YOLO类算法,发展到现在有了3代,称之为v1、v2、v3(version)。v3算法现在可以毫不夸张的成为开源通用目标检测算法的领头羊,虽然本人一直都很欣赏SSD,但不得不说V3版本已经达到目前的颠覆。
YOLOv3
转自:https://blog.csdn.net/jh0lmes/article/details/81264262 侵删
自己学习留存用,望见谅
两个甚至多个距离很近的重叠目标很难分辨出来是当下目标检测的一大难题,重叠目标可是同类目标或不同类目标。大多数算法会对图像进行尺度变化,缩放到较小的分辨率,但在这样小的分辨率下只会给出少量的bbox,容易造成目标的误判或者漏判。小目标检测一直以来也被看做是对算法的一种评估,v1和v2都不如SSD,而v3做到了,它对这种距离很近的物体或者小物体有很好的鲁棒性,虽然不能保证百分百,但是这个难题得到了很大程度的解决。
1.为什么v3和v2版本的测试性能提高很大,但速度却没有降低?
2.为什么v3性能上能有这么大的改进?或者说为什么v3在没有提高输入数据分辨率的前提下,对小目标检测变得这么好?
3.v2和v3相比,同样是416的feature map,为什么有这么大的提高?
要回答上述三个问题,必须要看看作者发布的v3论文了,v3的创新点:
Class Prediction:v3使用的是分类预测,使用了简单的logistic regression(逻辑回归)---binary cross-entropy loss(二元交叉熵损失)来代替softmax进行预测类别,由于每个点所对应的bbox少并且差异大,所以每个bbox与ground truth的matching策略变成了1对1。当预测的目标类别很复杂的时候,采用logistic regression进行分类是更合理的。比如Open Images Dataset数据集有很多重叠的标签,如女人和人,softmax每个候选框只对应着一个类别,而logistic regression使用multi-label classification(多标签分类)对数据进行更合理的建模。
Bounding Box Prediction
边界框预测。与之前YOLO版本一样,v3的anchor box也是通过聚类得到,每个bbox预测四个坐标值(tx,ty,tw,th),预测的cell图像左上角的偏移(cx,cy),及之前得到bbox的宽和高pw和ph可以对bbox按下图的方式进行预测,在训练这几个坐标值的时候采用了sum of squared error loss(平方和距离误差损失),因为这种方式的误差可以很快的计算出来。v3对每个bounding box通过逻辑回归预测一个物体的得分,如果预测的这个bbox与真实的边框值大部分重合且比其他所有预测的要好,那么这个值就为1。如果overlap没有达到一个阈值(v3阈值是0.5),那么这个预测的bbox将会被忽略,也就是会显示成没有损失值。
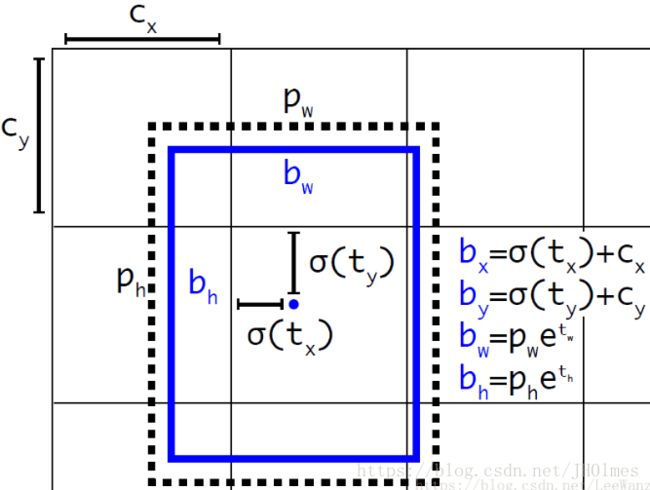
detection的策略不同:跨尺寸多级预测,解决了v1和v2颗粒度粗,对小目标无力的问题。v3提供了3种尺寸不一的边界框。用类似于FPN(feature pyramid network)网络提取这些尺寸的特征,以形成金字塔形网络。在基本特征提取器中增加了几个卷积层,并用最后的卷积层预测一个三维张量编码:边界框、框中目标和分类预测。在voc数据集实验中,神经网络分别为每种尺寸各预测了3个边界框,所以得到的张量是N×N×[3x(4+1+20)],其中包含4个边界框offset、1个目标置信度预测以及20种分类预测。v2只有一个detection,而v3有3个,一个下采样的,feature map为13*13,还有2个上采样的element-wise sum,feature map为26*26和52*52,而v2把多尺度考虑到训练的data采样上,最后也只是用到了13*13的feature map,获得更有意义的语义信息,这应该是对小目标影响最大的地方,v2--->v3经历了从单层预测五种bbox变成每层3种bbox。
element-wise sum
简称为Eltwise,有三种类型:product(点乘)、sum(求和)、max(取最大值)。sum把bottom对应元素相加,product是对应相乘,max是对应取最大,其中sum为默认操作。eltwise层要求对应bottom层的blob一致,得到的结果top层的blob和bottom层一致,这个过程想象成三维的过程很好理解。Concat层虽然利用到了上下文的语义信息,但仅仅是将其拼接起来,之所以能起到效果,在于它在不增加算法复杂度的情形下增加了channel数目。而Eltwise层直接关联上下文的语义信息,像这样的“encoder-decoder”的过程,有助于利用较高维度的feature map信息,有利于提高小目标的检测效果。
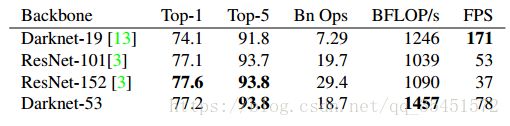
backbone不同:加入shortcut以加深网络,采用简化的residual block取代了原来1×1和3×3的block。这和上一点是有关系的,v2的darknet-19变成了v3的darknet-53,这是因为需要上采样,卷积层的数量自然就多了,另外作者还是用了一连串的3*3和1*1卷积,3*3的卷积增加channel,而1*1的卷积用于压缩3*3卷积后的特征表示,这样一增一减,效果超棒。v3一共有53个卷积层,所以称它为 Darknet-53,其在性能上远超Darknet-19,且在效率上同样优于ResNet-101和ResNet-152。Darknet-53在精度上可以与最先进的分类器相媲美,同时浮点运算(FLOPS,floating-point operations per second,每秒所执行的浮点运算次数)更少,速度也更快。Darknet-53的速度比ResNet-101快1.5倍,比ResNet-152快2倍,且还是在保证精度的前提下。Darknet-53可实现每秒最高的测量浮点运算,可更好利用GPU,使其预测效率更高,速度更快。这主要是因为ResNets的层数太多,效率不高。v2是一个纵向自上而下的网络架构,随着channel数目的不断增加,FLOPS是不断增加的,而v3网络架构是横纵交叉的,看着卷积层多,其实很多channel的卷积层没有继承性,另外虽然yolov3增加了anchor centroid,但是对ground truth的估计变得更加简单,每个ground truth只匹配一个先验框,而且每个尺度只预测3个框,v2预测5个框。这样的话也降低了复杂度。下表是在ImageNet上的实验结果:
router:由于top down 的多级预测,进而改变了router(或者说concatenate)时的方式,将原来诡异的reorg改成了upsample。
特征提取器不同:这次用了一个新的网络来提取特征,它融合了YOLOv2、Darknet-19以及其他新型残差网络,由连续的3×3和1×1卷积层组合而成,当然其中也添加了一些shortcut connection,
个人认为作者在创造v2的时候做了很多尝试和借鉴,实现了匹敌SSD的效果,但是他因为被借鉴的内容所困扰,只借鉴了皮毛而没领略其真谛,导致性能的停留。近几年涌现出各种别出心裁的目标检测佳作,像DSSD和FPN,说不定作者哪天茅塞顿开,一拍脑门,做成了v3,可能作者本人都没想到。但是作者目前没有写篇论文,认为没有创造性实质性的改变,写了一个report,科研的精神值得肯定!如果对比v2和v3你会发现反差确实很大,所以上面的问题才不奇怪。

失败尝试
1. Anchor box坐标的偏移预测
尝试了常规的Anchor box预测方法,比如利用线性激活将坐标x、y的偏移程度预测为边界框宽度或高度的倍数。但发现这种做法降低了模型的稳定性,且效果不佳。
2. 用线性方法预测x和y,而不是使用逻辑方法
尝试使用线性激活来直接预测x和y的offset,而不是逻辑激活,这降低了mAP成绩。
3. focal loss
尝试使用focal loss,但它使的mAP降低了2点。 对于focal loss函数试图解决的问题,YOLOv3从理论上来说已经很强大了,因为它具有单独的对象预测和条件类别预测。因此,对于大多数例子来说,类别预测没有损失?或者其他的东西?并不完全确定。
4. 双IOU阈值和真值分配
在训练期间,Faster RCNN用了两个IOU阈值,如果预测的边框与.7的ground truth重合,那它是个正面的结果;如果在[.3—.7]之间,则忽略;如果和.3的ground truth重合,那它就是个负面的结果。尝试了这种思路,但效果并不好。
官网介绍的关键点
Note: If during training you see nan values for avg (loss) field - then training goes wrong, but if nan is in some other lines - then training goes well.---nan只有出现在avg (loss)时才是错误
When should I stop training:When you see that average loss 0.xxxxxx avg no longer decreases at many iterations then you should stop training.Once training is stopped, you should take some of last .weights-files from darknet\build\darknet\x64\backup and choose the best of them.---什么时候可以停止训练,还能接着继续训练
Overfitting - is case when you can detect objects on images from training-dataset,but can't detect objects on any others images. You should get weights from Early Stopping Point.---什么情况是过拟合
IoU (intersect of union) - average instersect of union of objects and detections for a certain threshold = 0.24---交并比
How to improve object detection:---怎样提升检测效果
1.Before training:set flag random=1 in your .cfg-file - it will increase precision by training Yolo for different resolutions.---训练前设置flag random=1可提高精度
2.increase network resolution in your .cfg-file (height=608, width=608 or any value multiple of 32) - it will increase precision.---提高分辨率
3.recalculate anchors for your dataset for width and height from cfg-file:darknet.exe detector calc_anchors data/obj.data -num_of_clusters 9 -width 416 -height 416 then set the same 9 anchors in each of 3 [yolo]-layers in your cfg-file---设置锚点
4.desirable that your training dataset include images with objects at diffrent: scales, rotations, lightings, from different sides, on different backgrounds。---样本特点尽量多样化,亮度,旋转,背景,目标位置,尺寸
5.desirable that your training dataset include images with non-labeled objects that you do not want to detect - negative samples without bounded box (empty .txt files)---添加没有标注框的图片和其空的txt文件,作为negative数据
6.for training with a large number of objects in each image, add the parameter max=200 or higher value in the last layer [region] in your cfg-file.---
7.to speedup training (with decreasing detection accuracy) do Fine-Tuning instead of Transfer-Learning, set param stopbackward=1 in one of the penultimate convolutional layers before the 1-st [yolo]-layer, for example here: https://github.com/AlexeyAB/darknet/blob/0039fd26786ab5f71d5af725fc18b3f521e7acfd/cfg/yolov3.cfg#L598---可在第一个[yolo]层之前的倒数第二个[convolutional]层末尾添加 stopbackward=1,以此提升训练速度
8.After training - for detection:Increase network-resolution by set in your .cfg-file (height=608 and width=608) or (height=832 and width=832)or(any value multiple of 32) - this increases the precision and makes it possible to detect small objects,you do not need to train the network again, just use .weights-file already trained for 416x416 resolution.---即使在用416*416训练完之后,也可以在cfg文件中设置较大的width和height,增加网络对图像的分辨率,从而更可能检测出图像中的小目标,而不需要重新训练
9.if error Out of memory occurs then in .cfg-file you should increase subdivisions=16, 32 or 64 Out of memory.---出现这样的错误需要通过增大subdivisions来解决。
下面是GitHub中,提问的问题
mask
v3可进行3种不同尺度的预测。 使用检测层在三种不同尺寸的特征图上进行检测,分别具有stride=32、16、8,在输入图像为416 x 416的情况下,使用13x13、26x26、52x52的比例检测目标。网络下采样输入图像到第一检测层,即stride为32feature map为13x13的层进行检测,接着上采样2倍,并与具有相同特征图的先前层的特征图连接大小。 现在在具有stride=16的层上进行另一检测,重复相同的上采样过程,并且在stride=8处进行最终检测。在每个尺度上,每个单元使用3个anchor来预测3个bounding box,从而使用9个anchor的总数(anchor在不同尺度上是不同的)。作者在论文中说明,这有助于v3更好地检测小型物体,上采样可以帮助网络学习有助于检测小物体的细粒度特征。
每个尺度分配3个anchor,尺度指的是运用不同大小的feature map做detection。anchor是feature map上每个grid产生的不同大小和宽高比的box(不是bbox),用于确定该anchor中包含object的概率。与bbox的关系是:一旦anchor中包含某object的概率很大,然后对它的位置进行精修,接着进行非极大值抑制,得到的即是bbox。
不同尺度的3个detection是这样起作用的:1.对于小目标,大尺度feature map提供分辨率信息,小尺度feature map提供给语义信息;2.对于正常目标,小尺度feature map同时提供分辨率和语义信息。 因此不同尺度的3个detection可以有效检测不同尺度的object。 所有尺度下的检测结果都将做为预测结果,因为尺寸差异大的objects会分布在不同feature map上被检测到,即使同一个object出现在多个feature map上被检测到,也会因为nms取一个最佳的,所以不影响。 因此计算loss也是利用到了所有尺度,绝对不会只用某一个尺度。
分辨率信息直接反映的是构成object的像素的数量,一个object像素数量越多,对object的细节表现就越丰富越具体,这也就是为什么大尺度feature map提供的是分辨率信息了。语义信息在目标检测中指的是让object区分于背景的信息,即语义信息是让你知道这个是object,其余是背景。在不同类别中语义信息并不需要很多细节信息,分辨率信息大,反而会降低语义信息,因此小尺度feature map在提供必要的分辨率信息下语义信息会提供的更好,而对于小目标,小尺度feature map无法提供必要的分辨率信息,所以还需结合大尺度的feature map。
v3预测3种不同尺度的框(boxes),每个尺度的3个框,所以张量数量为NxNx[3x(4+1+80)]。网络会在预测三种尺度的特征N分别为13,26,52,分别对应各三种anchor :
13---(116×90); (156×198); (373×326)
26---(30×61); (62×45); (59×119);
52---(10×13); (16×30); (33×23)。 (大尺度用小anchor,提高小目标识别能力)
使用k-means聚类来确定bounding box priors,选择9个clusters和3个scales,然后在整个scales上均匀分割clusters,9个cluster即是上述9个anchor。
https://github.com/pjreddie/darknet/issues/567
according to paper, each yolo (detection) layer get 3 anchors with associated with its size, mask is selected anchor indices.
https://github.com/pjreddie/darknet/issues/558
Every layer has to know about all of the anchor boxes but is only predicting some subset of them. This could probably be named something better but the mask tells the layer which of the bounding boxes it is responsible for predicting. The first [yolo] layer predicts 6,7,8 because those are the largest boxes and it's at the coarsest scale. The 2nd [yolo] layer predicts some smallers ones, etc.
The layer assumes if it isn't passed a mask that it is responsible for all the bounding boxes, hence the if statement thing.
The [yolo] layers simply apply logistic activation to some of the neurons, mainly the ones predicting (x,y) offset, objectness, and class probabilities. then if you call get_yolo_detections(or something like that) it interprets the output as described in the paper.
num
num is 9 but each yolo layer is only actually looking at 3 (that's what the mask thing does). so it's (20+1+4)*3 = 75. If you use a different number of anchors you have to figure out which layer you want to predict which anchors and the number of filters will depend on that distribution.
according to paper, each yolo (detection) layer get 3 anchors with associated with its size, mask is selected anchor indices.
nan
https://github.com/pjreddie/darknet/issues/560
https://github.com/pjreddie/darknet/issues/566
https://github.com/pjreddie/darknet/issues/716
https://github.com/pjreddie/darknet/issues/746
https://github.com/AlexeyAB/darknet/issues/825
https://github.com/AlexeyAB/darknet/issues/786
https://github.com/AlexeyAB/darknet/issues/636#issuecomment-381400954
Anchor box
预测边界框的宽度和高度可能是有意义的,但实际上这会导致训练期间不稳定的梯度。 相反大多数目标检测器预测对数空间变换后的宽和高,或简单地偏移到预定义的默认边界框,也即是anchor。然后将这些变换应用于anchor box以获得预测。v3有三个anchor,可以预测每个单元的三个边界框。
通常情况下,YOLO不预测边界框中心的绝对坐标。它预测的是偏移量,预测的结果通过一个sigmoid函数,迫使输出的值在0~1之间。例如,若对中心的预测是(0.4,0.7),左上角坐标是(6,6),那么中心位于13×13特征地图上的(6.4,6.7);若预测的x,y坐标大于1,比如(1.2,0.7),则中心位于(7.2,6.7)。注意现在中心位于图像的第7排第8列单元格,这打破了YOLO背后的理论,因为如果假设原区域负责预测某个目标,目标的中心必须位于这个区域中,而不是位于此区域旁边的其他网格里。为解决这个问题,输出是通过一个sigmoid函数传递的,该函数在0到1的范围内压扁输出,有效地将中心保持在预测的网格中。
对于尺寸为416×416的图像,v3预测((52×52)+(26×26)+ 13×13))×3 = 10647个边界框。 然后忽略阈值分数低于某值的框数,再通过NMS将10647减少到1。
https://github.com/pjreddie/darknet/issues/568
https://github.com/pjreddie/darknet/issues/577
https://github.com/AlexeyAB/darknet/issues/838
打印参数的含义
详见yolo_layer.c文件的forward_yolo_layer函数:
-
printf(
"Region %d Avg IOU: %f, Class: %f, Obj: %f, No Obj: %f,
-
.5R: %f, .75R: %f, count: %d\n", net.index, avg_iou/count,
-
avg_cat/class_count, avg_obj/count, avg_anyobj/(l.w*l.h*l.
-
n*l.batch), recall/count, recall75/count, count)
刚开始迭代,由于没有预测出相应的目标,所以查全率 [.5R .75R] 较低,会出现大面积为0的情况,这个是正常的;我在实际训练的时候,v3它的训练轮数是50200,我的数据量比较小,因此迭代到900轮的时候,每一轮训练完显示的损失值都是nan,其原因可能就是上边因为阈值他直接忽略掉了这个bbox导致没有loss,之前的版本我使用时貌似不是这样的。
下面的两张图,第一张是v2的输出图,设置batch=64,subdivision=8,所以在训练输出中,训练迭代包含了8组,每组又包含了8张图片,跟设定的batch和subdivision的值一致;第二张是v3的输出图,

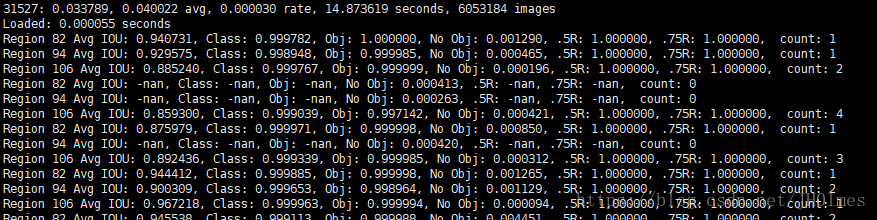
训练log中各参数的意义
-
Region Avg IOU
#平均IOU,表示预测的bbox和ground truth的交并比,期望趋近于1
-
Class
#是标注物体的概率,期望该值趋近于1
-
Obj
#期望该值趋近于1
-
No Obj
#期望该值越来越小但不为零
-
.5R
#0.5_recall???
-
.75R
#0.75_recall???
-
avg
#平均损失,期望该值趋近于0
-
rate
#当前学习率
-
-
针对上面第二幅图中第一行中的信息,如下的输出是由 detector.c 生成的:
-
-
31527
#训练迭代次数
-
0.033789
#总体Loss(损失),越小越好
-
0.040022 avg
#平均Loss,越低越好,一般低于0.06 avg即可终止训练
-
0.000030 rate:
#当前学习率,在.cfg文件中定义的
-
14.873619 seconds:
#当前批次训练花费的总时间
-
6053184 images:
#31527*192的大小,参与训练的图片总量,即每次训练batch个图像
-
-
见第二幅图第三行信息解析如下:
-
-
Region
82 Avg IOU:
0.940731
-
#在当前subdivision内平均IOU(交并比),期望趋近于1
-
Class:
0.999782
#标注物体分类的正确率,期望该值趋近于1
-
Obj:
1.000000:
#期望该值趋近于1
-
No Obj:
0.001290:
#期望该值越来越小,但不为零
-
.5R:
1.000000
#IOU为0.5时的recall
-
.75R:
1.000000
#IOU为0.75时的recall
-
count:
1
#表示当前subdivision图片中包含正样本的图片数
-
-
v2版本,见第一幅图第一行最后一个元素
-
Avg Recall:
0.125000:
-
#是在recall/count中定义的,是当前模型在所有subdivision图片中检测
-
#出的正样本与实际的正样本的比值。这里是0.125的正样本被正确的检测到
模型保存
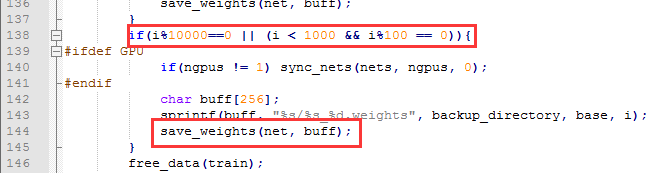
默认状况下,迭代次数小于1k时,每100次保存一次,大于1000时,每1w次保存一次。可根据需求修改,然后重新编译即可[ 先 make clean,找到代码位置,darknet/examples/detector.c 138行,然后再编译一次 make]。
可视化训练过程
等待训练结束后(有时还没等结束模型就开始发散了),因此需要检测各项指标(如loss)是否达到了我们期望的数值,如果没有,要分析为什么。可视化训练过程的中间参数可以帮助我们分析问题。
可视化中间参数需要用到训练时保存的log文件:
./darknet detector train cfg/yolov3.cfg yolov3.conv.9 2>1 | tee train_log.txt
保存log时会生成两个文件,文件里保存的是网络加载信息和checkout点保存信息,train_log.txt中保存的是训练信息。
modify the net
1.改进策略总览:https://github.com/AlexeyAB/darknet#how-to-improve-object-detection
2.下面三个问题是对小目标检测需做出的调整:
https://github.com/AlexeyAB/darknet/issues/930
https://github.com/AlexeyAB/darknet/issues/848
https://github.com/AlexeyAB/darknet/issues/977
https://github.com/AlexeyAB/darknet/issues/391
https://github.com/pjreddie/darknet/issues/323
下面网站中有人提出说这样修改网络:
-
SomeOne:
For pjreddie
's darknet , I can give you one suggestion:
-
In darknet/src/image.c,
try
to change line
259
-
int width = im.h *
.006 ---> int width = fmax(
1, im.h *
.006)
-
when
object
's height is very small this parameter becomes very very
-
small, so
try my suggestion
or make another combination
and see any
-
improvement.
-
OR clone AlexeyAB
's darknet and use small_object=1 in region layer of
-
your cfg file , this parameter
is used
when
object
's size is 1% by 1% of
-
the image
's resolution, which happens to be in your case.
https://github.com/pjreddie/darknet/issues/531
-
you can
change this line:
-
darknet/cfg/yolov3.cfg Line
720
-
layers =
-1,
36
-
to this
to detect
object
4x4: layers =
-1,
11
and stride=
4
-
to this
to detect
object
2x2: layers =
-1,
4
and stride=
8
-
to this
to detect
object
1x1: layers =
-1,
0
and stride=
16
-
4x4 means
size
of
object
4x4 pixels
after the image has been resized
to
416x416
-
-
AlexeyAB:I recommend you:
-
1.
use yolov3.cfg instead
of yolo v2
-
2.darknet/cfg/yolov3.cfg Line
720
-
set layers =
-1,
11 instead
of layers =
-1,
36
-
and
set stride =
4 instead
of stride =
2
-
3.
set width=
832 height=
832
and random=
1
in cfg-
file
and train it (
if
-
GPU-
memory
size
allow it),what GPU
do you
use?
-
Someone:My gpu
is Quadro P4000,GPU-
memory
is
8G.
-
AlexeyAB:
-
Try
to
set:batch=
64 subdivisions=
64 width=
832 height=
832
and random=
1
in
-
each
of
3 [yolo]-layers.If the
error
Out
of
memory occurs,
then try
to
-
use width=
608 height=
608.
-
Someone:There appeared -
nan,
after
2000 iterations,
test it.It cant
't work,
-
unless break large images into smaller ones and detect them individually.
随着网络深度的增加,语义值增加,而特征映射的分辨率降低。因此,通过将早期图层的特征图(分辨率大小较高)与后续图层连接起来,语义丰富的特征图有助于检测较小的对象(金字塔网络的类型)。要连接第11层输出尺寸104x104x128,前一层的步幅必须增加4倍,以匹配第11层的输出尺寸。
3.确定锚值:https://github.com/AlexeyAB/darknet/issues/527
./darknet detector calc_anchors cfg/voc.data -num_of_clusters 9 -width 416 -heigh 416

然后将所得的9个锚(18个值)复制到 [yolo] cfg文件中去
4.增加锚点:
https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
https://github.com/AlexeyAB/darknet/issues/611
-
If you
use
11 anchors,
then you should
distribute they across
3 yolo-layers
-
- i.e. you should specify
mask=
with
indexes
of anchors which
are used
in
-
this layer.
And
then you should
change
in
each yolo-layer.
-
filters=(classes + coords +
1)*<
number
of
mask
in
current layer>
-
-
Someone:
if we have
11 anchors, can we give
5 anchors
to one
mask layer
-
and rest
mask layers
with
3 anchors.(
5+
3+
3=
11)
-
AlexeyAB:Yes!
darknet53.conv.74 和 yolov3.weights 区别
-
A: I don
't understand what is the main difference between darknet53.conv.74
-
and yolov3.weights.
-
According
to what I understand, yolov3.weights
is trained
in COCO dataset
-
but which layers are loaded, all
of them?
And darknet53.conv
.74 just the
-
convolutionals
and trained
in Imagenet?
-
If I have a model which I train
with yolov3.weights initialization weights
-
and I want
to train it
with darknet53.conv
.74 how would you solve it?
-
-
B: you
've got the first part right: yolo3.weights includes weights for all
-
layers which were trained
in COCO
while darknet53.conv
.74 includes weights
-
for the convolutional layers trained
in Imagenet.
-
Regarding your last question, I don
't know what you would want to accomplish
-
with that. The training that resulted
in yolov3.weights,
if I
'm not mistaken,
-
started
from darknet53.conv
.74. Loading its weights again would probably
-
only mess up the training done
in the upper layers.
https://github.com/pjreddie/darknet/issues/569
训练1通道数图像
提速不明显,且正确率会下降。
-
AlexeyAB:
If you will use only
1-channel input instead
of
3-channels input,
-
then will be change only the
1st convolutional layer, but all rest will
-
still the same.
As you can see, the
1st layer spend only
2.14%
of total
-
computation, so
if total time
100ms (
and
1st layer took
2.14ms),
then use
-
of
1-channel instead
of
3-channels will recude this time
to
98.6ms (
1st
-
layer
0.71ms), so speedup will be about
1.4% only.
-
-
SomeOne:
By AlexyAB
's suggested solution, I can detect targets in testing
-
videos which are either ch=
1
or ch=
3.
On my side, IOU=
70% / recall=
0.75 /
-
mAP=
80%. The performance
of detection
is
not
as good
as training
on color
-
dataset.
-
Here are some check points:
-
1.Keep training
and testing
in the same color space:
for example, both
of
-
them are
in gray.
-
2.Overfitting:
do training again
on the same training dataset but
in ch=
3
-
format;
then,
do detection again.
-
3.Include some samples
in the training
set,
if the content
and
object size
-
is completely different
in your original dataset: even
if you already
-
trained
on
"random setting".
-
*My testing refers
to the net-cfg file
as same
as used
in training.
-
*My code-based
is
for YOLOv2+mAP-enable-
function
https://github.com/AlexeyAB/darknet/issues/359
https://github.com/pjreddie/darknet/issues/468
FPS
v2用如下代码测试fps
./darknet detector valid cfg/voc.data cfg/yolo-voc.cfg darknet19_448.conv.23
https://github.com/pjreddie/darknet/issues/392
mAP
darknet.exe detector map data/obj.data yolo-obj.cfg backup\yolo-obj_1500.weights
https://github.com/pjreddie/darknet/issues/671
https://github.com/AlexeyAB/darknet/issues/824
Deep Residual Networks
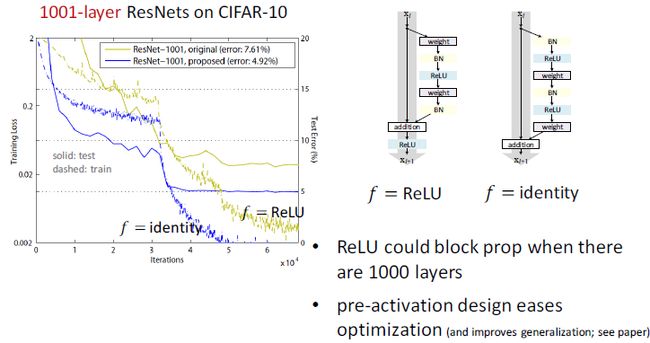
深度残差网络,层数越多的神经网络越难以训练。当层数超过一定数量后,传统的深度网络就会因优化问题而出现欠拟合(underfitting)的情况。残差学习框架大幅降低训练更深层网络的难度,也使准确率得到显著提升。在 ImageNet 和 COCO 2015 竞赛中,共有 152 层的深度残差网络 ResNet 在图像分类、目标检测和语义分割各个分项都取得最好成绩,相关论文更是连续两次获得 CVPR 最佳论文。最新研究发现,当残差网络将身份映射作为 skip connection 并实现 inter-block activation,正向和反向信号能够直接从一个区块传播到另一个区块,这样就达到了 1001 层的残差网络。由此可见,神经网络的深度这一非常重要的因素,还有很大的提升空间。
一、深度谱
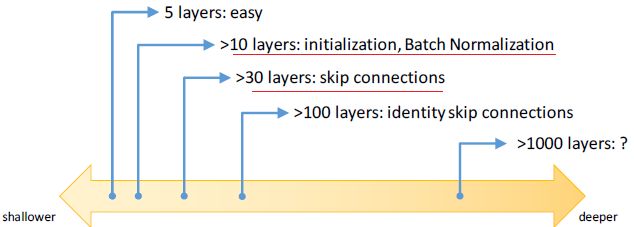
二、为使用网络层数更多,通常采用的方法有:初始化算法,BN方法;
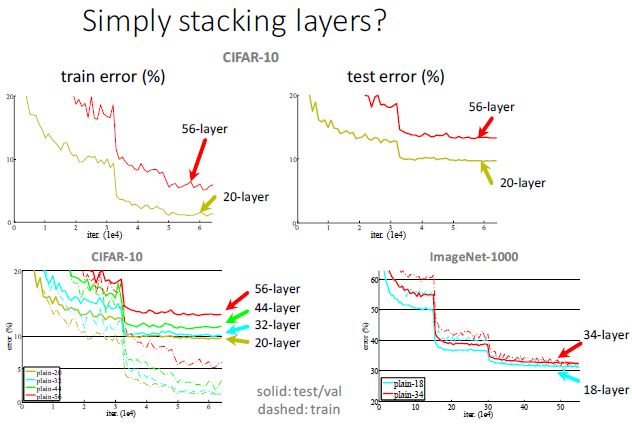
三、是否简单堆叠的网络层数越多,训练误差和测试误差就越小?答案正好相反;
四、目前流行的网络结构大致可以分为三类:直线型(如AlexNet, VGGNet),局部双分支型(ResNet),局部多分支型(GoogleNet)
很久以前人们就已经认识到更深的网络能够产生更好的数据表达,但是如何训练一个很深的网络却一直是一个困扰人们的问题,这主要是由于梯度消失或爆炸以及尺度不均匀的初始化造成的。围绕这一问题,人们提出了ReLU、Xavier、pReLU、batch normalization和path-SGD等一系列方法,但是即使有这些方法,神经网络的训练仍然呈现了degradation(退化)的现象,随着网络深度的增加,网络的性能反而下降,而且这种性能的下降并不是由前面所说的问题造成的。
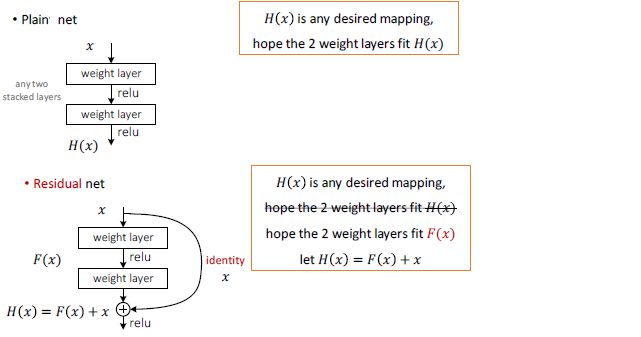
五、深度残差学习(Deep Residual Learning)的思想
假如目前有一个可以工作的很好的网络A,这时来了一个比它更深的网络B,只需要让B的前一部分与A完全相同,后一部分只实现一个恒等映射(identity mapping),这样B最起码能获得与A相同的性能,而不至于更差。深度残差学习的思想也由此而产生,既然B后面的部分完成的是恒等映射,何不在训练网络的时候加上这一先验(在网络训练过程中,加入先验信息指导非常重要,合理的先验往往会取得非常好的效果),于是构造网络的时候加入了捷径(shortcut)连接,即每层的输出不是传统神经网络中的输入的映射,而是输入的映射和输入的叠加,如下图中的"Residual net"所示。
在Residual net中:identity为恒等映射,此条路径一直存在,F(x)为需要学习的残差函数(residual function):H(x) - x = F(x)。问题的重新表示或预处理会简化问题的优化。假设期望的网络层关系映射为 H(x),让the stacked nonlinear layers 拟合另一个映射,F(x)= H(x) - x , 那么原先的映射就是 F(x)+x,假设优化残差映射F(x) 比优化原来的映射H(x)容易。
首先求取残差映射 F(x)= H(x)-x,那么原先的映射就是 F(x)+x。尽管这两个映射应该都可以近似理论真值映射 the desired functions (as hypothesized),但是它俩的学习难度是不一样的。这种改写启发于"网络层数越多,训练和测试误差越大"性能退化问题违反直觉的现象。如果增加的层数可以构建为一个恒等映射(identity mappings),那么增加层数后的网络训练误差应该不会增加,与没增加之前相比较。性能退化问题暗示多个非线性网络层用于近似identity mappings 可能有困难。使用残差学习改写问题之后,如果identity mappings 是最优的,那么优化问题变得很简单,直接将多层非线性网络参数趋0。实际identity mappings 不太可能是最优的,但是上述改写问题可能帮助预处理问题。如果最优函数接近identity mappings,那么优化将会变得容易些。 实验证明该思路是对的。
F(x)+x 可以通过shortcut connections 来实现,如下图所示:
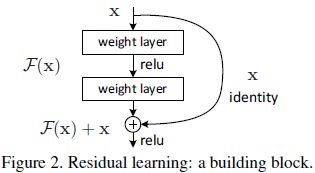
上图中的shortcut connections执行一个简单的恒等映射;既没有参数,也没有计算复杂度。公式分析如下:
(1)需要学习的残差映射

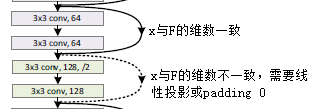
(2)x和F的维数必须相同,如果x和F的维数不相同,则对x进行线性投影(linear projection)使用其与F的维数一致,公式如下:

六、网络架构
I.普通网络(Plain Network)
设计原则:1对于输出特征图大小相同的层,它们的卷积拥有相同的filter个数;2如果输出的特征图大小减半,则filter个数乘以2,以确保每层的时间复杂度相同

II.残并网络(Residual Network)
在遵循普通网络设计原则的基础上,增加了shortcut connections
七、恒等映射的重要性
I.平滑的正向传播
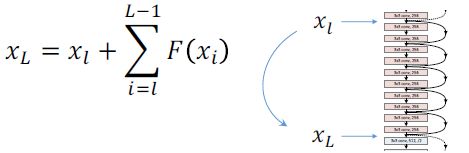
任意xl被直接正向传播到xL,xL是xl与残差相加的结果。
II.平滑的反向传播

八、保持最短路径尽量平滑
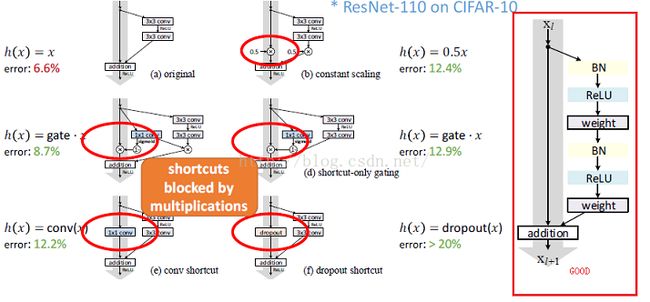
如果h(x)不是identity mapping,它将阻塞正向、反向传播,从而导致误差增加
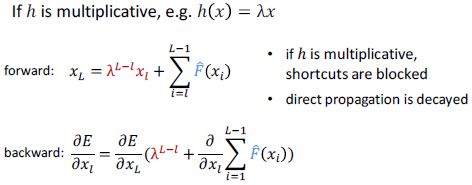
BN可能阻塞传播
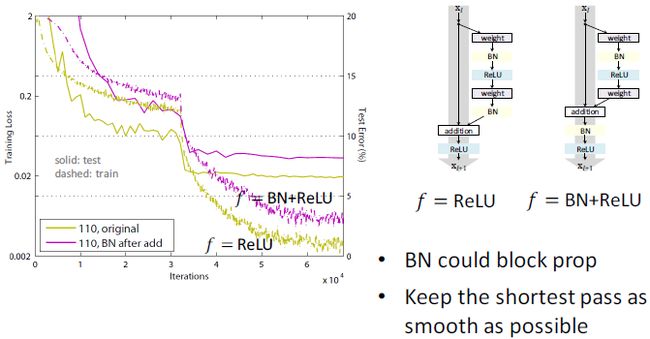
ReLU可能阻塞传播
分块输出
分块输出中的参数是一些重要且必须要输出的参数,IOU(交集比并集)是一个衡量模型检测特定的目标好坏的重要指标。100%表示拥有了一个完美的检测,即矩形框跟目标完美重合,很明显,我们需要优化这个参数。

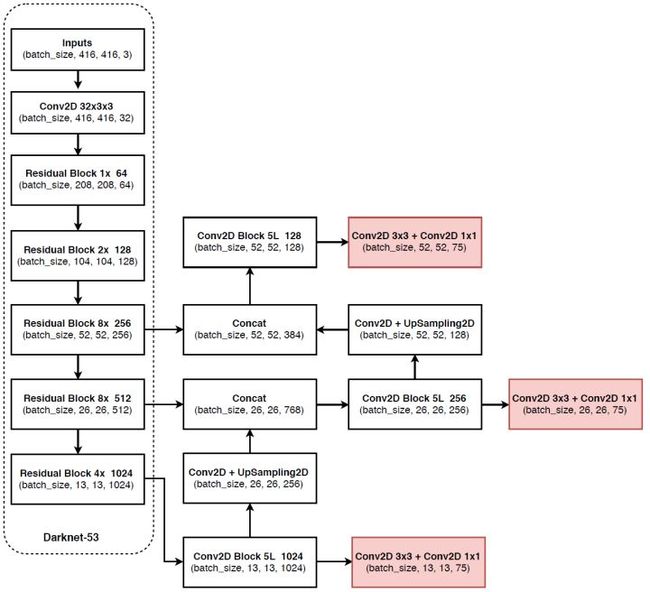
网络结构
1X1卷积核作用
1*1卷积核没有考虑与前一层局部信息之间的关系,在Network In Network中用于加深加宽网络结构 ,在Inception网络( Going Deeper with Convolutions )中用来降维。
单通道图像通过1*1卷积核等价于一个线性变换,而多通道(多个feature map)相当于多个feature map的线性组合,如果再加上激活层,那就相当于一个mini的多层(多个卷积下)感知机了。普通卷积层+多个1*1卷积(followed by 激活层)等价于类patch级别的MLP(Multi-Layer Perceptron,多层感知器),而单独的1*1卷积,实际上是多个通道的参数化pooling(线性组合)。还有一个重要的功能,就是可以在保持feature map 尺寸不变(即不损失分辨率)的前提下大幅增加非线性特性,把网络做得很deep。具体来说这两个作用:
1. 实现跨通道的交互和信息整合
利用MLP代替传统的线性卷积核,从而提高网络的表达能力。可从跨通道pooling的角度解释,MLP等价于在传统卷积核后面接cccp层(cascaded cross channel parametric pooling,亦称mlpconv,级联交叉通道参数池化),从而实现多个feature map的线性组合,实现跨通道的信息整合。而cccp层是等价于1×1卷积的,因此细看NIN的caffe实现,就是在每个传统卷积层后面接了两个cccp层(其实就是接了两个1×1的卷积层)。
2. 进行卷积核通道数的降维和升维
GoogleNet中对于每一个Inception模块,原始模块是左图,右图中是加入了1*1卷积进行降维的。虽然左图的卷积核都比较小,但是当输入和输出的通道数很大时,乘起来也会使得卷积核参数变的很大,而右图加入1*1卷积后可以降低输入的通道数,卷积核参数、运算复杂度也就跟着降下来了。以GoogLeNet的3a模块为例,输入的feature map是28×28×192,3a模块中1*1卷积通道为64,3*3卷积通道为128,5*5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64+3×3×192×128+5×5×192×32,而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),参数大约减少到原来的三分之一。同时在并行pooling层后面加入1×1卷积层后也可以降低输出的feature map数量,左图pooling后feature map是不变的,再加卷积层得到的feature map,会使输出的feature map扩大到416,如果每个模块都这样,网络的输出会越来越大。而右图在pooling后面加了通道为32的1*1卷积,使得输出的feature map数降到了256。GoogleNet利用1*1的卷积降维后,得到了更为紧凑的网络结构,虽然总共有22层,但是参数数量却只是8层的AlexNet的十二分之一(当然也有很大一部分原因是去掉了全连接层)。
最近大热的MSRA的ResNet同样也利用了1×1卷积,并且是在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,使得卷积层的输入和输出的通道数都减小,参数数量进一步减少,如下图的结构(不然真不敢想象152层的网络要怎么跑起来)。

yolov3那些尝试过并没有提升表现的想法
① 想对Anchor box的x,y偏移使用线性激活方式做一个对box宽高倍数的预测,结果发现没有好的表现并且是模型不稳定。
②对anchor box的x, y使用线性的预测,而不是使用逻辑回归,实验结果发现这样做使他们模型的mAP下降。
③使用Focal loss,测试结果还是掉mAP。
yolov3-voc.cfg
-
[net]
-
# Testing
-
# batch=1
-
# subdivisions=1
-
# Training
-
batch=
64
#每batch个样本更新一次参数。
-
subdivisions=
8
#将batch分割为8个子batch,每个子batch的大小batch/subdivisions
-
#在darknet代码中,会将batch/subdivisions命名为batch
-
#一般来说,batch越大训练效果越好,但要在显存的承受范围内
-
#subdivisions越大,越可以减轻显卡压力,找到适合自己显卡的一个数值
-
height=
416
-
width=
416
-
channels=
3
-
momentum=
0.9
#动量,影响着梯度下降到最优值得速度,一般,神经网络在更新权值时,采用如下
-
#公式:w= w-learning_rate*dw*,引入momentum后,采用如下公式:
-
#v=mu(v)-learning_rate*dw*
-
#w=w+v
-
#其中,v初始化为0,mu是设定的一个超变量,最常见的设定值是0.9
-
#可以这样理解上式:如果上次的momentum(v)与这次的负梯度方向是相同的,那么
-
#这次下降的幅度就会加大,从而加速收敛
-
-
decay=
0.0005
#权重衰减比,将学习后的参数按照固定比例进行降低,防止过拟合,
-
#越大对过拟合的抑制能力越强
-
-
#https://github.com/AlexeyAB/darknet/issues/279,详细解释
-
-
angle=
0
#通过旋转角度来生成更多训练样本
-
saturation =
1.5
#通过调整饱和度来生成更多训练样本
-
exposure =
1.5
#通过调整曝光量来生成更多训练样本
-
hue=
.1
#通过调整色调来生成更多训练样本
-
-
learning_rate=
0.001
#初始学习率,决定着权值更新的速度
-
max_batches =
50200
#训练达到max_batches后停止训练
-
policy=steps
#学习率策略,有:CONSTANT, STEP, EXP, POLY, STEPS, SIG, RANDOM
-
burn_in=
1000
#迭代次数小于burn_in,学习率更新有一种方式,大于burn_in,用policy更新方式
-
steps=
40000,
45000
#steps与scales组合,表示迭代到40000,学习率衰减十倍,45000时再衰减十倍
-
scales=
.1,
.1
-
-
[convolutional]
-
batch_normalize=
1
#是否做BN
-
filters=
32
#输出多少个特征图,即卷积核的个数
-
size=
3
#卷积核的尺寸
-
stride=
1
#做卷积运算的步长
-
pad=
1
#如果pad为0,padding由 padding参数指定。如果pad为1,padding大小为size/2
-
activation=leaky
#激活函数,有logistic,loggy,relu,elu,relie,linear,leaky,tanh,selu
-
-
####################### 下采样1 #######################
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
64
-
size=
3
-
stride=
2
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
32
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
64
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
####################### 下采样2 #######################
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
3
-
stride=
2
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
64
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
64
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
####################### 下采样3 #######################
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
3
-
stride=
2
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
####################### 下采样4 #######################
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
3
-
stride=
2
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
####################### 下采样5 #######################
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
1024
-
size=
3
-
stride=
2
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
1024
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
1024
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
1024
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
1024
-
size=
3
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[shortcut]
-
from=
-3
-
activation=linear
-
-
#####################################################
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
size=
3
-
stride=
1
-
pad=
1
-
filters=
1024
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
size=
3
-
stride=
1
-
pad=
1
-
filters=
1024
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
512
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
size=
3
-
stride=
1
-
pad=
1
-
filters=
1024
-
activation=leaky
-
-
[convolutional]
-
size=
1
-
stride=
1
-
pad=
1
-
filters=
75
#num([yolo]层数)*(classes + 5),5 即5个坐标--->tx,ty,tw,th,to
-
#这里的75是这么来的:3*(20+5)=75
-
activation=linear
-
-
[yolo]
#在V2中[yolo]层叫做[region]层
-
mask =
6,
7,
8
#YOLO层即检测层(detection layer),一共9个anchor,但只有mask标记的属性索引
-
#到的anchor才会被使用。mask的值0、1、2,表示使用第一,第二和第三个anchor。
-
#因为检测层的每个单元预测3个box,总共有三个检测层,共计9个anchor。
-
-
anchors =
10,
13,
16,
30,
33,
23,
30,
61,
62,
45,
59,
119,
116,
90,
156,
198,
373,
326
-
#anchors可事先通过cmd计算出来,和图片数量、width、height、cluster
-
#(应该就是下面的num的值,即想要使用的anchors的数量)相关的预选框,可以手工
-
#挑选,也可以通过k-means 方法从训练样本中学出
-
classes=
20
-
num=
9
#每个cell预测几个box,与anchors数一致,调大num若Obj->0可尝试调大object_scale
-
jitter=
.3
#通过抖动产生更多数据来抑制过拟合,v2中使用的是crop、filp、及net层的angle,
-
#flip是随机的,jitter是crop的参数,jitter=.3,表示在0~0.3中进行crop
-
-
ignore_thresh =
.5
#参与计算IOU阈值大小,bbox与gt的IOU大于ignore_thresh时参与loss计算
-
#目的是控制参与loss计算的检测框的规模,当ignore_thresh过大,接近于1时,参与
-
#检测框回归loss的个数会比较少,同时也容易造成过拟合;而ignore_thresh过小,
-
#那么参与计算的会数量规模就会很大。同时也容易在进行检测框回归的时候造成欠拟
-
#合。参数一般选取0.5-0.7之间的一个值,之前的计算基础都是小尺度(13*13)用的
-
#是0.7,(26*26)用的是0.5。
-
-
truth_thresh =
1
#???
-
random=
1
#1表示会启用Multi-Scale Training,随机使用不同尺寸的图片进行训练,显存小勿用
-
-
[route]
#route层是为了从网络的早期引入更细粒度的功能,起到连接作用
-
layers =
-4
#属性只有一个值时,会输出由该值索引的网络层的特征图
-
#−4表示这个层将从route层向后输出往上第4层的特征图
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[upsample]
-
stride=
2
-
-
[route]
#当图层有两个值时,会返回由其值所索引的图层的连接特征图。
-
layers =
-1,
61
#−1, 61表示该图层将输出来自上一层和第61层的特征图,并沿深度的维度连接
-
-
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
size=
3
-
stride=
1
-
pad=
1
-
filters=
512
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
size=
3
-
stride=
1
-
pad=
1
-
filters=
512
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
256
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
size=
3
-
stride=
1
-
pad=
1
-
filters=
512
-
activation=leaky
-
-
[convolutional]
-
size=
1
-
stride=
1
-
pad=
1
-
filters=
75
-
activation=linear
-
-
[yolo]
-
mask =
3,
4,
5
-
anchors =
10,
13,
16,
30,
33,
23,
30,
61,
62,
45,
59,
119,
116,
90,
156,
198,
373,
326
-
classes=
20
-
num=
9
-
jitter=
.3
-
ignore_thresh =
.5
-
truth_thresh =
1
-
random=
1
-
-
[route]
-
layers =
-4
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[upsample]
-
stride=
2
-
-
[route]
-
layers =
-1,
36
-
-
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
size=
3
-
stride=
1
-
pad=
1
-
filters=
256
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
size=
3
-
stride=
1
-
pad=
1
-
filters=
256
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
filters=
128
-
size=
1
-
stride=
1
-
pad=
1
-
activation=leaky
-
-
[convolutional]
-
batch_normalize=
1
-
size=
3
-
stride=
1
-
pad=
1
-
filters=
256
-
activation=leaky
-
-
[convolutional]
-
size=
1
-
stride=
1
-
pad=
1
-
filters=
75
-
activation=linear
-
-
[yolo]
-
mask =
0,
1,
2
-
anchors =
10,
13,
16,
30,
33,
23,
30,
61,
62,
45,
59,
119,
116,
90,
156,
198,
373,
326
-
classes=
20
-
num=
9
-
jitter=
.3
-
ignore_thresh =
.5
-
truth_thresh =
1
-
random=
1
输出
Darknet-53的这种结构能够实现每秒最高的测量浮点运算,这意味着此网络结构可以更好地利用GPU,从而使其评估效率更高,速度更快。 实验得出Darknet-53比ResNet-101速度更快1~5倍。 Darknet-53与ResNet-152具有相似的性能,速度提高2倍。如下图所示,左边的数字x代表有几个这样的过程,共有53层卷积层,1+(1+1x2)+(1+2x2)+(1+8x2)+(1+8x2)+(1+4x2)=53。
v3中,anchor由5个变为9个,当然,这是由K均值产生的,每个尺度分配3个anchor。其中每个尺度下每个位置预测3个bbox(1个objectness+4个位置输出+C个类别的分数)。所以每个位置输出3x(1+4+C)个值,这也就是训练时yolov3.cfg里的filter的数量,同样也是每个尺度张量的深度。
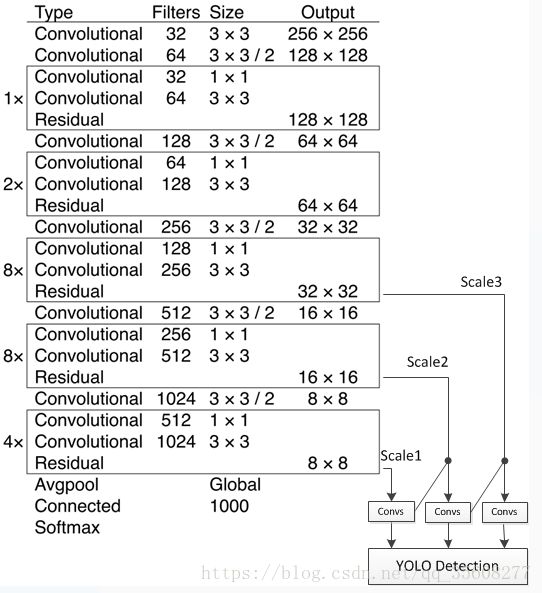
-
layer filters size input output
-
-----------------------------------------------------------------------
-
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32
-
---------------------------- Downsample 1 -----------------------------
-
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64
-
2 conv 32 1 x 1 / 1 208 x 208 x 64 -> 208 x 208 x 32
-
3 conv 64 3 x 3 / 1 208 x 208 x 32 -> 208 x 208 x 64
-
4 Shortcut Layer: 1
-
---------------------------- Downsample 2 -----------------------------
-
5 conv 128 3 x 3 / 2 208 x 208 x 64 -> 104 x 104 x 128
-
6 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64
-
7 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128
-
8 Shortcut Layer: 5
-
9 conv 64 1 x 1 / 1 104 x 104 x 128 -> 104 x 104 x 64
-
10 conv 128 3 x 3 / 1 104 x 104 x 64 -> 104 x 104 x 128
-
11 Shortcut Layer: 8
-
---------------------------- Downsample 3 -----------------------------
-
12 conv 256 3 x 3 / 2 104 x 104 x 128 -> 52 x 52 x 256
-
13 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
-
14 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
-
15 Shortcut Layer: 12
-
16 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
-
17 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
-
18 Shortcut Layer: 15
-
19 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
-
20 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
-
21 Shortcut Layer: 18
-
22 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
-
23 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
-
24 Shortcut Layer: 21
-
25 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
-
26 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
-
27 Shortcut Layer: 24
-
28 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
-
29 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
-
30 Shortcut Layer: 27
-
31 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
-
32 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
-
33 Shortcut Layer: 30
-
34 conv 128 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 128
-
35 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256
-
36 Shortcut Layer: 33
-
---------------------------- Downsample 4 -----------------------------
-
37 conv 512 3 x 3 / 2 52 x 52 x 256 -> 26 x 26 x 512
-
38 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
-
39 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
-
40 Shortcut Layer: 37
-
41 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
-
42 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
-
43 Shortcut Layer: 40
-
44 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
-
45 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
-
46 Shortcut Layer: 43
-
47 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
-
48 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
-
49 Shortcut Layer: 46
-
50 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
-
51 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
-
52 Shortcut Layer: 49
-
53 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
-
54 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
-
55 Shortcut Layer: 52
-
56 conv 256 1 x 1 / 1 26 x 26 x 512 -> 26 x 26 x 256
-
57 conv 512 3 x 3 / 1 26 x 26 x 256 -> 26 x 26 x 512
-
58 Shortcut Layer: 55
-