卷积神经网络(三) 轻量级网络EffNet pytorch实现
这篇论文是在Mobilenetv1,v2,Shufflev1发表之后提出来的,阅读论文前面的一部分就可以知道,主要也是针对这两篇论文的改进。
**
1.主要改进的地方就是下面这幅图:
**
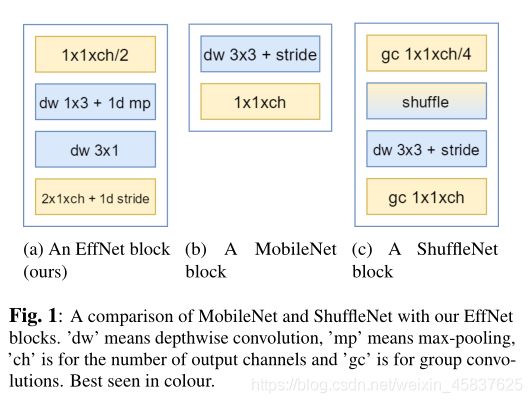
将深度可分离卷积(3,3)改成(3,1),(1,3)空间可分离卷积,这个结构在谷歌的Inception网络结构中也提到过,感兴趣的小伙伴可查阅。
2.该模块代码实现
def make_layers(self,ch_in,ch_out):
layers=[
# ch_in=32, (3,32)
nn.Conv2d(3,ch_in,kernel_size=(1,1),stride=(1,1),bias=False,padding=0,
dilation=(1,1))if ch_in==32 else nn.Conv2d(ch_in,ch_in,kernel_size=(1,1),stride=(1,1),bias=False,padding=0,dilation=(1,1)),
self.make_post(ch_in),
#DW
nn.Conv2d(ch_in,1*ch_in,groups=ch_in,kernel_size=(1,3),padding=(0,1),
bias=False,dilation=(1,1)),
self.make_post(ch_in),
nn.MaxPool2d(kernel_size=(2,1),stride=(2,1)),
#DW
nn.Conv2d(ch_in,1*ch_in,groups=ch_in,kernel_size=(3,1),stride=(1,1),padding=(1,0),
bias=False,dilation=(1,1)),
self.make_post(ch_in),
nn.Conv2d(ch_in,ch_out,kernel_size=(1,2),stride=(1,2),bias=False,dilation=(1,1)),
self.make_post(ch_out)
]
return nn.Sequential(*layers)
3.模型结构图

从模型中可以看出,在模型的第一层就使用作者自己设计的模型结构,而其他网络只是中规中矩的使用普通的卷积网络来提取特征。这个地方也是作者的创新点之一。
4.模型代码实现
#coding=utf-8
import torch.nn as nn
class Flatten(nn.Module):
def forward(self,x):
x=x.view(x.size()[0],-1)
#x=x.view(x.size(0),-1)
return x
"""
x = x.view(x.size()[0], -1) 这句话的出现就是为了将前面操作输出的多维度的tensor展平成一维,
然后输入分类器,-1是自适应分配,指在不知道函数有多少列的情况下,根据原tensor数据自动分配列数。
"""
class EffNet(nn.Module):
def __init__(self,nb_classes=10,include_top=True,weights=True):
super(EffNet,self).__init__()
#定义
self.block1 = self.make_layers(32,64)
self.block2 = self.make_layers(64,128)
self.block3 = self.make_layers(128, 256)
self.flatten= Flatten()
self.linear=nn.Linear(4096,nb_classes)
self.include_top=include_top
self.weights=weights
#定义 激活函数+BN
def make_post(self,ch_in):
layers=[
nn.LeakyReLU(0.3),
nn.BatchNorm2d(ch_in,momentum=0.99)
]
return nn.Sequential(*layers)
#定义核心模块 空间可分离卷积 深度可分离卷积 最大池化 作用:降低计算量
def make_layers(self,ch_in,ch_out):
layers=[
# ch_in=32, (3,32)
nn.Conv2d(3,ch_in,kernel_size=(1,1),stride=(1,1),bias=False,padding=0,
dilation=(1,1))if ch_in==32 else nn.Conv2d(ch_in,ch_in,kernel_size=(1,1),stride=(1,1),bias=False,padding=0,dilation=(1,1)),
self.make_post(ch_in),
#DW
nn.Conv2d(ch_in,1*ch_in,groups=ch_in,kernel_size=(1,3),padding=(0,1),
bias=False,dilation=(1,1)),
self.make_post(ch_in),
nn.MaxPool2d(kernel_size=(2,1),stride=(2,1)),
#DW
nn.Conv2d(ch_in,1*ch_in,groups=ch_in,kernel_size=(3,1),stride=(1,1),padding=(1,0),
bias=False,dilation=(1,1)),
self.make_post(ch_in),
nn.Conv2d(ch_in,ch_out,kernel_size=(1,2),stride=(1,2),bias=False,dilation=(1,1)),
self.make_post(ch_out)
]
return nn.Sequential(*layers)
def forward(self,x):
x=self.block1(x)
x=self.block2(x)
x=self.block3(x)
#判断有没有全连接
if self.include_top:
x=self.flatten(x)
x=self.linear(x)
return x
5.打印模型
model=EffNet()
print(model)
6.模型输出
EffNet(
(block1): Sequential(
(0): Conv2d(3, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
(2): Conv2d(32, 32, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), groups=32, bias=False)
(3): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
(4): MaxPool2d(kernel_size=(2, 1), stride=(2, 1), padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(32, 32, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), groups=32, bias=False)
(6): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
(7): Conv2d(32, 64, kernel_size=(1, 2), stride=(1, 2), bias=False)
(8): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
)
(block2): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
(2): Conv2d(64, 64, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), groups=64, bias=False)
(3): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
(4): MaxPool2d(kernel_size=(2, 1), stride=(2, 1), padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 64, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), groups=64, bias=False)
(6): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
(7): Conv2d(64, 128, kernel_size=(1, 2), stride=(1, 2), bias=False)
(8): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
)
(block3): Sequential(
(0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
(2): Conv2d(128, 128, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), groups=128, bias=False)
(3): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
(4): MaxPool2d(kernel_size=(2, 1), stride=(2, 1), padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(128, 128, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), groups=128, bias=False)
(6): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
(7): Conv2d(128, 256, kernel_size=(1, 2), stride=(1, 2), bias=False)
(8): Sequential(
(0): LeakyReLU(negative_slope=0.3)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.99, affine=True, track_running_stats=True)
)
)
(flatten): Flatten()
(linear): Linear(in_features=4096, out_features=10, bias=True)
)
参考文献:
论文:https://arxiv.org/abs/1801.06434
公众号:GiantPandaCV