推荐一些视觉SLAM的深度学习方法(下)
这里重点在RNN/LSTM的应用。
11. DeepVO: Towards End-to-End VO with Deep Recurrent CNNs
基本上这个方法是依赖CNN提取的特征在RNN(LSTM)学习pose的连续估计。如图所示

更细致的RNN网络结构如图

其中的LSTM结构图如下

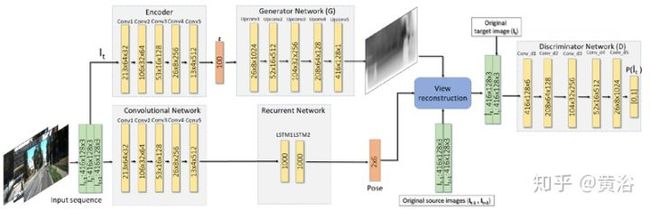
12. GANVO: Unsupervised Deep Monocular Visual Odometry and Depth Estimation with Generative Adversarial Networks
这个方法采用GAN学习depth和VO,基本框架如图

具体的模型架构如下图
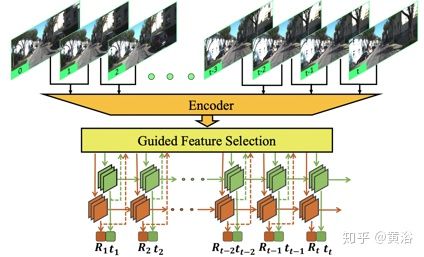
13. Guided Feature Selection for Deep Visual Odometry
这个北大的工作,通过深度学习学习特征选择过程,通过RNN网络实现VO(rotation和translation分开估计),这里RNN是ConvLSTM,其框架如下
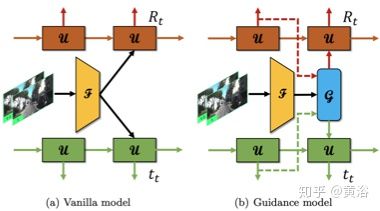
其中采用LSTM和guided model的组合方式如图(b)所示:
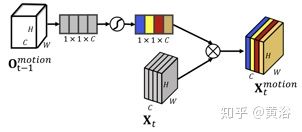
更具体的guided model架构如下(一个SENet类似的架构)
14. MagicVO: End-to-End Monocular Visual Odometry through Deep Bi-directional Recurrent Convolutional Neural Network
也是VO的工作,这里采用双向RCNN (CNN+LSTM)框架,如图所示:
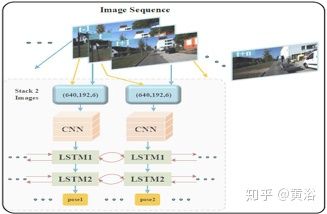
具体模型架构如图:最后通过FCL得到pose估计。

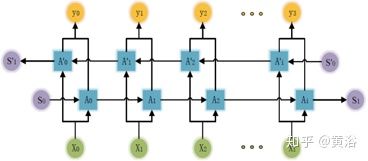
其中Bi-LSTM的细节如下:
15. Sequential Learning of Visual Tracking and Mapping Using Unsupervised Deep Neural Networks
这是基于非监督学习的SLAM方法,采用CNN+LSTM的架构,双目图像序列训练,单目测试,其框架如图所示
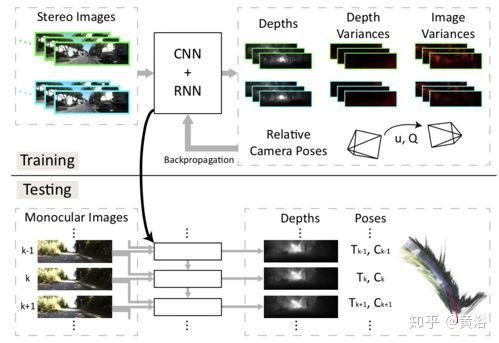
其中模型架构细节如下:

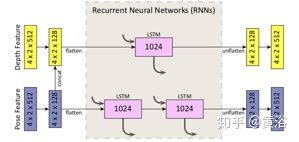
LSTM的细节如下:输入的是depthnet的feature和posenet的feature两路组合。
16. Learning By Inertia: Self-supervised Monocular Visual Odometry For Road Vehicles
该VO方法采用多帧图像的自监督训练方法,还是CNN+RCNN的组合,其中包括depth,pose和segmentation的front end(似乎是简单的前景-背景模式),测试不需要输出segmentation,如图所示

其CNN模型和RNN的架构如下:depth和pose两部分


17. SGANVO: Unsupervised Deep Visual Odometry and Depth Estimation with Stacked GANs
这也是基于GAN的VO方法,同样采用depth和pose,框架如下图
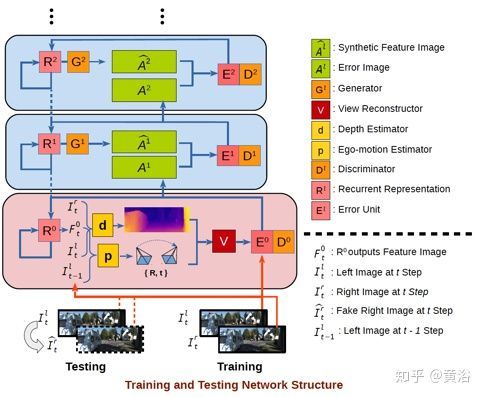
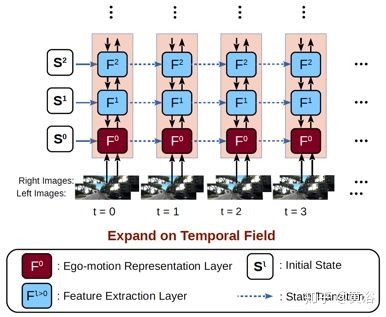
时域的扩展框架如图所示
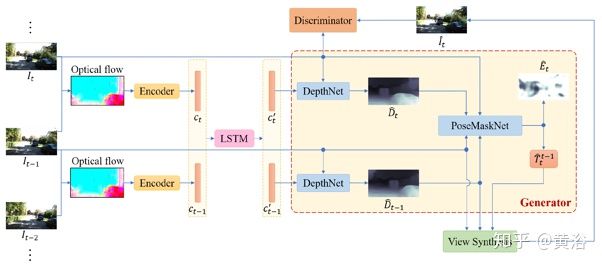
18. Sequential Adversarial Learning for Self-Supervised Deep Visual Odometry
基于对抗学习的方法做自监督VO,采用optic flow,时域基于LSTM建模,如图

更具体的架构如下:这里depthnet和poseMaskNet同时做生成器,感觉optic flow不是深度学习得到的。
19. SelfVIO: Self-Supervised Deep Monocular Visual-Inertial Odometry and Depth Estimation
还是基于GAN,但加入惯导和VO融合,即VIO,框架如下

深度学习架构具体如下图:CNN+LSTM组合,depth和pose同时做输入,还有IMU融合。

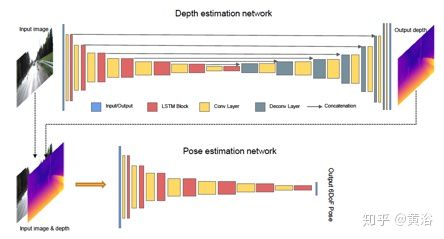
20. Recurrent Neural Network for (Un)supervised Learning of Monocular Video Visual Odometry and Depth
基于RNN的非监督/监督VO方法,其框架如图所示:convLSTM得到的depth和pose,基于optic flow的前向-后向warping损失计算做训练。

具体的depthnet和posenet架构如下:
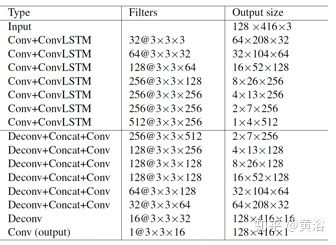
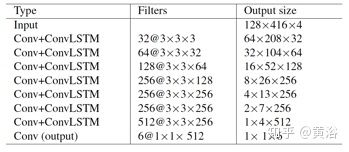
具体参数如下表:
21. Learning Monocular Visual Odometry via Self-Supervised Long-Term Modeling
这是NEC美研的一个自监督深度学习的CNN+LSTM方法,其架构如图所示
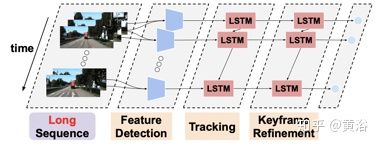
两步的训练框架(短时和长时序列)如图:分别是左右两个,采用depth和pose,各接一层convLSTM,
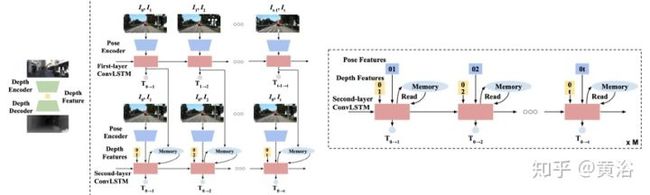
而循环连续性的两层LSTM姿态关系如图
结束
发布于昨天 12:01