虚拟机总结(大数据技术原理与应用概念、存储、处理、分析与应用(第2版))
第一章 大数据概论

2.信息科技为大数据时代提供技术支持:
①存储(存储设备容量不断增加)
②计算(CPU处理能力大幅提升)
③网络(网络带宽不断增加)
3.数据产生方式:运营式系统阶段 -> 用户原创内容阶段 -> 感知式系统阶段(物联网)
4.大数据
(1)是数据与大数据技术的综合体;
(2)特性(4V):大量化、快速化、多样化、价值密度低;
(3)由结构化数据和非结构化数据组成;
(4)影响:全样而非样、效率而非精确、相关而非因果;
(5)技术层次:
①数据采集
②数据存储与管理(核心)
③数据处理与分析(核心)
④数据隐私与安全;
(6)大数据关键技术:①分布式存储:解决海量数据的存储问题②分布式处理;
(7)大数据计算模式
| 大数据计算模式 | 解决问题 |
|---|---|
| 批处理计算 | 针对大规模数据的批量处理 |
| 流计算 | 针对流数据的实时计算,实时响应 |
| 图计算 | 针对大规模图结构数据的处理 |
| 查询分析计算 | 大规模数据的存储管理和查询分析 |
5.科学研究的四种范式:实验科学、理论科学、计算科学、数据密集型科学
6.云计算
(1)是通过网络以服务的方式为用户提供非常廉价的IT资源;
(2)解决分布式存储与分布式处理的问题;
(3)典型特征(虚拟化和多租户);
(4)模式(公有云、混合云、私有云);
(5)层次:
①面向网络架构师 -> 基础设施即服务IaaS、
②面向应用开发者 -> 平台即服务PaaS、
③面向用户 -> 软件即服务SaaS
7.物联网
(1)层次架构(感知层、网络层、处理层、应用层);
(2)关键技术:①识别和感知技术(二维码、RFID)②网络与通信技术③数据挖掘与融合技术
8.三者之间的关系

第二章 大数据处理架构Hadoop
(可以断网安装虚拟机默认是国内源,连接网络安装默认是国外源比较慢)
1.用VMware Workstation安装Linux18.04
(1)安装Linux18.04我选择了清理整个磁盘并安装Ubuntu,并没有选择分区(这样做需要把虚拟机安装在一个空文件夹里)不能跳过安装!!!虽然下载慢但是不能跳过,第一次因为跳过安装失败
(2)配置hadoop时那些安装包只需将他们拖入终端就可以有他们的名称不需要手打,或者输入前几个字母用tab补全(之前是手打名称,系统不能识别找不到文件)
(3)JAVA和hadoop都要配置路径加入到path中去,不把hadoop加入路径,输入./sbin/start-dfs.sh是无效的。记住hadoop的路径(直接输入./sbin/start-dfs.sh〈启动namenodes,datanodes,secondary namenodes〉不能找到文件,所以得在hadoop路径里输入)
(4)web界面打不开(终端输入hostname发现是ubuntu,把localhost改成ubuntu输入http://ubuntu:50070还是打不开。最后输入http://ubuntu:9870和http://ubuntu:8088〈这个需要输入./sbin/start-yarn.sh启动resourcemanager〉打开了界面)
(5)为了安装搜狗输入法得先安装fcitx,然后更改系统语言为中文(一直中文包没下载成功,以为是没有联网,打开浏览器却能上网。于是换了国内源,下载成功中文包,换了fcitx安装搜狗输入法成功)
2.用Oracle VM VirtualBox安装Linux16.04
(1)一样没分区(因为分区页面的下半部分一直没办法上拖,按住Alt键也不能拖动,最后就放弃了)
(2)安装系统时间比VMware Workstation慢了很多,语言包比较齐全而且直接可以选择中文界面,不用再去下载中文包,更换国内源
(3)安装系统比较方便,但是一些设置基本找不到,个人还是觉得VMware Workstation比较好用
3.hadoop
(1)两大核心 -> HDFS+MapReduce;
(2)特性:高可靠性、高效率、高可扩展性、成本低、运行在Linux平台、支持多种编程语言;
(3)生态系统:HDFS、HBase、MapReduce、HIVE、Pig、Mahout、Zookeeper、Flume、Sqoop、Ambari
第三章 分布式文件系统HDFS
1.实现目标:
①兼容廉价的硬件设备
②实现流数据读写
③支持大数据集
④支持简单的文件模型
⑤强大的跨平台兼容性
2.局限性:不适合低延迟数据访问、无法高效储存大量小文件、不支持多用户写入及任意修改文件
3.块(HDFS最核心概念)
(1)目的(为了支持面向大规模数据存储,降低分布式节点的寻址开销)
(2)缺点(如果块过大会导致MapReduce只有少量任务在执行,完全牺牲了MapReduce的并行度,发挥不了分布式并行处理的效果)
(3)HDFS采用块的好处(支持大规模文件存储、简化系统设计、适合数据备份)
4.HDFS两大组件
(1)名称节点(整个HDFS集群的管家)
①FsImage(保存系统文件树)
文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块
②EditLog(记录对数据进行的诸如创建、删除、重命名等操作)
③EditLog不断增大,第二名称节点(名称节点的冷备份,对EditLog的处理)定期和名称节点进行通信,停止使用EditLog文件
(2)数据节点(存储实际数据)
存取数据,把它们保存到Linux本地文件里
5.HDFS体系结构局限性
(1)命名空间限制(名称节点是保存在内存中的,因此,名称节点能够容纳的对象〈文件、块〉的个数会受到空间大小限制)
(2)性能的瓶颈(整个分布式文件的吞吐量受限于单个名称节点的吞吐量)
(3)隔离问题(由于集群中只有一个名称节点,只有一个命名空间,因此无法对不同应用程序进行隔离)
(4)集群的可用性(一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用)
6.HDFS存储原理
(1)冗余数据保存的问题
①加快数据传输速度
②很容易检查数据错误
③保证数据可靠性
(2)数据保存策略问题
①数据存放
②数据读取(就近原则)
(3)数据恢复问题
①名称节点出错(通过第二名称节点恢复)
②数据节点出错(数据节点通过远程调用把心脏信息不断发给名称信息,若收不到信息则数据节点发生故障,此时名称节点把它标记为宕机,名称节点把故障数据节点的数据的备份复制一份就可以恢复)
③数据本身出错(计算的校验码与之前的校验码不同则出错)
7.HDFS读数据过程
(1)打开文件(HDFS客户端向DistributedFileSystem)
(2)获取数据块信息(FSDataInputStream向名称节点沟通)
(3)读取请求(名称节点返回数据位置给客户端,HDFS客户端向FSDataInputStream)
(4)读取数据(FSDataInputStream向数据节点)
(5)获取数据块信息(可能发生,FSDataInputStream向名称节点沟通)
(6)读取数据(FSDataInputStream向数据节点)
(7)关闭文件(HDFS客户端向FSDataInputStream)
8.HDFS写数据过程
(1)创建文件请求(HDFS客户端向DistributedFileSystem)
(2)创建文件元数据(FSDataOutputStream向名称节点,名称节点检查是否存在文件是否有权限)
(3)写入数据(HDFS客户端向FSDataOutputStream)
(4)写入数据包(FSDataOutputStream向数据节点)
(5)接收确认数据包(数据节点向FSDataOutputStream)
(6)关闭文件(HDFS客户端向FSDataOutputStream)
(7)写操作完成(FSDataOutputStream向名称节点)
9.运行代码提示hadoop本地库和平台不匹配:重新导入jar包,并导入hadoop-hdfs-client-3.1.1.jar就可以了
第四章 分布式数据库HBase
1.分布式数据库可以用来存储非结构化和半结构化的松散数据
特性:高可靠,高性能,面向列,可伸缩
底层分布式文件系统 -> 存储完全非结构化的数据
HBase -> 允许几千台服务器存储海量文件
2.Hadoop主要解决大规模数据离线批量处理,但是Hadoop没办法满足大数据实时处理需求,随着数据大规模爆炸式增长,传统关系型数据库的扩展能力非常有限。
3.HBase和传统关系数据库的联系与区别
(1)数据类型:传统关系数据库是关系数据模型;
(2)数据操作:关系数据库定了很多数据操作;
(3)存储模式:关系数据库基于行模式存储,HBase基于列存储;
(4)数据索引:关系数据库可以直接针对各个不同的列,构建复杂的索引,HBase只支持对行键的简单索引;
(5)数据维护:关系数据库做更新时,实际上里面的值会被新值覆盖,HBase在这方面不存在覆盖;
(6)可伸缩性:关系数据库很难实现水平扩展,最多实现纵向扩展
4.HBase访问接口
(1)提供一个原生Java API{shell命令、Thrift Gateway方式、REST Gateway}
(2)提供SQL类型接口{Pig、数据仓库产品Hive}
5.HBase是一个稀疏的多维度的排序的映射表。
(1)列限定符(列);
(2)每个值都是未经解释的字符串也就是bytes数组;
(3)一个行可以有一个行键和任意多个列;
(4)列族(支持动态扩展,保留旧版本)
列限定符、行键、列族、时间戳(新版本会通过时间戳来进行区分)
6.数据坐标
(1)HBase对数据定位{采用四维坐标来定位、必须确定行键 列族 列限定符 时间戳、键值数据库}
(2)传统的关系数据库的定位{只要通过一个行一个列这两个维度就可以确定一个唯一得到数据、Excel表格就类似于关系数据库}
7.HBase采用列式存储可以带来很高的数据压缩率(一列的数据类型很相似,适用于分析数据);传统关系数据库采用行式存储不可能达到很高的数据压缩率(一行的数据类型极有可能不同,适用于事务型操作多)
8.功能组件
(1)库函数(一般用于链接每个客户端)
(2)Master服务器(充当管家的作用->分区信息进行维护和管理,维护了一个Region服务器列表,整个集群当中有哪些Region服务器在工作,负责对Region进行分配,负载平衡)
(3)Region服务器(负责存储不同的Region)
9.HBase三层结构
(1)第一层:Zookeeper文件(记录-ROOT-表的位置)
(2)第二层:-ROOT-表(记录.META.表的Region位置信息-ROOT-表只能有一个Region。通过-ROOT-表,就可以访问.META.表中数据)
(3)第三层:.META.表(记录了用户数据表的Region位置信息,.META.表可以有多个Region,保存了HBase中所有用户数据表的Region位置信息)
10.HBase系统架构
(1)客户端(为了加快访问速度->访问HBase的接口)
(2)Zookeeper(实现协同管理服务、提供管家功能<维护和管理整个HBase集群>)
(3)Master(①对表增删改查②负责不同Region服务器的负载均衡③负责调整分裂、合并后Region的分布④负责重新分配故障、失效的Region服务器,也要借助于Master来进行重新分配)
11.性能优化方法
(1)时间靠近的数据都存在一起->时间戳->{按升序排序、越到后面时间戳会越大、长整型变量64位}
(2)用系统最大的整型值减去时间戳->排序就反过来了从而改变了排序的顺序
12.提升读写性能
(1)设置HColumnDescriptor.setlnMemory选项为true
(2)把相关的表放到Region服务器的缓存中,根据需要来决定是否放入缓存
第五章 NoSQL数据库
1.NoSQL数据库特点
灵活的可扩展性、灵活的数据模型、和云计算紧密结合
2.关系数据库
优点:非常完备的关系理论基础、具有事务性机制的支持、高效的查询优化机制、有严格的标准
不足:①无法满足海量数据的管理需求②无法满足高并发的需求③无法满足高可扩展性和高可用性的需求
3.MySQL集群方式的缺陷
①复杂性,整个集群部署管理配置都非常复杂
②延迟性,当主库压力较大时,就会带来较大的延迟
③扩容问题,整个集群压力过大时,需要增加新机器对整个数据集进行重新分区,非常复杂
4.NoSQL兴起原因:①关系型数据库无法满足为web2.0的需求②数据模型局限性③web2.0关系型数据库许多特性没有发挥
5.NoSQL与关系数据库的比较

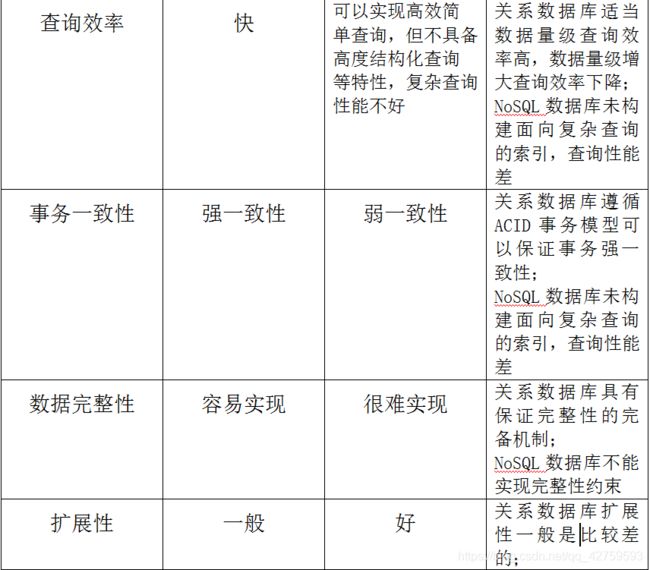

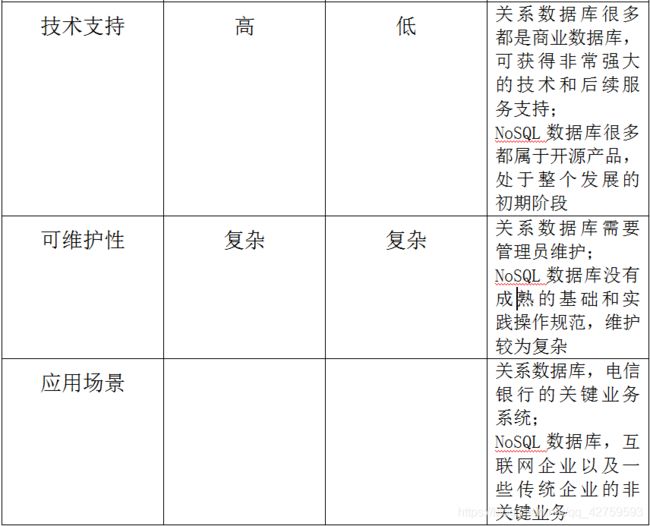
6.NoSQL四大类型
(1)键值数据库
可以成为理想的缓冲层解决方案
| 键值数据库 | 说明 |
|---|---|
| 相关产品 | Redis,Riak,SimpleDB,Chordless,Scalaris,Memcached |
| 数据模型 | 键/值对,键是一个字符串对象,值可以是任意类型的数据,如:整型、字符型、数组、列表、集合等 |
| 典型应用 | 涉及频繁读写,拥有简单数据模型的应用;内容缓存,如:会话、配置文件、参数、购物车等;存储配置和用户数据信息等移动应用 |
| 优点 | 扩展性好,灵活性好,大量写操作性能高 |
| 缺点 | 无法存储结构化信息,条件查询效率较低 |
| 不适用情形 | 没有通过值查询的途径;不能通过两个及以上的键来关联数据;在一些键值数据库中产生故障时不可以回滚 |
(2)列族数据库
| 列族数据库 | 说明 |
|---|---|
| 相关产品 | BigTable,HBase,Cassandra,HadoopDB,GreenPlum,PNUTS |
| 数据模型 | 列族 |
| 典型应用 | 分布式数据存储与管理;数据在地理上分布于多个数据中心的应用程序;可以容忍副本中存在短期不一致情况的应用程序;拥有动态字段的应用程序 |
| 优点 | 查找速度快、可扩展性强、容易进行分布式扩展、复杂性低 |
| 缺点 | 功能较少,大都不支持强事务一致性 |
| 不适用情形 | 需要ACID事务支持的情形Cassandra等产品就不适用 |
(3)文档数据库
特性:能够将它自己的数据的内容和类型进行自我描述
数据结构:JSON数据格式
| 文档数据库 | 说明 |
|---|---|
| 相关产品 | CouchDB,MongoDB,Terrastore,ThruDB,RavenDB,SisoDB,RaptorDB,CloudKit,Perservere,Jackrabbit |
| 数据模型 | 版本化文档,就是一个键值,本质上是一个键值数据库 |
| 典型应用 | 存储、索引并管理面向文档的数据或者类似的半结构化数据 |
| 优点 | 性能好(高并发),灵活性高;提供嵌入式文档功能,将经常查看的数据存储在同一个文档中 |
| 缺点 | 缺乏统一的查询语句 |
| 不适用情形 | 不支持文档间的事务,如果对这方面有需求,则不应该选取这个解决方案 |
(4)图数据库
| 图数据库 | 说明 |
|---|---|
| 相关产品 | Neo4j,OrientDB,InfoGrid,Infinite Graph,GraphDB |
| 数据模型 | 图结构 |
| 典型应用 | 专门用于处理具有高度相互关联关系的数据,比较适合于社交网络、模式识别、依赖分析、推荐系统以及路径寻找等问题 |
| 优点 | 灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱 |
| 缺点 | 数据模型应用范围非常有限 |
7.NoSQL三大理论基石
(1)CAP理论
C:一致性,任何一个读操作总是能够读到之前完成的写操作的结果
A:可用性,快速获取数据,可以在确定的时间内返回操作结果
P:分区容忍性,当出现网络分区的情况时(即系统中的一部分节点无法和其他节点进行通信),分离的系统也能够正常运行
(2)BASE
①基本可用
②软状态
③最终一致性
(3)最终一致性
①因果一致性
②读己之所写一致性
③会话一致性
④单调读一致性
⑤单调写一致性
8.NoSQL->NewSQL(一种架构支持多类应用->多架构支持多类应用)
第六章云数据库
1.云计算概念:通过网络以服务的方式为用户提供非常廉价的IT资源
2.云计算八大优势:
(1)按需服务
(2)随时服务
(3)通用性
(4)高可靠性
(5)极其廉价
(6)超大规模
(7)虚拟化
(8)高可扩展性
3.云数据库特性
(1)动态可扩展
(2)高可用性
(3)较低的使用代价
(4)易用性
(5)高性能
(6)免维护
(7)安全
4.个性化存储需求:大企业海量数据储存需求,中小企业低成本数据存储需求,企业动态变化存储需求
5.云数据库产品
Amazon-> 亚马逊RDS、SimpleDB、DynamoDB、Amazon ElastiCache
谷歌Google -> Google Cloud SQL
微软Microsoft -> Microsoft SQL Azure
6.UMP系统
(1)整个系统保持单一的对外访问入口
(2)消除单点故障,保证服务的高可用性
(3)具有良好的可伸缩,能够动态地增加、减少计算资源
(4)可以实现资源之间的相互隔离
7.UMP系统架构
(1)Mnesia
①是一个分布式数据库管理系统
②支持事务,支持透明的数据分片,利用两阶段锁实现分布式事务,可以线性扩展到至少50个节点③Mnesia的数据库模式(schema)可在运行时动态重配置
(2)RabbitMQ:是一个工业级的消息队列产品
(3)ZooKeeper:高效可靠的协调服务(统一命名服务、状态同步服务、集群管理)
①作为全局的配置服务器
②提供分布式锁(选出一个集群的“总管”)
③监控所有MySQL实例
(5)LVS:即Linux虚拟服务器,是一个虚拟的服务器集群系统
①实现集群内部的负载均衡
②采用IP负载均衡技术和基于内容请求分发技术
③调度器是LVS集群系统的唯一入口④整个服务器集群的结构对客户是透明的
(5)Controller服务器:UMP集群的总管(集群成员的管理、元数据的存储、MySQL实例管理、故障恢复、备份迁移扩容),
为了避免单点故障 -> 设置了多个Controller服务器
|
|
ZooKeeper服务器 -> 确定总管 -> 提供对外服务
(6)Web控制台:向用户提供系统管理界面
(7)Proxy服务器
①向用户提供访问MySQL数据库的服务
②使用MySQL数据库时下载客户端、连接MySQL服务器,
MySQL客户端-> Proxy服务器 ->( 用户的认证信息、后台MySQL实例地址、 资源配额的限制)
(8)Agent服务器:部署在运行MySQL进程的机器上用来管理每台物理机上的MySQL实例
(9)日志分析服务器:对整个日志进行分析
(10)信息统计服务器 -> 系统运营数据->(用户连接数、MySQL实例进程状态、每秒查询数(QPS))
(11)愚公系统
①数据迁移
②系统允许在不停机的情况下,可以实现动态的扩容、缩容、迁移
8.UMP系统功能
(1)容灾
①是云数据库必须具备的基础功能
②为实现容灾UMP系统会为每个用户创建两个MySQL实例(主库、从库)
(2)读写分离
①充分利用主从库实现用户读写操作的分离,实现负载均衡
②SQL语句查询(写操作直接发送到主库;读操作被均衡地发送到主库和从库上执行)
(3)分库分表
①Proxy服务器解析用户SQL语句,提取出重写和分发SQL语句所需要的信息
②对SQL语句进行重写,得到多个针对相应MySQL实例的子语句,分发到对应的MySQL实例上执行
③接受来自各个MySQL实例的SQL语句执行结果合并得到最终结果
(4)资源管理
(5)资源调度
①小规模用户:多个用户共享一个MySQL实例
②中等用户:每个用户独占一个MySQL实例
③分库分表用户:占有多个独立MySQL实例
(6)资源隔离
(7)数据安全
①SSL数据库连接
②提供数据访问IP白名单
③记录用户操作日志
④SQL拦截
9.Amazon AWS上的云数据库服务
(1)关系数据库服务RDS
(2)键值数据库SimpleDB
(3)NoSQL 数据库DynamoDB
(4)数据仓库Redshift
(5)分布式内存缓存ElastiCache
10.微软云数据库SQL Azure
(1)SQL Server实例
(2)全局分区管理器:维护分区映射表信息
(3)协议网关:负责将用户的数据库连接请求转发到相应的主分区上
(4)分布式基础部件
第七章MapReduce
1.MapReduce是一种分布式并行编程框架
2.适合用MapReduce来处理的数据集需要满足的一个前提条件:待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理
3.Map和Reduce

4.MapReduce的策略
(1)MapReduce采用分而治之
(2)把非常庞大的数据集,切分成非常多的独立的小分片
(3)为每个分片单独地启动一个map任务
(4)最终通过多个map任务,并行地在多个机器上去处理
5.MapReduce的理念
(1)计算向数据靠拢而不是数据向计算靠拢
(2)要完成一次数据分析时,选择一个计算节点,把运行数据分析的程序放到计算节点上运行
(3)然后把它所涉及的数据,全部从各个不同节点上面拉过来,传输到计算发生的地方
6.MapReduce的结构体系
(1)Client(客户端)
①通过Client可以提交用户编写的应用程序,用户通过它将应用程序交到JobTracker端
②通过这些Client,用户也可以通过它提供的一些接口去查看当前提交作业的运行状态
(2)JobTracker(作业跟踪器)
①负责资源的监控和作业的调度
②监控底层的其他TaskTracker以及当前运行的Job的健康状况
③一旦检测到失败的情况就把这个任务转移到其他节点,继续执行跟踪任务执行进度和资源使用量
(3)TaskTracker(任务调度器)
①执行具体的相关任务,一般接受JobTracker发送过来的命令
②把一些自己的资源使用情况,以及任务的运行进度通过心跳的方式,也就是heartbeat发送给JobTracker,同时接收JobTracker发送过来的命令并执行相应的操作
③TaskTracker使用slot等量划分本节点的资源量(CPU、内存等),一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用,slot分为Map slot和Reduce slot,分别供Map Task和Reduce Task使用
(4)Task(任务)
一台机器可以同时运行Map Task和Reduce Task,均由TaskTracker启动
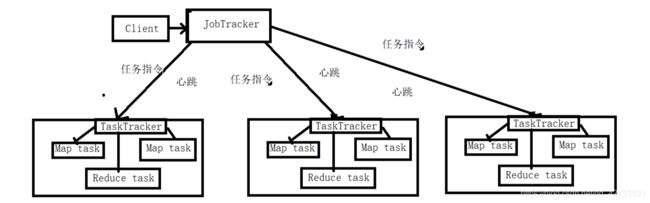
7.MapReduce工作流程
(1)①不同的Map任务之间不会进行通信
②不同的Reduce任务之间也不会发生任何信息交换
③用户不能显式地从一台机器向另一台机器发送消息
④所有数据交换都是通过MapReduce框架自身去是实现的
(2)split分片
HDFS 以固定大小的block为基本单位存储数据,MapReduce处理单位是split,split包含一些元数据信息(数据起始位置、数据长度、数据所在结点等),它的划分由用户自己定义
(3)Map任务数量
Hadoop为每个split创建一个Map任务,split的多少决定了Map任务的数目,大多数情况下,理想的分片大小是一个HDFS块
(4)Reduce任务数量
最优的Reduce任务个数取决于集群中可用的reduce任务槽(slot)的数目,通常设置比reduce任务槽数目稍小一些的Reduce任务个数(预留系统资源处理可能发生的错误)
8.Map端的Shuffle过程
(1)输入数据和执行Map任务
(2)写入缓存
(3)溢写(分区、排序、合并)
(4)文件归并
9.Reduce端的Shuffle过程
(1)“领取”数据
(2)归并数据
(3)把数据输入给Reduce任务
10.MapReduce应用程序执行过程
(1)程序部署
(2)执行map任务,执行reduce任务
(3)读数据,
(4)本地写数据
(5)远程读数据
(6)写数据
11.MaprReduce具体应用
(1)关系的选择运算
(2)关系的投影运算
(3)关系的并、交、差运算
(4)关系的自然连接运算
12.MapReduce编程实践
(1)编写Map处理逻辑,输入
(2)编写Reduce处理逻辑,输入
(3)编写main方法
(4)编译打包代码以及运行程序,编译成可执行程序,生成.class文件,把.class文件打包成jar包,启动hadoop运行jar包,查看结果
13.在hadoop中执行MapReduce任务的方式
(1)hadoop jar
(2)Pig
(3)Hive
(4)Python
(5)shell脚本
11.MaprReduce具体应用
(1)关系的选择运算
(2)关系的投影运算
(3)关系的并、交、差运算
(4)关系的自然连接运算
12.MapReduce编程实践
(1)编写Map处理逻辑,输入
(2)编写Reduce处理逻辑,输入
(3)编写main方法
(4)编译打包代码以及运行程序,编译成可执行程序,生成.class文件,把.class文件打包成jar包,启动hadoop运行jar包,查看结果
13.在hadoop中执行MapReduce任务的方式
(1)hadoop jar
(2)Pig
(3)Hive
(4)Python
(5)shell脚本
14.WordCount.java
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] " );
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}
15.使用命令行编译打包运行MapReduce程序(Hadoop3.1.3伪分布式)
(1)新建wordcount文件夹,编写WordCount.java文件
(2)在wordcount目录里运行javac WordCount.java,把生成的.class打包成jar,在wordcount目录里运行jar -cvf WordCount.jar ./WordCount*.class
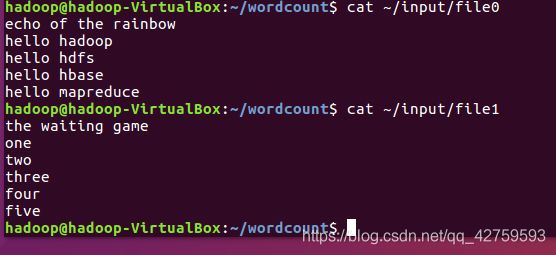
(3)在hadoop/home目录里新建input目录,新建文件file0和file1,文件内容如下:

(4)把本地目录input里的文件上传到伪分布式HDFS上的input目录里,运行打包的WordCount.jar,输入文件为HDFS里的input,输出为HDFS里的output(如果没有output电脑会自己建立)

(5)读取output里的part-r-00000文件就可以知道统计单词结果
(6)如果是运行Hadoop自带的wordcount单词统计程序:
第四步里运行WordCount.jar,不用自己打包的WordCount.jar,直接用Hadoop自带的例子,把WordCount.jar换成/usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar;不用自己写的WordCount方法,直接调用Hadoop自带的wordcount方法,把org/apache/hadoop/examples/WordCount换成wordcount
