kaggle-电影评论情感分析-Words Meets Bags of Popcorn
Kaggle竞赛 - Words Meets Bags of Popcorn
经过一段时间ml的学习,以及kaggle入门的泰坦尼克幸存者项目的研究,我对这此产生了浓厚的兴趣,最近又学习了nlp的相关内容,想要动手实践一下,就在kaggle上尝试做了“Bag of Words Meets Bags of Popcorn”这个项目,它的主要任务是对电影评论文本进行情感分类,分类的结果为正面评论和负面评论,和之前泰坦尼克项目中预测船上某人是否存活一样,是一个二分类问题,二分类训练模型可以选择我熟悉的xgboost模型,但是两个项目特征数据上有很大差异,所以特征工程中使用了不同的方法,进行特征处理时的挑战之一是文本内容的向量化,因此,我首先尝试bag of words,然后尝试基于TF-IDF的向量化方法。最后训练模型评估时采用了交叉验证和留出法两种方法。其中在使用sklearn封装的xgboost函数在模型优化中发现其功能太少,改进使用了原生是xgboost并实现运行时打印出每一颗树训练集和测试集的auc,并能打印出模型学习到的对判断review情感类别权重较大的关键词
- 数据清洗
# coding: UTF-8
import pandas as pd
import numpy as np
from sklearn.metrics import roc_auc_score
import re
from bs4 import BeautifulSoup
def review_to_wordlist(review):
# 去掉HTML标签,拿到内容
review_text = BeautifulSoup(review, "html.parser").get_text()
#用正则表达式取出符合规范的部分
review_text = re.sub("[^a-zA-Z]"," ",review_text)
# 小写化所有的词,并转成词list
#return review_text
words = review_text.lower().split()
# 返回words
return words
分析:titanic项目中的数据集是描述乘客属性的多维特征,每个特征的特征值都是客观的数据,我们只需要在多维特征中抽取和标签相关性最高的几个特征来训练模型即可,而“Bag of Words Meets Bags of Popcorn”项目中数据集中的每个数据都是一段review的文本,而且每段文本都是带有作者表达的主观性的,那么怎么在一段本文中提取出能表现出这个review情感的特征呢?首先,观察文本,因为这些数据均是从网页上通过网络爬虫抓取下来的,所以本文内容里会有残留的html标签,标点符号,数字等对于我们情感分析没有意义的元素,所以我们要把这些元素过滤掉,使用BeautifulSoup Package来去掉html标签拿到文本内容,使用python中内置的re package中的正则表达式来清除文本中的标点符号和数字,处理之后已经得到纯英文的review文本了,但是其中每个单词会有大小写的差别,为了进一步地将特征归一化,再把review文本全转换成小写,并将它们分割成单个单词(称为NPL LINGO中的标记化)
总结:数据清洗在titanic项目中是没有遇到的,但是titanic项目中客观的特征值会有缺失的问题,需要进行缺失值处理,这在sentiment analysis项目中也没有体现,这是和两个项目的特征数据差异相对应的,所以在特征工程中要针对不同的原始特征数据来做不同的处理,不过这些处理特征的方法可能在以后的某个问题中全都会利用上,所以要深刻理解特征工程的主要方法的使用。
- 特征抽取
stops = set(stopwords.words("english"))
meaningful_words = [w for w in words if not w in stops] 分析:从中文的表达来看,每一段review里都会很频繁的出现一些包括英文中的”a”, “and”, “is”, “and” “the”等不携带任何意义的词,这些词被成为停止词,所以要把停止词从review文本中清除,留下关键词。在Python程序包中,带有内置的停止单词列表,可以简单的实现这一步。
优化:把数据类型为list的停止词列表转换成set集合形式,主要是为了程序运行的速度,因为我们将调用这个函数数万次,它需要快速,并且在Python中搜索集合要比搜索列表快得多。
- 特征处理
分析:直接把清洗好的词文本丢给计算机,它是无法计算的,因此我们需要把文本进行向量化,首先尝试用词袋模型做向量化
词袋模型:如果一个单词在文档中出现不止一次,就统计其出现的次数,旨在用向量来描述文本的主要内容
from sklearn.feature_extraction.text import CountVectorizer
# bag of words tool
vectorizer = CountVectorizer(analyzer = "word",
tokenizer = None,
preprocessor = None,
stop_words = 'english',
max_features = 5000)
train_x = vectorizer.fit_transform(train_data)
train_x = train_x.toarray()
print 'bag of words处理结束!'- xgboost训练与评估
from xgboost import XGBClassifier
#from xgboost import XGBRegressor
xgbc = XGBClassifier(max_depth=2, learning_rate=0.1, n_estimators=500,
subsample=0.8,
colsample_btree=0.8,
objective='binary:logitraw')
### 交叉验证
#from sklearn.cross_validation import cross_val_score
#scores = cross_val_score(xgbc, train_x, label, cv=3, scoring='accuracy')
#print scores
#print scores.mean()
交叉验证的评估分数以及运行的时间
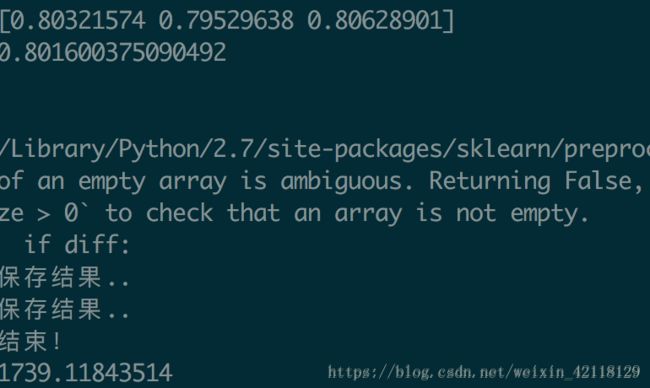
优化:可以看出整个程序跑完需要接近半个小时的时间,在做baseline时,程序可能有报错,或者需要多次修改模型的参数来优化,这都需要多次的运行程序,如果每次都用全部的数据跑会浪费很多时间,所以先在训练集和测试集中分别抽出100条review数据来跑程序,排除掉所有bug,修改模型的参数后,再用所有的数据集来跑程序,最后将测试集的预测结果提交到kaggle。此外这次我们用到的交叉验证来对模型进行评估,三次评估的分数分别为0.80321574 ,0.79529638,0.80628901可以看出三次评估的分数很稳定,所以改用留出法来评估模型,可以减少程序的运行时间
留出法的评估分数以及运行时间
总结:可以看出留出法与交叉验证法对模型的评估分数基本一致,但是运行时间却不到交叉验证运行时间的三分之一,这可以很有效的帮我们节约项目的开发时间。但是在titanic项目里4次交叉验证的分数分别为0.77678571 ,0.86547085 ,0.80630631 ,0.82882883,可以看出四次评估的分数波动很大,那么就不能为了节省时间而用留出法来评估,交叉验证可以帮助我们减少模型评估的误差.
提交最终的结果到kaggle,AUC为:0.80656

这个分数在kaggle分数排行榜上的排名不高,需要再一次对baseline进行优化,首先调整xgboost模型的参数
xgbc = XGBClassifier(max_depth=3 learning_rate=0.1, n_estimators=300,
subsample=0.8,
colsample_btree=0.8,
objective='binary:logitraw')
把max_depth设为2 把n_estimators设为300 运行程序把预测的数据提交到kaggle
提交最终的结果到kaggle,AUC为:0.83476

分析:最后的结果有提升,那么继续增加树的颗数效果会不会更好?再增加树的深度会不会也能使分数更高?每次修改参数之后,再运行程序平均需要二十分钟来处理,但是每次修改还会担心模型训练是否过拟合了,方向性不明确还很费时间,我想能不能在程序运行时实时打印出每一轮迭代的训练集和测试集的auc这样就可以很直观的看到修改参数后模型的训练效果,并且根据训练集与测试集auc的差值来判断是否过拟合。但是现在使用的是sklearn封装好的xgboost函数功能比较少,不能实现这个预想,所以就继续对代码进行优化,使用原生的xgboost函数来做,并且能打印出模型学习到的对判断review情感类别权重较大的关键词。
fmap = dict(map(lambda x: ('f%d' % (x[1]), x[0]), tfidf.vocabulary_.items()))
import xgboost as xgb
params = {
'booster':'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'error',
'max_depth': 3,
'subsample': 0.8,
'colsample_bytree': 0.8,
'eta': 0.025,
'alpha': 1,
'seed': 0,
#'nthread': 8,
'silent': 1
}
# 留出法
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_x, label, test_size=0.2, random_state=31)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
watchlist = [(dtrain,'train'), (dtest, 'test')]
bst = xgb.train(params, dtrain, num_boost_round=1000, evals=watchlist)
ypred = bst.predict(dtest)
y_pred = (ypred >= 0.5) * 1
from sklearn import metrics
print 'AUC: %.4f' % metrics.roc_auc_score(y_test, ypred)
print 'ACC: %.4f' % metrics.accuracy_score(y_test, y_pred)
print 'Recall: %.4f' % metrics.recall_score(y_test, y_pred)
print 'F1-score: %.4f' %metrics.f1_score(y_test, y_pred)
print 'Precesion: %.4f' %metrics.precision_score(y_test, y_pred)
for key, value in sorted(bst.get_fscore().items(), key=lambda x: -x[1])[:20]:
print fmap.get(key), value
dtest = xgb.DMatrix(test_x)
ypred = bst.predict(dtest)
test_predicted = (ypred >= 0.5) * 1运行效果

提交最终的结果到kaggle,AUC为:0.82376

总结:这次我把树的棵数改到了1000,但是提交到kaggle后的auc反而比之前树的颗数为500的时候更低了,我的理解可能是参数为1000时相对于500来说训练出来的模型过拟合的程度更大,也就是说n_estimators的参数值大于500对模型的优化效果不大,甚至会让模型更加过拟合,这里的分析对我来说是个很大的难点,说明自己对xgboost的模型的原理掌握的不够全面,并且认识到了误差评估里过拟合的概念也是相对的,我们用留出法用分割出来的训练集训练出来的模型来预测分割出来的测试集,做auc评估到最后也没有出现过拟合,但是提交到kaggle上的分数却变低了,显然就是训练出来的模型相对于全新的测试集是过拟合了的。就能够解释这个问题了。
优化:那么就再继续调整树的深度,这次把树的深度设为3,运行程序提交到kaggle上。
提交最终的结果到kaggle,AUC为:0.83744

总结:这次的分数比之前树的深度为2的时候有略微的提升,说明改变树的深度还可以对模型进行进一步的优化。除了以上通过修改训练模型参数来优化,还可以在特征处理的部分尝试一下其他的文本向量化方法,看是否对训练模型的效果有所提高,下面我们采用TF-IDF模型来代替词袋模型
- TF-IDF向量化模型:TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。
TF代表某个词在一段review文本中出现的频率,而IDF则代表这个词和所有文档整体的相关性,如果某个词在某一类别出现的多,在其他类别出现的少,那IDF的值就会比较大。如果这个词在所有类别中都出现的多,那么IDF值则会随着类别的增加而下降,IDF反映的是一个词能将当前文本与其它文本区分开的能力。总之,TF-IDF向量化旨在用向量来表述文本的主要内容,并且在向量中能更加突出的表现出review中与情感分类有关的关键字
from sklearn.feature_extraction.text import TfidfVectorizer as TFIDF
tfidf = TFIDF(min_df=2, # 最小支持度为2
max_features=None,
strip_accents='unicode',
analyzer='word',
token_pattern=r'\w{1,}',
ngram_range=(1, 3), # 二元文法模型
use_idf=1,
smooth_idf=1,
sublinear_tf=1,
stop_words = 'english') # 去掉英文停用词
# 合并训练和测试集以便进行TFIDF向量化操作
data_all = train_data + test_data
len_train = len(train_data)
tfidf.fit(data_all)
data_all = tfidf.transform(data_all)
# 恢复成训练集和测试集部分
train_x = data_all[:len_train]
test_x = data_all[len_train:]
print 'TF-IDF处理结束.'
提交最终的结果到kaggle,AUC为:0.83712

对比词袋模型提交到kaggle,AUC为:0.80656

总结:用TF-IDF向量化模型明显比词袋模型的效果要好一些。
看case
权重较大的关键词列表

分析:查看关键词发现比如great,bad,excellent等这些能够表达情感的形容词权重都比较高,这也是符合直觉的,但是特别注意到单个字母‘t’的权重也非常高,根据经验来看单个字母‘t’对review的感情表达是没有作用的,所以进一步来探究一下原因,打开训练集的原始数据,在里面查找‘t’,发现‘t’基本出现在否定的表达中,或者是有些单词书写时带有空格把原单词拆开了,而且发现带有单个t的特征对应的标签0的比重非常高,这个很有可能造成训练的模型过拟合,即一遇到某个特征数据就直接判断它的标签是0,所以我们在特征清洗这一步添加一行代码,把单个字母都数据也都去掉,看看模型训练效果是否有所提升。
# 去掉单个字母的元素
words = filter(lambda x: len(x) >= 2, words)
提交最终的结果到kaggle,AUC为:0.77740

结论:kaggle上的结果表明,数据集经过上面的处理不仅没有实现进一步优化反而效果更差,这与我的预期也是相反的,还有待于后续继续探究。
综上,我把“Bag of Words Meets Bags of Popcorn”这个项目的baseline完整的走了一遍,并对模型训练的效果进行了优化,通过对优化后的各种结果的分析,更加深刻地体会到模型参数和特征工程对机器学习的重要性,除此之外,这个项目还有很多优化的空间,比如二分类模型我们还可以尝试朴素贝叶斯模型,逻辑回归模型,随机森林模型来训练,在处理自然语言问题时文本向量化还有基于神经网络的语言模型Word2vec模型,后续我会继续在这些项目中尝试这些模型,并比较他们的效果。