Elasticsearch - Fuzzy query
引言
fuzzy query 是基于Levenshtein Edit Distance(莱温斯坦编辑距离)基础上,对索引文档进行模糊搜索。当用户输入有错误时,使用这个功能能在一定程度上召回一些和输入相近的文档。
例子
首先,我们来直观感受下这个功能。
现在索引的文档如下:
PUT levtest/_doc/_bulk
{ "index" : { "_id": 1 } }
{ "title": "lucky" }
|
此时,向索引发送如下请求:
GET /_search
{
"query": {
"fuzzy" : { "title" : "luky" }
}
}
|
由于查询词luky和索引lucky之间的编辑距离为1,此时是可以召回文档lucky的。
fuzzy query的参数
| 参数名 | 含义 |
|---|---|
| fuzziness | 定义最大的编辑距离,默认为AUTO,即按照es的默认配置。 fuzziness可选的值为0,1,2,也就是说编辑距离最大只能设置为2. AUTO策略: 在AUTO模式下,es将根据输入查询的term的长度决定编辑距离大小。用户也可以自定义term长度边界的最大和最小值,AUTO:[low],[high],如果没有定义的话,默认值为3和6,即等价于 AUTO:3,6,即按照以下方案: 输入查询term的长度: 0-2:必须精确匹配 3-5:编辑距离为1 >5:编辑距离为2 |
| prefix_length | 定义最初始不会被“模糊”的term的数量。这是基于用户的输入一般不会在最开始犯错误的设定的基础上设置的参数。这个参数的设定将减少去召回限定编辑距离的的term时,检索的term的数量。默认参数为0. |
| max_expansions | 定义fuzzy query会扩展的最大term的数量。默认为50. |
| transpositions | 定义在计算编辑聚利时,是否允许term的交换(例如ab->ba),实际上,如果设置为true的话,计算的就是Damerau,F,J distance。默认参数为false。 |
注意:如果prefix_length设为0并且max_expansions设置为很大的一个数,这个查询的计算量将会是非常大。很有可能导致索引里的每个term都被检查一遍。
参数应用的例子:
GET /_search
{
"query": {
"fuzzy" : {
"user" : {
"title": "ki",
"boost": 1.0,
"fuzziness": 2,
"prefix_length": 0,
"max_expansions": 100
}
}
}
} |
具体的计算流程

至于FST是什么,具体可以参考:lucene字典实现原理
如果想进一步深入了解如何根据编辑距离进行召回,可以参考:Levenshtein Automata
为了进一步了解es的fuzzy query是如何工作的,我们来看几个例子:
我们的索引目前有以下文档:
{
"_index": "bitao_fuzzy_test",
"_type": "doc",
"_id": "2",
"_score": 1,
"_source": {
"id": 2,
"title": "组合沙发",
"title_pinyin": "zu he sha fa",
"title_pinyin_continuous": "zuheshafa"
}
},
{
"_index": "bitao_fuzzy_test",
"_type": "doc",
"_id": "4",
"_score": 1,
"_source": {
"id": 4,
"title": "卧室电视柜",
"title_pinyin": "wo shi dian shi gui",
"title_pinyin_continuous": "woshidianshigui"
}
},
{
"_index": "bitao_fuzzy_test",
"_type": "doc",
"_id": "5",
"_score": 1,
"_source": {
"id": 5,
"title": "酒柜",
"title_pinyin": "jiu gui",
"title_pinyin_continuous": "jiugui"
}
},
{
"_index": "bitao_fuzzy_test",
"_type": "doc",
"_id": "6",
"_score": 1,
"_source": {
"id": 6,
"title": "橱柜",
"title_pinyin": "chu gui",
"title_pinyin_continuous": "chugui"
}
},
{
"_index": "bitao_fuzzy_test",
"_type": "doc",
"_id": "1",
"_score": 1,
"_source": {
"id": 1,
"title": "沙发组合",
"title_pinyin": "sha fa zu he",
"title_pinyin_continuous": "shfazuhe"
}
},
{
"_index": "bitao_fuzzy_test",
"_type": "doc",
"_id": "3",
"_score": 1,
"_source": {
"id": 3,
"title": "电视柜",
"title_pinyin": "dian shi gui",
"title_pinyin_continuous": "dianshigui"
}
|
每个文档都将经过ik_max_word的中文分词器,经过分词后,构建的词典含有以下词:
"token": "卧室",
"token": "电视机",
"token": "电视",
"token": "机柜",
"token "组合",
"token": "沙发",
"token": "酒柜",
"token": "橱柜",
"token": "电视柜",
"token"电视",
"token": "柜",
这时我们进行如下的模糊查询:
{
"profile":"true",
"query": {
"multi_match": {
"fields": [ "title" ],
"query": "卧室电视机柜",
"fuzziness": "1"
}
}
} |
这时将得到以下的召回
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 3,
"successful": 3,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 3.1329184,
"hits": [
{
"_index": "bitao_suggester_test",
"_type": "doc",
"_id": "4",
"_score": 3.1329184,
"_source": {
"id": 4,
"title": "卧室电视柜",
"title_pinyin": "wo shi dian shi gui",
"title_pinyin_continuous": "woshidianshigui"
}
},
{
"_index": "bitao_suggester_test",
"_type": "doc",
"_id": "3",
"_score": 1.708598,
"_source": {
"id": 3,
"title": "电视柜",
"title_pinyin": "dian shi gui",
"title_pinyin_continuous": "dianshigui"
}
},
{
"_index": "bitao_suggester_test",
"_type": "doc",
"_id": "5",
"_score": 0.75678295,
"_source": {
"id": 5,
"title": "酒柜",
"title_pinyin": "jiugui"
}
},
{
"_index": "bitao_suggester_test",
"_type": "doc",
"_id": "6",
"_score": 0.75678295,
"_source": {
"id": 6,
"title": "橱柜",
"title_pinyin": "chugui"
}
}
]
}
} |
你一定很疑惑,为什么会召回这么多文档,按照编辑距离的定义,只有"卧室电视柜"与原query :"卧室电视机柜"编辑距离为1才对。
为了解开这个疑惑,我们来进一步看看es具体是怎么召回的:
在发送给索引进行召回时,我们看到,实际是发送了这么一个指令:
"title:卧室 ((title.smart_word:电视)^0.5 (title.smart_word:电视柜)^0.6666666) (title.smart_word:电视 (title.smart_word:电视柜)^0.5) ((ConstantScore(title.smart_word:柜))^0.0 (title.smart_word:橱柜)^0.5 (title.smart_word:酒柜)^0.5)"
|
|
这个指令是怎么构成的,指令里的词是怎么来的?
我们来看下输入的query的分词:
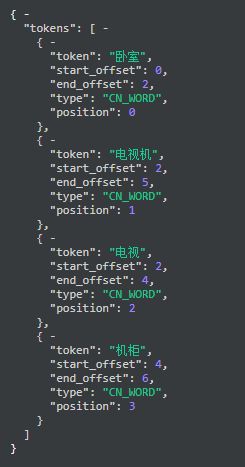
而我们的词典包含 "卧室","电视机","电视","机柜","组合","沙发", "酒柜", "橱柜","电视柜","电视", "柜"
看到这,就离答案不远了。
实际上,当对“卧室电视机柜” 进行fuzzy query时,es首先对其进行分词,然后针对每个词,进行编辑距离为一的词典词召回。
其中分出来的词“卧室” 与词典中的 “卧室”的Levenshtein Distance都为0,所以都召回;
其中分出来的词“电视机” 与词典中的 “电视”的Levenshtein Distance为1,所以 “电视”被召回,与“电视柜”编辑距离为1,所以“电视柜”也被召回;
其中分出来的词“电视” 与词典中的 “电视”的Levenshtein Distance为0,所以 “电视”被召回,与“电视柜”编辑距离为1,所以“电视柜”也被召回;
其中分出来的词“机柜” 与词典中的 “柜”、“酒柜”、“橱柜”的Levenshtein Distance都为1,所以都被召回了;
所以最后组成的发送给索引的查询语句如下构成:
"title:卧室 ((title.smart_word:电视)^0.5 (title.smart_word:电视柜)^0.6666666) (title.smart_word:电视 (title.smart_word:电视柜)^0.5) ((ConstantScore(title.smart_word:柜))^0.0 (title.smart_word:橱柜)^0.5 (title.smart_word:酒柜)^0.5)"
至于权重是如何设置的,目前还没有具体研究,待续吧。