Hadoop教程(三):HDFS、MapReduce、程序入门实践
HDFS集群主要由 NameNode 管理文件系统 Metadata 和 DataNodes 存储的实际数据。
-
NameNode: NameNode可以被认为是系统的主站。它维护所有系统中存在的文件和目录的文件系统树和元数据 。 两个文件:“命名空间映像“和”编辑日志“是用来存储元数据信息。Namenode 有所有包含数据块为一个给定的文件中的数据节点的知识,但是不存储块的位置持续。从数据节点在系统每次启动时信息重构一次。
-
DataNode : DataNodes作为从机,每台机器位于一个集群中,并提供实际的存储. 它负责为客户读写请求服务。
HDFS中的读/写操作运行在块级。HDFS数据文件被分成块大小的块,这是作为独立的单元存储。默认块大小为64 MB。
HDFS操作上是数据复制的概念,其中在数据块的多个副本被创建,分布在整个节点的群集以使在节点故障的情况下数据的高可用性。
注: 在HDFS的文件,比单个块小,不占用块的全部存储。
在HDFS读操作
数据读取请求将由 HDFS,NameNode和DataNode来服务。让我们把读取器叫 “客户”。下图描绘了文件的读取操作在 Hadoop 中。
- 客户端启动通过调用文件系统对象的 open() 方法读取请求; 它是 DistributedFileSystem 类型的对象。
- 此对象使用 RPC 连接到 namenode 并获取的元数据信息,如该文件的块的位置。 请注意,这些地址是文件的前几个块。
- 响应该元数据请求,具有该块副本的 DataNodes 地址被返回。
-
一旦接收到 DataNodes 的地址,FSDataInputStream 类型的一个对象被返回到客户端。 FSDataInputStream 包含 DFSInputStream 这需要处理交互 DataNode 和 NameNode。在上图所示的步骤4,客户端调用 read() 方法,这将导致 DFSInputStream 建立与第一个 DataNode 文件的第一个块连接。
-
以数据流的形式读取数据,其中客户端多次调用 “read() ” 方法。 read() 操作这个过程一直持续,直到它到达块结束位置。
- 一旦到模块的结尾,DFSInputStream 关闭连接,移动定位到下一个 DataNode 的下一个块
- 一旦客户端已读取完成后,它会调用 close()方法。
HDFS写操作
在本节中,我们将了解如何通过的文件将数据写入到 HDFS。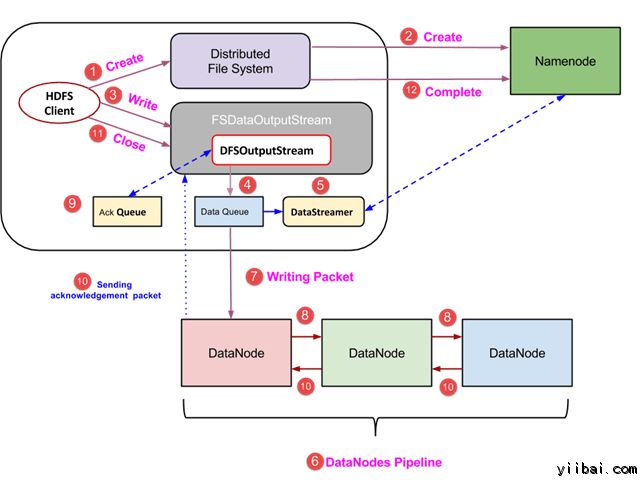
- 客户端通过调用 DistributedFileSystem对象的 create() 方法创建一个新的文件,并开始写操作 - 在上面的图中的步骤1
- DistributedFileSystem对象使用 RPC 调用连接到 NameNode,并启动新的文件创建。但是,此文件创建操作不与文件任何块相关联。NameNode 的责任是验证文件(其正被创建的)不存在,并且客户端具有正确权限来创建新文件。如果文件已经存在,或者客户端不具有足够的权限来创建一个新的文件,则抛出 IOException 到客户端。否则操作成功,并且该文件新的记录是由 NameNode 创建。
- 一旦 NameNode 创建一条新的记录,返回FSDataOutputStream 类型的一个对象到客户端。客户端使用它来写入数据到 HDFS。数据写入方法被调用(图中的步骤3)。
- FSDataOutputStream包含DFSOutputStream对象,它使用 DataNodes 和 NameNode 通信后查找。当客户机继续写入数据,DFSOutputStream 继续创建这个数据包。这些数据包连接排队到一个队列被称为 DataQueue
- 还有一个名为 DataStreamer 组件,用于消耗DataQueue。DataStreamer 也要求 NameNode 分配新的块,拣选 DataNodes 用于复制。
- 现在,复制过程始于使用 DataNodes 创建一个管道。 在我们的例子中,选择了复制水平3,因此有 3 个 DataNodes 管道。
- 所述 DataStreamer 注入包分成到第一个 DataNode 的管道中。
- 在每个 DataNode 的管道中存储数据包接收并同样转发在第二个 DataNode 的管道中。
- 另一个队列,“Ack Queue”是由 DFSOutputStream 保持存储,它们是 DataNodes 等待确认的数据包。
- 一旦确认在队列中的分组从所有 DataNodes 已接收在管道,它从 'Ack Queue' 删除。在任何 DataNode 发生故障时,从队列中的包重新用于操作。
- 在客户端的数据写入完成后,它会调用close()方法(第9步图中),调用close()结果进入到清理缓存剩余数据包到管道之后等待确认。
- 一旦收到最终确认,NameNode 连接告诉它该文件的写操作完成。
使用JAVA API访问HDFS
在本节中,我们来了解 Java 接口并用它们来访问Hadoop的文件系统。
为了使用编程方式与 Hadoop 文件系统进行交互,Hadoop 提供多种 Java 类。org.apache.hadoop.fs包中包含操纵 Hadoop 文件系统中的文件类工具。这些操作包括,打开,读取,写入,和关闭。实际上,对于 Hadoop 文件 API 是通用的,可以扩展到 HDFS 的其他文件系统交互。
编程从 HDFS 读取文件
java.net.URL 对象是用于读取文件的内容。首先,我们需要让 Java 识别 Hadoop 的 HDFS URL架构。这是通过调用 URL 对象的 setURLStreamHandlerFactory方法和 FsUrlStreamHandlerFactory的一个实例琮传递给它。此方法只需要执行一次在每个JVM,因此,它被封闭在一个静态块中。
示例代码
|
publicclassURLCat {
static{
URL.setURLStreamHandlerFactory(newFsUrlStreamHandlerFactory());
}
publicstaticvoidmain(String[] args) throwsException {
InputStream in = null;
try{
in = newURL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally{
IOUtils.closeStream(in);
}
}
}
|
这段代码用于打开和读取文件的内容。HDFS文件的路径作为命令行参数传递给该程序。
使用命令行界面访问HDFS
这是与 HDFS 交互的最简单的方法之一。 命令行接口支持对文件系统操作,例如:如读取文件,创建目录,移动文件,删除数据,并列出目录。
可以执行 '$HADOOP_HOME/bin/hdfs dfs -help' 来获得每一个命令的详细帮助。这里, 'dfs' HDFS是一个shell命令,它支持多个子命令。首先要启动 Haddop 服务(使用 hduser_用户),执行命令如下:
hduser_@ubuntu:~$ su hduser_ hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-dfs.sh hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-yarn.sh
一些广泛使用的命令的列表如下
1. 从本地文件系统复制文件到 HDFS
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -copyFromLocal temp.txt /
此命令将文件从本地文件系统拷贝 temp.txt 文件到 HDFS。
2. 我们可以通过以下命令列出一个目录下存在的文件 -ls
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -ls /

我们可以看到一个文件 'temp.txt“(之前复制)被列在”/“目录。
3. 以下命令将文件从 HDFS 拷贝到本地文件系统
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -copyToLocal /temp.txt
我们可以看到 temp.txt 已经复制到本地文件系统。
4. 以下命令用来创建新的目录
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -mkdir /mydirectory
接下来检查是否已经建立了目录。现在,应该知道怎么做了吧?
MapReduce 是适合海量数据处理的编程模型。Hadoop是能够运行在使用各种语言编写的MapReduce程序: Java, Ruby, Python, and C++. MapReduce程序是平行性的,因此可使用多台机器集群执行大规模的数据分析非常有用的。
MapReduce程序的工作分两个阶段进行:
-
Map阶段
-
Reduce 阶段
输入到每一个阶段均是键 - 值对。此外,每一个程序员需要指定两个函数:map函数和reduce函数
整个过程要经历三个阶段执行,即
MapReduce如何工作
让我们用一个例子来理解这一点 –
假设有以下的输入数据到 MapReduce 程序,统计以下数据中的单词数量:
Welcome to Hadoop Class
Hadoop is good
Hadoop is bad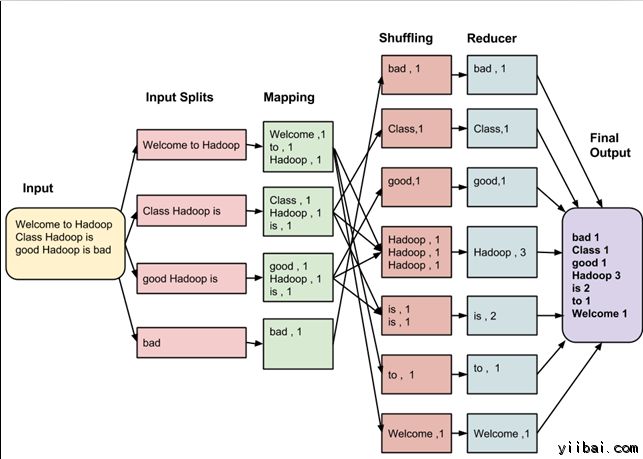
MapReduce 任务的最终输出是:
| bad |
1 |
| Class |
1 |
| good |
1 |
| Hadoop |
3 |
| is |
2 |
| to |
1 |
| Welcome |
1 |
这些数据经过以下几个阶段
输入拆分:
输入到MapReduce工作被划分成固定大小的块叫做 input splits ,输入折分是由单个映射消费输入块。
映射 - Mapping
这是在 map-reduce 程序执行的第一个阶段。在这个阶段中的每个分割的数据被传递给映射函数来产生输出值。在我们的例子中,映射阶段的任务是计算输入分割出现每个单词的数量(更多详细信息有关输入分割在下面给出)并编制以某一形式列表<单词,出现频率>
重排
这个阶段消耗映射阶段的输出。它的任务是合并映射阶段输出的相关记录。在我们的例子,同样的词汇以及它们各自出现频率。
Reducing
在这一阶段,从重排阶段输出值汇总。这个阶段结合来自重排阶段值,并返回一个输出值。总之,这一阶段汇总了完整的数据集。
在我们的例子中,这个阶段汇总来自重排阶段的值,计算每个单词出现次数的总和。
详细的整个过程
-
映射的任务是为每个分割创建在分割每条记录执行映射的函数。
-
有多个分割是好处的, 因为处理一个分割使用的时间相比整个输入的处理的时间要少, 当分割比较小时,处理负载平衡是比较好的,因为我们正在并行地处理分割。
-
然而,也不希望分割的规模太小。当分割太小,管理分割和映射创建任务的超负荷开始逐步控制总的作业执行时间。
-
对于大多数作业,最好是分割成大小等于一个HDFS块的大小(这是64 MB,默认情况下)。
-
map任务执行结果到输出写入到本地磁盘的各个节点上,而不是HDFS。
-
之所以选择本地磁盘而不是HDFS是因为,避免复制其中发生 HDFS 存储操作。
-
映射输出是由减少任务处理以产生最终的输出中间输出。
-
一旦任务完成,映射输出可以扔掉了。所以,复制并将其存储在HDFS变得大材小用。
-
在节点故障的映射输出之前,由 reduce 任务消耗,Hadoop 重新运行另一个节点在映射上的任务,并重新创建的映射输出。
- 减少任务不会在数据局部性的概念上工作。每个map任务的输出被供给到 reduce 任务。映射输出被传输至计算机,其中 reduce 任务正在运行。
- 在此机器输出合并,然后传递到用户定义的 reduce 函数。
- 不像到映射输出,reduce输出存储在HDFS(第一个副本被存储在本地节点上,其他副本被存储于偏离机架的节点)。因此,写入 reduce 输出
MapReduce如何组织工作?
Hadoop 划分工作为任务。有两种类型的任务:
-
Map 任务 (分割及映射)
-
Reduce 任务 (重排,还原)
如上所述
完整的执行流程(执行 Map 和 Reduce 任务)是由两种类型的实体的控制,称为
-
Jobtracker : 就像一个主(负责提交的作业完全执行)
-
多任务跟踪器 : 充当角色就像从机,它们每个执行工作
对于每一项工作提交执行在系统中,有一个 JobTracker 驻留在 Namenode 和 Datanode 驻留多个 TaskTracker。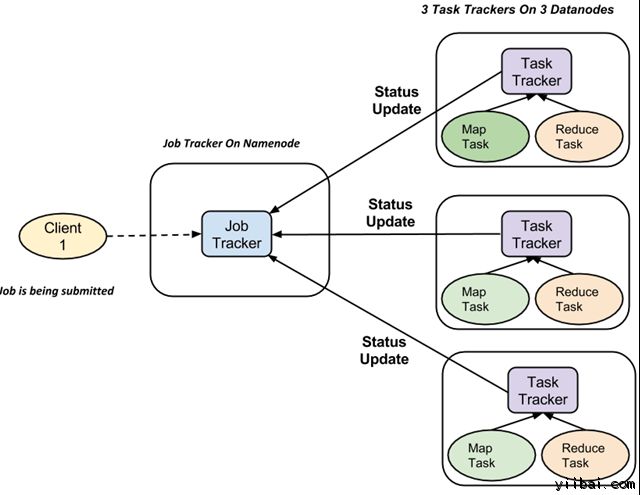
-
作业被分成多个任务,然后运行到集群中的多个数据节点。
-
JobTracker的责任是协调活动调度任务来在不同的数据节点上运行。
-
单个任务的执行,然后由 TaskTracker 处理,它位于执行工作的一部分,在每个数据节点上。
-
TaskTracker 的责任是发送进度报告到JobTracker。
-
此外,TaskTracker 周期性地发送“心跳”信号信息给 JobTracker 以便通知系统它的当前状态。
-
这样 JobTracker 就可以跟踪每项工作的总体进度。在任务失败的情况下,JobTracker 可以在不同的 TaskTracker 重新调度它。
问题陈述:
找出销往各个国家商品数量。
输入: 我们的畋输入数据集合是一个 CSV 文件, Sales2014.csv
前提条件:
- 本教程是在Linux上开发 - Ubuntu操作系统
- 已经安装了Hadoop(本教程使用版本2.7.1)
- 系统上已安装了Java(本教程使用 JDK1.8.0)。
在实际操作过程中,使用的用户是'hduser_“(此用户使用 Hadoop)。
yiibai@ubuntu:~$ su hduser_
步骤:
1.创建一个新的目录名称是:MapReduceTutorial
hduser_@ubuntu:~$ sudo mkdir MapReduceTuorial
授予权限
hduser_@ubuntu:~$ sudo chmod -R 777 MapReduceTutorial
下载相关文件:下载 Java 程序文件,拷贝以下文件:SalesMapper.java, SalesCountryReducer.java 和 SalesCountryDriver.java 到 MapReduceTutorial 目录中,
检查所有这些文件的文件权限是否正确:
如果“读取”权限缺少可重新再授予权限,执行以下命令:
yiibai@ubuntu:/home/hduser_/MapReduceTutorial$ sudo chmod +r *
2.导出类路径
hduser_@ubuntu:~/MapReduceTutorial$ export CLASSPATH="$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.1.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.1.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.1.jar:~/MapReduceTutorial/SalesCountry/*:$HADOOP_HOME/lib/*" hduser_@ubuntu:~/MapReduceTutorial$
3. 编译Java文件(这些文件存在于目录:Final-MapReduceHandsOn). 它的类文件将被放在包目录:
hduser_@ubuntu:~/MapReduceTutorial$ javac -d . SalesMapper.java SalesCountryReducer.java SalesCountryDriver.java
安全地忽略此警告:
此编译将创建一个名称与Java源文件(在我们的例子即,SalesCountry)指定包名称的目录,并把所有编译的类文件在里面,因此这个目录要在编译文件前创建。
接下来:
创建一个新的文件:Manifest.txt
hduser_@ubuntu:~/MapReduceTutorial$ vi Manifest.txt
添加以下内容到文件中:
Main-Class: SalesCountry.SalesCountryDriver
SalesCountry.SalesCountryDriver 是主类的名称。请注意,必须键入回车键,在该行的末尾。
下一步:创建一个 jar 文件
hduser_@ubuntu:~/MapReduceTutorial$ $JAVA_HOME/bin/jar cfm ProductSalePerCountry.jar Manifest.txt SalesCountry/*.class
检查所创建的 jar 文件,结果如下:

6. 启动 Hadoop
hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-dfs.sh hduser_@ubuntu:~$ $HADOOP_HOME/sbin/start-yarn.sh
7. 拷贝文件 Sales2014.csv 到 ~/inputMapReduce
hduser_@ubuntu:~$ mkdir inputMapReduce hduser_@ubuntu:~$ cp MapReduceTutorial/Sales2014.csv ./inputMapReduce/Sales2014.csv
现在使用以下命令来拷贝 ~/inputMapReduce 到 HDFS.
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/inputMapReduce /
我们可以放心地忽略此警告。验证文件是否真正复制没有?
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -ls /inputMapReduce
8. 运行MapReduce 作业
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales
这将在 HDFS 上创建一个输出目录,名为mapreduce_output_sales。此目录的文件内容将包含每个国家的产品销售。
9. 结果可以通过命令界面中可以看到
hduser_@ubuntu:~$ $HADOOP_HOME/bin/hdfs dfs -cat /mapreduce_output_sales/part-00000
结果也可以通过 Web 界面看到,打开 Web 浏览器,输入网址:http://localhost:50070/dfshealth.jsp ,结果如下:
现在选择 'Browse the filesystem' 并导航到 /mapreduce_output_sales 如下:

打开 part-r-00000 ,如下图所示:
下载后,查看结果内容。
from: http://www.yiibai.com/hadoop/