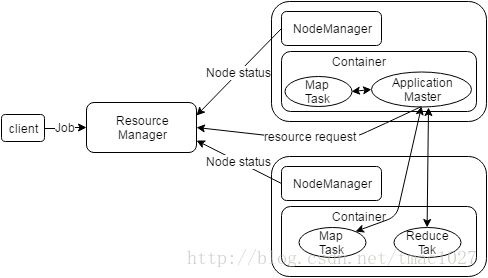
YARN将JobTracker中这两大模块分离开来,让ResourceManager(简称RM)作为资源调度的主控节点,负责对各NodeManager(简称NM)执行统一资源调度,而将负责监控作业运行状态的任务赋予ApplictionMaster(简称AM),AM向RM申请资源,同时通知NM在对应的container中启动或停止对应Task。
如下图所示描绘了YARN的工作流程,当客户端向YARN提交应用程序时,首先RM会为该应用分配对应的container来启动AM,然后AM向RM注册,并通过RPC通信协议向RM申请可用的资源,之后AM要求各NM准备好运行环境并启动Task,NM在运行期间通过RPC向AM汇报各自Task的执行状态及进度,以便AM发现Task失败时重启Task。最终,AM向RM注销后关闭自身,整个应用程序运行结束。
2 Spark系统概述
2.1 Spark简介
针对Hadoop MapReduce在迭代式、交互式计算方面的不足,美国加州大学的AMPLab提出了基于内存展开分布式计算的大数据平台Spark。Spark借鉴于Scala语言函数式编程的理念,提出RDD分布式数据架构,实现了Spark系统的快速性和高容错性。目前,Spark已衍生为涵盖各种计算模式的生态系统,并与Hadoop生态系统无缝兼容。
2.2 弹性分布式数据集RDD
RDD是Spark的核心所在,是一种分布式的内存抽象。RDD本质上是一个分区的数据集合,物理上由BlockManager管理数据块,在执行过程中,RDD通过一系列的Transformation算子,转化为新的RDD,还可通过Cache将数据缓存,最后由Action算子触发作业提交操作。同时,RDD的产生还可以通过从HDFS创建或调用SparkContext的parallelize方法创建。
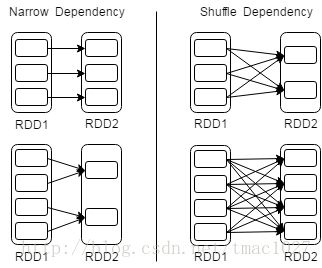
由于RDD仅支持粗粒度的转化操作,因此当RDD某个分区的数据发生丢失时,可以根据RDD之间的依赖关系来重新计算并恢复数据分区,Spark基于这种Lineage机制保证系统的容错性。其中,RDD之间的依赖关系可以分为Narrow Dependency与Shuffle Dependency,如上图所示为RDD依赖关系图。对于Narrow Dependency来说,一个父RDD分区至多对应一个子RDD分区,当节点失效时,只需重新计算对应的父RDD分区即可。而对于Shuffle Dependency来说,多个子RDD分区会同时对应一个父RDD,当节点失效时,需要重新计算对应父RDD的所有分区,这样就付出了不必要的冗余计算代价。
2.3 Spark on YARN工作机制
在Spark中,Driver进程是Spark Application的主控进程,负责应用的解析、监控以及任务的调度。Spark各模块间基于AKKA框架实现通信。
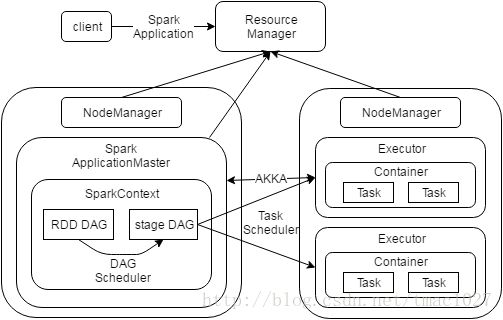
如图为Spark on YARN执行流程图,Spark on YARN模式下,Driver在NodeManager中作为一个ApplicationMaster启动。客户端提交Spark应用后,Driver进程将创建SparkContext,并由其作为程序运行的入口点,当RDD的Action算子触发Job提交后,生成RDD的有向无环图,之后由DAGScheduler划分为以Shuffle Dependency为依据的stage DAG,每个stage对应一个TaskSet,最后TaskScheduler将TaskSet中的Task调度分发到对应worker节点中的Excecutor执行,其中每个Task对应一个RDD分区。