Beautiful Soup库的用法
Beautiful Soup库的用法
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
这篇文档介绍了BeautifulSoup4中所有主要特性,并且有小例子.让我来向你展示它适合做什么,如何工作,怎样使用,如何达到你想要的效果,和处理异常情况.
文档中出现的例子在Python2.7和Python3.2中的执行结果相同
你可能在寻找 Beautiful Soup3 的文档,Beautiful Soup 3 目前已经停止开发,我们推荐在现在的项目中使用Beautiful Soup 4, 移植到BS4
寻求帮助
如果你有关于BeautifulSoup的问题,可以发送邮件到 讨论组 .如果你的问题包含了一段需要转换的HTML代码,那么确保你提的问题描述中附带这段HTML文档的 代码诊断 [1]
快速开始
下面的一段HTML代码将作为例子被多次用到.这是 爱丽丝梦游仙境的 的一段内容(以后内容中简称为 爱丽丝 的文档):
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc)
print(soup.prettify())
#
#
#
# The Dormouse's story
#
#
#
#
#
# The Dormouse's story
#
#
#
# Once upon a time there were three little sisters; and their names were
#
# Elsie
#
# ,
#
# Lacie
#
# and
#
# Tillie
#
# ; and they lived at the bottom of a well.
#
#
# ...
#
#
#
几个简单的浏览结构化数据的方法:
soup.title
# The Dormouse's story
soup.title.name
# u'title'
soup.title.string
# u'The Dormouse's story'
soup.title.parent.name
# u'head'
soup.p
# The Dormouse's story
soup.p[‘class’]
# u'title'
soup.a
# Elsie
soup.find_all(‘a’)
# [Elsie,
# Lacie,
# Tillie]
soup.find(id=“link3”)
# Tillie
从文档中找到所有标签的链接:
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
从文档中获取所有文字内容:
print(soup.get_text())
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
这是你想要的吗?别着急,还有更好用的
安装 Beautiful Soup
如果你用的是新版的Debain或ubuntu,那么可以通过系统的软件包管理来安装:
$ apt-get install Python-bs4
Beautiful Soup 4 通过PyPi发布,所以如果你无法使用系统包管理安装,那么也可以通过 easy_install 或 pip 来安装.包的名字是 beautifulsoup4 ,这个包兼容Python2和Python3.
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
(在PyPi中还有一个名字是 BeautifulSoup 的包,但那可能不是你想要的,那是 Beautiful Soup3 的发布版本,因为很多项目还在使用BS3, 所以 BeautifulSoup 包依然有效.但是如果你在编写新项目,那么你应该安装的 beautifulsoup4 )
如果你没有安装 easy_install 或 pip ,那你也可以 下载BS4的源码 ,然后通过setup.py来安装.
$ Python setup.py install
如果上述安装方法都行不通,Beautiful Soup的发布协议允许你将BS4的代码打包在你的项目中,这样无须安装即可使用.
作者在Python2.7和Python3.2的版本下开发Beautiful Soup, 理论上Beautiful Soup应该在所有当前的Python版本中正常工作
安装完成后的问题
Beautiful Soup发布时打包成Python2版本的代码,在Python3环境下安装时,会自动转换成Python3的代码,如果没有一个安装的过程,那么代码就不会被转换.
如果代码抛出了 ImportError 的异常: “No module named HTMLParser”, 这是因为你在Python3版本中执行Python2版本的代码.
如果代码抛出了 ImportError 的异常: “No module named html.parser”, 这是因为你在Python2版本中执行Python3版本的代码.
如果遇到上述2种情况,最好的解决方法是重新安装BeautifulSoup4.
如果在ROOT_TAG_NAME = u’[document]’代码处遇到 SyntaxError “Invalid syntax”错误,需要将把BS4的Python代码版本从Python2转换到Python3. 可以重新安装BS4:
$ Python3 setup.py install
或在bs4的目录中执行Python代码版本转换脚本
$ 2to3-3.2 -w bs4
安装解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,其中一个是 lxml .根据操作系统不同,可以选择下列方法来安装lxml:
$ apt-get install Python-lxml
$ easy_install lxml
$ pip install lxml
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同,可以选择下列方法来安装html5lib:
$ apt-get install Python-html5lib
$ easy_install html5lib
$ pip install html5lib
通用例子
获取网站所有的外部链接以及内部链接
#!/usr/bin/Python
# -*- coding: UTF-8 -*-
from urllib.request import urlopen
from urllib.parse import urlparse, quote
from bs4 import BeautifulSoup
import re
import datetime
import random
import urllib
from urllib import request
pages = set()
random.seed(datetime.datetime.now())
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
#获取页面所有内链的列表
def getInternalLinks(bsObj, includeUrl):
includeUrl = urlparse(includeUrl).scheme + "://" + urlparse(includeUrl).netloc
internalLinks = []
#找出所有以“/”开头的链接
for link in bsObj.findAll("a", href=re.compile("^(/|.*" + includeUrl + ")")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in internalLinks:
if(link.attrs['href'].startswith("/")):
internalLinks.append(includeUrl + link.attrs['href'])
else:
internalLinks.append(link.attrs['href'])
return internalLinks
#获取页面所有外链的列表
def getExternalLinks(bsObj, excludeUrl):
externalLinks = []
#找出所有以“http”或者“www”开头且不包含当前URL的链接
for link in bsObj.findAll("a", href=re.compile("^(http|www)((?!" + excludeUrl + ").)*$")):
if link.attrs['href'] is not None:
if link.attrs['href'] not in externalLinks:
externalLinks.append(link.attrs['href'])
return externalLinks
def getRandomExternalLink(startingPage):
quotePage = quote(startingSite, safe='/:?=&#')
req = request.Request(quotePage,headers=headers)
response = urlopen(req)
buff = response.read()
html = buff.decode("gbk")
bsObj = BeautifulSoup(html,"html.parser")
externalLinks = getExternalLinks(bsObj, urlparse(startingPage).netloc)
if len(externalLinks) == 0:
#print("没有外部链接,准备遍历整个网站")
print(1)
domain = urlparse(startingPage).scheme + "://" + urlparse(startingPage).netloc
internalLinks = getInternalLinks(bsObj, domain)
return getRandomExternalLink(internalLinks[random.randint(0,len(internalLinks) - 1)])
else:
return externalLinks[random.randint(0, len(externalLinks) - 1)]
def followExternalOnly(startingSite):
quoteSite = quote(startingSite, safe='/:?=&#')
externalLink = getRandomExternalLink(quoteSite)
#print("随机外链是: " + externalLink)
print("Ext link: " + externalLink)
followExternalOnly(externalLink)
#收集网站上发现的所有外链列表
#allExtLinks = set()
allIntLinks = set()
def getAllInternalLinks(siteUrl):
'''
#设置代理IP访问
proxy_handler = urllib.request.ProxyHandler({'http':'183.77.250.45:3128'})
proxy_auth_handler = urllib.request.ProxyBasicAuthHandler()
proxy_auth_handler.add_password('realm', '123.123.2123.123', 'user','password')
'''
opener = urllib.request.build_opener(urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
quoteUrl = quote(siteUrl, safe='/:?=&#')
req = request.Request(quoteUrl,headers=headers,)
#html = urlopen(req)
#bsObj = BeautifulSoup(html.read(),"html.parser")
response = urlopen(req)
buff = response.read()
html = buff.decode("gbk")
bsObj = BeautifulSoup(html,"html.parser")
domain = urlparse(quoteUrl).scheme + "://" + urlparse(quoteUrl).netloc
internalLinks = getInternalLinks(bsObj,domain)
externalLinks = getExternalLinks(bsObj,domain)
#收集外链
for link in externalLinks:
if link not in allExtLinks:
allExtLinks.add(link)
print(link)
#收集内链
for link in internalLinks:
if link not in allIntLinks:
#print("即将获取内部链接的URL是:" + link)
print("Internal URL:" + link)
allIntLinks.add(link)
getAllInternalLinks(link)
#followExternalOnly("http://bbs.3s001.com/forum-36-1.html")
#allIntLinks.add("http://www.zfcg.sh.gov.cn/login.do;jsessionid=gLTLhDhpJG1bTg6q71GrDDdqGlBcvKmxQLD4c4wzJhYDz1v8rfSG!1611271843!-160182643?method=beginloginnew")
getAllInternalLinks("http://www.zfcg.sh.gov.cn/login.do;jsessionid=gLTLhDhpJG1bTg6q71GrDDdqGlBcvKmxQLD4c4wzJhYDz1v8rfSG!1611271843!-160182643?method=beginloginnew")
遍历和搜索HTML节点以及文本1
# -*- coding: utf-8 -*-
import re
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
#分析:bs中,标签只有一个子节点,但是有2个子孙节点
# 获取BeautifulSoup对象并按标准缩进格式输出
soup = BeautifulSoup(html_doc,'lxml')
#######遍历文档树###############
print(soup.head) #获取head标签
print(soup.title) #获取title标签
print(soup.body.b) #获取body的b标签
print(soup.a) #)点取属性的方式只能获得当前名字的第一个tag
print(soup.find_all('a')) #得到所有的标签
print('-------')
print(soup.head.contents) #获取head子节点 返回元组
print(soup.head.contents[0]) #获取head子节点,返回字符串
print(soup.head.contents[0].contents) #获取head子节点,返回字符串
print('-------descendants-------') #递归所有子孙节点
for child in soup.head.descendants:
print(child)
print(soup.head.string) #只有一个String 类型子节点,那么这个tag可以使用.string 得到子节点
print('--strings--') #(soup.strings:)获取所有字符串(soup.stripped_strings,可以去掉多于空白内容)
for string in soup.stripped_strings: #
print(repr(string))
print(soup.title.parent) #获取title的父节点
print(soup.title.string.parent) #string的父节点
print('---parents--')
for parent in soup.a.parents: #获取a的所有父节点
if parent is None:
print(parent)
else:
print(parent.name)
#.next_sibling 和 .previous_sibling ,遍历兄弟结点
# .next_siblings 和 .previous_siblings,遍历所有兄弟结点
#.next_element 和 .previous_element ,指向解析过程中下一个被解析的对象(字符串或tag)
#.next_elements 和 .previous_elements,解析整个文档
########搜索文档树###############
print(soup.find_all(["a", "b"])) #查找带有a或b的标签
for tag in soup.find_all(True): #找到所有tag
print(tag.name)
print(soup.find_all(id='link2')) #搜索每个tag的id属性
print(soup.find_all(id=True)) #搜索所有包含id属性的tag
print(soup.find_all(href=re.compile("elsie"))) #搜索tag的href属性
print(soup.find_all(href=re.compile("elsie"), id='link1'))
#soup.find_all("a", class_="sister") ,按照CSS类名搜索tag
#soup.find_all(text="Elsie") 搜索字符串
#soup.select('a[href]')
print('------')
print(soup.get_text()) #获取所有tag文档
遍历和搜索HTML节点以及文本2
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
doc = BeautifulSoup(html_doc,'lxml')
soup = doc.head
for child in soup.children:
print(child)
# The Dormouse's story
for string in doc.strings:
print(repr(string))
# u"The Dormouse's story"
# u'\n\n'
# u"The Dormouse's story"
# u'\n\n'
# u'Once upon a time there were three little sisters; and their names were\n'
# u'Elsie'
# u',\n'
# u'Lacie'
# u' and\n'
# u'Tillie'
# u';\nand they lived at the bottom of a well.'
# u'\n\n'
# u'...'
# u'\n'
HTML表格文本转换为JSON数据
import json
from bs4 import BeautifulSoup
html_data = """
Card balance
$18.30
Card name
NAMEn
Account holder
NAME
Card number
1234
Status
Active
"""
table = BeautifulSoup(html_data,'lxml')
table_data = [[cell.text for cell in row("td")] for row in table("tr")]
json_data = json.dumps(dict(table_data))
print(json_data)
![]()
HTML表格文本按顺序转换为JSON数据
import json
from collections import OrderedDict
from bs4 import BeautifulSoup
html_data = """
Card balance
$18.30
Card name
NAMEn
Account holder
NAME
Card number
1234
Status
Active
"""
table = BeautifulSoup(html_data,'lxml')
table_data = [[cell.text for cell in row("td")] for row in table("tr")]
json_data = json.dumps(OrderedDict(table_data))
print(json_data)
![]()
HTML列表文本转换为JSON数据
from bs4 import BeautifulSoup
html_data = """
-
Outer List
-
-
Inner List
-
info 1
-
info 2
-
info 3
"""
soup = BeautifulSoup(html_data,'lxml')
inner_ul = soup.find('ul', class_='innerUl')
inner_items = [li.text.strip() for li in inner_ul.ul.find_all('li')]
outer_ul_text = soup.ul.span.text.strip()
inner_ul_text = inner_ul.span.text.strip()
result_list = {outer_ul_text: {inner_ul_text: inner_items}}
print(result_list)
![]()
HTML网页转换为JSON数据
import threading
from queue import Queue
from urllib.parse import quote
import json
import os
import requests
from bs4 import BeautifulSoup
headersParameters = { #发送HTTP请求时的HEAD信息,用于伪装为浏览器
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
timeout = 60 #默认超时时间为60秒
#文件操作
def create_dir(directory):
'''
创建目录
'''
if not os.path.exists(directory):
os.makedirs(directory)
return directory
def write_file(file_name, data):
'''
写入文件内容
'''
with open(file_name, 'w') as f:
f.write(data)
def file_to_set(file_name):
'''
文件内容转化为集合
'''
results = set()
with open(file_name, 'rt') as f:
for line in f:
results.add(line.replace('\n', ''))
return results
def write_json(file_name, data):
'''
写入Json数据到文件
'''
with open(file_name, 'w') as f:
json.dump(data, f)
class MasterParser:
'''
爬取网页转换为Json格式内容,并输出为文件
'''
@staticmethod
def parse(url, output_dir, output_file):
print('Crawling ' + url)
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
resp = requests.get(url ,timeout=timeout, headers=headersParameters)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
if resp.status_code == 200:
html = resp.text
try:
page_parser = PageParser(html) #resp_bytes.decode('utf-8')
except UnicodeDecodeError:
return
json_results = {
'url': url,
'status': resp.status_code,
'headers': dict(resp.headers),
'tags': page_parser.all_tags
}
write_json(output_dir + '/' + output_file + '.json', json_results)
else:
print('[ERROR]',self.url,u'get此url返回的http状态码不是200')
return
class Tag:
'''
获取HTML节点的内容
'''
def __init__(self, name):
self.name = name
self.content = None
self.attributes = {}
def add_content(self, text):
self.content = ' '.join(text.split())
def add_attribute(self, key, value):
if str(type(value)) == "":
if len(value) < 1:
return
self.attributes[key] = value
def get_data(self):
if len(self.attributes) == 0:
self.attributes = None
return {
'name': self.name,
'content': self.content,
'attributes': self.attributes
}
class PageParser:
'''
HTML页面转换为Json内容
'''
def __init__(self, html_string):
self.soup = BeautifulSoup(html_string, 'html5lib')
self.html = self.soup.find('html')
self.all_tags = self.parse()
def parse(self):
'''
转换BeautifulSoup对象为Json对象
'''
results = []
for x, tag in enumerate(self.html.descendants):
if str(type(tag)) == "":
if tag.name == 'script':
continue
# Find tags with no children (base tags)
if tag.contents:
if sum(1 for _ in tag.descendants) == 1:
t = Tag(tag.name.lower())
# Because it might be None ()
if tag.string:
t.add_content(tag.string)
if tag.attrs:
for a in tag.attrs:
t.add_attribute(a, tag[a])
results.append(t.get_data())
# Self enclosed tags (hr, meta, img, etc...)
else:
t = Tag(tag.name.lower())
if tag.attrs:
for a in tag.attrs:
t.add_attribute(a, tag[a])
results.append(t.get_data())
return results
#输入URL列表的文件
#INPUT_FILE = 'sample-links.txt'
#输出文件的目录
OUTPUT_DIR = 'data'
#爬取HTML网页最大线程数
NUMBER_OF_THREADS = 8
#爬取HTML网页工作队列
queue = Queue()
#创建输出文件的目录
create_dir(OUTPUT_DIR)
#爬取HTML网页工作队列计数
crawl_count = 0
def create_workers():
'''
启动多个爬取HTML网页工作线程
'''
for _ in range(NUMBER_OF_THREADS):
t = threading.Thread(target=work)
t.daemon = True
t.start()
def work():
'''
爬取HTML网页工作线程
'''
global crawl_count
while True:
url = queue.get()
crawl_count += 1
MasterParser.parse(url, OUTPUT_DIR, str(crawl_count))
queue.task_done()
def create_jobs():
'''
创建爬取HTML网页作业
'''
#将文件中的URL放入集合去重,然后用这些URL创建爬取HTML网页作业
#for url in file_to_set(INPUT_FILE):
#queue.put(url)
keyword = "VBA"
url = 'https://www.baidu.com/baidu?wd=' + quote(keyword) + '&tn=monline_dg&ie=utf-8'
queue.put(url)
queue.join()
#启动多个爬取HTML网页工作线程
create_workers()
#创建爬取HTML网页作业
create_jobs()
政府采购网站爬虫
获取上海市政府采购和中标的详细信息导出文件
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.parse import quote
from bs4 import BeautifulSoup
import urllib
from urllib import request
import requests
import re
'''
上海市采购网
'''
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
#b'\xe9\xa1\xb9\xe7\x9b\xae\xe5\x90\x8d\xe7\xa7\xb0'="项目名称".encode()
encode_bidding_name = b'\xe9\xa1\xb9\xe7\x9b\xae\xe5\x90\x8d\xe7\xa7\xb0'
#b'\xe6\x8b\x9b\xe6\xa0\x87\xe7\xbc\x96\xe5\x8f\xb7'="招标编号".encode()
encode_bidding_number = b'\xe6\x8b\x9b\xe6\xa0\x87\xe7\xbc\x96\xe5\x8f\xb7'
#b'\xe9\xa2\x84\xe7\xae\x97\xe7\xbc\x96\xe5\x8f\xb7'="预算编号".encode()
encode_bidding_budget_number = b'\xe9\xa2\x84\xe7\xae\x97\xe7\xbc\x96\xe5\x8f\xb7'
#b'\xe9\xa1\xb9\xe7\x9b\xae\xe4\xb8\xbb\xe8\xa6\x81\xe5\x86\x85\xe5\xae\xb9'="项目主要内容".encode()
encode_bidding_description = b'\xe9\xa1\xb9\xe7\x9b\xae\xe4\xb8\xbb\xe8\xa6\x81\xe5\x86\x85\xe5\xae\xb9'
#b'\xe9\x87\x87\xe8\xb4\xad\xe9\xa2\x84\xe7\xae\x97\xe9\x87\x91\xe9\xa2\x9d'="采购预算金额".encode()
encode_bidding_purchase_budget = b'\xe9\x87\x87\xe8\xb4\xad\xe9\xa2\x84\xe7\xae\x97\xe9\x87\x91\xe9\xa2\x9d'
#b'\xe4\xba\xa4\xe4\xbb\x98\xe5\x9c\xb0\xe5\x9d\x80'="交付地址".encode()
encode_bidding_delivery_address = b'\xe4\xba\xa4\xe4\xbb\x98\xe5\x9c\xb0\xe5\x9d\x80'
#b'\xe4\xba\xa4\xe4\xbb\x98\xe6\x97\xa5\xe6\x9c\x9f'="交付日期".encode()
encode_bidding_delivery_date = b'\xe4\xba\xa4\xe4\xbb\x98\xe6\x97\xa5\xe6\x9c\x9f'
#b'\xe6\x8b\x9b\xe6\xa0\x87\xe6\x96\x87\xe4\xbb\xb6\xe7\x9a\x84\xe8\x8e\xb7\xe5\x8f\x96'="招标文件的获取".encode()
encode_bidding_time = b'\xe6\x8b\x9b\xe6\xa0\x87\xe6\x96\x87\xe4\xbb\xb6\xe7\x9a\x84\xe8\x8e\xb7\xe5\x8f\x96'
#b'\xe5\x90\x88\xe6\xa0\xbc\xe7\x9a\x84\xe4\xbe\x9b\xe5\xba\x94\xe5\x95\x86\xe5\x8f\xaf\xe4\xba\x8e'="合格的供应商可于".encode()
encode_bidding_time2 = b'\xe5\x90\x88\xe6\xa0\xbc\xe7\x9a\x84\xe4\xbe\x9b\xe5\xba\x94\xe5\x95\x86\xe5\x8f\xaf\xe4\xba\x8e'
#b'\xef\xbc\x8c'=",".encode()
encode_comma = b'\xef\xbc\x8c'
#b'\xe6\x8a\x95\xe6\xa0\x87\xe6\x88\xaa\xe6\xad\xa2\xe6\x97\xb6\xe9\x97\xb4'="投标截止时间".encode()
encode_bidding_deadline = b'\xe6\x8a\x95\xe6\xa0\x87\xe6\x88\xaa\xe6\xad\xa2\xe6\x97\xb6\xe9\x97\xb4'
#b'\xe3\x80\x82'="。".encode()
encode_stop = b'\xe3\x80\x82'
#b'\xe3\x80\x81'="、".encode()
encode_punctuation_mark = b'\xe3\x80\x81'
#b'\xe5\xbc\x80\xe6\xa0\x87\xe6\x97\xb6\xe9\x97\xb4'="开标时间".encode()
encode_bidding_opening_time = b'\xe5\xbc\x80\xe6\xa0\x87\xe6\x97\xb6\xe9\x97\xb4'
#b'\xe9\x87\x87\xe8\xb4\xad\xe4\xba\xba'="采购人".encode()
encode_bidding_purchaser_name = b'\xe9\x87\x87\xe8\xb4\xad\xe4\xba\xba'
#b'\xe4\xbb\xa3\xe7\x90\x86\xe6\x9c\xba\xe6\x9e\x84'="代理机构".encode()
encode_bidding_procurement_agency_name = b'\xe4\xbb\xa3\xe7\x90\x86\xe6\x9c\xba\xe6\x9e\x84'
#b'\xe5\x9c\xb0\xe5\x9d\x80'="地址".encode()
encode_address = b'\xe5\x9c\xb0\xe5\x9d\x80'
#b'\xe9\x82\xae\xe7\xbc\x96'="邮编".encode()
encode_zipcode = b'\xe9\x82\xae\xe7\xbc\x96'
#b'\xe8\x81\x94\xe7\xb3\xbb\xe4\xba\xba'="联系人".encode()
encode_contact = b'\xe8\x81\x94\xe7\xb3\xbb\xe4\xba\xba'
#b'\xe7\x94\xb5\xe8\xaf\x9d'="电话".encode()
encode_telephone = b'\xe7\x94\xb5\xe8\xaf\x9d'
#b'\xe4\xbc\xa0\xe7\x9c\x9f'="传真".encode()
encode_fax = b'\xe4\xbc\xa0\xe7\x9c\x9f'
#b'\xe7\x94\xb1'="由".encode()
encode_because = b'\xe7\x94\xb1'
#b'\xe7\xbb\x84\xe7\xbb\x87\xe6\x8b\x9b\xe6\xa0\x87\xe7\x9a\x84'="组织招标的".encode()
encode_bid = b'\xe7\xbb\x84\xe7\xbb\x87\xe6\x8b\x9b\xe6\xa0\x87\xe7\x9a\x84'
#b'\xef\xbc\x88'="(".encode()
encode_left = b'\xef\xbc\x88'
#b'\xef\xbc\x89'=")".encode()
encode_right = b'\xef\xbc\x89'
#b'\xe9\xa1\xb9\xe7\x9b\xae\xe7\xbc\x96\xe5\x8f\xb7'="项目编号".encode()
encode_bid_number = b'\xe9\xa1\xb9\xe7\x9b\xae\xe7\xbc\x96\xe5\x8f\xb7'
#b'\xe9\xa2\x84\xe7\xae\x97\xe7\xbc\x96\xe5\x8f\xb7'="预算编号".encode()
encode_bid_budget_number = b'\xe9\xa2\x84\xe7\xae\x97\xe7\xbc\x96\xe5\x8f\xb7'
#b'\xe9\xa1\xb9\xe7\x9b\xae\xe6\x80\xbb\xe9\x87\x91\xe9\xa2\x9d'="项目总金额".encode()
encode_bid_total_amount = b'\xe9\xa1\xb9\xe7\x9b\xae\xe6\x80\xbb\xe9\x87\x91\xe9\xa2\x9d'
#b'\xe4\xb8\xad\xe6\xa0\x87\xe4\xbe\x9b\xe5\xba\x94\xe5\x95\x86'="中标供应商".encode()
encode_bid_provider = b'\xe4\xb8\xad\xe6\xa0\x87\xe4\xbe\x9b\xe5\xba\x94\xe5\x95\x86'
#b'\xe4\xb8\xad\xe6\xa0\x87\xe4\xbe\x9b\xe5\xba\x94\xe5\x95\x86\xe5\x9c\xb0\xe5\x9d\x80'="中标供应商地址".encode()
encode_bid_provider_address = b'\xe4\xb8\xad\xe6\xa0\x87\xe4\xbe\x9b\xe5\xba\x94\xe5\x95\x86\xe5\x9c\xb0\xe5\x9d\x80'
#b'\xe4\xb8\xad\xe6\xa0\x87\xe9\x87\x91\xe9\xa2\x9d'="中标金额".encode()
encode_bid_amount = b'\xe4\xb8\xad\xe6\xa0\x87\xe9\x87\x91\xe9\xa2\x9d'
#b'\xe5\x8c\x85\xe4\xb8\xba'="包为".encode()
encode_bid_assign_to = b'\xe5\x8c\x85\xe4\xb8\xba'
#b'\xe9\x87\x87\xe8\xb4\xad\xe9\xa1\xb9\xe7\x9b\xae'="采购项目".encode()
encode_purchase_project = b'\xe9\x87\x87\xe8\xb4\xad\xe9\xa1\xb9\xe7\x9b\xae'
bidding_content = ["url;类型;项目名称;招标编号;预算编号;基本概况介绍;交付地址;交付日期;采购预算金额;招标文件获取时间;上传材料;投标截止时间;开标时间;采购人;采购代理机构\n"]
bid_content = ["url;类型;项目名称;项目编号;预算编号;项目总金额;中标供应商;中标供应商地址;中标金额;采购人;代理机构\n"]
#遍历招标信息的分页的招标信息
def getBiddingDetailLinks(html, matchStr):
#招标城市
city = "shanghai"
#类型
bidding_type = "招标文件"
bsObj = BeautifulSoup(html,"html.parser")
for tr in bsObj.findAll("tr",{"odd ","even "}):
if tr.attrs['id'] is not None:
title = tr.find_all("td",limit=2)[1].a.text #中标/招标公告
if(matchStr.decode() == title[0:4]):
bidding_url = "http://www.zfcg.sh.gov.cn/bulletin.do?method=showbulletin&bulletin_id=" + tr.attrs['id']
print(bidding_url)
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
bidding_req = request.Request(bidding_url,headers=headers,)
bidding_response = urlopen(bidding_req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
bidding_buff = bidding_response.read()
bidding_html = bidding_buff.decode("GB18030")
bsDetailObj = BeautifulSoup(bidding_html,"html.parser")
listContent = bsDetailObj.find_all("p","MsoNormal")
if(len(listContent) > 0):
#处理Word转换的HTML页面
if('bidding_name' in dir()):
del bidding_name
if('bidding_time' in dir()):
del bidding_time
if('bidding_description' in dir()):
del bidding_description
for index in range(len(listContent)):
#项目名称
if(encode_bidding_name.decode() in listContent[index].text):
temp_bidding_name = listContent[index].contents[1].text
if('bidding_name' not in dir()):
bidding_name = temp_bidding_name[temp_bidding_name.index(encode_bidding_name.decode()) + 5:]
#assert bidding_name
#招标编号
elif(encode_bidding_number.decode() in listContent[index].text):
temp_bidding_number = listContent[index].contents[1].text
re_bidding_number = temp_bidding_number[temp_bidding_number.index(encode_bidding_number.decode()) + 5:]
bidding_number_group = re.match(r'(\w*-\d*-\d*-\d*)', re_bidding_number)
if bidding_number_group == None:
bidding_number_group2 = re.match(r'(\w*-\w*-\w*)', re_bidding_number)
if bidding_number_group2 == None:
bidding_number_group3 = re.match(r'(\w*-\w*)', re_bidding_number)
if bidding_number_group3 == None:
bidding_number = re.match(r'(\w*)', re_bidding_number).groups()[0]
else:
bidding_number = bidding_number_group3.groups()[0]
else:
bidding_number = bidding_number_group2.groups()[0]
else:
bidding_number = bidding_number_group.groups()[0]
#assert bidding_number
#预算编号
elif(encode_bidding_budget_number.decode() in listContent[index].text):
temp_bidding_budget_number = listContent[index].contents[1].text
re_bidding_budget_number = temp_bidding_budget_number[temp_bidding_budget_number.index(encode_bidding_budget_number.decode()) + 5:]
bidding_budget_number = ''
p = re.compile(r'(\w*-\w*-\w*)')
list_bidding_budget_number = p.split(re_bidding_budget_number)
for idx in range(len(list_bidding_budget_number)):
if(idx == 0 and len(list_bidding_budget_number) == 1):
bidding_budget_number = list_bidding_budget_number[0]
if(idx % 2 == 1):
bidding_budget_number = bidding_budget_number + list_bidding_budget_number[idx]
elif(idx > 0 and idx % 2 == 0 and idx != len(list_bidding_budget_number) - 1):
bidding_budget_number = bidding_budget_number + ','
#bidding_budget_number = re.match(r'(\d*-\w*-\d*)',
#re_bidding_budget_number).groups()[0]
#assert bidding_budget_number
#基本概况介绍(项目主要内容)
elif(encode_bidding_description.decode() in listContent[index].text):
if('bidding_description' not in dir()):
temp_bidding_description = listContent[index + 1].contents[1].textarea.text
bidding_description = temp_bidding_description
#assert bidding_description
#采购预算金额
elif(encode_bidding_purchase_budget.decode() in listContent[index].text):
if bidding_budget_number != '':
temp_bidding_purchase_budget = listContent[index].contents[1].text
re_bidding_purchase_budget = temp_bidding_purchase_budget[temp_bidding_purchase_budget.index(encode_bidding_purchase_budget.decode()) + 7:]
bidding_purchase_budget = re.match(r'(\d*.\d*)', re_bidding_purchase_budget).groups()[0]
#assert bidding_purchase_budget
else:
bidding_purchase_budget = ''
#交付地址
elif(encode_bidding_delivery_address.decode() in listContent[index].text):
temp_bidding_delivery_address = listContent[index].contents[1].text
bidding_delivery_address = temp_bidding_delivery_address[temp_bidding_delivery_address.index(encode_bidding_delivery_address.decode()) + 5:]
#assert bidding_delivery_address
#交付日期
elif(encode_bidding_delivery_date.decode() in listContent[index].text):
temp_bidding_delivery_date = listContent[index].contents[1].text
bidding_delivery_date = temp_bidding_delivery_date[temp_bidding_delivery_date.index(encode_bidding_delivery_date.decode()) + 5:]
#assert bidding_delivery_date
elif(encode_bidding_time.decode() in listContent[index].text and encode_punctuation_mark.decode() in listContent[index].text):
if('bidding_time' not in dir()):
#招标文件获取时间
temp_bidding_time = listContent[index + 1].contents[1].text
if(listContent[index].text.find(encode_bidding_time.decode()) > -1 and encode_bidding_time2.decode() in temp_bidding_time):
bidding_time = temp_bidding_time[temp_bidding_time.index(encode_bidding_time2.decode()) + 8:temp_bidding_time.index(encode_comma.decode()) - temp_bidding_time.index(encode_bidding_time2.decode()) + 2]
if(bidding_time is None):
bidding_time = ''
#上传材料
bidding_upload_file = listContent[index + 2].contents[1].textarea.text
else:
bidding_time = ''
bidding_upload_file = listContent[index + 1].contents[1].textarea.text
#投标截止时间
elif(encode_bidding_deadline.decode() in listContent[index].text and encode_punctuation_mark.decode() in listContent[index].text and listContent[index].contents[1].text[0:1] == '1' and encode_comma.decode() in listContent[index].text):
temp_bidding_deadline = listContent[index].contents[1].text
bidding_deadline = temp_bidding_deadline[temp_bidding_deadline.index(encode_bidding_deadline.decode()) + 7:temp_bidding_deadline.index(encode_comma.decode()) - temp_bidding_deadline.index(encode_bidding_deadline.decode()) + 2]
#assert bidding_deadline
#开标时间
elif(encode_bidding_opening_time.decode() in listContent[index].text and encode_punctuation_mark.decode() in listContent[index].text and listContent[index].contents[1].text[0:1] == '2' and encode_stop.decode() in listContent[index].text):
temp_bidding_opening_time = listContent[index].contents[1].text
bidding_opening_time = temp_bidding_opening_time[temp_bidding_opening_time.index(encode_bidding_opening_time.decode()) + 5:temp_bidding_opening_time.index(encode_stop.decode()) - temp_bidding_opening_time.index(encode_bidding_opening_time.decode()) + 2]
#assert bidding_opening_time
listTR = bsDetailObj.find("tbody").find_all("tr")
for index in range(len(listTR)):
#采购人信息
temp_bidding_purchaser = listTR[index].contents[3].contents[1].text
#采购代理机构信息
temp_bidding_procurement_agency = listTR[index].contents[5].contents[1].text
#采购人姓名
if(encode_bidding_purchaser_name.decode() == temp_bidding_purchaser[0:3]):
bidding_purchaser_name = temp_bidding_purchaser[temp_bidding_purchaser.index(encode_bidding_purchaser_name.decode()) + 4:]
#assert bidding_purchaser_name
#采购人地址
elif(encode_address.decode() == temp_bidding_purchaser[0:2]):
bidding_purchaser_address = temp_bidding_purchaser[temp_bidding_purchaser.index(encode_address.decode()) + 3:]
#assert bidding_purchaser_address
#采购人邮编
elif(encode_zipcode.decode() == temp_bidding_purchaser[0:2]):
bidding_purchaser_zipcode = temp_bidding_purchaser[temp_bidding_purchaser.index(encode_zipcode.decode()) + 3:]
if(bidding_purchaser_zipcode is None):
bidding_purchaser_zipcode = ''
#采购人联系人
elif(encode_contact.decode() == temp_bidding_purchaser[0:3]):
bidding_purchaser_contact = temp_bidding_purchaser[temp_bidding_purchaser.index(encode_contact.decode()) + 4:]
#assert bidding_purchaser_contact
#采购人电话
elif(encode_telephone.decode() == temp_bidding_purchaser[0:2]):
bidding_purchaser_telephone = temp_bidding_purchaser[temp_bidding_purchaser.index(encode_telephone.decode()) + 3:]
#assert bidding_purchaser_telephone
#采购人传真
elif(encode_fax.decode() == temp_bidding_purchaser[0:2]):
bidding_purchaser_fax = temp_bidding_purchaser[temp_bidding_purchaser.index(encode_fax.decode()) + 3:]
#assert bidding_purchaser_fax
#采购代理机构名称
if(encode_bidding_procurement_agency_name.decode() == temp_bidding_procurement_agency[2:6]):
bidding_procurement_agency_name = temp_bidding_procurement_agency[temp_bidding_procurement_agency.index(encode_bidding_procurement_agency_name.decode()) + 5:]
#assert bidding_procurement_agency_name
#采购代理机构地址
elif(encode_address.decode() == temp_bidding_procurement_agency[0:2]):
bidding_procurement_agency_address = temp_bidding_procurement_agency[temp_bidding_procurement_agency.index(encode_address.decode()) + 3:]
#assert bidding_procurement_agency_address
#采购代理机构邮编
elif(encode_zipcode.decode() == temp_bidding_procurement_agency[0:2]):
bidding_procurement_agency_zipcode = temp_bidding_procurement_agency[temp_bidding_procurement_agency.index(encode_zipcode.decode()) + 3:]
#assert bidding_procurement_agency_zipcode
#采购代理机构联系人
elif(encode_contact.decode() == temp_bidding_procurement_agency[0:3]):
bidding_procurement_agency_contact = temp_bidding_procurement_agency[temp_bidding_procurement_agency.index(encode_contact.decode()) + 4:]
#assert bidding_procurement_agency_contact
#采购代理机构电话
elif(encode_telephone.decode() == temp_bidding_procurement_agency[0:2]):
bidding_procurement_agency_telephone = temp_bidding_procurement_agency[temp_bidding_procurement_agency.index(encode_telephone.decode()) + 3:]
#assert bidding_procurement_agency_telephone
#采购人传真
elif(encode_fax.decode() == temp_bidding_procurement_agency[0:2]):
bidding_procurement_agency_fax = temp_bidding_procurement_agency[temp_bidding_procurement_agency.index(encode_fax.decode()) + 3:]
if(bidding_procurement_agency_fax is None):
bidding_procurement_agency_fax = ''
#类型 项目名称 招标编号 预算编号 基本概况介绍 交付地址 交付日期 采购预算金额 招标文件获取时间 上传材料
#投标截止时间
#开标时间 采购人
#采购代理机构
bidding_purchaser_info = bidding_purchaser_name + "|地址:" + bidding_purchaser_address + "|邮编:" + bidding_purchaser_zipcode + "|联系人:" + bidding_purchaser_contact + "|电话:" + bidding_purchaser_telephone + "|传真:" + bidding_purchaser_fax
bidding_procurement_agency_info = bidding_procurement_agency_name + "|地址:" + bidding_procurement_agency_address + "|邮编:" + bidding_purchaser_zipcode + "|联系人:" + bidding_procurement_agency_contact + "|电话:" + bidding_procurement_agency_telephone + "|传真:" + bidding_procurement_agency_fax
bidding_line = bidding_url + ';' + bidding_type + ';' + bidding_name + ';' + bidding_number + ';' + bidding_budget_number + ';' + bidding_description + ';' + bidding_delivery_address + ';' + bidding_delivery_date + ';' + bidding_purchase_budget + ';' + bidding_time + ';' + bidding_upload_file + ';' + bidding_deadline + ';' + bidding_opening_time + ';' + bidding_purchaser_info + ';' + bidding_procurement_agency_info + '\n'
else:
bidding_line = bidding_url + '\n'
bidding_content.append(bidding_line)
return bsObj
#遍历中标信息的分页的中标信息
def getBidDetailLinks(html, matchStr):
#招标城市
city = "shanghai"
#类型
bid_type = '中标文件'
bsObj = BeautifulSoup(html,"html.parser")
for tr in bsObj.findAll("tr",{"odd ","even "}):
if tr.attrs['id'] is not None:
title = tr.find_all("td",limit=2)[1].a.text #中标公告
if(matchStr.decode() == title[0:4] and tr.attrs['id'] != '2018018944'):
bidding_url = "http://www.zfcg.sh.gov.cn/bulletin.do?method=showbulletin&bulletin_id=" + tr.attrs['id']
print(bidding_url)
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
bidding_req = request.Request(bidding_url,headers=headers,)
bidding_response = urlopen(bidding_req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
bidding_buff = bidding_response.read()
bidding_html = bidding_buff.decode("GB18030")
bsDetailObj = BeautifulSoup(bidding_html,"html.parser")
listContent = bsDetailObj.find_all("p","MsoNormal")
if(len(listContent) > 0):
if('bid_provider' in dir()):
del bid_provider
for index in range(len(listContent)):
if encode_because.decode() in listContent[index].text and encode_bid.decode() in listContent[index].text:
temp_bid = listContent[index].contents[1].text
#项目名称
bid_name = temp_bid[temp_bid.index(encode_bid.decode()) + 5:temp_bid.index(encode_bid_number.decode()) - 1]
#assert bid_name
#项目编号
if encode_bid_budget_number.decode() in temp_bid:
bid_number = temp_bid[temp_bid.index(encode_bid_number.decode()) + 5:temp_bid.index(encode_bid_budget_number.decode()) - 1]
else:
bid_number = temp_bid[temp_bid.index(encode_bid_number.decode()) + 5:temp_bid.index(encode_right.decode()) - 1]
#assert bid_number
#预算编号
if encode_bid_budget_number.decode() in temp_bid:
bid_budget_number = temp_bid[temp_bid.index(encode_bid_budget_number.decode()) + 5:temp_bid.index(encode_bid_total_amount.decode()) - 1]
else:
bid_budget_number = ''
#assert bid_budget_number
#项目总金额
if encode_bid_total_amount.decode() in temp_bid:
bid_total_amount = temp_bid[temp_bid.index(encode_bid_total_amount.decode()) + 6:temp_bid.rindex(encode_purchase_project.decode()) - 1]
else:
bid_total_amount = ''
#assert bid_total_amount
elif 'bid_provider' not in dir() and encode_bid_provider.decode() in listContent[index].text and encode_bid_assign_to.decode() in listContent[index].text:
temp_bid = listContent[index].contents[1].text
#中标供应商
if encode_bid_provider_address.decode() in temp_bid:
bid_provider = temp_bid[temp_bid.index(encode_bid_provider.decode()) + 6:temp_bid.index(encode_bid_provider_address.decode()) - 1]
else:
bid_provider = temp_bid[temp_bid.index(encode_bid_provider.decode()) + 6:]
#assert bid_provider
#中标供应商地址
if encode_bid_provider_address.decode() in temp_bid:
bid_provider_address = temp_bid[temp_bid.index(encode_bid_provider_address.decode()) + 8:temp_bid.index(encode_bid_amount.decode()) - 1]
else:
bid_provider_address = ''
#assert bid_provider_address
#中标金额
if encode_bid_amount.decode() in temp_bid:
bid_amount = temp_bid[temp_bid.index(encode_bid_amount.decode()) + 5:]
else:
bid_amount = ''
#assert bid_amount
elif 'bid_provider' not in dir() and encode_bid_provider.decode() in listContent[index].text:
temp_bid = listContent[index].contents[1].text
#中标供应商
bid_provider = temp_bid[temp_bid.index(encode_bid_provider.decode()) + 8:temp_bid.index(encode_bid_provider_address.decode()) - 1]
#assert bid_provider
#中标供应商地址
bid_provider_address = temp_bid[temp_bid.index(encode_bid_provider_address.decode()) + 8:temp_bid.index(encode_bid_amount.decode()) - 1]
#assert bid_provider_address
#中标金额
bid_amount = temp_bid[temp_bid.index(encode_bid_amount.decode()) + 5:-1]
#assert bid_amount
listTR = bsDetailObj.find("tbody").find_all("tr")
for index in range(len(listTR)):
#采购人信息
temp_bid_purchaser = listTR[index].contents[3].contents[1].text
#采购代理机构信息
temp_bid_procurement_agency = listTR[index].contents[5].contents[1].text
#采购人姓名
if(encode_bidding_purchaser_name.decode() == temp_bid_purchaser[0:3]):
bid_purchaser_name = temp_bid_purchaser[temp_bid_purchaser.index(encode_bidding_purchaser_name.decode()) + 4:]
#assert bid_purchaser_name
#采购人地址
elif(encode_address.decode() == temp_bid_purchaser[0:2]):
bid_purchaser_address = temp_bid_purchaser[temp_bid_purchaser.index(encode_address.decode()) + 3:]
#assert bid_purchaser_address
#采购人邮编
elif(encode_zipcode.decode() == temp_bid_purchaser[0:2]):
bid_purchaser_zipcode = temp_bid_purchaser[temp_bid_purchaser.index(encode_zipcode.decode()) + 3:]
#assert bid_purchaser_zipcode
#采购人联系人
elif(encode_contact.decode() == temp_bid_purchaser[0:3]):
bid_purchaser_contact = temp_bid_purchaser[temp_bid_purchaser.index(encode_contact.decode()) + 4:]
#assert bid_purchaser_contact
#采购人电话
elif(encode_telephone.decode() == temp_bid_purchaser[0:2]):
bid_purchaser_telephone = temp_bid_purchaser[temp_bid_purchaser.index(encode_telephone.decode()) + 3:]
#assert bid_purchaser_telephone
#采购人传真
elif(encode_fax.decode() == temp_bid_purchaser[0:2]):
bid_purchaser_fax = temp_bid_purchaser[temp_bid_purchaser.index(encode_fax.decode()) + 3:]
#assert bid_purchaser_fax
#采购代理机构名称
if(encode_bidding_procurement_agency_name.decode() == temp_bid_procurement_agency[0:4]):
bid_procurement_agency_name = temp_bid_procurement_agency[temp_bid_procurement_agency.index(encode_bidding_procurement_agency_name.decode()) + 5:]
#assert bid_procurement_agency_name
#采购代理机构地址
elif(encode_address.decode() == temp_bid_procurement_agency[0:2]):
bid_procurement_agency_address = temp_bid_procurement_agency[temp_bid_procurement_agency.index(encode_address.decode()) + 3:]
#assert bid_procurement_agency_address
#采购代理机构邮编
elif(encode_zipcode.decode() == temp_bid_procurement_agency[0:2]):
bid_procurement_agency_zipcode = temp_bid_procurement_agency[temp_bid_procurement_agency.index(encode_zipcode.decode()) + 3:]
#assert bid_procurement_agency_zipcode
#采购代理机构联系人
elif(encode_contact.decode() == temp_bid_procurement_agency[0:3]):
bid_procurement_agency_contact = temp_bid_procurement_agency[temp_bid_procurement_agency.index(encode_contact.decode()) + 4:]
#assert bid_procurement_agency_contact
#采购代理机构电话
elif(encode_telephone.decode() == temp_bid_procurement_agency[0:2]):
bid_procurement_agency_telephone = temp_bid_procurement_agency[temp_bid_procurement_agency.index(encode_telephone.decode()) + 3:]
#assert bid_procurement_agency_telephone
#采购人传真
elif(encode_fax.decode() == temp_bid_procurement_agency[0:2]):
bid_procurement_agency_fax = temp_bid_procurement_agency[temp_bid_procurement_agency.index(encode_fax.decode()) + 3:]
if(bid_procurement_agency_fax is None):
bid_procurement_agency_fax = ''
#类型 项目名称 项目编号 预算编号 项目总金额 中标供应商 中标供应商地址 中标金额 采购人 代理机构
bid_purchaser_info = bid_purchaser_name + "|地址:" + bid_purchaser_address + "|邮编:" + bid_purchaser_zipcode + "|联系人:" + bid_purchaser_contact + "|电话:" + bid_purchaser_telephone + "|传真:" + bid_purchaser_fax
bid_procurement_agency_info = bid_procurement_agency_name + "|地址:" + bid_procurement_agency_address + "|邮编:" + bid_purchaser_zipcode + "|联系人:" + bid_procurement_agency_contact + "|电话:" + bid_procurement_agency_telephone + "|传真:" + bid_procurement_agency_fax
bid_line = bidding_url + ';' + bid_type + ';' + bid_name + ';' + bid_number + ';' + bid_budget_number + ';' + bid_total_amount + ';' + bid_provider + ';' + bid_provider_address + ';' + bid_amount + ';' + bid_purchaser_info + ';' + bid_procurement_agency_info + '\n'
else:
bid_line = bidding_url + '\n'
bid_content.append(bid_line)
return bsObj
#遍历招标信息的主页的招标信息
def getAllBiddingLinks(siteUrl, matchStr):
opener = urllib.request.build_opener(urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
quoteUrl = quote(siteUrl, safe='/:?=&#')
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
req = request.Request(quoteUrl,headers=headers,)
response = urlopen(req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
buff = response.read()
html = buff.decode("GB18030")
#解析招标信息的主页,并找到所有的招标详细页
bsObj = getBiddingDetailLinks(html, matchStr)
#获取招标信息的分页数量
pages = bsObj.find(attrs={"name": "bulletininfotable_totalpages"}).attrs["value"]
tempTotalPages = bsObj.find_all("nobr")[0].text
totalPages = re.match(r'/(\d*)页', tempTotalPages).groups()[0]
tempTotalRows = bsObj.find("td","statusTool").text
totalRows = re.match(r'共(\d*)条记录,显示1到10', tempTotalRows).groups()[0]
pagelist = list(range(2, int(pages)))
for index in range(len(pagelist)):
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
payload = {'ec_i': 'bulletininfotable', 'bulletininfotable_efn': '', 'bulletininfotable_crd': '10', 'bulletininfotable_p': str(pagelist[index]), 'bulletininfotable_s_bulletintitle': '', 'bulletininfotable_s_beginday': '', 'treenum': '05', 'title': '采购公告', 'treenumfalse': '', 'method': 'bdetail', 'bulletininfotable_totalpages': totalPages, 'bulletininfotable_totalrows': totalRows, 'bulletininfotable_pg': str(pagelist[index] - 1), 'bulletininfotable_rd': '10', 'findAjaxZoneAtClient': 'false'}
r = requests.post(quote("http://www.zfcg.sh.gov.cn/bulletininfo.do?method=bdetail&treenum=05&title=采购公告&treenumfalse=#", safe='/:?=&#'), data=payload)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
pageBuff = r._content
pageHTML = pageBuff.decode("GB18030")
#解析招标信息的分页,并找到所有的中标/招标详细页
getBiddingDetailLinks(pageHTML, matchStr)
with open(r'C:\Temp\BiddingDocuments.txt', 'w', encoding='utf-8') as f_bidding:
for index in range(len(bidding_content)):
f_bidding.write(bidding_content[index])
#遍历中标信息的主页的中标信息
def getAllBidLinks(siteUrl, matchStr):
opener = urllib.request.build_opener(urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
quoteUrl = quote(siteUrl, safe='/:?=&#')
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
req = request.Request(quoteUrl,headers=headers,)
response = urlopen(req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
buff = response.read()
html = buff.decode("GB18030")
#解析中标信息的主页,并找到所有的中标详细页
bsObj = getBidDetailLinks(html, matchStr)
#获取中标信息的分页数量
pages = bsObj.find(attrs={"name": "bulletininfotable_totalpages"}).attrs["value"]
tempTotalPages = bsObj.find_all("nobr")[0].text
totalPages = re.match(r'/(\d*)页', tempTotalPages).groups()[0]
tempTotalRows = bsObj.find("td","statusTool").text
totalRows = re.match(r'共(\d*)条记录,显示1到10', tempTotalRows).groups()[0]
pagelist = list(range(2, int(pages)))
for index in range(len(pagelist)):
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
payload = {'ec_i': 'bulletininfotable', 'bulletininfotable_efn': '', 'bulletininfotable_crd': '10', 'bulletininfotable_p': str(pagelist[index]), 'bulletininfotable_s_bulletintitle': '', 'bulletininfotable_s_beginday': '', 'treenum': '13', 'title': '中标公告', 'treenumfalse': '', 'method': 'bdetail', 'bulletininfotable_totalpages': totalPages, 'bulletininfotable_totalrows': totalRows, 'bulletininfotable_pg': str(pagelist[index] - 1), 'bulletininfotable_rd': '10', 'findAjaxZoneAtClient': 'false'}
r = requests.post(quote("http://www.zfcg.sh.gov.cn/bulletininfo.do?method=bdetail&treenum=13&title=中标公告&treenumfalse=#", safe='/:?=&#'), data=payload)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
pageBuff = r._content
pageHTML = pageBuff.decode("GB18030")
#解析中标信息的分页,并找到所有的中标/招标详细页
getBidDetailLinks(pageHTML, matchStr)
with open(r'C:\Temp\BidDocuments.txt', 'w', encoding='utf-8') as f_bid:
for index in range(len(bid_content)):
f_bid.write(bid_content[index])
def getShanghaiBiddingAndBidInfo():
#采购公告
#b'\xe6\x8b\x9b\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'="招标公告".encode()
matchStr = b'\xe6\x8b\x9b\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'
#http://www.zfcg.sh.gov.cn/bulletininfo.do?method=bdetailnew&treenum=17&treenumfalse=
getAllBiddingLinks("http://www.zfcg.sh.gov.cn/bulletininfo.do?method=bdetail&treenum=05&title=采购公告&treenumfalse=#",matchStr)
#中标公告
#b'\xe4\xb8\xad\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'="中标公告".encode()
matchStr = b'\xe4\xb8\xad\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'
getAllBidLinks("http://www.zfcg.sh.gov.cn/bulletininfo.do?method=bdetail&treenum=13&title=中标公告&treenumfalse=", matchStr)
#获取上海政府采购公告和中标公告
getShanghaiBiddingAndBidInfo()
获取江西省政府采购和中标的信息链接
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.parse import quote
from bs4 import BeautifulSoup
import urllib
from urllib import request
from time import sleep
'''
江西省采购网
'''
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
#遍历当前页面中的中标/招标信息
def getAllBiddingLinks(siteUrl, matchStr):
opener = urllib.request.build_opener(urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
quoteUrl = quote(siteUrl, safe='/:?=&#')
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
req = request.Request(quoteUrl,headers=headers,)
response = urlopen(req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
buff = response.read()
html = buff.decode("gbk")
bsObj = BeautifulSoup(html,"html.parser")
for td in bsObj.findAll("td","pp"):
if td.a is not None:
title = td.a.attrs["title"] #中标/招标公告
href = td.a.attrs["href"]
if(matchStr.decode() in title):
bidding_url = siteUrl + href[2:]
print(bidding_url)
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
bidding_req = request.Request(bidding_url,headers=headers,)
bidding_response = urlopen(bidding_req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
bidding_buff = bidding_response.read()
bidding_html = bidding_buff.decode("gbk")
#采购公告
#b'\xe6\x8b\x9b\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'="招标公告".encode()
matchStr = b'\xe6\x8b\x9b\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'
getAllBiddingLinks("http://www.jxtb.org.cn/zbgg/", matchStr)
#中标公告
#b'\xe4\xb8\xad\xe6\xa0\x87'="中标".encode()
matchStr = b'\xe4\xb8\xad\xe6\xa0\x87'
getAllBiddingLinks("http://www.jxtb.org.cn/zbjg/", matchStr)
获取山东省政府采购和中标的信息链接
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.parse import quote
from bs4 import BeautifulSoup
import urllib
from urllib import request
from time import sleep
'''
山东省采购网
'''
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
#遍历当前页面中的中标/招标信息
def getAllBiddingLinks(siteUrl, matchStr):
opener = urllib.request.build_opener(urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
quoteUrl = quote(siteUrl, safe='/:?=&#')
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
req = request.Request(quoteUrl,headers=headers,)
response = urlopen(req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
buff = response.read()
html = buff.decode("gbk")
bsObj = BeautifulSoup(html,"html.parser")
for a in bsObj.findAll("a","aa"):
title = a.attrs["title"] #中标/招标公告
href = a.attrs["href"]
if(matchStr.decode() in title):
bidding_url = "http://www.ccgp-shandong.gov.cn/" + href[1:]
print(bidding_url)
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
bidding_req = request.Request(bidding_url,headers=headers,)
bidding_response = urlopen(bidding_req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
bidding_buff = bidding_response.read()
bidding_html = bidding_buff.decode("gbk")
#b'\xe6\x8b\x9b\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'="招标公告".encode()
matchStr = b'\xe6\x8b\x9b\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'
#省采购公告
getAllBiddingLinks("http://www.ccgp-shandong.gov.cn/sdgp2014/site/channelall.jsp?colcode=0301", matchStr)
#市县采购公告
getAllBiddingLinks("http://www.ccgp-shandong.gov.cn/sdgp2014/site/channelall.jsp?colcode=0303", matchStr)
#b'\xe4\xb8\xad\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'="中标公告".encode()
matchStr = b'\xe4\xb8\xad\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'
#省中标公告
getAllBiddingLinks("http://www.ccgp-shandong.gov.cn/sdgp2014/site/channelall.jsp?colcode=0302", matchStr)
#市县中标公告
getAllBiddingLinks("http://www.ccgp-shandong.gov.cn/sdgp2014/site/channelall.jsp?colcode=0304", matchStr)
获取贵州省政府采购和中标的信息链接
from bs4 import BeautifulSoup
from urllib.request import urlopen
from urllib.parse import quote
from bs4 import BeautifulSoup
import urllib
from urllib import request
from time import sleep
'''
贵州省采购网
'''
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
#遍历当前页面中的中标/招标信息
def getAllBiddingLinks(siteUrl, matchStr):
opener = urllib.request.build_opener(urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
quoteUrl = quote(siteUrl, safe='/:?=&#')
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
req = request.Request(quoteUrl,headers=headers,)
response = urlopen(req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
buff = response.read()
html = buff.decode("utf-8")
bsObj = BeautifulSoup(html,"html.parser")
for a in bsObj.find("div","xnrx").findAll("a"):
title = a.text #中标/招标公告
href = a.attrs["href"]
if(matchStr.decode() in title):
bidding_url = "http://www.ccgp-guizhou.gov.cn/" + href[1:]
print(bidding_url)
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
bidding_req = request.Request(bidding_url,headers=headers,)
bidding_response = urlopen(bidding_req)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
bidding_buff = bidding_response.read()
bidding_html = bidding_buff.decode("utf-8")
#采购公告
#b'\xe6\x8b\x9b\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'="招标公告".encode()
matchStr = b'\xe6\x8b\x9b\xe6\xa0\x87\xe5\x85\xac\xe5\x91\x8a'
getAllBiddingLinks("http://www.ccgp-guizhou.gov.cn/list-1153797950913584.html", matchStr)
#中标公告
#b'\xe4\xb8\xad\xe6\xa0\x87'="中标".encode()
matchStr = b'\xe4\xb8\xad\xe6\xa0\x87'
getAllBiddingLinks("http://www.ccgp-guizhou.gov.cn/list-1153905922931045.html", matchStr)
百度地图网站爬虫
获取百度地图经纬度范围内的特定地点
零基础掌握百度地图兴趣点获取POI爬虫(python语言爬取)(代码篇)
2017年12月07日 21:45:34
阅读数:1062
好,现在进入高阶代码篇。
目的:
爬取昆明市中学的兴趣点POI。
关键词:中学
已有ak:9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
昆明市坐标范围:
左下角:24.390894,102.174112
右上角:26.548645,103.678942
上海市坐标范围:
URL模板:
http://api.map.baidu.com/place/v2/search?query=中学& bounds=24.390894,102.174112,26.548645,103.678942&page_size=20&page_num=0&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
工具:python2.7
我们将使用python语言来写爬虫代码。
1.功能分解
先把这个爬虫要实现的功能做一个分解。
已经知道在这个URL中,变量是bounds和page_num的值。
Bounds范围值要采取矩形分割,分4个矩形,就是4组坐标范围,page_num的值从0到19之间。
1组坐标范围20个page_num值,4×20=80。要生成的URL阵列是80个。
每个URL都能生成一个网页,每个网页上的信息都要被爬下来,保存到一个txt文件中。
A.根据bounds和page_num组合生成URL。
B.根据URL爬取网页数据,添加到txt文件中。
这将是一个循环代码:
Bounds=[矩形1,矩形2,矩形3,矩形4]
Page_nums=[0、1、2……19]
For 矩形 in bounds:
For page_num in page_nums:
URL=http://api.map.baidu.com/place/v2/search?query=中学& bounds=矩形&page_size=20&page_num=page_num&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
URL内容爬取,添加入txt文件
Next
Next
End
这个代码的框架说完了。
然后进入每个功能的代码如何实现环节。
2.功能代码实现。
代码要实现的功能是哪几个呢?
按照步骤分:
A.bounds列表的生成。
B.URL列表的生成。
C.爬取的网页内容保存到txt文本中。
(1)bounds列表生成
再说一下,因为这个是零基础教程,所以我会讲解得非常细致,python代码会由浅入深,从最简单最基础的开始。
我们看一下坐标范围:
左下角:24.390894,102.174112
右上角:26.548645,103.678942
纬度差是2.157751,经度差是1.50483。
用代码表示一下坐标范围:
lat_1=24.390894
lon_1=102.174112
lat_2=26.548645
lon_2=103.678942
lat是纬度的英文,lon是经度的英文。
我们切分矩形的话,这个矩形的坐标肯定是由上面这几个坐标范围计算的来的,内插运算。
为了计算简便,我们就切方形吧,这个方形的边长我们设定一个值,假设是las(length of a side,边长英文)。
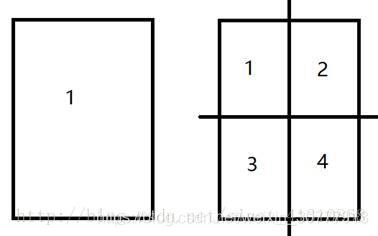
那么第一个矩形的左下角坐标是lat_1+las,lon_1,右上角坐标是lat_1+las2,lon_1+las;第二个矩形的左下角坐标是lat_1+las,lon_1+las,右上角坐标是lat_1+las2,lon_1+las2……
我们设定的计算规则是:
整个坐标范围的大矩形我们叫它矩形A,切分的小矩形我们叫它矩形B。
矩形A的左下角坐标是:lat_1,lon_1,右上角坐标是lat_2,lon_2;
矩形B的边长是las。
那么计算一下矩形B的数量:
(int((lat_2-lat_1)/las)+1)(int((lon_2-lon_1)/las)+1)
int是一个取整函数。
int(1.334)=1
int((lat_2-lat_1)/las)+1计算的是在纬度上切了几个,int((lon_2-lon_1)/las)+1计算的是在经度上切了几个,乘积就是一共几个矩形。
我们看下面一段代码:
lat_1=24.390894
lon_1=102.174112
lat_2=26.548645
lon_2=103.678942 #坐标范围
las=1 #给las一个值1
lat_count=int((lat_2-lat_1)/las+1)
lon_count=int((lon_2-lon_1)/las+1)
for lat_c in range(0,lat_count):
lat_b1=lat_1+las*lat_c
for lon_c in range(0,lon_count):
lon_b1=lon_1+las*lon_c
print str(lat_b1)+','+str(lon_b1)
#这段代码生成的是矩形B的左下角坐标
24.390894,102.174112
24.390894,103.174112
25.390894,102.174112
25.390894,103.174112
26.390894,102.174112
26.390894,103.174112
因为我把las设置为1了,所以切出来6个矩形,这是这六个矩形的左下角坐标。
这行代码很简单,只涉及到两组内嵌的循环语句:for lat_c in range(0,lat_count):
用VB语言翻译一下这行就是 for lat_c=0 to lat_count step 1。
说明几个注意点:
a.python语言不需要声明变量。
b.for语句后面的:别忘了。
c.range(0,3)是[0,1,2],3不在数组里面,好好理解一下函数关系,这么个算法,说明左下角坐标是正好的,不会多一个。
d.python没有结束循环的语句,靠回车,表示嵌套关系靠的“ ”,四个空格,for语句冒号后面跟着的那行,比for语句后退了四个空格,说明这个语句是在for循环中的,如果语句要跳出for循环的话,那么就删掉四个空格,表示跳出循环。这是一个很有意思的python写码规则。
我们把这段代码改一改,获取矩形B的范围坐标:
lat_1=24.390894
lon_1=102.174112
lat_2=26.548645
lon_2=103.678942 #坐标范围
las=1 #给las一个值1
lat_count=int((lat_2-lat_1)/las+1)
lon_count=int((lon_2-lon_1)/las+1)
for lat_c in range(0,lat_count):
lat_b1=lat_1+las*lat_c
for lon_c in range(0,lon_count):
lon_b1=lon_1+las*lon_c
print str(lat_b1)+','+str(lon_b1)+','+str(lat_b1+las)+','+str(lon_b1+las)
#这段代码生成的是矩形B的范围坐标
运行结果如下:
24.390894,102.174112,25.390894,103.174112
24.390894,103.174112,25.390894,104.174112
25.390894,102.174112,26.390894,103.174112
25.390894,103.174112,26.390894,104.174112
26.390894,102.174112,27.390894,103.174112
26.390894,103.174112,27.390894,104.174112
好好理解一下这行代码。
(2)URL列表生成:
bounds列表生成之后,page_num在range(0,20)中遍历一遍,就生成了URL列表了。
代码如下:

看看这张图,好好理解一下循环与空格之间的关系,python没有结束循环的语句,就靠空格来做嵌套。
把这段代码完善一下,主要是URL那段怎么写。
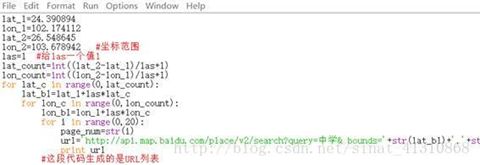
其中:
url=’http://api.map.baidu.com/place/v2/search?query=中学& bounds=’+str(lat_b1)+’,’+str(lon_b1)+’,’+str(lat_b1+las)+’,’+str(lon_b1+las)+’&page_size=20&page_num=’+str(page_num)+’&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO’
print url
URL列表也生成了,是不是曙光在望了?
继续!
(3)网页解析
我们先学习一下网页的爬取,依然用这行URL来学习。
http://api.map.baidu.com/place/v2/search?query=中学& bounds=24.390894,102.174112,26.548645,103.678942&page_size=20&page_num=0&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
我用的python2.7,我们写一段代码,把这个URL上的数据爬下来。
打开IDLE,file——new file(ctrl+n),新建一个py文件,在里面敲代码。当然也可以在python shell里面一行一行敲,对于初学者来说,这种方式比较合适,一行一行敲,错了就有提示。
我们简单敲入一段代码,看看怎么爬取网页:
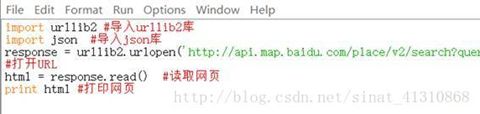
在代码的最开始,我们看到导入了两个库,一个是urllib2库,一个是json,这是要解析百度开放平台URL必须要导入的两个库,urllib2是做网页解析的,而URL中,我们仔细查看,会看到“output=json”,URL的网页输出是以这种格式输出的。
输出结果如下:

但显然,我们不需要这样的数据,在结果“results”中,我们只需要name、lat、lng、address的值,这时候,就需要对json数据格式进行解析了。
我们把这段代码修改一下:

与上文不同的是,我们还导入了一个sys库,解释如图。
用加载的方式,json.load(response)在python中载入了URL生成的json数据,用一个循环读入了json数据中的results中name,仔细观察json数据结构就能理解这些代码。
运行结果如下:

当然,我们要获取的是四个值,name、lat、lng、address,那么把这行代码改写一下吧!
改写的代码部分如下:
for item in data['results']:
jname=item['name']
jlat=item['location']['lat']
jlon=item['location']['lng']
jadd=item['address']
(5)python默认编码问题。
python默认的编码是ASCII,不过URL解析的json文件编码是uft-8。
如果不对编码方式进行重新设定,就会出现中文乱码问题。
把python默认编码从ascii转到uft-8的代码是固定的。
# -*- coding:utf-8 -*
import os
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
把这段代码放在代码前端即可。
我们将要实现的代码前端如图,保证代码行的顺序。

(6)txt文件写入
f=open(r'D:\python\kunmingschool.txt','a')
f.write('zhongxue')
f.close()
这是一段最简单的文本写入代码,打开D:\python\kunmingschool.txt这个文件,以添加方式写入,写入zhongxue,把文件关闭。
A.文件全路径前面加一个r,这是防止字符转译的,就是怕识别不了路径。
B.a的意思是以添加方式写入,如果是w的话,就是覆盖方式写入。
C.写入完成后,要把文件关闭,close(),括号别忘了。
把网页解析和txt文件写入,联合一下。
还是把这个URL上的内容写入txt文件,文件的全路径是D:\python\kunmingschool.txt。
http://api.map.baidu.com/place/v2/search?query=中学& bounds=24.390894,102.174112,26.548645,103.678942&page_size=20&page_num=0&output=json&ak=9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO
这段的代码如下:
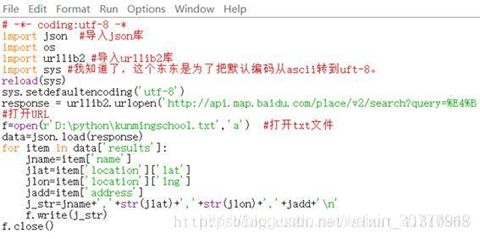
n\是python里面的换行符。
运行结果如下图:

至此,要用到的功能代码,我们都会了,现在只要把它们都组合到一切就可以了。
3.全部代码
import json
from urllib.parse import quote
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
#shanghai
lat_1 = 30.6667
lon_1 = 120.85
lat_2 = 31.8833
lon_2 = 122.2
#kunming
'''
lat_1 = 24.390894
lon_1 = 102.174112
lat_2 = 26.548645
lon_2 = 103.678942
'''
las = 1 #?las???1
ak = '9s5GSYZsWbMaFU8Ps2V2VWvDlDlqGaaO'
keyword = b'\xe6\xb6\x82\xe6\x96\x99\xe5\xba\x97' #b'\xe6\xb6\x82\xe6\x96\x99\xe5\xba\x97'='涂料店'.encode()
push = r'C:\Temp\shanghai.txt'
def start_catch_data():
f = open(push,'w',encoding='utf-8')
lat_count = int((lat_2 - lat_1) / las + 1)
lon_count = int((lon_2 - lon_1) / las + 1)
for lat_c in range(0,lat_count):
lat_b1 = lat_1 + las * lat_c
for lon_c in range(0,lon_count):
lon_b1 = lon_1 + las * lon_c
for i in range(0,5):
if('total' in dir()):
if(i * 20 >= total):
break
page_num = str(i)
url = 'http://api.map.baidu.com/place/v2/search?query=' + keyword.decode() + '&bounds=' + str(lat_b1) + ',' + str(lon_b1) + ',' + str(lat_b1 + las) + ',' + str(lon_b1 + las) + '&page_size=20&page_num=' + str(page_num) + '&output=json&ak=' + ak
print(url)
quoteUrl = quote(url, safe='/:?=&#')
response = requests.get(quoteUrl,)
json_data = response.text
data = json.loads(json_data)
if(data['status'] != 401):
if(int(data['total']) > 1):
for item in data['results']:
jname = item['name']
#print(item)
if(item['location'] != None):
jlat = item['location']['lat']
jlon = item['location']['lng']
jadd = item['address']
j_str = jname + '\t' + str(jlat) + '\t' + str(jlon) + '\t' + jadd + '\n'
f.write(j_str)
f.close()
start_catch_data()
获取百度地图指定城市的特定地点
import json
from urllib.parse import quote
import requests
from time import sleep
#HTTP请求的头部
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
#百度地图API的KEY
ak = '597a11f21bf9dfd3ab95632271b3832c'
#百度地图数据的搜索关键字
keyword = b'\xe6\xb6\x82\xe6\x96\x99' #b'\xe6\xb6\x82\xe6\x96\x99'='涂料'.encode()
#结果文件保存路径
directory = "C:\\Temp\\"
#b'\xe7\x9c\x81\xe4\xbb\xbd\t\xe5\x9f\x8e\xe5\xb8\x82\t\xe5\x9c\xb0\xe5\x8c\xba\t\xe5\x95\x86\xe9\x93\xba\xe5\x90\x8d\xe7\xa7\xb0\t\xe7\xbb\x8f\xe7\xba\xac\xe5\xba\xa6\t\xe7\x94\xb5\xe8\xaf\x9d\t\xe5\x9c\xb0\xe5\x9d\x80'="省份\t城市\t地区\t商铺名称\t经纬度\t电话\t地址".encode()
table_head = b'\xe7\x9c\x81\xe4\xbb\xbd\t\xe5\x9f\x8e\xe5\xb8\x82\t\xe5\x9c\xb0\xe5\x8c\xba\t\xe5\x95\x86\xe9\x93\xba\xe5\x90\x8d\xe7\xa7\xb0\t\xe7\xbb\x8f\xe7\xba\xac\xe5\xba\xa6\t\xe7\x94\xb5\xe8\xaf\x9d\t\xe5\x9c\xb0\xe5\x9d\x80'
#结果列表
content = [table_head.decode() + '\n']
key_value = {192:b'\xe5\xae\x81\xe5\xbe\xb7\xe5\xb8\x82', #宁德市
300:b'\xe7\xa6\x8f\xe5\xb7\x9e\xe5\xb8\x82', #福州市
195:b'\xe8\x8e\x86\xe7\x94\xb0\xe5\xb8\x82', #莆田市
119:b'\xe4\xb8\x9c\xe8\x8e\x9e\xe5\xb8\x82', #东莞市
134:b'\xe6\xb3\x89\xe5\xb7\x9e\xe5\xb8\x82', #泉州市
255:b'\xe6\xbc\xb3\xe5\xb7\x9e\xe5\xb8\x82', #漳州市
2758:b'\xe6\x96\x87\xe6\x98\x8c\xe5\xb8\x82', #文昌市
139:b'\xe8\x8c\x82\xe5\x90\x8d\xe5\xb8\x82', #茂名市
187:b'\xe4\xb8\xad\xe5\xb1\xb1\xe5\xb8\x82', #中山市
301:b'\xe6\x83\xa0\xe5\xb7\x9e\xe5\xb8\x82', #惠州市
141:b'\xe6\xa2\x85\xe5\xb7\x9e\xe5\xb8\x82', #梅州市
159:b'\xe8\xa1\xa1\xe9\x98\xb3\xe5\xb8\x82', #衡阳市
158:b'\xe9\x95\xbf\xe6\xb2\x99\xe5\xb8\x82', #长沙市
236:b'\xe9\x9d\x92\xe5\xb2\x9b\xe5\xb8\x82', #青岛市
283:b'\xe9\x84\x82\xe5\xb0\x94\xe5\xa4\x9a\xe6\x96\xaf\xe5\xb8\x82', #鄂尔多斯市
191:b'\xe5\xbb\x8a\xe5\x9d\x8a\xe5\xb8\x82', #廊坊市
150:b'\xe7\x9f\xb3\xe5\xae\xb6\xe5\xba\x84\xe5\xb8\x82', #石家庄市
307:b'\xe4\xbf\x9d\xe5\xae\x9a\xe5\xb8\x82', #保定市
151:b'\xe9\x82\xaf\xe9\x83\xb8\xe5\xb8\x82', #邯郸市
154:b'\xe5\x95\x86\xe4\xb8\x98\xe5\xb8\x82', #商丘市
214:b'\xe4\xbf\xa1\xe9\x98\xb3\xe5\xb8\x82', #信阳市
286:b'\xe6\xb5\x8e\xe5\xae\x81\xe5\xb8\x82', #济宁市
172:b'\xe6\x9e\xa3\xe5\xba\x84\xe5\xb8\x82', #枣庄市
179:b'\xe6\x9d\xad\xe5\xb7\x9e\xe5\xb8\x82', #杭州市
293:b'\xe7\xbb\x8d\xe5\x85\xb4\xe5\xb8\x82', #绍兴市
224:b'\xe8\x8b\x8f\xe5\xb7\x9e\xe5\xb8\x82', #苏州市
334:b'\xe5\x98\x89\xe5\x85\xb4\xe5\xb8\x82', #嘉兴市
294:b'\xe6\xb9\x96\xe5\xb7\x9e\xe5\xb8\x82', #湖州市
270:b'\xe5\xae\x9c\xe6\x98\x8c\xe5\xb8\x82', #宜昌市
157:b'\xe8\x8d\x86\xe5\xb7\x9e\xe5\xb8\x82', #荆州市
373:b'\xe6\x81\xa9\xe6\x96\xbd\xe5\x9c\x9f\xe5\xae\xb6\xe6\x97\x8f\xe8\x8b\x97\xe6\x97\x8f\xe8\x87\xaa\xe6\xb2\xbb\xe5\xb7\x9e', #恩施土家族苗族自治州
333:b'\xe9\x87\x91\xe5\x8d\x8e\xe5\xb8\x82', #金华市
243:b'\xe8\xa1\xa2\xe5\xb7\x9e\xe5\xb8\x82', #衢州市
178:b'\xe6\xb8\xa9\xe5\xb7\x9e\xe5\xb8\x82', #温州市
223:b'\xe7\x9b\x90\xe5\x9f\x8e\xe5\xb8\x82', #盐城市
347:b'\xe8\xbf\x9e\xe4\xba\x91\xe6\xb8\xaf\xe5\xb8\x82', #连云港市
162:b'\xe6\xb7\xae\xe5\xae\x89\xe5\xb8\x82', #淮安市
316:b'\xe5\xbe\x90\xe5\xb7\x9e\xe5\xb8\x82', #徐州市
277:b'\xe5\xae\xbf\xe8\xbf\x81\xe5\xb8\x82', #宿迁市
180:b'\xe5\xae\x81\xe6\xb3\xa2\xe5\xb8\x82', #宁波市
244:b'\xe5\x8f\xb0\xe5\xb7\x9e\xe5\xb8\x82', #台州市
346:b'\xe6\x89\xac\xe5\xb7\x9e\xe5\xb8\x82', #扬州市
276:b'\xe6\xb3\xb0\xe5\xb7\x9e\xe5\xb8\x82', #泰州市
161:b'\xe5\x8d\x97\xe9\x80\x9a\xe5\xb8\x82', #南通市
348:b'\xe5\xb8\xb8\xe5\xb7\x9e\xe5\xb8\x82', #常州市
160:b'\xe9\x95\x87\xe6\xb1\x9f\xe5\xb8\x82', #镇江市
129:b'\xe8\x8a\x9c\xe6\xb9\x96\xe5\xb8\x82', #芜湖市
127:b'\xe5\x90\x88\xe8\x82\xa5\xe5\xb8\x82', #合肥市
317:b'\xe6\x97\xa0\xe9\x94\xa1\xe5\xb8\x82', #无锡市
1713:b'\xe4\xbb\x99\xe6\xa1\x83\xe5\xb8\x82', #仙桃市
1293:b'\xe6\xbd\x9c\xe6\xb1\x9f\xe5\xb8\x82', #潜江市
2654:b'\xe5\xa4\xa9\xe9\x97\xa8\xe5\xb8\x82', #天门市
189:b'\xe6\xbb\x81\xe5\xb7\x9e\xe5\xb8\x82', #滁州市
132:b'\xe9\x87\x8d\xe5\xba\x86\xe5\xb8\x82', #重庆市
93:b'\xe6\x98\x8c\xe5\x90\x89\xe5\x9b\x9e\xe6\x97\x8f\xe8\x87\xaa\xe6\xb2\xbb\xe5\xb7\x9e', #昌吉回族自治州
80:b'\xe5\x87\x89\xe5\xb1\xb1\xe5\xbd\x9d\xe6\x97\x8f\xe8\x87\xaa\xe6\xb2\xbb\xe5\xb7\x9e', #凉山彝族自治州
105:b'\xe6\xa5\x9a\xe9\x9b\x84\xe5\xbd\x9d\xe6\x97\x8f\xe8\x87\xaa\xe6\xb2\xbb\xe5\xb7\x9e', #楚雄彝族自治州
262:b'\xe9\x81\xb5\xe4\xb9\x89\xe5\xb8\x82', #遵义市
205:b'\xe9\x93\x9c\xe4\xbb\x81\xe5\x9c\xb0\xe5\x8c\xba', #铜仁地区
343:b'\xe9\xbb\x94\xe8\xa5\xbf\xe5\x8d\x97\xe5\xb8\x83\xe4\xbe\x9d\xe6\x97\x8f\xe8\x8b\x97\xe6\x97\x8f\xe8\x87\xaa\xe6\xb2\xbb\xe5\xb7\x9e', #黔西南布依族苗族自治州
75:b'\xe6\x88\x90\xe9\x83\xbd\xe5\xb8\x82', #成都市
109:b'\xe8\xa5\xbf\xe5\x8f\x8c\xe7\x89\x88\xe7\xba\xb3\xe5\x82\xa3\xe6\x97\x8f\xe8\x87\xaa\xe6\xb2\xbb\xe5\xb7\x9e', #西双版纳傣族自治州
111:b'\xe5\xa4\xa7\xe7\x90\x86\xe7\x99\xbd\xe6\x97\x8f\xe8\x87\xaa\xe6\xb2\xbb\xe5\xb7\x9e', #大理白族自治州
116:b'\xe5\xbe\xb7\xe5\xae\x8f\xe5\x82\xa3\xe6\x97\x8f\xe6\x99\xaf\xe9\xa2\x87\xe6\x97\x8f\xe8\x87\xaa\xe6\xb2\xbb\xe5\xb7\x9e', #德宏傣族景颇族自治州
268:b'\xe9\x83\x91\xe5\xb7\x9e\xe5\xb8\x82', #郑州市
340:b'\xe6\xb7\xb1\xe5\x9c\xb3\xe5\xb8\x82', #深圳市
257:b'\xe5\xb9\xbf\xe5\xb7\x9e\xe5\xb8\x82', #广州市
332:b'\xe5\xa4\xa9\xe6\xb4\xa5\xe5\xb8\x82', #天津市
131:b'\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82', #北京市
289:b'\xe4\xb8\x8a\xe6\xb5\xb7\xe5\xb8\x82', #上海市
261:b'\xe5\x8d\x97\xe5\xae\x81\xe5\xb8\x82', #南宁市
163:b'\xe5\x8d\x97\xe6\x98\x8c\xe5\xb8\x82', #南昌市
194:b'\xe5\x8e\xa6\xe9\x97\xa8\xe5\xb8\x82', #厦门市
125:b'\xe6\xb5\xb7\xe5\x8f\xa3\xe5\xb8\x82', #海口市
198:b'\xe6\xb9\x9b\xe6\xb1\x9f\xe5\xb8\x82', #湛江市
138:b'\xe4\xbd\x9b\xe5\xb1\xb1\xe5\xb8\x82', #佛山市
140:b'\xe7\x8f\xa0\xe6\xb5\xb7\xe5\xb8\x82', #珠海市
302:b'\xe6\xb1\x9f\xe9\x97\xa8\xe5\xb8\x82', #江门市
303:b'\xe6\xb1\x95\xe5\xa4\xb4\xe5\xb8\x82', #汕头市
287:b'\xe6\xbd\x8d\xe5\x9d\x8a\xe5\xb8\x82', #潍坊市
326:b'\xe7\x83\x9f\xe5\x8f\xb0\xe5\xb8\x82', #烟台市
58:b'\xe6\xb2\x88\xe9\x98\xb3\xe5\xb8\x82', #沈阳市
48:b'\xe5\x93\x88\xe5\xb0\x94\xe6\xbb\xa8\xe5\xb8\x82', #哈尔滨市
53:b'\xe9\x95\xbf\xe6\x98\xa5\xe5\xb8\x82', #长春市
321:b'\xe5\x91\xbc\xe5\x92\x8c\xe6\xb5\xa9\xe7\x89\xb9\xe5\xb8\x82', #呼和浩特市
229:b'\xe5\x8c\x85\xe5\xa4\xb4\xe5\xb8\x82', #包头市
176:b'\xe5\xa4\xaa\xe5\x8e\x9f\xe5\xb8\x82', #太原市
167:b'\xe5\xa4\xa7\xe8\xbf\x9e\xe5\xb8\x82', #大连市
153:b'\xe6\xb4\x9b\xe9\x98\xb3\xe5\xb8\x82', #洛阳市
234:b'\xe4\xb8\xb4\xe6\xb2\x82\xe5\xb8\x82', #临沂市
354:b'\xe6\xb7\x84\xe5\x8d\x9a\xe5\xb8\x82', #淄博市
288:b'\xe6\xb5\x8e\xe5\x8d\x97\xe5\xb8\x82', #济南市
315:b'\xe5\x8d\x97\xe4\xba\xac\xe5\xb8\x82', #南京市
218:b'\xe6\xad\xa6\xe6\xb1\x89\xe5\xb8\x82', #武汉市
323:b'\xe5\x92\xb8\xe9\x98\xb3\xe5\xb8\x82', #咸阳市
36:b'\xe5\x85\xb0\xe5\xb7\x9e\xe5\xb8\x82', #兰州市
104:b'\xe6\x98\x86\xe6\x98\x8e\xe5\xb8\x82', #昆明市
146:b'\xe8\xb4\xb5\xe9\x98\xb3\xe5\xb8\x82', #贵阳市
331:b'\xe6\xb3\xb8\xe5\xb7\x9e\xe5\xb8\x82', #泸州市
186:b'\xe5\xae\x9c\xe5\xae\xbe\xe5\xb8\x82', #宜宾市
240:b'\xe7\xbb\xb5\xe9\x98\xb3\xe5\xb8\x82', #绵阳市
291:b'\xe5\x8d\x97\xe5\x85\x85\xe5\xb8\x82', #南充市
233:b'\xe8\xa5\xbf\xe5\xae\x89\xe5\xb8\x82', #西安市
305:b'\xe6\x9f\xb3\xe5\xb7\x9e\xe5\xb8\x82', #柳州市
142:b'\xe6\xa1\x82\xe6\x9e\x97\xe5\xb8\x82', #桂林市
295:b'\xe5\x8c\x97\xe6\xb5\xb7\xe5\xb8\x82', #北海市
204:b'\xe9\x98\xb2\xe5\x9f\x8e\xe6\xb8\xaf\xe5\xb8\x82', #防城港市
145:b'\xe9\x92\xa6\xe5\xb7\x9e\xe5\xb8\x82', #钦州市
304:b'\xe6\xa2\xa7\xe5\xb7\x9e\xe5\xb8\x82', #梧州市
341:b'\xe8\xb4\xb5\xe6\xb8\xaf\xe5\xb8\x82', #贵港市
361:b'\xe7\x8e\x89\xe6\x9e\x97\xe5\xb8\x82', #玉林市
226:b'\xe6\x8a\x9a\xe5\xb7\x9e\xe5\xb8\x82', #抚州市
364:b'\xe4\xb8\x8a\xe9\xa5\xb6\xe5\xb8\x82', #上饶市
349:b'\xe4\xb9\x9d\xe6\xb1\x9f\xe5\xb8\x82', #九江市
350:b'\xe8\x90\x8d\xe4\xb9\xa1\xe5\xb8\x82', #萍乡市
164:b'\xe6\x96\xb0\xe4\xbd\x99\xe5\xb8\x82', #新余市
278:b'\xe5\xae\x9c\xe6\x98\xa5\xe5\xb8\x82', #宜春市
365:b'\xe8\xb5\xa3\xe5\xb7\x9e\xe5\xb8\x82', #赣州市
318:b'\xe5\x90\x89\xe5\xae\x89\xe5\xb8\x82', #吉安市
137:b'\xe9\x9f\xb6\xe5\x85\xb3\xe5\xb8\x82', #韶关市
200:b'\xe6\xb2\xb3\xe6\xba\x90\xe5\xb8\x82', #河源市
197:b'\xe6\xb8\x85\xe8\xbf\x9c\xe5\xb8\x82', #清远市
193:b'\xe9\xbe\x99\xe5\xb2\xa9\xe5\xb8\x82', #龙岩市
121:b'\xe4\xb8\x89\xe4\xba\x9a\xe5\xb8\x82', #三亚市
199:b'\xe9\x98\xb3\xe6\xb1\x9f\xe5\xb8\x82', #阳江市
338:b'\xe8\x82\x87\xe5\xba\x86\xe5\xb8\x82', #肇庆市
201:b'\xe6\xbd\xae\xe5\xb7\x9e\xe5\xb8\x82', #潮州市
259:b'\xe6\x8f\xad\xe9\x98\xb3\xe5\xb8\x82', #揭阳市
275:b'\xe9\x83\xb4\xe5\xb7\x9e\xe5\xb8\x82', #郴州市
314:b'\xe6\xb0\xb8\xe5\xb7\x9e\xe5\xb8\x82', #永州市
219:b'\xe5\xb8\xb8\xe5\xbe\xb7\xe5\xb8\x82', #常德市
363:b'\xe6\x80\x80\xe5\x8c\x96\xe5\xb8\x82', #怀化市
221:b'\xe5\xa8\x84\xe5\xba\x95\xe5\xb8\x82', #娄底市
222:b'\xe6\xa0\xaa\xe6\xb4\xb2\xe5\xb8\x82', #株洲市
313:b'\xe6\xb9\x98\xe6\xbd\xad\xe5\xb8\x82', #湘潭市
220:b'\xe5\xb2\xb3\xe9\x98\xb3\xe5\xb8\x82', #岳阳市
272:b'\xe7\x9b\x8a\xe9\x98\xb3\xe5\xb8\x82', #益阳市
173:b'\xe6\x97\xa5\xe7\x85\xa7\xe5\xb8\x82', #日照市
175:b'\xe5\xa8\x81\xe6\xb5\xb7\xe5\xb8\x82', #威海市
320:b'\xe9\x9e\x8d\xe5\xb1\xb1\xe5\xb8\x82', #鞍山市
351:b'\xe8\xbe\xbd\xe9\x98\xb3\xe5\xb8\x82', #辽阳市
184:b'\xe6\x8a\x9a\xe9\xa1\xba\xe5\xb8\x82', #抚顺市
41:b'\xe9\xbd\x90\xe9\xbd\x90\xe5\x93\x88\xe5\xb0\x94\xe5\xb8\x82', #齐齐哈尔市
50:b'\xe5\xa4\xa7\xe5\xba\x86\xe5\xb8\x82', #大庆市
55:b'\xe5\x90\x89\xe6\x9e\x97\xe5\xb8\x82', #吉林市
169:b'\xe5\xb7\xb4\xe5\xbd\xa6\xe6\xb7\x96\xe5\xb0\x94\xe5\xb8\x82', #巴彦淖尔市
264:b'\xe5\xbc\xa0\xe5\xae\xb6\xe5\x8f\xa3\xe5\xb8\x82', #张家口市
357:b'\xe9\x98\xb3\xe6\xb3\x89\xe5\xb8\x82', #阳泉市
238:b'\xe6\x99\x8b\xe4\xb8\xad\xe5\xb8\x82', #晋中市
328:b'\xe8\xbf\x90\xe5\x9f\x8e\xe5\xb8\x82', #运城市
368:b'\xe4\xb8\xb4\xe6\xb1\xbe\xe5\xb8\x82', #临汾市
355:b'\xe5\xa4\xa7\xe5\x90\x8c\xe5\xb8\x82', #大同市
356:b'\xe9\x95\xbf\xe6\xb2\xbb\xe5\xb8\x82', #长治市
290:b'\xe6\x99\x8b\xe5\x9f\x8e\xe5\xb8\x82', #晋城市
265:b'\xe5\x94\x90\xe5\xb1\xb1\xe5\xb8\x82', #唐山市
148:b'\xe7\xa7\xa6\xe7\x9a\x87\xe5\xb2\x9b\xe5\xb8\x82', #秦皇岛市
149:b'\xe6\xb2\xa7\xe5\xb7\x9e\xe5\xb8\x82', #沧州市
208:b'\xe8\xa1\xa1\xe6\xb0\xb4\xe5\xb8\x82', #衡水市
207:b'\xe6\x89\xbf\xe5\xbe\xb7\xe5\xb8\x82', #承德市
266:b'\xe9\x82\xa2\xe5\x8f\xb0\xe5\xb8\x82', #邢台市
282:b'\xe4\xb8\xb9\xe4\xb8\x9c\xe5\xb8\x82', #丹东市
228:b'\xe7\x9b\x98\xe9\x94\xa6\xe5\xb8\x82', #盘锦市
166:b'\xe9\x94\xa6\xe5\xb7\x9e\xe5\xb8\x82', #锦州市
319:b'\xe8\x91\xab\xe8\x8a\xa6\xe5\xb2\x9b\xe5\xb8\x82', #葫芦岛市
267:b'\xe5\xae\x89\xe9\x98\xb3\xe5\xb8\x82', #安阳市
209:b'\xe6\xbf\xae\xe9\x98\xb3\xe5\xb8\x82', #濮阳市
152:b'\xe6\x96\xb0\xe4\xb9\xa1\xe5\xb8\x82', #新乡市
211:b'\xe7\x84\xa6\xe4\xbd\x9c\xe5\xb8\x82', #焦作市
212:b'\xe4\xb8\x89\xe9\x97\xa8\xe5\xb3\xa1\xe5\xb8\x82', #三门峡市
308:b'\xe5\x91\xa8\xe5\x8f\xa3\xe5\xb8\x82', #周口市
309:b'\xe5\x8d\x97\xe9\x98\xb3\xe5\xb8\x82', #南阳市
269:b'\xe9\xa9\xbb\xe9\xa9\xac\xe5\xba\x97\xe5\xb8\x82', #驻马店市
213:b'\xe5\xb9\xb3\xe9\xa1\xb6\xe5\xb1\xb1\xe5\xb8\x82', #平顶山市
155:b'\xe8\xae\xb8\xe6\x98\x8c\xe5\xb8\x82', #许昌市
344:b'\xe6\xbc\xaf\xe6\xb2\xb3\xe5\xb8\x82', #漯河市
325:b'\xe6\xb3\xb0\xe5\xae\x89\xe5\xb8\x82', #泰安市
124:b'\xe8\x8e\xb1\xe8\x8a\x9c\xe5\xb8\x82', #莱芜市
353:b'\xe8\x8f\x8f\xe6\xb3\xbd\xe5\xb8\x82', #菏泽市
174:b'\xe4\xb8\x9c\xe8\x90\xa5\xe5\xb8\x82', #东营市
235:b'\xe6\xbb\xa8\xe5\xb7\x9e\xe5\xb8\x82', #滨州市
372:b'\xe5\xbe\xb7\xe5\xb7\x9e\xe5\xb8\x82', #德州市
366:b'\xe8\x81\x8a\xe5\x9f\x8e\xe5\xb8\x82', #聊城市
216:b'\xe5\x8d\x81\xe5\xa0\xb0\xe5\xb8\x82', #十堰市
156:b'\xe8\xa5\x84\xe9\x98\xb3\xe5\xb8\x82', #襄阳市
371:b'\xe9\x9a\x8f\xe5\xb7\x9e\xe5\xb8\x82', #随州市
292:b'\xe4\xb8\xbd\xe6\xb0\xb4\xe5\xb8\x82', #丽水市
245:b'\xe8\x88\x9f\xe5\xb1\xb1\xe5\xb8\x82', #舟山市
358:b'\xe9\xa9\xac\xe9\x9e\x8d\xe5\xb1\xb1\xe5\xb8\x82', #马鞍山市
190:b'\xe5\xae\xa3\xe5\x9f\x8e\xe5\xb8\x82', #宣城市
337:b'\xe9\x93\x9c\xe9\x99\xb5\xe5\xb8\x82', #铜陵市
130:b'\xe5\xae\x89\xe5\xba\x86\xe5\xb8\x82', #安庆市
252:b'\xe9\xbb\x84\xe5\xb1\xb1\xe5\xb8\x82', #黄山市
299:b'\xe6\xb1\xa0\xe5\xb7\x9e\xe5\xb8\x82', #池州市
311:b'\xe9\xbb\x84\xe7\x9f\xb3\xe5\xb8\x82', #黄石市
122:b'\xe9\x84\x82\xe5\xb7\x9e\xe5\xb8\x82', #鄂州市
271:b'\xe9\xbb\x84\xe5\x86\x88\xe5\xb8\x82', #黄冈市
217:b'\xe8\x8d\x86\xe9\x97\xa8\xe5\xb8\x82', #荆门市
310:b'\xe5\xad\x9d\xe6\x84\x9f\xe5\xb8\x82', #孝感市
250:b'\xe6\xb7\xae\xe5\x8d\x97\xe5\xb8\x82', #淮南市
128:b'\xe9\x98\x9c\xe9\x98\xb3\xe5\xb8\x82', #阜阳市
298:b'\xe5\x85\xad\xe5\xae\x89\xe5\xb8\x82', #六安市
188:b'\xe4\xba\xb3\xe5\xb7\x9e\xe5\xb8\x82', #亳州市
126:b'\xe8\x9a\x8c\xe5\x9f\xa0\xe5\xb8\x82', #蚌埠市
253:b'\xe6\xb7\xae\xe5\x8c\x97\xe5\xb8\x82', #淮北市
370:b'\xe5\xae\xbf\xe5\xb7\x9e\xe5\xb8\x82', #宿州市
171:b'\xe5\xae\x9d\xe9\xb8\xa1\xe5\xb8\x82', #宝鸡市
352:b'\xe6\xb1\x89\xe4\xb8\xad\xe5\xb8\x82', #汉中市
324:b'\xe5\xae\x89\xe5\xba\xb7\xe5\xb8\x82', #安康市
170:b'\xe6\xb8\xad\xe5\x8d\x97\xe5\xb8\x82', #渭南市
35:b'\xe7\x99\xbd\xe9\x93\xb6\xe5\xb8\x82', #白银市
66:b'\xe8\xa5\xbf\xe5\xae\x81\xe5\xb8\x82', #西宁市
92:b'\xe4\xb9\x8c\xe9\xb2\x81\xe6\x9c\xa8\xe9\xbd\x90\xe5\xb8\x82', #乌鲁木齐市
360:b'\xe9\x93\xb6\xe5\xb7\x9d\xe5\xb8\x82', #银川市
284:b'\xe5\xbb\xb6\xe5\xae\x89\xe5\xb8\x82', #延安市
231:b'\xe6\xa6\x86\xe6\x9e\x97\xe5\xb8\x82', #榆林市
135:b'\xe5\xba\x86\xe9\x98\xb3\xe5\xb8\x82', #庆阳市
81:b'\xe6\x94\x80\xe6\x9e\x9d\xe8\x8a\xb1\xe5\xb8\x82', #攀枝花市
249:b'\xe6\x9b\xb2\xe9\x9d\x96\xe5\xb8\x82', #曲靖市
263:b'\xe5\xae\x89\xe9\xa1\xba\xe5\xb8\x82', #安顺市
100:b'\xe6\x8b\x89\xe8\x90\xa8\xe5\xb8\x82', #拉萨市
78:b'\xe8\x87\xaa\xe8\xb4\xa1\xe5\xb8\x82', #自贡市
248:b'\xe5\x86\x85\xe6\xb1\x9f\xe5\xb8\x82', #内江市
242:b'\xe8\xb5\x84\xe9\x98\xb3\xe5\xb8\x82', #资阳市
79:b'\xe4\xb9\x90\xe5\xb1\xb1\xe5\xb8\x82', #乐山市
77:b'\xe7\x9c\x89\xe5\xb1\xb1\xe5\xb8\x82', #眉山市
74:b'\xe5\xbe\xb7\xe9\x98\xb3\xe5\xb8\x82', #德阳市
329:b'\xe5\xb9\xbf\xe5\x85\x83\xe5\xb8\x82', #广元市
330:b'\xe9\x81\x82\xe5\xae\x81\xe5\xb8\x82', #遂宁市
369:b'\xe8\xbe\xbe\xe5\xb7\x9e\xe5\xb8\x82', #达州市
239:b'\xe5\xb7\xb4\xe4\xb8\xad\xe5\xb8\x82', #巴中市
106:b'\xe7\x8e\x89\xe6\xba\xaa\xe5\xb8\x82', #玉溪市
108:b'\xe6\x99\xae\xe6\xb4\xb1\xe5\xb8\x82', #普洱市
112:b'\xe4\xbf\x9d\xe5\xb1\xb1\xe5\xb8\x82', #保山市
114:b'\xe4\xb8\xbd\xe6\xb1\x9f\xe5\xb8\x82', #丽江市
110:b'\xe4\xb8\xb4\xe6\xb2\xa7\xe5\xb8\x82', #临沧市
210:b'\xe5\xbc\x80\xe5\xb0\x81\xe5\xb8\x82', #开封市
196:b'\xe5\xa4\xa9\xe6\xb0\xb4\xe5\xb8\x82' #天水市
}
def start_catch_map_data():
'''
抓取地图数据
'''
#遍历百度地图的城市代号和城市名称
for k, v in key_value.items():
#创建一个临时列表用来存储百度地图API返回数据中没有省份名称的记录
tmp_content = []
#百度地图API返回数据分页最多输出5页
for i in range(0,5):
#如果百度地图API返回数据的总记录数不足以显示当前分页的记录,则跳出循环
if('total' in dir()):
if(i * 20 >= total):
break
#分页数
page_num = str(i)
#构造请求数据的URL
url = 'http://api.map.baidu.com/place/v2/search?query=' + keyword.decode() + '®ion=' + str(k) + '&page_size=20&page_num=' + str(page_num) + '&output=json&ak=' + ak
print(url)
#对URL进行编码
quoteUrl = quote(url, safe='/:?=&#')
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
response = requests.get(quoteUrl,)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
#得到网络响应,返回的JSON字符串用UTF-8解码
json_data = response.text
#JSON字符串解析为JSON数据结构
data = json.loads(json_data)
if(data['status'] != 401):
#获取总记录数
total = int(data['total'])
if(total > 1):
for item in data['results']:
#获取商铺名称
jname = item['name']
if('location' in item):
#获取城市名称
jcity = v.decode()
#获取省份名称
if('jprovince' not in dir()):
if('province' in item):
jprovince = item['province']
else:
jprovince = ''
elif(jprovince == '' and 'province' in item):
jprovince = item['province']
#获取地区名称
if('area' in item):
jarea = item['area']
else:
jarea = ''
#获取经纬度
jlat = item['location']['lat']
jlon = item['location']['lng']
#获取电话
if('telephone' in item):
jtel = item['telephone']
else:
jtel = ''
#获取地址
jadd = item['address']
#如果获取不到省份名称,就把记录临时存储在tmp_content列表中
if(jprovince == ''):
j_str = '\t'.join(('%s',jcity,jarea,jname,str(jlon) + ',' + str(jlat),jtel,jadd)) + '\n'
tmp_content.append(j_str)
#如果获取到省份名称,就把记录存储在content列表中
else:
j_str = '\t'.join((jprovince,jcity,jarea,jname,str(jlon) + ',' + str(jlat),jtel,jadd)) + '\n'
content.append(j_str)
print(j_str)
#用已有省份名称,来填充百度地图API返回数据中没有省份名称的记录
f_province = lambda jprovince: jprovince if 'jprovince' in dir() else ''
content_list = [j_str % f_province(jprovince) for j_str in tmp_content]
#将省份名称匹配的结果存储到content列表中,用于输出到文件
for list_idx in range(len(content_list)):
content.append(content_list[list_idx])
#重置当前省名
if('jprovince' in dir()):
del jprovince
#重置总记录数
if('total' in dir()):
del total
def outputResultFile():
'''
输出为结果文件
'''
#设置结果文件的路径和文件名
path_name = directory + '\\baidumap_tuliao.csv'
#以写入模式打开结果文件,编码为UTF-8
with open(path_name, 'w', encoding='utf-8') as file:
#循环遍历content列表
for index in range(len(content)):
#将记录写入结果文件
file.write(content[index])
def start_crawl():
'''
爬虫主程序
'''
#抓取地图数据
start_catch_map_data()
#输出为结果文件
outputResultFile()
#完成
print('Complete!')
#爬虫主程序
start_crawl()
股票数据爬虫
获取新浪实时股票数据
import requests
import threading
#结果文件保存路径
directory = "C:\\Temp\\"
#b'\xe8\x82\xa1\xe7\xa5\xa8\xe5\x90\x8d\xe7\xa7\xb0,\xe4\xbb\x8a\xe6\x97\xa5\xe5\xbc\x80\xe7\x9b\x98\xe4\xbb\xb7,\xe6\x98\xa8\xe6\x97\xa5\xe6\x94\xb6\xe7\x9b\x98\xe4\xbb\xb7,\xe5\xbd\x93\xe5\x89\x8d\xe4\xbb\xb7\xe6\xa0\xbc,\xe4\xbb\x8a\xe6\x97\xa5\xe6\x9c\x80\xe9\xab\x98\xe4\xbb\xb7,\xe4\xbb\x8a\xe6\x97\xa5\xe6\x9c\x80\xe4\xbd\x8e\xe4\xbb\xb7,\xe7\xab\x9e\xe4\xb9\xb0\xe4\xbb\xb7\xef\xbc\x8c\xe5\x8d\xb3\xe2\x80\x9c\xe4\xb9\xb0\xe4\xb8\x80\xe2\x80\x9d\xe6\x8a\xa5\xe4\xbb\xb7,\xe7\xab\x9e\xe5\x8d\x96\xe4\xbb\xb7\xef\xbc\x8c\xe5\x8d\xb3\xe2\x80\x9c\xe5\x8d\x96\xe4\xb8\x80\xe2\x80\x9d\xe6\x8a\xa5\xe4\xbb\xb7,\xe6\x88\x90\xe4\xba\xa4\xe9\x87\x8f,\xe6\x88\x90\xe4\xba\xa4\xe9\x87\x91\xe9\xa2\x9d,\xe4\xb9\xb0\xe4\xb8\x80\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe4\xb8\x80\xe6\x8a\xa5\xe4\xbb\xb7,\xe4\xb9\xb0\xe4\xba\x8c\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe4\xba\x8c\xe6\x8a\xa5\xe4\xbb\xb7,\xe4\xb9\xb0\xe4\xb8\x89\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe4\xb8\x89\xe6\x8a\xa5\xe4\xbb\xb7,\xe4\xb9\xb0\xe5\x9b\x9b\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe5\x9b\x9b\xe6\x8a\xa5\xe4\xbb\xb7,\xe4\xb9\xb0\xe4\xba\x94\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe4\xba\x94\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe4\xb8\x80\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe4\xb8\x80\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe4\xba\x8c\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe4\xba\x8c\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe4\xb8\x89\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe4\xb8\x89\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe5\x9b\x9b\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe5\x9b\x9b\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe4\xba\x94\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe4\xba\x94\xe6\x8a\xa5\xe4\xbb\xb7,\xe6\x97\xa5\xe6\x9c\x9f,\xe6\x97\xb6\xe9\x97\xb4'="股票名称,今日开盘价,昨日收盘价,当前价格,今日最高价,今日最低价,竞买价,即“买一”报价,竞卖价,即“卖一”报价,成交量,成交金额,买一申请股数,买一报价,买二申请股数,买二报价,买三申请股数,买三报价,买四申请股数,买四报价,买五申请股数,买五报价,卖一申请股数,卖一报价,卖二申请股数,卖二报价,卖三申请股数,卖三报价,卖四申请股数,卖四报价,卖五申请股数,卖五报价,日期,时间".encode()
table_head = b'\xe8\x82\xa1\xe7\xa5\xa8\xe5\x90\x8d\xe7\xa7\xb0,\xe4\xbb\x8a\xe6\x97\xa5\xe5\xbc\x80\xe7\x9b\x98\xe4\xbb\xb7,\xe6\x98\xa8\xe6\x97\xa5\xe6\x94\xb6\xe7\x9b\x98\xe4\xbb\xb7,\xe5\xbd\x93\xe5\x89\x8d\xe4\xbb\xb7\xe6\xa0\xbc,\xe4\xbb\x8a\xe6\x97\xa5\xe6\x9c\x80\xe9\xab\x98\xe4\xbb\xb7,\xe4\xbb\x8a\xe6\x97\xa5\xe6\x9c\x80\xe4\xbd\x8e\xe4\xbb\xb7,\xe7\xab\x9e\xe4\xb9\xb0\xe4\xbb\xb7\xef\xbc\x8c\xe5\x8d\xb3\xe2\x80\x9c\xe4\xb9\xb0\xe4\xb8\x80\xe2\x80\x9d\xe6\x8a\xa5\xe4\xbb\xb7,\xe7\xab\x9e\xe5\x8d\x96\xe4\xbb\xb7\xef\xbc\x8c\xe5\x8d\xb3\xe2\x80\x9c\xe5\x8d\x96\xe4\xb8\x80\xe2\x80\x9d\xe6\x8a\xa5\xe4\xbb\xb7,\xe6\x88\x90\xe4\xba\xa4\xe9\x87\x8f,\xe6\x88\x90\xe4\xba\xa4\xe9\x87\x91\xe9\xa2\x9d,\xe4\xb9\xb0\xe4\xb8\x80\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe4\xb8\x80\xe6\x8a\xa5\xe4\xbb\xb7,\xe4\xb9\xb0\xe4\xba\x8c\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe4\xba\x8c\xe6\x8a\xa5\xe4\xbb\xb7,\xe4\xb9\xb0\xe4\xb8\x89\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe4\xb8\x89\xe6\x8a\xa5\xe4\xbb\xb7,\xe4\xb9\xb0\xe5\x9b\x9b\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe5\x9b\x9b\xe6\x8a\xa5\xe4\xbb\xb7,\xe4\xb9\xb0\xe4\xba\x94\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe4\xb9\xb0\xe4\xba\x94\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe4\xb8\x80\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe4\xb8\x80\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe4\xba\x8c\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe4\xba\x8c\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe4\xb8\x89\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe4\xb8\x89\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe5\x9b\x9b\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe5\x9b\x9b\xe6\x8a\xa5\xe4\xbb\xb7,\xe5\x8d\x96\xe4\xba\x94\xe7\x94\xb3\xe8\xaf\xb7\xe8\x82\xa1\xe6\x95\xb0,\xe5\x8d\x96\xe4\xba\x94\xe6\x8a\xa5\xe4\xbb\xb7,\xe6\x97\xa5\xe6\x9c\x9f,\xe6\x97\xb6\xe9\x97\xb4'
#结果列表
content = [table_head.decode() + '\n']
def display_info(code):
url = 'http://hq.sinajs.cn/list=' + code
print(url)
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
response = requests.get(url).text
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
_,data,_ = response.split('"')
content.append(data + '\n')
def single_thread(codes):
for code in codes:
code = code.strip()
display_info(code)
def multi_thread(tasks):
# 用列表推导生成线程,注意codes后面的‘,’!
threads = [threading.Thread(target = single_thread, args = (codes,)) for codes in tasks]
# 启动线程
for t in threads:
t.start()
# 等待线程结束
for t in threads:
t.join()
def outputResultFile():
'''
输出为结果文件
'''
path_name = directory + '\\sina_stock.txt'
with open(path_name, 'w', encoding='utf-8') as file:
#循环遍历列表content
for index in range(len(content)):
file.write(content[index])
def getStockPrices():
'''
获取新浪实时股票数据
'''
codes = ['sh600519', 'sh601006', 'sh603277', 'sh601012', 'sh600340', 'sh600026']
# 计算每个线程要做多少工作
thread_len = int(len(codes) / 4)
t1 = codes[0: thread_len]
t2 = codes[thread_len: thread_len * 2]
t3 = codes[thread_len * 2: thread_len * 3]
t4 = codes[thread_len * 3:]
# 多线程启动
multi_thread([t1, t2, t3, t4])
def start_crawl():
'''
爬虫主程序
'''
#获取新浪实时股票数据
getStockPrices()
#输出为结果文件
outputResultFile()
#完成
print('Complete!')
#爬虫主程序
start_crawl()
搜索引擎爬虫
百度搜索结果链接爬虫
#!/usr/bin/python
# coding:utf8
import re
import requests
import sys
import getopt
from urllib.parse import quote
from time import sleep
from bs4 import BeautifulSoup
import time
import random
class crawler:
'''爬百度搜索结果的爬虫'''
main_url = ''
url = ''
urls = set()
o_urls = []
main_html = ''
html = ''
rsv_pq = ''
rsv_t = ''
ie = ''
f = ''
rsv_bp = ''
tn = ''
rqlang = ''
total_pages = 5
current_page = 0
next_page_url = ''
p1 = 0
i1 = 3
headersParameters = { #发送HTTP请求时的HEAD信息,用于伪装为浏览器
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, image/jxr, */*',
'Accept-Language': 'en-US, en; q=0.8, zh-Hans-CN; q=0.5, zh-Hans; q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Cookie': 'BAIDUID=A730654D13307F11B9C931195729185D:FG=1; BIDUPSID=A730654D13307F11B9C931195729185D; PSTM=1496195632; MCITY=-289%3A; H_PS_PSSID=1996_1458_21117_20929; BD_UPN=1126314751; ispeed_lsm=18; BD_HOME=0',
'Host': 'www.baidu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; Touch; rv:11.0) like Gecko'
}
def __init__(self, keyword):
print("搜索关键词:" + keyword)
print("正在获取网页链接中......")
self.main_url = 'https://www.baidu.com/'
def set_total_pages(self, num):
'''设置总共要爬取的页数'''
try:
self.total_pages = int(num)
self.p1 = int(100 / (self.total_pages + 2))
except:
pass
def set_current_url(self, url):
'''设置当前url'''
self.url = url
def switch_url(self):
'''切换当前url为下一页的url
若下一页为空,则退出程序'''
if self.next_page_url == '':
sys.exit()
else:
self.set_current_url(self.next_page_url)
def is_finish(self):
'''判断是否爬取完毕'''
if self.current_page >= self.total_pages:
return True
else:
return False
def get_main_page_parameters(self):
'''获取百度搜索主页面的内容,提取其中的URL参数'''
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
r = requests.get(self.main_url , headers=self.headersParameters)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
print(str(self.p1) + " %")
if r.status_code == 200:
self.main_html = r.text
bsObj = BeautifulSoup(self.main_html,"html.parser")
form = bsObj.find(id="form")
list_input = form.find_all("input")
for input in list_input:
if 'name' in input.attrs:
if input["name"] == 'rsv_pq':
self.rsv_pq = input["value"]
elif input["name"] == 'rsv_t':
self.rsv_t = input["value"]
elif input["name"] == 'ie':
self.ie = input["value"]
elif input["name"] == 'f':
self.f = input["value"]
elif input["name"] == 'rsv_bp':
self.rsv_bp = input["value"]
elif input["name"] == 'rsv_idx':
self.rsv_idx = input["value"]
elif input["name"] == 'tn':
self.tn = input["value"]
elif input["name"] == 'rqlang':
self.rqlang = input["value"]
assert self.rsv_t
assert self.rsv_pq
assert self.ie
assert self.f
assert self.rsv_bp
assert self.rsv_idx
assert self.tn
assert self.rqlang
self.url = 'https://www.baidu.com/s?ie=' + self.ie + '&f=' + self.f + '&rsv_bp=' + self.rsv_bp + '&rsv_idx=' + self.rsv_idx + '&tn=' + self.tn + '&wd=' + quote(keyword) + '&rsv_pq=' + self.rsv_pq + '&rsv_t=' + self.rsv_t + '&rqlang=' + self.rqlang + '&rsv_enter=1&rsv_n=2&rsv_sug3=1'
else:
self.main_html = ''
print(str(self.p1 * 2) + " %")
def get_html(self):
'''爬取当前URL所指页面的内容,保存到HTML中'''
assert self.main_html
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
r = requests.get(self.url, headers=self.headersParameters)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
if r.status_code == 200:
self.html = r.text
self.current_page += 1
else:
self.html = u''
print('[ERROR]',self.url,u'get此url返回的http状态码不是200')
def get_urls(self):
'''从当前HTML中解析出搜索结果的URL,保存到o_urls'''
o_urls = re.findall('href\=\"(http\:\/\/www\.baidu\.com\/link\?url\=.*?)\" class\=\"c\-showurl\"', self.html)
o_urls = list(set(o_urls)) #去重
self.o_urls = o_urls
#取下一页地址
next = re.findall(' href\=\"(\/s\?wd\=[\w\d\%\&\=\_\-]*?)\" class\=\"n\"', self.html)
if len(next) > 0:
self.next_page_url = 'https://www.baidu.com' + next[-1]
else:
self.next_page_url = ''
def get_real(self, o_url):
'''获取重定向url指向的网址'''
r = requests.get(o_url, allow_redirects = False) #禁止自动跳转
if r.status_code == 302:
try:
return r.headers['location'] #返回指向的地址
except:
pass
return o_url #返回源地址
def transformation(self):
'''读取当前o_urls中的链接重定向的网址,并保存到urls中'''
for o_url in self.o_urls:
self.urls.add(self.get_real(o_url))
def print_urls(self):
'''输出当前urls中的url'''
for url in self.urls:
print(url)
def run(self):
c.get_main_page_parameters()
#随机延时
time.sleep(random.randint(6,20))
while(not self.is_finish()):
#爬取当前URL所指页面的内容,保存到HTML中
c.get_html()
#从当前HTML中解析出搜索结果的URL,保存到o_urls
c.get_urls()
#读取当前o_urls中的链接重定向的网址,并保存到URLs中
c.transformation()
#切换当前url为下一页的URL
c.switch_url()
print(str(self.p1 * self.i1) + " %")
if not self.is_finish():
#随机延时
time.sleep(random.randint(6,20))
self.i1+=1
if self.p1 * self.i1 < 100:
print("100 %")
c.print_urls()
print("完毕......")
if __name__ == '__main__':
help = 'baidu_crawler.py -k [-p ]'
keyword = None
totalpages = None
try:
opts, args = getopt.getopt(sys.argv[1:], "hk:t:p:")
except getopt.GetoptError:
print(help)
sys.exit(2)
#解析命令行参数
for opt, arg in opts:
if opt == '-h':
print(help)
sys.exit()
elif opt in ("-k", "--keyword"):
keyword = arg
elif opt in ("-p", "--totalpages"):
totalpages = arg
print('获取' + totalpages + '个搜索结果页面')
if keyword == None:
print(help)
sys.exit()
c = crawler(keyword)
if totalpages != None:
c.set_total_pages(totalpages)
print("0 %")
c.run()
360搜索结果链接爬虫
#!/usr/bin/python
# coding:utf8
import re
import requests
import sys
import getopt
from bs4 import BeautifulSoup
from urllib.parse import quote
from time import sleep
import time
import random
class crawler:
'''爬360搜索结果的爬虫'''
url = ''
#去重
urls = set()
html = ''
total_pages = 5
current_page = 0
next_page_url = ''
timeout = 60
p1 = 0
i1 = 1
headersParameters = { #发送HTTP请求时的HEAD信息,用于伪装为浏览器
'Connection': 'Keep-Alive',
'Accept': 'text/html, application/xhtml+xml, */*',
'Accept-Language': 'en-US,en;q=0.8,zh-Hans-CN;q=0.5,zh-Hans;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'User-Agent': 'Mozilla/6.1 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
def __init__(self, keyword):
print("搜索关键词:" + keyword)
print("正在获取网页链接中......")
self.url = u'https://www.so.com/s?ie=utf-8&fr=360portal&src=home_www&q=' + quote(keyword)
def set_timeout(self, time):
'''设置超时时间,单位:秒'''
try:
self.timeout = int(time)
except:
pass
def set_total_pages(self, num):
'''设置总共要爬取的页数'''
try:
self.total_pages = int(num)
self.p1 = int(100 / self.total_pages)
except:
pass
def set_current_url(self, url):
'''设置当前url'''
self.url = url
def switch_url(self):
'''切换当前url为下一页的url
若下一页为空,则退出程序'''
if self.next_page_url == '':
sys.exit()
else:
self.set_current_url(self.next_page_url)
def is_finish(self):
'''判断是否爬取完毕'''
if self.current_page >= self.total_pages:
return True
else:
return False
def get_html(self):
'''爬取当前url所指页面的内容,保存到html中'''
#发送网络请求,如果连接失败,延时5秒,无限重试链接
success = False
while(success == False):
try:
#发送网络请求
r = requests.get(self.url ,timeout=self.timeout, headers=self.headersParameters)
except requests.exceptions.ConnectionError as e:
sleep(5)
else:
success = True
if r.status_code == 200:
self.html = r.text
self.current_page += 1
else:
self.html = u''
print('[ERROR]',self.url,u'get此url返回的http状态码不是200')
def get_urls(self):
'''从当前html中解析出搜索结果的url,保存到o_urls'''
bsObj = BeautifulSoup(self.html,"html.parser")
list_h3 = bsObj.find_all("h3","res-title ")
for h3 in list_h3:
if "data-url" in h3.a.attrs:
self.urls.add(h3.a.attrs["data-url"])
else:
self.urls.add(h3.a.attrs["href"])
#取下一页地址
next = re.findall(' href\=\"(\/s\?q\=[\w\d\%\&\=\_\-]*?)\"', self.html)
if len(next) > 0:
self.next_page_url = 'https://www.so.com' + next[-1]
else:
self.next_page_url = ''
def print_urls(self):
'''输出当前urls中的url'''
for url in self.urls:
print(url)
def run(self):
while(not self.is_finish()):
c.get_html()
c.get_urls()
c.switch_url()
print(str(self.p1 * self.i1) + " %")
if not self.is_finish():
#随机延时
time.sleep(random.randint(6,20))
self.i1+=1
if self.p1 * self.i1 < 100:
print("100 %")
c.print_urls()
print("完毕......")
if __name__ == '__main__':
help = '360_crawler.py -k [-t -p ]'
keyword = None
timeout = None
totalpages = None
try:
opts, args = getopt.getopt(sys.argv[1:], "hk:t:p:")
except getopt.GetoptError:
print(help)
sys.exit(2)
#解析命令行参数
for opt, arg in opts:
if opt == '-h':
print(help)
sys.exit()
elif opt in ("-k", "--keyword"):
keyword = arg
elif opt in ("-t", "--timeout"):
timeout = arg
elif opt in ("-p", "--totalpages"):
totalpages = arg
if keyword == None:
print(help)
sys.exit()
c = crawler(keyword)
if timeout != None:
print('网站连接超时时间:' + timeout + '秒')
c.set_timeout(timeout)
if totalpages != None:
print('获取' + totalpages + '个搜索结果页面')
c.set_total_pages(totalpages)
print("0 %")
c.run()