BigData-25:Spark基础
Spark生态圈:
Spark Core: 最重要,其中最重要的就是RDD(弹性分布式数据集)
Spark SQL
Spark Streaming
Spark MLLib: 协同过滤、ALS、逻辑回归等等 —> 实现推荐系统
Spark Graphx:图计算
Spark Core
一、什么是Spark?特点?
官网:Apache Spark™ is a unified analytics engine for large-scale data processing.
类似MapReduce
特点:快、易用、通用、兼容
为什么要学习Spark?基于内存,回顾Mapreduce 2.x的Shuffle
二、安装和部署Spark、Spark的HA
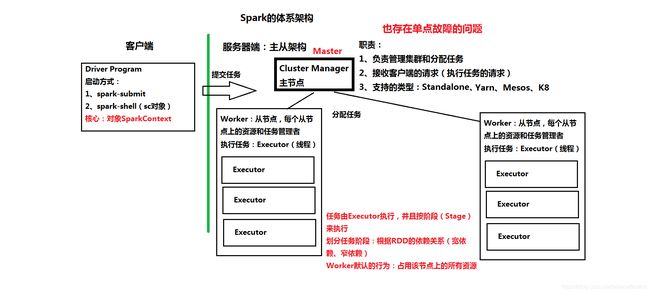
1、Spark的体系架构:主从架构
http://spark.apache.org/docs/latest/cluster-overview.html
2、安装和配置Spark:以Standalone模式为例
注意:Hadoop和Spark的命令脚本有冲突
核心配置文件:conf/spark-env.sh
(1)准备工作:安装JDK、配置主机名和免密码登录
(2)伪分布模式:bigdata111
在一台虚拟机上,模拟一个分布式的环境(Master+Worker)
conf/spark-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
export SPARK_MASTER_HOST=bigdata111
export SPARK_MASTER_PORT=7077
conf/slave 配置从节点
bigdata111
启动Spark集群: sbin/start-all.sh
Web Console:http://ip:8080
(3)全分布模式:三台机器
bigdata112(Master) bigdata113(Worker) bigdata114(Worker)
conf/spark-env.sh
export JAVA_HOME=/root/training/jdk1.8.0_144
export SPARK_MASTER_HOST=bigdata112
export SPARK_MASTER_PORT=7077
conf/slave 配置从节点
bigdata111
把安装包复制到从节点上
scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata113:/root/training
scp -r spark-2.1.0-bin-hadoop2.7/ root@bigdata114:/root/training
在主节点上,启动Spark集群: sbin/start-all.sh
Web Console:http://ip:8080
3、Spark HA有两种方式:
回顾一下HA:
()HDFS、Yarn、HBase、Storm、Spark 主从结构
()单点故障的问题
(*)解决方案:HA(High Availability)
(1)基于文件目录的单点恢复
(*)本质:还是只有一个主节点Master
恢复目录 —> 保存的是集群的状态和任务的信息
重新启动Master,会从恢复目录下读取状态信息
主要用于开发或测试环境
配置
mkdir /root/training/spark-2.1.0-bin-hadoop2.7/recovery
文件spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/root/training/spark-2.1.0-bin-hadoop2.7/recovery"
测试:执行一个Application:启动spark-shell命令行工具(作为一个独立的Application运行在Spark集群中)
(2)基于ZooKeeper的Standby的Master
()复习ZooKeeper:(bigdata112、bigdata113、bigdata114)
()相当于是一个”数据库“
(*)数据同步、选举功能、分布式锁功能(秒杀)
配置spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata112:2181,bigdata113:2181,bigdata114:2181 -Dspark.deploy.zookeeper.dir=/spark"
三、执行Spark的任务:两个工具
1、spark-submit:用于提交Spark的任务(就是一个jar包)
举例:examples/jars/spark-examples_2.11-2.1.0.jar
应用:蒙特卡罗求PI(圆周率)
命令:
bin/spark-submit --master spark://bigdata111:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 100
结果 Pi is roughly 3.1413835141383513
2、spark-shell: 相当于REPL,命令行工具;作为一个独立的Application运行
两种运行模式
(1)本地模式:不需要链接到Spark集群上,在本地(Eclipse)直接运行;用于开发和测试
命令:bin/spark-shell
日志:Spark context available as ‘sc’ (master = local[*], app id = local-1540472971277)
(2)集群模式:需要链接到Spark集群上
命令: bin/spark-shell --master spark://bigdata111:7077
日志:Spark context available as ‘sc’ (master = spark://bigdata111:7077, app id = app-20181025211312-0001).
在spark-shell中开发程序 WordCount
(*) 处理本地文件 直接打印结果
sc.textFile("/root/temp/input/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
(*) 处理HDFS的文件:输出到HDFS
sc.textFile("hdfs://bigdata111:9000/input/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://bigdata111:9000/output/1025")
(*) 单步运行WordCount ----> 知识点:RDD
val rdd1 = sc.textFile("/root/temp/input/data.txt")
val rdd2 = rdd1.flatMap(_.split(" "))
val rdd3 = rdd2.map((_,1)) 完整: val rdd3 = rdd2.map((word:String)=>(word,1) )
val rdd4 = rdd3.reduceByKey(_+_) 完整
val rdd4 = rdd3.reduceByKey((a:Int,b:Int)=> a+b)
rdd4.collect
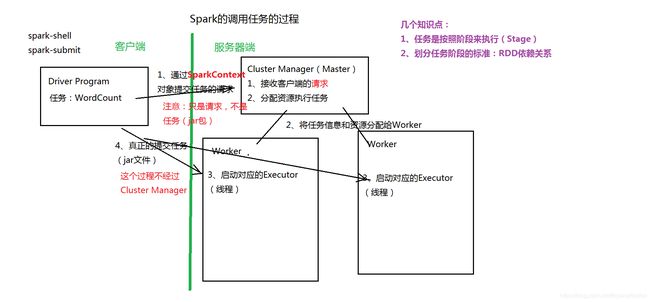
四、分析Spark的任务流程
1、分析WordCount数据处理过程
2、Spark的调用任务的过程

五、RDD和RDD的特性、RDD的算子(函数、方法)
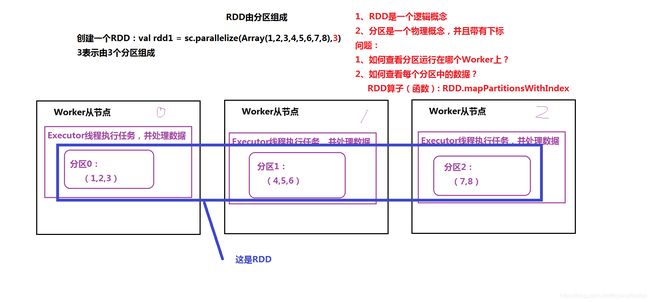
1、RDD:弹性分布式数据集 Resilent distributed dataset
()Spark中最基本的数据抽象
()结合源码查看什么是RDD?
五个特性
-
Internally, each RDD is characterized by five main properties:
-
A list of partitions
是一组分区,由分区组成,每个分区运行在不同的worker上 -
- A function for computing each split
函数(算子),用于处理计算每个分区中的数据
(1)Transformation:延时计算,不会触发计算
(2)Action:立即执行计算,举例:打印结果、保存为文件,等等
- A function for computing each split
-
- A list of dependencies on other RDDs
RDD之间存在依赖的关系:(1)窄依赖 (2)宽依赖
根据依赖的关系,来划分任务的Stage(阶段)
- A list of dependencies on other RDDs
可选:
-
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
自定义分区规则来创建RDD,类似MapReduce中的分区
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
-
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
(*)如何创建RDD?
(1)通过SparkContext.parallelize创建
val rdd1 = sc.parallelize(Array(1,2,3,4,5,6,7,8),3)
(2)通过读取外部的数据源创建:比如:HDFS、本地目录
val rdd1 = sc.textFile("hdfs://bigdata111:9000/input/data.txt")
val rdd2 = sc.textFile("/root/temp/data.txt")
2、算子(函数)
(1)Transformation:会延时加载(计算)
map(func)
对原来的RDD进行某种操作,返回一个新的RDD
filter(func):过滤
flatMap(func):压平,类似Map
mapPartitions(func):对RDD中的每个分区进行操作
mapPartitionsWithIndex(func):对RDD中的每个分区进行操作,还带有小标
sample(withReplacement, fraction, seed)
集合运算
union(otherDataset)
intersection(otherDataset)
distinct([numTasks])) 去重
聚合操作:(分组)
groupByKey([numTasks])
reduceByKey(func, [numTasks])
aggregateByKey(zeroValue)(seqOp,combOp,[numTasks])
排序
sortByKey([ascending], [numTasks]) 针对的是
sortBy(func,[ascending], [numTasks])
join(otherDataset, [numTasks])
cogroup(otherDataset, [numTasks])
cartesian(otherDataset) 笛卡尔积
pipe(command, [envVars])
重分区
coalesce(numPartitions)
repartition(numPartitions)
repartitionAndSortWithinPartitions(partitioner)
(2)Action:触发计算
reduce(func)
collect()
count()
first()
take(n)
takeSample(withReplacement,num, [seed])
takeOrdered(n, [ordering])
saveAsTextFile(path)
saveAsSequenceFile(path)
saveAsObjectFile(path)
countByKey()
foreach(func): 类似map,区别是:没有返回值
3、特性:
(1)RDD的缓存机制:默认将RDD的数据缓存在内存中
()作用:提高性能
()需要标识RDD可以被缓存:函数:persist或者cache
查看源码:
storage level标识缓存的位置,默认是内存
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
(*)可以缓存的位置:由StorageLevel来定义
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
(*)举例:
测试的数据:Oracle数据库中的订单数据:大概有92万条数据
读入数据: var rdd1 = sc.textFile("hdfs://bigdata111:9000/input/sales")
计算:统计订单文件中有多少条订单数据?
rdd1.count ---> Action操作,这一次没有缓存
rdd1.cache ---> 标识这个RDD可以被缓存,但是不会触发计算,cache是一个Transformation
rdd1.count ----> Action操作,把结果进行缓存
rdd1.count ----> 问题:数据从哪里得到? 从缓存中读取数据
通过Web Console观察三次count操作的执行时间
(2)RDD的容错机制:通过的检查点(Checkpoint)来实现
()复习检查点:HDFS中,由SecondaryNameNode来进行日志的合并
Oracle中,会以最高的优先级唤醒数据库的写进程(DBWn),把内存中的脏数据写到文件
()RDD的检查点:是一种容错机制
概念:Lineage(血统)—> 表示任务执行的生命周期(整个任务的执行过程)
如果血统越长,越容易出错
基于内存
(*)RDD的类型有两种类型
通过SparkContext.setCheckpointDir(目录)
1、本地目录:需要将spark-shell或者任务运行在本地模式上(setMaster(“local”))
用于开发和测试
sc.setCheckpointDir("/root/tem/spark")
2、HDFS的目录:需要将spark-shell或者任务运行在集群模式上
用于生产
(*)举例
scala> sc.setCheckpointDir("hdfs://bigdata111:9000/sparkckpt")
设置检查点目录
scala> var rdd1 = sc.textFile("hdfs://bigdata111:9000/input/sales")
rdd1: org.apache.spark.rdd.RDD[String] = hdfs://bigdata111:9000/input/sales MapPartitionsRDD[39] at textFile at :24
scala> rdd1.checkpoint ----> 查看一下源码
标识RDD可以执行检查点
/**
* Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint
* directory set with `SparkContext#setCheckpointDir` and all references to its parent
* RDDs will be removed. This function must be called before any job has been
* executed on this RDD. It is strongly recommended that this RDD is persisted in
* memory, otherwise saving it on a file will require recomputation.
*/
scala> rdd1.count
res16: Long = 918843
(3)依赖关系:宽依赖、窄依赖
可以划分任务执行的Stage(阶段)
(*)回顾WordCount程序:
val rdd1 = sc.textFile("/root/temp/input/data.txt")
val rdd2 = rdd1.flatMap(_.split(" "))
val rdd3 = rdd2.map((_,1)) 完整: val rdd3 = rdd2.map((word:String)=>(word,1) )
val rdd4 = rdd3.reduceByKey(_+_)
rdd4.collect
(*)宽依赖:类似“超生”
多个子RDD的分区依赖了同一个父RDD的分区
(*)窄依赖:类似“独生子女”
每一个父RDD的分区,最多被一个RDD的分区使用
参考讲义