Hadoop2.2.0伪分布式之MapReduce简介
一概念、
mapReduce是分布式计算模型。注:在hadoop2.x中MapReduce运行在yarn上,yarn支持多种运算模型。storm、spark等等,任何运行在JVM上的程序都可以运行在yarn上(我想这是因为它使用的是Container技术,且真正发挥了Container技术相对于Hyperviser(KVM、XEN)虚拟化的优势).
MR有两个阶段组成,Map和Reduce,用户只需要实现Map()和reduce()两个函数(
且这两个函数的输入和输出均是key -value的形式)即可实现分布式计算。代码示例略。
MapReduce设计框架:
在1.0中:,管理者:Job Tracker;被管理者:Task Tracker:
在2.0之后:管理者ResourceManager,被管理者:Node Manager。2.0之后使用YArn
YARN上的MapReduce比传统的MapReduce包括更多的实例:主要如下
-
- 提交MapReduce作业的客户端
- YARN资源管理器,负责协调集群上计算资源的分配,
- YARN节点管理器,负责启动和监视集群中机器上的计算容器(Container)
- MapReduce应用程序master,
- 分布式文件系统HDFS,用来与其他实例间共享作业文件。
二、MapReduce执行过程:
其输入输出都在HDFS中,资源数据在HDFS中,计算结果同样存入HDFS中。

1、主要有三个阶段;map-》Shuffle-》reducer、
2、其中分区排序分组(按key值进行分组
)都是在shuffle中完成的,Reducer会去想shuffle去取数据。
3、Map和reducer的输入输出都是key-value
1、Map任务执行步骤(简述):
1、读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。key的值是当前行首字母的偏移量,value的值时当前行的内容
2、每一个键值对调用一次map函数。
3、 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
4、对输出的key、value进行分区。
5、 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。
6、(可选)分组后的数据进行归约。
2、Reduce任务执行步骤(简述):
1、对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2、 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
3、 把reduce的输出保存到文件中
3、Shuffle的执行过程(概述):由于篇幅较长故放在文章最后。
三、MapReduce在Hadoop1.0中的流程:(2.0中会有些区别)
1、将jar包写好之后再客户端运行一个hadoop jar命令,来执行MapReduce任务中的main方法,而此main方法中会构建一个Job对象,这个Job 对象中其实还持有一个JobClient,JobClient持有ResourceManager的代理对象,因此JobClient可以与ResourceManager通信,通信之后,ResourceManager会给JobClient
一个JOBID和一个存放jar包的路径(比较固定),
2、客户端会将ResourceManager给他的Jar包路径作为前缀,JobID作为后缀将两个路径拼接起来作为唯一的
路径,
3、客户端会根据拼接得到的路径,将任务jar包写入到HDFS文件系统中。Client中有FileSystem对象(即Hadoop提供的工具类),利用该对象Client就可以将jar包写入到HDFS中,默认情况下jar包写10份(源码包:
hadoop-mapreduce-client-core-2.2.0.jar/mapred-default.xml中的
mapreduce.client.submit.file.replication参数中定义的),这样可以提高NodeManager向HDFS读取jar包的效率(其他数据默认写三份)。程序运行完成后会将jar包删除
4、Client会将任务信息包括:jobID和提交到HDFS的位置和一些配置信息等等,通过RPC方法的参数提交给ResourceManager,因此ResourceManager会存有该任务的描述信息
5、ResourceManager得到该任务的描述信息后,将这些信息初始化放到其调度器中(hadoop有多种调度器),
6、ResourceManager查看数据(计算资源)多大,决定启动多少个Mapper和多少Reducer,之后将任务放到调度其中(hadoop有多种调度器 ),
7、之后小弟NodeManager就可以通过心跳机制领取任务
8、小弟NodeManager在领取任务后回去HDFS上下载任务jar包,
9、下载完jar包之后,NodeManager会另外启动一个java子进程yarnChild(在这个子进程中运行mapper任务或Reduce任务),子进程中Mapper先读取数据解析成key-value后,传给reduce,
10、reduce计算完成后再将数据写回到HDFS中
四、mapReduce在Hadoop2.x中
各部分简介:
ResourceManager,RM :管理集群上资源使用的资源管理器:
Application Master ,
AM :管理集群上运行任务声明周期的应用管理器:
应用服务器MA和资源管理器RM协商集群的计算资源:容器(
Container,每个容器都有特定的内存上线),在这些容器上运行特定应用程序的进程,容器由集群节点上运行的节点管理器
Node Manager监视,以确保应用程序使用的资源不会超过分配给他的资源。
NodeMagnager:管理每个节点上的资源和任务,主要有两个作用,定期向
RM汇报该节点的资源使用情况和各个
Container的运行状态;接收并处理
AM任务的启动停止等请求。
应用的每一个MapReduce作业有一个专用的应用Master,他运行在应用的运行期间,他和MapReduce任务在任务容器(
Container)中运行,这些容器由资源管理器
ResourceManager分配并由节点管理器
NodeManager进行管理。
hadoop2.0执行流程:

一、作业提交; 步骤1-步骤4
Job的submit()方法创建一个内部的JobSubmiter实例,并且调用其submitJobInternal()每秒轮询作业的进度,如果发现自从上次报告后有改变,,便把进度报告到控制台,作业完成后,如果成功就显示作业计数器,如果失败将导致作业失败的错误记录到控制台。
具体如下:
-
- 从资源管理器中获取新的作业ID,在Yarn命名法中它是有一个应用程序。(步骤2)
- 检查作业的输出说明,例如,如果程序中没有指定输出目录或指定的输出目录已经存在,作业就不提交,错误返回给MapReduce程序
- 计算作业的输入分片,,如果无法计算,比如因为输入路径不存在,作业就无法提交,将错误返回给Mapreduce程序
- 作业客户端检查作业的输出说明,在计算输入分片,并将作业资源(包括JAR、配置和分片信息)复制到HDFS,默认保存10份。(步骤3)
- 最后,通过调用资源管理器上的submitApplication()方法提交作业。(步骤4)
二、作业初始化; 步骤5-步骤7
-
- 资源管理器收到调用它的submitApplication()消息后,便将请求传递给调度器(Schedule),调度器分配一个容器,然后资源管理器在节点管理器的管理下在容器中启动应用程序master进程
- MapReduce作业的application master是一个Java应用程序,它的主类是MRAPPMaster他对作业进行初始化,通过创建多个薄记对象以保持对作业进度的跟踪,因为他将接受来自任务的进度和完成报告(步骤6)
- 接下来application master接受来自共享文件系统HDFS的在客户端计算的输入分片,并对每一个分片创建一个map任务对象以及由mapreduce.job.reduces属性确定的多个reduce任务对象。(步骤7)
- application master决定如何运行构成MapReduce作业的各个任务,如果作业很小,就选择在于他同一个JVM上运行。此时的任务称为uberized或称为uber任务。uber任务具体指:小于10个mapper且只有一个reducer且输入大小小于一个HDFS块的任务。
三、任务分配;步骤8
-
- 如果作业不适合作为uber任务运行,那么application master就会为该作业中的所有map任务和reduce任务向资源管理器ResourceManager请求容器。步骤8
- 具体如下:附着心跳信息的请求包括每个map任务的数据本地化信息,特别是输入片所在的主机和相应的机架信息,调度器使用这些信息来做调度决策,利用心跳的返回值与其进行通信,理想情况下,将他任务分配到数据本地化的节点,但是如果不能这样做,调度器就会相对于非本地化的分配优先使用机架本地化的分配。
四、任务执行;
步骤9-步骤11
-
- 一旦资源管理器的调度器为任务分配了容器,application master 就通过与节点管理器NodeManager通信来启动容器。步骤9a、步骤9b
- 该任务由主类为YarnChild的java程序执行,它在运行之前,首先将任务需要的资源本地化,包括作业的配置、JAR文件、和所有来自分布式HDFS缓存的文件,步骤10
- 最后运行map任务或reduce任务。步骤11
五、进度和状态更新
-
- 在YARN下运行时,任务每三秒钟通过Umbilical接口向application master汇报进度和状态(包括技术器),作为作业的汇聚视图(aggregate view)。过程如图:客户端每秒钟(可以设置)查询一次application master已接收进度更新,通常会向用户显示,
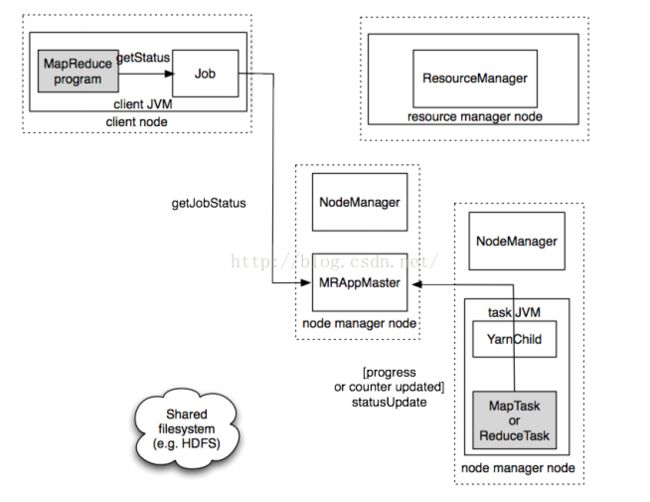
六、作业完成
-
- 除了想application master查询进度外,客户端每隔5秒还通过调用Job的waitForCompletion()来检查作业是否完成,查询的间隔可以通过属性设置。
- 作业完成后application master和任务容器清理其工作状态,OutputCommitter的作业清理方法会被调用,作业历史服务器保存作业的信息供用户需要时查询。
附1: shuffle过程:
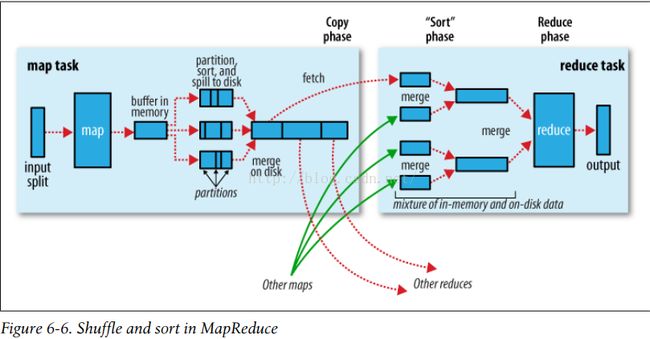
Mapper阶段
1、
一个切片对应一个Mapper,每一个Mapper都对应在内存中有一个环形缓冲区(内存当中的一段空间默认100M),用来存储Mapper的输出,当缓冲区存放的数据达到80%时,此时会开启一个线程开始将缓冲区的数据溢写到磁盘(注此时Mapper仍在向缓冲区中写入输出数据),直到缓冲区中的数据达到100%时,此时Map会被阻塞直到写磁盘的过程完成。
2、
而在内存缓冲区向磁盘溢写入数据时,会首先将数据进行分区,若没有自定义Partition类(关于partition这里不再赘述),则会采用自己默认的Partition类HashPartitioner(getPartition()中实现为:
return (key.hashCode() & Integer.MAX_VALUE)% numReduceTasks
;numReduceTasks为Reduce的数量,可以在程序中自己设置)即将数据均匀的分不给Reduce。(其中reducer的数量可以在程序中自己决定
job.setNumReduceTasks(ReducerNumber);。
上图中启动了三个Reducer )
3、
这样经过partition后数据都会有对应的分区,之后首先按照分区号将相同分区的数据放在一起,按分区号大小排序存入小文件(
Spill file )中,之后,后台线程将每一个分区里的数据按照key2的规则排序(若可key2为Text类型则按字典顺序排,若key2为LongWritable型则按自然数顺序排序,若为自定义类型则按该定义类
该类必须继承WritableComparable即必须是可排序的 规定的排序规则排)因为mapper向内存缓冲区中写数据要快于缓冲区向磁盘写数据,所以当缓冲区被写满时,mapper就会被阻塞,直到将当前缓冲区中的内容被全部写到磁盘上的一个小文件(
Spill file )中。之后再开启Mapper继续向内存缓冲区中写数据,当缓冲区中数据达到80%时,会再次开启一个线程将向缓冲区的数据写到磁盘上的
另一个小文件(Spill file )中(
即每次内存缓冲区达到溢出阈值,就会建立一个小文件Spill file)。
上图中总共写了三个小文件(其他的mapper可能会有更多的小文件Spill file )这些小文件都是分区且按分区号排序的,每个小文件(Spill file )都有三个分区,分区每个分区中的数据按key2排序。
4、Combiner
在写磁盘之前,如果有Combiner,它就会在排序后的输出上运行,使得Mapp的输出结果更紧凑,以减少写到磁盘的数据,和要传递给Reducer的数据。
5、
最后上面的小文件还要合并成一个大的文件,由于合并所以顺序肯定会被打乱,因此大文件需要再次先按分区号将数据放在一起,此时相同分区的数据进行合并 ,每个分区中再按key2排序,最终大文件也是一个分区且排序的。
最后Mapper向他的上级领导汇报,此时Mapper的任务就完成了,
Reducer阶段
Reducer要主动去获取Mapper端的数据(
如何取?向谁取?详见下文)Reducer通过HTTP方式得到输出文件的分区。上图中开启了三个reducer(
只显示的画出了0号Reducer),因此0号reduce会去取所有Mapper产生的大文件中的0号分区的数据(
上图中为4个Mapper即Orther Maps是3,因为reducer中的merge数量为4个),1号Reducer去取所有大文件中1号分区中的数据,2号Reducer会去取所有大文件中2号分区的数据。(
问题:因为集群有很多机器,会运行很多Mapper,而每个Mapper都会产生一个大文件,此时Reduce如何知道向哪里去取文件数据?详见下文)
如图0号Reducer获取到来自4个Map的大文件中的)号分区的数据(
即图中的4个mege)后会再次将这些数据合并为一个大文件,并进行排序,将最终数据给Reducer,Reducer经过计算后将结果写回到HDFS中。
Reducer获取数据的方式:1.0版本
在hadoop1.0中MapReduce的管理者为
JobTrackerc它既要监控所有的任务又要分配资源;即由它决定Mapper运行在哪台机器上,例如,若提交了1000个MapReduce那么这些MapReduce都交由
JobTrackerc 管理。而在2.0中将其功能进行了拆分,资源的分配交给
ResourceManager,资源的监控交给
ApplicationMaster,此时若提交了1000个
MapReduce,每个MapReduce就会对应有一个ApplicationMaster。
小弟的进程名为TaskTracker,TaskTracker通过心跳进程向JobTracker领取任务,领取到任务后就会启动一个JavaChild子进程,且进程名字就叫做child(而不是yarnchild)一台机器上可以运行多个child进程。child中运行Mapper或Reducer。
对于运行Mapper的child进程,当child运行完Mapper后会将产生的数据放到本机的磁盘上,关于Mapper输出数据的大小,存放位置,各个分区的具体位置等映射描述信息,会向其上级领导TaskTracker汇报,然后TaskTracker会向JobTracker汇报。其他的运行Mapper的child也会将Mapper产生的数据的映射信息,向上级汇报,最终JobTracker得到所有的Mapper产生数据的映射信息。(
之间的通信使用的RPC)
Reducer取数据
运行Reducer的child中有一个后台线程会不断的向JobTracker询问(越过自己的领导TaskTracker,以提高效率),
通过RPC机制获取 Mapper输出数据的映射关系,从而得知从哪个磁盘下载数据,而
下载数据是通过HTTp协议,由于reducer可能失败,因此TaskTracker并没有在第一个reducer检索到map输出时就从磁盘上将他们删掉,相反TaskTracker会等待,reducer执行完成之后回想JobTracker汇报,直到JobTracker告知
TaskTracker
可以删除map输出,这是作业完成后执行的。
Reducer获取数据的方式:2.x版本
2.0上提供了一个平台Yarn,只要满足Yarn的规则即可在yarn上运行。yarn的管理者
ResourceManager,yarn被管理者为
NodeManager
运行
nodeMapper进程的机器上在领到任务后会启动
YarnChild进程(一台NodeManager节点上可以启动多个YarnChild),但是NodeManager不负责管理YarnChild,YarnChild的管理是由
MrAPPMaster进程 负责管理的,每个MapReduce任务会对应一个
MrAPPMaster进程 。NodeManager只负责管理当前节点(即运行NodeManager的机器)的状态,例如内存使用情况,CPU使用情况等等。
假设有三台机器运行NodeManager,数据量较大,此时需启动了三个yarnChild进程(
每台机器上运行一个Yarnchild,若只有一台机器运行NodeManager此时会在这一台机器上启动三个YarnChild进程)其中两个运行mapper一个运行Reducer,
MrAPPMaster会随机分配到三个YarnChild中的一个上,且只有一台机器上会运行
MrAPPMaster进程,用于监控属于同一个MapReduce任务的YarnChild。因为是不同机器间的通信,此时该MrAPPMaster进程需要通过RPC监控其他机器上的yarnchild进程,运行Mapper的YarnChild中当Mapper运行完成后将输出的结果数据放到本机磁盘,然后将数据的映射信息汇报到
MrAPPMaster进程,而运行Reducer的YarnChild会向
MrAPPMaster询问数据的映射信息。
附2:Mapper启动的个数:
现在关键是确定mapper的个数,即文件被切分的个数。
文件被上传到HDFS后首先被物理切分按块存储(2.x中默认每块大小128M,1.x中默认64M),之后会对块进行逻辑切分,将其切分成多个切片。
默认情况下,切片的大小等于块的大小128M,要想让切片大小小于块的大小,此时修改,maxSize
要想使切片大小大于块的大小,此时修改Mixsize的大小。
一个切片等于一个块大小,有助于提高效率。因为这样可以使得mapper直接在自己的机器上的DataManage上取数据即可。
例如:若当前MapReduce输入文件有两个:a.txt大小为130M;b.txt大小为2K.此时会启动3个mapper。a.txt会启动两个,b.txt会启动一个。