X3D: Expanding Architectures for Efficient Video Recognition 论文学习
Abstract
本文提出的 X3D 是一组高效率的视频网络,沿着网络的空间、时间、宽度和深度维度来对较小的2D图像分类结构进行扩展。受到机器学习中特征选择方法的启发,本文使用了一个简单的、逐步的网络扩展方法,每一步中只扩展单个维度,这样就可以实现准确度与复杂度的平衡。为了将X3D的复杂度扩展至一个目标程度,在前向扩展操作之后会跟着一个反向的收缩操作。X3D实现了state of the art的性能,而计算量比以前的方法少了 4.8 × 4.8\times 4.8×,参数量少了 5.5 × 5.5\times 5.5×。本文最惊人的发现就是,使用高时空分辨率的网络也能效果很好,而其网络的宽度和参数量都极其轻量。在视频分类和检测基准上,X3D都取得了最佳的准确率。代码位于:https://github.com/facebookresearch/SlowFast。
1. Introduction
将2D图像的网络结构扩展至时空域,大幅度地推动了视频分类的网络结构。这些扩展通常发生在时间维度上,比如将网络的输入、特征、卷积核扩展至时空维度。但是其它的设计选项—如深度(层的个数)、宽度(通道个数)以及空间大小都沿用了2D图像的网络结构。尽管沿着时间维度来扩展(保留其它的设计属性),通常可以提升准确率,但是考虑到计算量/准确率之间的关系,这就不是最优的了。
直接将2D模型扩展至3D,视频识别的网络结构的计算量很重。与图像识别相比,视频模型通常会消耗更多的计算量,如图像ResNet的计算量要比一个在时间维度上延展出来的视频模型少 27 × 27\times 27×倍。
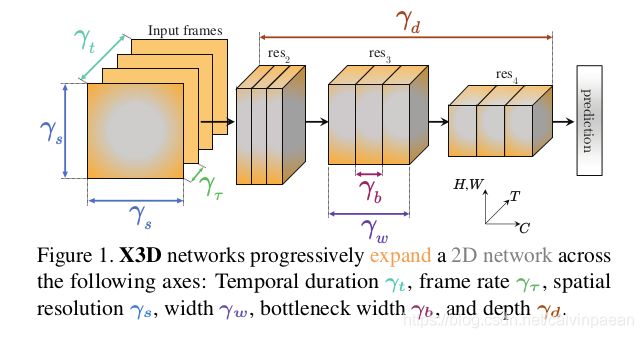
本文关注于计算量较低的方法上,针对视频识别实现计算量/准确率的平衡。作者基于图像识别中的移动端模型来设计本文方法。本文的核心思想是,尽管沿着时间维度来扩展小模型可以提升准确率,但是与扩展其它维度相比,其计算量/准确率的平衡并不一定是最佳的,尤其是在较低计算量的方法中,其它维度上的准确率可能提升地更快。
如图1所示,本文中作者通过增加多个可能的维度,逐步地将一个小型的2D网络结构扩展至时空域。候选的维度包括时长 γ t \gamma_t γt、帧率 γ τ \gamma_\tau γτ、空间分辨率 γ s \gamma_s γs、网络宽度 γ ω \gamma_\omega γω、bottleneck宽度 γ b \gamma_b γb、深度 γ d \gamma_d γd。该网络结构称作X3D(Expand 3D),从2D空间扩展至3D时空域。
2D基线模型受到 MobileNet 的核心概念(通道可分离卷积)启发,但是要小许多,它的计算量要比移动端图像模型少10倍。然后扩展操作会逐步地增加计算量(每次扩展一个维度),随后训练及验证得到的模型结构,最后选择能实现最佳计算量/准确率的维度。该过程会不断地重复,直到我们达到了理想的计算量目标。我们可以理解为是 coordinate descent 的一种形式,这些维度就定义了超参数空间。
本文递进的网络扩展方式受到了卷积网络的设计和机器学习中特征选取方式的启发,流行的网络结构都会在深度、分辨率或宽度维度上进行扩展。递进的特征选取方法在一开始时,会有一个数量极少的特征组成的集合,然后通过greedy算法找到那些相关的、能大幅度提升表现的特征;或者一开始时,会有一个完备的特征集合,然后重复地删除那些对性能损害最小的特征,找到那些不相关的特征。
为了和之前的研究相比较,作者使用了Kinetics-400、Kinetics-600、Charades、AVA数据集。为了系统性地研究,作者将其模型分为不同的复杂度层级—小型、中型、大型的模型。
总之,利用该扩展操作,作者构建了一组时空网络结构,涵盖了大范围的计算量/准确率 trade-offs。在实际应用中,它们可以根据不同的计算量预算来使用。例如,在不同的计算量和准确率设定下,X3D的表现与目前state of the art的模型相似,而所需的计算量和参数量少了 4.8 × 4.8\times 4.8×和 5.5 × 5.5\times 5.5×。此外,扩展操作简单且成本低,例如,只训练30个小模型后,我们的低计算量模型就完成了,而这30个小模型所需的计算量要比训练一个大模型所需的少 25 × 25\times 25×倍。
本文最惊人的发现就是,通过扩展时空分辨率而得到的很窄的视频网络结构,其效果也很好,而网络的宽度和参数量要小许多。X3D网络的宽度要比其它网络小许多,这样X3D就和高分辨率的Fast Pathway相似。
2. Related Work
时空(3D)网络。对图像分类网络进行扩展,加入时间维度,并保留其空间属性,人们就设计出了视频识别模型。这些扩展包括直接的2D模型变换,如将ResNet或Inception改为3D,在2D CNNs之上增加RNNs,或者通过光流 stream 来扩展2D模型。它一开始是一个2D图像模型,然后通过滤波器改造,将之转换为时空域的模型,这允许我们在图像分类任务上进行预训练,但是该视频网络结构内在地就会偏向基于图像的那部分。
SlowFast 网络在Slow和Fast pathway 的多个维度上,以及不同的时间、空间和通道分辨率上探索了分辨率的 trade-offs。有趣的是,Fast pathway 可以非常地窄,因此所需的计算量比较少。但是,运算起来较慢。而且,它需要和计算量沉重的Slow pathway结构一起运算。本文研究了我们是否需要Slow pathway,以及一个轻量级网络能否有竞争力的问题。
高效2D网络。在图像分类任务上,人们大量研究了计算高效率的网络结构,如MobileNetV1&V2和ShuffleNet,研究了通道可分离卷积和扩展bottlenecks。人们也提出了神经结构搜索方法,在设计空间中加入了SE注意力模块,和最近的MobileNetV3 Swish非线性激活函数。MobileNets 通过一个宽度和分辨率乘数来变大和变小。最近,MnasNet 对空间、宽度和深度维度分别使用线性缩放因子,得到一组EfficientNets用于图像分类。
本文的扩展方法与之相关,但是所需的样本数更少,它可以处理更多的维度,因为在每一步,对于每个维度,我们只训练一个模型。对原始设定采用网格搜索法,我们就需要训练 k d k^d kd个模型,其中 k k k是网格的个数, d d d是维度的个数。为了得到MnasNet,所需搜索的模型数会有约8000个。对于视频而言,这就无法做到了,因为相较于图像分类所需的图像数量而言,它是指数倍的,比如Kinetics 有 ≈ 195 M \approx 195M ≈195M帧,比ImageNet的图像数量多 162.5 × 162.5\times 162.5×倍。相反,本文方法只需训练6个模型,每个维度扩展都对应一个模型,直到我们达到最终的复杂度。假设我们有5步,它就需要训练30个模型。
高效率3D网络。针对高效率视频分类课题,人们提出了多个创新的网络结构。通道可分离卷积是高效率2D卷积网络的核心构建模块,在视频分类任务上人们也进行了尝试,将2D结构扩展为3D结构,比如在 ShuffleNet、MobileNet 或 ResNet 中残差阶段的bottleneck中使用 3 × 3 × 3 3\times 3\times 3 3×3×3的通道可分离卷积。更早一点,[10] 采用 2D ResNets 和 MobileNets,将每个残差模块内的连接进行稀疏化,与可分离卷积或分组卷积相似。[51]中提出了时间转移模块(TSM),扩展了ResNets,利用内存转移操作来获取时间信息。在自适应的帧采样技巧方面,人们也有大量的研究,可作为本文的补充。
本文方法没有采用从2D网络继承而来的设计,但在多个维度上(空间、时间、通道和深度)对小型网络结构进行扩展,实现不错的效率 trade-off。
3. X3D网络
图像分类网络经历了结构设计上的演化,沿着网络的深度、输入分辨率或通道宽度不断地扩展现有的模型。在移动端图像分类领域,我们也可以看到相似的进展,对网络做收缩改造(网络更浅、分辨率更低、层更窄、可分离卷积)使得计算量很低。在视频网络结构上,我们并没有发现相似的演进,因为它们都是对图像模型进行直接的时间域扩展但是,单纯地将2D结构扩展为3D真的理想吗?沿着不同的维度来扩展或收缩是否更好呢?
对于视频分类,时间维度带来了一个新的问题,增加可能性的数量,但是所需的处理方式与空间维度的处理方式不同。作者特别关心不同维度之间的 trade-offs:
- 对于3D网络最佳的时间采样策略是什么?相较于较短的视频片段的快速采样,长时长的输入和稀疏采样策略是否更好?
- 我们是否需要更高的空间分辨率?之前的视频分类工作都采用较低的分辨率,提升效率。同样,视频通常要比网络图像的分辨率更粗糙,那么是否会存在一个空间分辨率,使得网络的表现会饱和呢?
- 高帧率而通道分辨率较低的网络是否更好?或者用一个较宽的模型来慢慢处理视频?比如,网络内的层是否应该更重,与图像分类模型(Slow pathway)相似,或更轻量、宽度较窄,与Fast pathway相似?
- 当我们增加网络宽度时,全局地增加ResNet模块中的宽度更好,还是增大内部 "bottleneck"的宽度更好?这与使用了通道可分离卷积的移动端图像分类网络相似。
- 加大输入分辨率的同时,是否应该网络更深一些?以此来保证网络的感受野足够大,而且它的growth rate 几乎是常量,在不同的维度进行扩展是否更好?这在空间和时间维度上是否都成立?
这一部分,在3.1节首先介绍了基本的X2D结构,在3.2节定义了扩展操作,3.3节介绍了渐进的网络的扩展。

3.1 基本结构
作者首先介绍了基本的网络结构 X2D,作为基线模型,可以扩展入时空维度。该实例化延续了 ResNet 结构以及单帧时间输入时 SlowFast模型中的 Fast pathway 设计。表1中详细介绍了X2D 的结构,如果所有的扩展因子 { γ τ , γ t , γ s , γ ω , γ b , γ d } \{\gamma_\tau, \gamma_t, \gamma_s, \gamma_\omega, \gamma_b, \gamma_d\} {γτ,γt,γs,γω,γb,γd}都设为1。
作者将时空大小表示为 T × S 2 T\times S^2 T×S2,其中 T T T是时间长度, S S S是一个正方形空间裁剪区域的宽度和高度。X2D的结构如下所述。
网络分辨率和通道表示能力。模型的输入是一个视频片段,在数据层中的采样帧率是 1 / γ τ 1/\gamma_\tau 1/γτ。基本网络结构的输入只有1帧,大小是 T × S 2 = 1 × 11 2 2 T\times S^2 = 1\times 112^2 T×S2=1×1122作为输入,因此它可看作为图像分类网络。每层的宽度都以 Fast pathway 设计为指导,第一个 stage, c o n v 1 conv_1 conv1 对RGB输入通道进行滤波操作,输出24个通道。从 r e s 2 res_2 res2到 r e s 5 res_5 res5,经过每次步长是 1 , 2 2 1, 2^2 1,22的空间下采样后,宽度都会乘以2。在每个stage的第一个残差模块中,都会用 bottleneck 中的滤波器进行空间下采样。
与SlowFast pathway相似,该模型在各特征层级中保留了所有特征的时间输入分辨率。在整个网络中,直到分类层之前的全局池化层,都没有用到时间下采样层(时间池化或time-strided conv)。因此,激活张量包含了时间维度上的所有帧,保留了所有特征中的时间频率信息。
网络阶段 X2D 由一个 stage-level 和 bottleneck 设计组成,受2D移动端图像分类网络启发,它使用了通道可分离卷积,是高效率卷积网络的核心构建模块。作者借鉴了 MobileNet 的设计,将bottleneck 模块中的空间 3 × 3 3\times 3 3×3卷积扩展为 3 × 3 × 3 3\times 3\times 3 3×3×3时空卷积。此外,在第一个 c o n v 1 conv_1 conv1中的 3 × 1 3\times 1 3×1 时间卷积是 channel-wise的。
讨论。X2D 可以理解为一个 Slow pathway,因为它每次只将单帧作为输入,而网络宽度与 Fast pathway 相似,这和传统的3D卷积网络相比更加轻量。它只需要 20.67M FLOPS,是目前 SlowFast 的 0.0097 % 0.0097\% 0.0097%。
如表1和图1所示,X2D 在 6 个维度上进行了扩展, { γ τ , γ t , γ s , γ ω , γ b , γ d } \{\gamma_\tau, \gamma_t, \gamma_s, \gamma_\omega, \gamma_b, \gamma_d\} {γτ,γt,γs,γω,γb,γd}。
3.2 扩展操作
作者定义了一组基本的扩展操作,逐步地将X2D从一个小型空间网络扩展为X3D,通过以下在时间、空间、宽度和深度维度上的操作。
- 通过提高帧率 1 / γ τ 1/\gamma_\tau 1/γτ,X-Fast 扩展了时间激活大小, γ t \gamma_t γt,因此也就提高了时间分辨率,而视频时长不变。
- 通过采样一个较长的视频片段,X-Temporal 扩展了时间长短, γ t \gamma_t γt,增加帧率 1 / γ τ 1/\gamma_\tau 1/γτ,扩展视频的时长和时间分辨率。
- 通过提高输入视频的空间采样分辨率,X-Spatial 扩展了空间分辨率, γ s \gamma_s γs。
- 通过增加每个残差 stage 中的层数 γ d \gamma_d γd倍,X-Depth 扩展了网络的深度。
- X-Width 通过一个全局宽度扩展系数 γ ω \gamma_\omega γω 来扩展所有层的通道数。
- X-Bottleneck 在每个残差模块中,扩展其内部卷积滤波器的通道宽度 γ b \gamma_b γb。
3.3 渐进的网络扩展
作者采用一个简单的、渐进的算法来进行网络扩张,与特征选取的前向和反向算法相似。一开始,作者将X2D作为基础的模型实例,其扩张系数集合 χ 0 \chi_0 χ0的势为 a a a。本文中 a = 6 a=6 a=6, χ = { γ τ , γ t , γ s , γ w , γ b , γ d } \chi=\{\gamma_\tau, \gamma_t, \gamma_s, \gamma_w, \gamma_b, \gamma_d\} χ={γτ,γt,γs,γw,γb,γd}。
前向扩张。作者将网络扩张的评价函数表示为 J ( χ ) J(\chi) J(χ),它可以衡量当前扩张系数 χ \chi χ的好坏。分数越高,表示扩张系数越好,分数越低,则表示扩张系数不好。在实验中,它对应着用 χ \chi χ扩张的模型的准确率。此外,以 C ( χ ) C(\chi) C(χ)作为复杂度评价函数,衡量当前扩张系数 X \Chi X的成本。在实验中, C C C是 χ \chi χ扩展出的网络实例的浮点计算操作个数,而其他的指标如运行时、参数量、内存也是可以的。然后,网络扩展操作试图找到最佳 trade-off 的扩展系数 χ \chi χ, χ = arg max Z , C ( Z ) = c = J ( Z ) \chi = \argmax_{Z,C(Z)=c} = J(Z) χ=Z,C(Z)=cargmax=J(Z),其中 Z Z Z是可能的扩张系数,有待研究, c c c是目标复杂度。在本文中,作者所进行的扩张,只会改变 a a a个扩张系数中的一个,而其它的保持不变。因此我们一共有 a a a个不同的 Z Z Z的子集去评价,它们中的每一个只会改变 χ \chi χ中的一个维度。能得到最佳计算量/准确率平衡的扩张系数会留作下一次的优化。这是超参数空间 coordinate descent 的一种形式,该超参空间由这些维度定义而来。
该扩张是以一个渐进的方式进行的,扩张率是 c ^ \hat c c^,对应着模型复杂度 c c c在扩张步骤中所增加的大小。作者使用了 c ^ ≈ 2 \hat c \approx 2 c^≈2的乘数增加,在每一步中增加模型复杂度,对应着模型帧数的增加一倍。该逐步扩张的方式因此很简单,且高效,因为它只需要训练少量的模型,就可达到目标复杂度。
反向收缩。由于前向扩张只在离散的步骤中产生模型,作者进行了反向收缩来满足目标复杂度,如果前向扩张步骤超过了目标复杂度。该收缩操作的实现很简单,就是对最后一个扩张操作进行降低操作,来满足目标复杂度。例如,如果最后一步将帧率增加了一倍,反向收缩就会用 < 2 <2 <2的系数来降低帧率,从而满足目标复杂度。
4. Experiments
Pls read paper for more details.