欢迎回到 NodeJS 事件循环系列。在这篇文章中,我将谈一下 NodeJS 处理 I/O 的细节。我希望能够深挖事件循环的处理机制以及 I/O 如何和其它异步操作很好的协同工作。如果你错过了任何这个系列的文章,我非常推荐你根据下面的阅读导引去阅读。我在前三篇文章中讲了 NodeJS 事件循环中的许多概念。
原文的阅读导引
- Reactor Pattern and the Big Picture
- Timers and Immediates
- Promises, Next-Ticks and Immediates
- Handling I/O (This Article)
- Event Loop Best Practices
异步 I/O 阻塞太主流了
我们经常讨论关于NodeJS 的异步 I/O。比如我们之前写过的第一篇文章(first article of this series),I/O 从未打算同步的。
在所有的操作系统处理中,他们为 I/O 操作提供事件通知接口(比如 linux 的 epoll, macOS 的 kqueue 等等)。NodeJS 利用这些平台的事件通知系统提供非阻塞的异步 I/O。
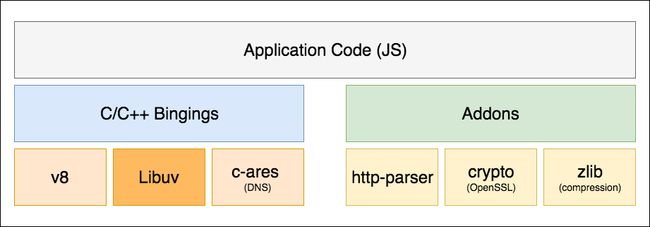
正如我们所见,NodeJS 是一系列工具合集的高可用的 NodeJS 框架。这些工具包括:
- Chrome v8 引擎 -- 高可用 JS
- Libuv -- 带有异步 I/O 的事件循环
- C-ares -- 用于 DNS 操作
-
其它的附加部分比如 http-parser, crypto 和 zlib
 libuv 2.png
libuv 2.png
在这篇文章中,我们将会谈到 Libuv 及它如何提供异步 I/O 给 Node,让我们再次看一下这个示意图。
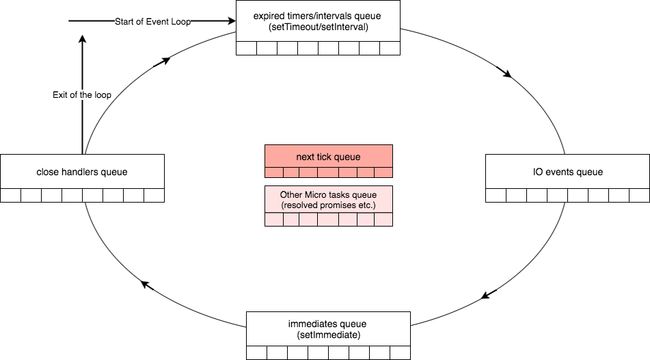
让我们回顾一下我们到目前为止学到的事件循环的内容:
- 事件循环是从执行多个 expired timers 开始
- 然后它将执行任何的 I/O 操作,然后选择性等待任何 I/O 操作结束。
- 然后移动到下一步执行 setImmediate 的回调
- 最后他将执行所有的 I/O 结束处理程序
- 在每个阶段之间,libuv 需要将每个阶段的结果传递给 Node 架构(也就是 Javascript)的上层。每次这件事发生的时候,所有的 process.nextTick 回调和微任务回调将会被执行。
现在,让我们尝试来理解一下 NodeJS 如何在 event loop 中处理 I/O。
tips: 什么是 I/O?通常任何除了 CPU 之外的外部设备的调用都叫做 I/O,最常见的 I/O 操作就是文件处理和 TCP/UDP 网络操作。
Libuv 和 NodeJS I/O
JS 自身并没有任何地方可以去处理异步 I/O 操作。在开发 NodeJS 期间,libuv 被创建出来用来给 Node 提供异步 I/O 操作,虽然 libuv 是一个独立的库,也可以被单独引用。Libuv 在 NodeJS 结构中的角色是抽象内部复杂的 I/O 操作并且提供共一个 Node 顶层的通用接口。所以 Node 可以执行独立于平台的异步 I/O,而不需要担心它所运行的平台。
警告!
如果你对事件循环没有基本的了解,我推荐你去读一下 event loop 系列之前的那几篇文章,因为这边我会一笔带过一下,这篇文章我更多的会讲解 I/O。
我可能会使用 libuv 自己的一些代码片段,而且我只会使用特定的 Unix 代码片段和示例来简化操作。 特定的 Windows 的代码可能略有不同,但应该没有太大区别。
你需要懂一些 C 语言,不需要特别多,一些对基本的代码流程的理解就可以。
在上面的 NodeJS 架构示例图中可以看到,libuv 在结构的底层。现在让我们看看 NodeJS 上层和 libuv 事件循环多个阶段的关系。

在我们之前看到的示例图2中,事件循环中有四个独立的阶段。但是在 libuv 中,有7个独立阶段,分别是:
1. 计时器 -- 执行通过 setTimeout 和 setInterval 添加的 expired timer 和 interval 回调
2. 悬停的 I/O 回调 -- 执行任何完成/错误的 I/O 操作回调函数
3. Idle 处理程序 -- 做一些 libuv 核心操作
4. 预备处理程序 -- 做一些轮询 I/O 之前的预备工作
5. I/O 轮询 — 选择性的等待任何 I/O 去完成
6. 检查处理程序 - 在轮询I / O后执行一些事后检查工作。 通常,setImmediate 调度的回调将在此处调用。
7. 关闭处理程序 -- 在任何结束的 I/O 操作后执行。
现在如果你还记得第一篇文章的内容,你也许会感到困惑:
1. 什么是检查处理程序?它并没有出现在事件循环示例图中。
2. 什么是 I/O 轮询?为什么我们执行在 I/O 回调的时候需要阻塞 I/O 操作。Node 不是非阻塞的吗?
让我来回答上面的问题。
检查处理程序(Check Handlers)
现在你也许会困惑 I/O 轮询到底是什么,虽然我将 I/O 回调队列和 I/O 轮询合并成事件循环示例图的简单的一个阶段,I/O 轮询会在完成/错误 的 I/O 回调后执行。
但是在大多数的 I/O 轮询中,这是可选择的。I/O 轮询会在某些状态下并不会执行。为了更彻底的理解,让我们来看一下 libuv 是如何处理的。
r = uv__loop_alive(loop); if (!r) uv__update_time(loop); while (r != 0 && loop->stop_flag == 0) { uv__update_time(loop); uv__run_timers(loop); ran_pending = uv__run_pending(loop); uv__run_idle(loop); uv__run_prepare(loop); timeout = 0; if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT) timeout = uv_backend_timeout(loop); uv__io_poll(loop, timeout); uv__run_check(loop); uv__run_closing_handles(loop); if (mode == UV_RUN_ONCE) { uv__update_time(loop); uv__run_timers(loop); } r = uv__loop_alive(loop); if (mode == UV_RUN_ONCE || mode == UV_RUN_NOWAIT) break; }
这个会让不熟悉 C 语言的人看起来比较费劲。别担心,让我们尝试看一下。上述代码 libuv 源码 core.c 文件内部的 uv_run 函数的部分代码,更重要的是,它是 NodeJS 事件循环的核心。
如果你再回过头看一下图3,上面的代码会更好理解。让我们一行一行去理解这个代码。
1. uv__loop_alive — 检查是否有关联的处理程序需要被调用,或者是否有任何活动的操作挂起。
2. uv__update_time — 它会发起一个系统调用去获取当前时间然后更新循环时间。(这个用来去辨认 expired timers).
3. uv__run_timers -- 执行所有的 expired timers
4. uv__run_pending -- 执行所有的完成/错误的 I/O 回调
5. uv__io_poll — 做 I/O 轮询
6. uv__run_check -- 执行所有的检查处理程序(setImmediate 回调在这执行)
7. uv__run_closing_handles -- 执行所有的关闭处理程序
首先,事件循环会检查事件循环是否还是还是存在的,这个检查是通过 uv__loop_alive 函数做的。这个函数很简单:
static int uv__loop_alive(const uv_loop_t* loop) { return uv__has_active_handles(loop) || uv__has_active_reqs(loop) || loop->closing_handles != NULL; }
uv__loop_alive 函数就简单的返回布尔值。如果符合以下条件则值是 true:
- 会有一些活动的处理程序可以被执行
- 会有一些活动的请求处于等待状态
- 有一些关闭处理程序可以被调用
只要 uv__loop_alive 函数返回 true,事件循环就会保持高速循环。
在执行了所有的 expired timers 回调以后,uv__run_pending 函数会被调用。这个函数会将完成的 I/O 操作存储在 libuv 事件的 pending_queue。如果 pending_queue 是空的,函数则返回 0,否则,所有的 pending_queue 的回调将会执行,并且函数返回 1。
static int uv__run_pending(uv_loop_t* loop) { QUEUE* q; QUEUE pq; uv__io_t* w; if (QUEUE_EMPTY(&loop->pending_queue)) return 0; QUEUE_MOVE(&loop->pending_queue, &pq); while (!QUEUE_EMPTY(&pq)) { q = QUEUE_HEAD(&pq); QUEUE_REMOVE(q); QUEUE_INIT(q); w = QUEUE_DATA(q, uv__io_t, pending_queue); w->cb(loop, w, POLLOUT); } return 1; }
现在让我们看一下 libuv 中通过调用 uv__io_poll 的 I/O 轮询操作。
你需要看到 uv__io_poll 函数获取一个通过 uv _backend_timeout 函数计算的时间 timeout 参数,该参数是通过uv_backend_timeout 计算出来的 。uv__io_poll 使用这个倒计时去明确多久需要去阻塞这个 I/O。如果这个倒计时的时间是 0,I/O 轮询将会被跳过并且事件循环将会到达检查处理程序(setImmediate) 阶段。如何检查这个超时的值是一个有趣的部分。基于上面的 uv_run的代码,我们可以推断如下:
1. 如果事件循环执行 UV_RUN_DEFAULT 模式,timeout 是通过 uv_backend_timeout 方法计算的。
2. 如果事件循环执行 UV_RUN_ONCE 模式并且如果 uv_run_pending 返回0(例如 pending_queue 是空的),timeout 是通过 uv_backend_timeout 计算的。
3. 否则 timoout 是 0.
tips: 让我们尝试着不要在这里去关心事件循环的不同模式比如 UV_RUN_DEFAULT 和 UV_RUN_ONCE 的区别 。但是如果你真的对这些很感兴趣,可以查看这里 here。
现在让我们看一下 uv_backend_timeout方法去理解如何确定超时。
int uv_backend_timeout(const uv_loop_t* loop) { if (loop->stop_flag != 0) return 0; if (!uv__has_active_handles(loop) && !uv__has_active_reqs(loop)) return 0; if (!QUEUE_EMPTY(&loop->idle_handles)) return 0; if (!QUEUE_EMPTY(&loop->pending_queue)) return 0; if (loop->closing_handles) return 0; return uv__next_timeout(loop); }
- 如果设置了循环的 stop_flag ,确定循环即将退出,则 timeout 是 0。
- 如果这里没有挂起的活跃事件处理程序或者活跃的操作,这里没有需要等待的内容,因此 timeout 是0。
- 如果有挂起的 idle handles 准备执行,则不应该等待 I/O。因此 timeout 是 0。
- 如果 pending_queue 中有完成的 I/O 处理程序,则不应等待 I/O。 因此 timeout 为0。
- 如果有任何挂起的 close handlers 要执行,不应该等待 I/O。因此 timeout 是 0。
如果上面的情况都没遇到过,uv__next_timeout 方法会被调用来明确 libuv 需要等待 I/O 多久。
int uv__next_timeout(const uv_loop_t* loop) { const struct heap_node* heap_node; const uv_timer_t* handle; uint64_t diff; heap_node = heap_min((const struct heap) &loop->timer_heap); if (heap_node == NULL) return -1; / block indefinitely */ handle = container_of(heap_node, uv_timer_t, heap_node); if (handle->timeout <= loop->time) return 0; diff = handle->timeout - loop->time; if (diff > INT_MAX) diff = INT_MAX; return diff; }
uv__next_timeout 的作用是,它会返回一个最接近计时器的时间值。如果没有计时器,它将返回 -1 代表无限。
现在你已经知道这个问题的答案:为什么我们在执行 I/O 回调后要阻塞 I/O。Node 不是应该非阻塞的吗?
如果有任何挂起的任务待执行,则事件循环不会被阻塞。如果没有任何挂起的任务被执行,它将被阻塞直到所有的 next timer 都没有了,此处会重新启动循环。
tips:我希望你跟上了我(的节奏)。我知道这里对于你来说有太多细节了,但是清楚地去理解它,去清楚地知道到底发生了什么是很有必要的。
现在我们知道循环等待 I/O 完成要多久。超时值会传递到 uv__io_poll 函数。这个函数将会监听任何传入的 I/O 操作直到超时到期或者达到了系统指定的最大安全倒计时值。在超时后,事件循环将会再次变成活跃的并且移动到“check hanlders” 阶段。
I/O 轮询在不同的操作系统上会有不同的执行表现。在 Linux 中,它会被 epoll_wait 核心系统调用,在 macOS 使用 kqueue。在 windows 中,它通过 IOCP 的 GetQueueCompleteionsStatus 做到。我不会深究 I/O 轮询是如何工作的因为它真的非常复杂,并且需要别的系列文章去讲述了(并且我应该不会去写。
一些线程池的内容
目前为止,在这些文章中我们还没说过线程池。正如我们第一篇文章说到的,线程池主要用于在DNS操作期间执行所有文件I / O操作,getaddrinfo 和 getnameinfo 的调用仅仅是因为不同平台中的文件 I/O 的复杂性(到底多复杂,看这篇文章)。自从线程池的尺寸被限制(默认是 4),多个文件系统操作的请求会被阻塞直到线程池是可获取的。然而线程池的大小可以使用环境变量 UV_THREADPOOL_ZISE增长到 128(写这篇文章的时候),以提高应用的性能。
尽管如此,这个固定大小的线程池已经确定是 NodeJS 应用的瓶颈。因为文件 I/O,getaddrinfo,getnameinfo 并不是唯一在线程池中被执行的操作。一些 CPU 密集型加密操作比如 randomBytes, randowFill 和 pbkqf2 一样会在 libuv 线程池中执行来为了阻止一些不利于应用性能的事。但是同样会导致给 I/O 操作的线程池有限的资源更紧张。
截止目前的 libuv 提高的提议,它被建议让线程池基于负荷是可伸缩的,但是这个提案被停止了,它被替换为一个为了 threading 的可插拔 API,以便将来引入。
本文的某些部分的灵感来自SaúlIbarraCorretgé在NodeConfEU 2016上所做的演示。如果您想了解更多有关libuv的信息,我强烈建议您观看它。
【地址不贴了】
更多
在这篇文章中,我讲了一些 NodeJS 处理 I/O 的细节,深挖 libuv 的源码。我相信非阻塞,事件驱动的 NodeJS 对于你来说更清楚了。如果你有任何问题,我将非常乐意回答。因此,请不要犹豫去回复这篇文章。 如果你真的喜欢这篇文章,如果你能鼓掌并鼓励我,我很乐意写更多。 谢谢。
原文地址:
https://jsblog.insiderattack.net/handling-io-nodejs-event-loop-part-4-418062f917d1