为什么我们这么期待Kubernetes?
Kubernetes的目标用一张被很多人引用过的图来说明最好:

Kubernetes的目标是让你可以像管理牲畜一样管理你的服务,而不是像宠物一样,同时提高资源的利用率,让码农关注在应用开发本身,高可用的事情就交给Kubernetes吧。这个图本来是openstack提出的,但纯粹IaaS层的解决方案实现不了这个目标,于是有了Kubernetes。
Kubernetes和Borg系出同门,基本是Borg的开源改进版本,引用Google Borg论文里的说法:
it (1) hides the details of resource management and failure handling so its users can focus on application development instead; (2) operates with very high reliability and availability, and supports applica- tions that do the same; and (3) lets us run workloads across tens of thousands of machines effectively
我们如何验证是否达到这个目标了呢?
随机关掉一台机器,看你的服务能否正常
减少的应用实例能否自动迁移并恢复到其他节点
服务能否随着流量进行自动伸缩
我们从一个简单的多层应用的架构改进来探讨下:
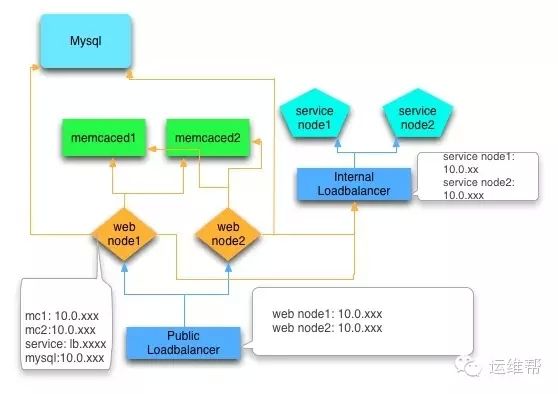
说明:
mysql应该是一主多从的架构,这里为了简单进行了省略
service后面也会依赖数据库等资源,这里为了简单进行了省略
箭头表示调用和依赖关系
具体分析一下为了达到我们的目标,需要做到改进:
Loadbalancer要调用后端应用服务节点,后端应用服务节点挂了或者迁移增加节点,都要变更Loadbalancer的配置。这样明显达不到目标,于是计划将Loadbalancer改造成Smart Loadbalancer,通过服务发现机制,应用实例启动或者销毁时自动注册到一个配置中心(etcd/zookeeper),Loadbalancer监听应用配置的变化自动修改自己的配置。
Web应用对后端资源的依赖,比如Mysql和Memcached,对应资源的ip一般是写到配置文件的。资源节点变更或者增加都要变更应用配置。
Mysql计划该成域名访问方式,而不是ip。为了避免dns变更时的延迟问题,需要在内网架设私有dns。高可用采用MHA方案,然后配合服务发现机制自动修改dns。
Memcached计划参照couchbase的方式,通过服务发现机制,使用SmartClient,客户端应用监听配置中心的节点变化。难点可能在于对Memcached的改造(可以参考couchbase)。另外也可以通过增加一层代理的机制实现。
应用节点迁移时依赖的系统和基础库不一样如何处理?部署方式不一样如何处理?磁盘路径,监听端口等冲突怎么办?这个可以通过Docker这样的容器技术,将应用部署运行的方式进行标准化,操作系统和基础库的依赖允许应用自定义,对磁盘路径以及端口的依赖通过Docker运行参数动态注入,而不需要变更应用配置。Docker的自定义变量以及参数,需要提供标准化的配置文件。
服务迁移问题 每种服务都需要一个master调度中心,来监控实例状态,确定要不要进行迁移,负责统一调度。并且每个服务器节点上要有个agent来执行具体的操作,监控该节点上的应用。另外还要提供接口以及工具去操作。
网络以及端口冲突的问题比较麻烦 需要引入类似SDN的解决方案。
内存,cpu,以及磁盘等硬件资源,原来的习惯是购买服务器的时候就根据服务器的上的应用类型进行规划,如果应用和硬件解耦,这种方式需要淘汰。但必须有一种调度机制让应用迁移的时候可进行筛选。
总结一下,通过分析得出,要达到目标,关键是解耦,应用进程和资源(包括 cpu,内存,磁盘,网络)的解耦,服务依赖关系的解耦。
我们上面的改造机制基本是按照个案进行设计,Kubernetes的则是要提供一套全面通用的机制。
然后,我们看看Kubernetes对以上问题的解决方案:
先上一张Kubernetes官方的架构图

调度中心master,主要有四个组件构成:
etcd 作为配置中心和存储服务(架构图中的Distributed Watchable Storage),保存了所有组件的定义以及状态,Kubernetes的多个组件之间的互相交互也主要通过etcd。

kube-apiserver 提供和外部交互的接口,提供安全机制,大多数接口都是直接读写etcd中的数据。
kube-scheduler 调度器,主要干一件事情:监听etcd中的pod目录变更,然后通过调度算法分配node,最后调用apiserver的bind接口将分配的node和pod进行关联(修改pod节点中的nodeName属性)。scheduler在Kubernetes中是一个plugin,可以用其他的实现替换(比如mesos)。有不同的算法提供,算法接口如下:

kube-controller-manager 承担了master的主要功能,比如和CloudProvider(IaaS)交互,管理node,pod,replication,service,namespace等。基本机制是监听etcd /registry/events下对应的事件,进行处理。具体的逻辑需要专门文章分析,此处不进行详解。
节点上的agent,主要有两个组件:
kubelet 主要包含容器管理,镜像管理,Volume管理等。同时kubelet也是一个rest服务,和pod相关的命令操作都是通过调用接口实现的。比如:查看pod日志,在pod上执行命令等。pod的启动以及销毁操作依然是通过监听etcd的变更进行操作的。但kubelet不直接和etcd交互,而是通过apiserver提供的watch机制,应该是出于安全的考虑。kubelet提供插件机制,用于支持Volume和Network的扩展。
kube-proxy 主要用于实现Kubernetes的service机制。提供一部分SDN功能以及集群内部的智能LoadBalancer。前面我们也分析了,应用实例在多个服务器节点之间迁移的一个难题是网络和端口冲突问题。Kubernetes为每个service分配一个clusterIP(虚拟ip)。不同的service用不同的ip,所以端口也不会冲突。Kubernetes的虚拟ip是通过iptables机制实现的。每个service定义的端口,kube-proxy都会监听一个随机端口对应,然后通过iptables nat规则做转发。比如Kubernetes上有个dns服务,clusterIP:10.254.0.10,端口:53。应用对10.254.0.10:53的请求会被转发到该node的kube-proxy监听的随机端口上,然后再转发给对应的pod。如果该服务的pod不在当前node上,会先在kube-proxy之间进行转发。当前版本的kube-proxy是通过tcp代理实现的,性能损失比较大(具体参看后面的压测比较),1.2版本中已经计划将kube-proxy完全通过iptables实现(https://github.com/kubernetes/kubernetes/issues/3760)
Pods Kubernetes将应用的具体实例抽象为pod。每个pod首先会启动一个google_containers/pause docker容器,然后再启动应用真正的docker容器。这样做的目的是为了可以将多个docker容器封装到一个pod中,共享网络地址。
Replication Controller 控制pod的副本数量,高可用就靠它了。
Services service是对一组pods的抽象,通过kube-proxy的智能LoadBalancer机制,pods的销毁迁移不会影响services的功能以及上层的调用方。Kubernetes对service的抽象可以将底层服务和上层服务的依赖关系解耦,同时实现了和Docker links类似的环境变量注入机制(https://github.com/kubernetes/kubernetes/blob/release-1.0/docs/user-guide/services.md#environment-variables),但更灵活。如果配合dns的短域名解析机制,最终可实现完全解耦。
Label key-value格式的标签,主要用于筛选,比如service和后端的pod是通过label进行筛选的,是弱关联的。
Namespace Kubernetes中的namespace主要用来避免pod,service的名称冲突。同一个namespace内的pod,service的名称必须是唯一的。
Kubectl Kubernetes的命令行工具,主要是通过调用apiserver来实现管理。
Kube-dns dns是Kubernetes之上的应用,通过设置Pod的dns searchDomain(由kubelet启动pod时进行操作),可以实现同一个namespace中的service直接通过名称解析(这样带来的好处是开发测试正式环境可以共用同一套配置)。主要包含以下组件,这几个组件是打包到同一个pod中的。
etcd skydns依赖,用于存储dns数据
skydns 开源的dns服务
kube2sky 通过apiserver的接口监听kube内部变更,然后调用skydns的接口操作dns
Networking Kubernetes的理念里,pod之间是可以直接通讯的(http://kubernetes.io/v1.1/docs/admin/networking.html),但实际上并没有内置解决方案,需要用户自己选择解决方案: Flannel,OpenVSwitch,Weave 等。我们测试用的是Flannel,比较简单。
配置文件 Kubernetes 支持yaml和json格式的配置文件,主要用来定义pod,replication controller,service,namespace等。
Kubernates 可能带来的改变
降低分布式应用开发运维的复杂度 纵观当前的各种分布式架构,hadoop,storm等,都是master-workers模式,框架很大一部分功能在节点的管理,处理程序的调度上,如果基于Kubernetes来实现类似功能,这些基本都可以交给Kubernetes完成,框架只需要负责核心数据的流转以及收集逻辑。当然,当前Kubernetes的pod还未像Borg一样直接支持batch job,但按照Kubernetes和Borg的关系,将来应该会支持(http://blog.kubernetes.io/2015/04/borg-predecessor-to-kubernetes.html)。
更完备的CI/CD(持续集成/持续交付)工具 CI是code-deploy的关键工具,但当前由于受限于部署环境的不一致,CI可做的事情有限,大多数还依赖用户的自定义脚本。有了Kubernetes这样的标准环境后,以后此类工具可以覆盖测试环境部署,集成测试,上线部署等环节,实现标准化的交付工作流。
Kubernetes之上的分布式存储 Kubernetes官方提供了一个在Kubernetes上部署cassandra的例子,只需要重写一个基于Kubernetes apiserver的SeedProvider,就可以避免静态配置seed ip,享受Kubernetes带来的scale-out能力。再如前面我们提到的memcached的高可用例子,如果基于Kubernetes实现一个memcached的smart client,只需要改下客户端即可,非常简单。个人认为以后在Kubernetes上的支持多租户的分布式存储会更加流行。只要解决了存储服务的scale-out问题,应用的scale-out一般不会有太大问题。Hypernetes就是一个实现了多租户的Kubernetes版本。
企业应用的分发 当前SaaS(on-demand)比较流行的一个很大的原因是原来的on-premise应用的部署运维成本太高,如果Kubernetes等分布式操作系统得到广泛应用,on-premise的成本降低,on-premise以及托管云模式对SaaS的格局也会带来影响。这也是我们这样的创业公司关注Kubernetes的原因之一。
对IaaS的影响 当前的IaaS平台的组件逐渐有闭源的趋势,比如AWS尝试用Aurora替代Mysql,阿里云用KVStore替换Redis。用户主要关心的是服务的可靠性,自己运维的时候可能会倾向于开源方案,但如果使用云厂商的服务,就不太关心。按照这样的趋势,随着IaaS的普及,会对整个开源的生态产生影响。但有了Kubernetes这样的平台,IaaS厂商主要为Kubernetes提供运行的基础环境,Kubernetes接管上面的应用和服务,这样在IaaS厂商之间迁移也很容易。
微服务 微服务最近很热,但这个概念其实不新。主要一直受限于运维的复杂度,没有普及。如果运维系统跟不上,服务拆太细,很容易出现某个服务器的角落里部署着一个很古老的不常更新的服务,后来大家竟然忘记了,最后服务器迁移的时候给丢了,用户投诉才发现。而随着Docker以及Kubernetes这样的工具和平台逐渐成熟,微服务的时代也到来了。 在Kubernetes上的微服务治理框架可以一揽子解决微服务的rpc,监控,容灾问题,个人觉得可以期待。