Android 音频技术开发总结
在文章开头,我们先来了解几个概念,这样有利于对后面内容的理解。
1、概念理解
采样率:即采样频率,百科的解释是,每秒从连续信号中提取并组成离散信号的采样个数,单位 赫兹(Hz)。通俗的讲采样频率是指计算机每秒钟采集多少个声音样本,是描述声音文件的音质、音调,衡量声卡、声音文件的质量标准。好吧,感觉这样还是不太理解,那我们来看看下面的解释:
如图,
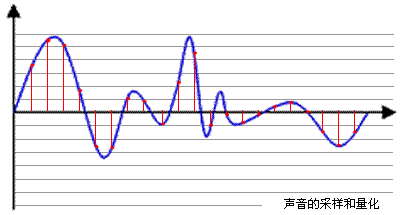
采样就是把模拟信号数字化的过程,不仅仅是音频需要采样,所有的模拟信号都需要通过采样转换为可以用 0101 来表示的数字信号,上图蓝色代表模拟音频信号,而红色的点代表采样得到的量化数值。红色点之间的间隔越小,表示采样频率越高,同时音频质量也就越高。
通道数:一般表示声音录制时的音源数量或回放时相应的扬声器数量。单声道(Mono)和双声道(Stereo)比较常见。
量化精度(位宽):上图中的每一个红色点,都有一个数值来表示其大小,这个数值的数据类型有:4bit、8bit、16bit、32bit等,位数越多,表示得就越精细,声音质量也就越好。
音频帧(frame):音频数据是流式的,本身并没有明确的一帧帧的概念,在实际的应用中,为了音频算法处理/传输的方便,一般约定俗成取 2.5 ms ~ 60 ms为单位的数据量为一帧音频。 这个时间被称之为“采样时间”,其长度没有特别的标准。我们可以计算一下一帧音频帧的大小:
假设某通道的音频信号是采样率为 8 kHz,位宽为16 bit,20 ms 一帧,双通道,则一帧音频数据的大小为:
int size = 8000 x 16bit x 0.02s x 2 = 5120 bit = 640 byte音频编码:模拟的音频信号转换为数字信号需要经过采样和量化,量化的过程被称之为编码。根据不同的量化策略,产生了许多不同的编码方式。
2、音频采集
在 Android 开发中,官方 SDK 提供了两套音频录制的 API,一个是 MediaRecorder ,另一个是 AudioRecord。前者会对录入的音频数据进行编码压缩(如 AMR,3GP等), 而后者是更加偏向底层的 API,录入的是一帧帧 的 PCM 音频数据,是无损没有经过压缩的。如果你对音频格式没有特殊的要求,只是简单的想做一个录音功能,那推荐你使用 MediaRecorder 。MediaRecorder 支持的输出方式有:amr_nb,amr_wb, default, mpeg_4, raw_amr, three_gpp。如果需要对音频数据进行额外的算法处理,则建议使用更加灵活的 AudioRecord API。比如,我想要录制一个 MP3 格式的音频文件, Android SDK 本身是不支持直接录制 MP3 格式的文件,我们就可以通过 AudioRecord 来采集音频数据,并通过第三方库来进行编码。下面我将会介绍怎么在 Android 上使用 AudioRecord 录制 MP3 和 WAV 格式的音频文件。
2.1 MP3 音频录制
LAME 是目前最出色的 MP3 编码引擎。我们要在 Android 平台上使用它,需要下载 lame 源码并将其编译成 so 库,然后通过 jni 来调用。这里有一个开源项目 AndroidMP3Recorder 帮我们省去了这一步骤,而且这个库封装了底层的 MP3 编码,我们直接拿过来使用就可以了。作者具体的实现思路,可以参考这里 实现思路讲解。
我简要说下怎么引入这个库和使用,以及本人踩过的坑。
在 Android studio 上集成这个库:
dependencies {
compile 'com.czt.mp3recorder:library:1.0.2'
}另外,因为上面的集成会自动引入多种 so 库,如果只需要其中的几种,可以在gradle中添加下面的配置(比如):
productFlavors {
arm {
ndk {
abiFilters "armeabi-v7a", "armeabi"
}
}
x86 {
ndk {
abiFilter "x86"
}
}
}这样在编译时就只会在 arm 中接入 armeabi-v7a armeabi 包,在 x86 上接入 x86 的包,而不会接入其他的包。最后还需要在 gradle.properties 中添加:
android.useDeprecatedNdk = true这样就可以正常使用了。如果不过滤不需要的 so 库,在编译时就会报这个错
java.lang.UnsatisfiedLinkError举个例子,使用无线保镖 SDK 时,我们会接入 armeabi-v7a 和 x86 这两个包的 so 文件,但由于我们使用了 AndroidMP3Recorder 这个库,它会产生额外的诸如 armeabi、armeabi-v8a、mips等多个文件夹,这些文件夹里面都有 liblame.so 文件,但没有无线保镖的 so 文件,这样就会引发java.lang.UnsatisfiedLinkError 错误,导致编译不通过。
OK,剩下的就是开始使用这个库了。
// 创建 MP3Recorder 实例, 传入录音文件的保存路径和文件名
MP3Recorder mRecorder = new MP3Recorder(new File(Environment.getExternalStorageDirectory(), "demo.mp3"));
// 开始录音
mRecorder.start();
// 停止录音
mRecorder.stop();是不是很简单,转码的事情通通不用操心,全帮你做了。
踩到的坑:
后面我发现在小米4、锤子 T2 等手机上打开接入了这个库的 app 直接闪退了。经过分析发现,在小米 4、锤子 T2 等手机上运行我们的 app ,系统会先去找 arm64-v8a 这个目录下的 so 文件,如果不存在还好,偏偏我的 app 存在 arm64-v8a 目录,此时因为找不到目录下无线保镖的 so 文件(前面说过,接入了无线保镖只会引入 armeabi-v7a 和 x86 这两个包的 so 文件),就直接报 java.lang.UnsatisfiedLinkError:couldn't find "libsecuritysdk.so" 的错了。
这时候我就纳闷了,前面配置时我的确只保留了 armeabi-v7a 和 x86 这两个目录下的 so 文件,去掉了不需要的 so ,但为什么还会出现其他的 so 目录呢?后面发现,在打包 apk 时,这些 so 库还是会一并被打包进 apk !而在测试时,刚好使用的 MX3 手机加载 so 文件正常,所以没发现这个问题。这时候你也许会问,为什么小米4、锤子 T2 等手机会先去找 arm64-v8a 这个目录呢?因为它们是 64 位设备呀,而 armeabi-v7a 和 x86 针对的都是 32 位的文件。综上所述,问题可以描述为怎么在 64 位的设备上运行 32 位的二进制文件,这里指 so 文件。
在 stackoverflow 上找到了解决的答案:
When you install an APK on Android, the system will look for native libraries directories (armeabi, armeabi-v7a, arm64-v8a, x86, x86_64, mips64, mips) inside the lib folder of the APK, in the order determined by Build.SUPPORTED_ABIS.
If your app happen to have an arm64-v8a directory with missing libs, the missing libs will not be installed from another directory, the libs aren't mixed. That means you have to provide the full set of your libraries for each architecture.
So, to solve your issue, you can remove your 64-bit libs from your build, or set abiFilters to package only 32-bit architectures:
android {
....
defaultConfig {
....
ndk {
abiFilters "x86", "armeabi-v7a"
}
}
}如果照上面的配置,那打包时就只会把 "x86", "armeabi-v7a" 这两个目录及其下的 so 文件打包进 apk 。我们的问题也解决了,因为系统也只能找这两个目录下的 so 文件了。
2.2 WAV 音频录制
因为 wav 是无损格式的音频文件,所以我们使用的还是 AudioRecord 这个 API。但在此之前,我们需要先了解一下怎么存储 wav 格式的文件。
wav 是微软公司开发的一种声音文件格式,整个文件分两部分,第一部分是"文件头",包括:采样率、通道数、位宽等参数信息,第二部分是"数据块":指一帧一帧的二进制音频数据。
见下图 wav 格式的文件头:
它主要分为三个部分:
第一部分,The "RIFF" chunk descriptor,通过 “ChunkID” 来表示这是一个 “RIFF” 格式的文件,通过 “Format” 填入 “WAVE” 来标识这是一个 wav 文件。而 “ChunkSize” 则记录了整个 wav 文件的字节数。
第二部分,The "fmt" sub-chunk,从图中可以看出记录了 wav 音频文件的详细音频参数信息,例如:通道数、采样率、位宽、编码方式、数据块对齐信息等等。
第三部分,The "data" sub-chunk,这部分是真正保存 wav 数据的地方,由“Subchunk2Size”这个字段来记录后面存储的二进制原始音频数据的长度。
OK,我们来看下 Java 代码是怎么实现往一个文件写入 wav "文件头"的。结合上图,你理解起来就不会很困难了。
关键代码来自 ExtAudioRecorder:
...
RandomAccessFile randomAccessWriter = null;
...
randomAccessWriter = new RandomAccessFile(filePath, "rw");
randomAccessWriter.setLength(0); // Set file length to 0, to prevent unexpected behavior in case the file already existed
randomAccessWriter.writeBytes("RIFF");
randomAccessWriter.writeInt(0); // Final file size not known yet, write 0
randomAccessWriter.writeBytes("WAVE");
randomAccessWriter.writeBytes("fmt ");
randomAccessWriter.writeInt(Integer.reverseBytes(16)); // Sub-chunk size, 16 for PCM
randomAccessWriter.writeShort(Short.reverseBytes((short) 1)); // AudioFormat, 1 for PCM
randomAccessWriter.writeShort(Short.reverseBytes(nChannels));// Number of channels, 1 for mono, 2 for stereo
randomAccessWriter.writeInt(Integer.reverseBytes(sRate)); // Sample rate
randomAccessWriter.writeInt(Integer.reverseBytes(sRate*bSamples*nChannels/8)); // Byte rate, SampleRate*NumberOfChannels*BitsPerSample/8
randomAccessWriter.writeShort(Short.reverseBytes((short)(nChannels*bSamples/8))); // Block align, NumberOfChannels*BitsPerSample/8
randomAccessWriter.writeShort(Short.reverseBytes(bSamples)); // Bits per sample
randomAccessWriter.writeBytes("data");
randomAccessWriter.writeInt(0); // Data chunk size not known yet, write 0filePath 是音频文件绝对路径,注意此时的录音还未开始,这里的思路是在准备阶段,先创建一个带有 wave 头部信息的文件,然后在录音进行时再不断从缓冲区取出音频数据写入到这个文件中,所以这里的 ChunkSize 一开始就设置为 0。
另外,再给一个 samsung 的实现思路,它是读取录制完后的音频文件再往文件头写入 wave 的头部信息,本质上是一样的,但相对好理解些。
private void rawToWave(final File rawFile, final File waveFile) throws IOException {
byte[] rawData = new byte[(int) rawFile.length()];
DataInputStream input = null;
try {
input = new DataInputStream(new FileInputStream(rawFile));
input.read(rawData);
} finally {
if (input != null) {
input.close();
}
}
DataOutputStream output = null;
try {
output = new DataOutputStream(new FileOutputStream(waveFile));
// WAVE header
// see http://ccrma.stanford.edu/courses/422/projects/WaveFormat/
writeString(output, "RIFF"); // chunk id
writeInt(output, 36 + rawData.length); // chunk size
writeString(output, "WAVE"); // format
writeString(output, "fmt "); // subchunk 1 id
writeInt(output, 16); // subchunk 1 size
writeShort(output, (short) 1); // audio format (1 = PCM)
writeShort(output, (short) 1); // number of channels
writeInt(output, SAMPLE_RATE); // sample rate
writeInt(output, SAMPLE_RATE * 2); // byte rate
writeShort(output, (short) 2); // block align
writeShort(output, (short) 16); // bits per sample
writeString(output, "data"); // subchunk 2 id
writeInt(output, rawData.length); // subchunk 2 size
// Audio data (conversion big endian -> little endian)
short[] shorts = new short[rawData.length / 2];
ByteBuffer.wrap(rawData).order(ByteOrder.LITTLE_ENDIAN).asShortBuffer().get(shorts);
ByteBuffer bytes = ByteBuffer.allocate(shorts.length * 2);
for (short s : shorts) {
bytes.putShort(s);
}
output.write(bytes.array());
} finally {
if (output != null) {
output.close();
}
}
}3.麦克风音量获取
3.1 基础知识
度量声音强度的单位,大家最熟悉的就是分贝。计算公式如下:
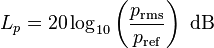
分子是测量值的声压,分母是参考值的声压(20微帕,人类所能听到的最小声压)。
在 Android 设备上传感器可以提供的物理量是场的幅值(amplitude),常用下列公式计算分贝值:
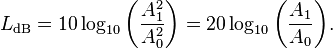
从SDK中读取了某段音频数据的振幅后,取最大振幅或平均振幅(可以用平方和平均,或绝对值的和平均),代入上述公式的A1。这里的 A0 取值似情况而定,这里不做讨论。
MediaRecorder 有一个无参方法 getMaxAmplitude 即可获得一小段时间内音源数据中的最大振幅。而 AudioRecord 没有提供类似的方法,但是我们可以获得具体的音源数据值来进行换算。调用 AudioRecord 的 read(byte[] audioData, int offsetInBytes, int sizeInBytes) 方法从缓冲区读取到我们传入的字节数组buffer 后,便可以对其进行操作,如求平方和或绝对值的平均值。这样可以避免个别极端值的影响,使计算的结果更加稳定。求得平均值之后,如果是平方和则代入常数系数为 10 的公式中,如果是绝对值的则代入常数系数为 20 的公式中,算出分贝值。
我们先来获取振幅,关键代码如下:
AudioRecord audioRecorder;
byte[] buffer;
int bufferSize;
// 振幅
int mAmplitude= 0;
// Number of frames written to file on each output(only in uncompressed mode)
private int framePeriod;
...
// 初始化,sampleRate 是采样率,这里我设置的是 44100 Hz,Google Android 文档明确表明只有以下3个参数是可以在所有设备上保证支持的,44100 Hz,AudioFormat.CHANNEL_IN_MONO(单声道),AudioFormat.ENCODING_PCM_16BIT(位宽)
bufferSize = AudioRecord.getMinBufferSize(sampleRate, AudioFormat.CHANNEL_IN_MONO, AudioFormat.ENCODING_PCM_16BIT);
// MediaRecorder.AudioSource.MIC,音频采集的输入源
audioRecorder = new AudioRecord(MediaRecorder.AudioSource.MIC, sampleRate, AudioFormat.CHANNEL_IN_MONO, AudioFormat.ENCODING_PCM_16BIT, bufferSize);
...
buffer = new byte[framePeriod*bSamples/8*nChannels];
...
// 开始录音
audioRecorder.start();
// 读取缓冲区音频数据
audioRecorder.read(buffer, 0, buffer.length); // Fill buffer
try
{
randomAccessWriter.write(buffer); // Write buffer to file
payloadSize += buffer.length;
for (int i=0; i mAmplitude)
{ // Check amplitude
mAmplitude = curSample;
}
}
}
catch (IOException e)
{
}
上面的 mAmplitude 就是振幅了。现在我们需要换算成分贝,直接代入公式,只需简单的这么一句代码就行了。
int mVolume = (int)(10 * Math.log10(amplitude));上面的 mAmplitude 时刻都在变化的,除非录音结束。所以,我们可以通过 mAmplitude 来实现诸如绘制声音频率图、声波图等效果。
参考资料:
- 《wav文件格式分析详解》
- 《如何存储和解析wav文件》
- 《Android 音频开发基础知识》