heartbeat+drbd+mysql+keepalived
mysql 高可用集群概述
很多解决方案能够实现不同的SLA(服务水平协定),这些方案可以保证数据库服务器高可用性。
那么就说说目前比较流行的高可用解决方案如下几种:
- Mysql的主从复制功能是通过建立复制关系的多台或多台机器环境中,一台宕机就切换到另一台服务器上,保证mysql的可用性,可以实现90.000%的SLA。
- mysql的复制功能加一些集群软件可以实现95.000%的SLA。
- Mysql+heartbeat+DRBD的复制功能可以实现99.999%的SLA。
- 共享存储+MYSQL复制功能可以实现99.990%的SLA
- Mysql cluster的标准版和电信版可以达到99.999%的SLA。
在上述方案中,对于Mysql来说,使用共享存储的相对较少,使用方法最多的就是heartbeat+drbd+mysql cluster的方案。
DRBD原理阐述
DRBD官网:http://www.drbd.org/en/doc/users-guide-90
DRBD的英文全称是Distributed Replicated Block Deivce(分布式块设备复制),是linux内核的存储层一个分布式存储系统。可以利用DRBD在两台服务器之间共享块设备,文件系统和数据。类似于一个网络RAID1的功能。
它有三个特点:
- 实时复制:一端修改后马上复制过去。
- 透明的传输: 应用程序不需要感知(或者认识)到这个数据存储在多个主机上。
- 同步或者异步通过:同步镜像,应用程序写完成后会通知所有已连接的主机;异步同步;应用程序会在本地写完之前通知其他的主机。
他有三个协议
- A 写I/O达到本地磁盘和本地的TCP发送发送缓存区后,返回操作成功。
- B 写I/O达到本地磁盘和远程节点的缓存区之后,返回操作成功。
- C 写I/O达到本地磁盘和远程节点的磁盘之后,返回操作成功。
架构图如下所示:
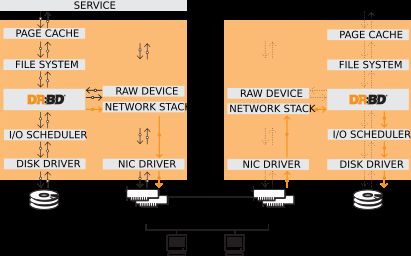
当数据写入到本地主节点的文件系统时,这些数据会通过网络发送到另一台主节点上。本地节点和远程节点数据通过TCP/IP协议保持同步,主节点故障时,远程节点保存着相同的数据,可以接替主节点继续提供数据。两个节点之间通过使用heartbeat来检测对方是否存活。
同步过程如下
左为node1,右为node2
- 在NODE1上写操作被提交,然后通过内核传给DRBD模块。
- DRBD发送写操作到NODE2。
- NODE2上的DRBD发送写操作给本地磁盘
- 在node2上的DRBD向node1发送确认信息,确认已经收到写操作并发给本地磁盘。
- NODE1上的DRBD发送写操作给本地磁盘。
- NODE1上的内核回应写操作完成。
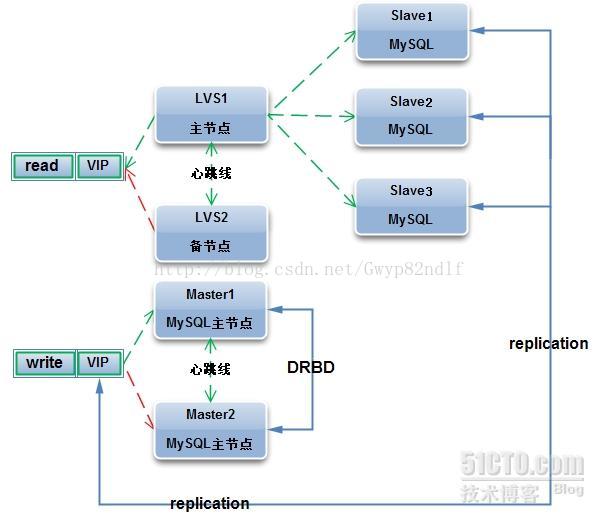
部署Mysql高可用扩展集群
公司Mysql集群具备高可用,可以扩展,易管理,低成本的特点。通常采用Mysql读写分离的方法,而读写之间的数据同步采用Mysql的单向或者双向复制技术实现。Mysql写操作一般采用基于heartbeat+DRBD+MYSQL搭建高可用集群的方案,而读操作普遍采用基于LVS+keepalived搭建高可用扩展集群方案。
下面是我们环境的设备信息
| 主机名 | IP | 角色 |
|---|---|---|
| dbmaster81 | 172.16.22.81 | heartbeat+DRBD+Mysql的主节点 |
| dbbackup136 | 172.16.22.136 | heartbeat+DRBD+Mysql的备节点 |
| dbrepslave142 | 172.16.22.142 | mysql-salve,master_host=172.16.160.251 |
| dbrepslave134 | 172.16.22.134 | mysql-salve,master_host=172.16.160.251 |
| lvsmaster162 | 172.16.22.162 | lvs+keepalived master |
| lvsbackup163 | 172.16.160.163 | lvs+keepalived backup |
- keepalived 所使用的IP为 172.16.22.251
- heartbeat 所使用的IP为172.16.22.250
- lvs 对应的realserver 为 172.16.22.142和172.16.22.134
- 以上都是CentOs6.6的系统
- Notice
如果读取的流量非常大,我们还可以考虑在LVS前面加一个Memcached,使其Memcached作为Mysql读数据的一层缓冲层。至于如何让Memcached与Mysql进行联动http://www.cnblogs.com/liaojiafa/p/6029313.html
架构图如下:
基础工作要到位
1. /etc/hosts
所有服务器的/etc/hosts这个文件必须包含所有主机名和主机IP。如下所示:
[root@dbmaster81 ~]# cat /etc/hosts
127.0.0.1 mfsmaster localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.22.162 lvsmaster162
172.16.22.163 lvsbackup163
172.16.22.142 dbrepslave142
172.16.22.134 dbrepslave134
172.16.22.81 dbmaster81
172.16.22.136 dbbackup136 2. 磁盘分区
数据服务器最好划分一个块单独的分区给数据库文件使用。包含mysql的datadir目录,binlog文件,relay log文件,my.cnf文件,以及ibd文件(单独表空间),ibdata文件和ib_logfile文件。互为主备或者同一集群下面 最好磁盘分区一致。避免磁盘空间大小不同导致出现的问题。
3. 网络环境
咱们使用DRBD进行同步的网络状况是否良好。DRBD同步操作对网络环境要求很好,特别是在写入大量数据的时候,网络越好同步速度和可靠性越高。可以考虑把DB对外服务和DRBD同步网络分开,使他们不会互相干扰。关于心跳线的,两台服务器之间最好为2根,这样不会一根线故障导致VIP的切换。在要求较高的环境下,都要求3根心跳线进程心跳检测,以此减少误切换和脑裂的问题,同时要确认上层交换机是否禁止ARP广播。
开始部署
DRBD的部署
可以采用源码安装或者yum安装,我这边为了更方便就采用yum安装,源码安装比较麻烦了。
首先安装yum源,然后再安装BRBD,yum参考文档:http://www.drbd.org/en/doc/users-guide-84/s-distro-packages
在172.16.22.81上安装drbd
[root@dbmaster81 ~]# yum update kernel-devel kernel # 先升级内核,不然安装不上DRBD,我的内核旧的是(2.6.32-504.el6.x86_64),升级后的是2.6.32-642.11.1.el6.x86_64。
[root@dbmaster81 ~]# reboot # 启动之前先检测当前使用的内核版本,同时确认grub.conf里面默认启动的是新内核
[root@dbmaster81 ~]# rpm -Uvh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
[root@dbmaster191 ~]# ls /etc/yum.repos.d/ # 下面是yum源
CentOS-Base.repo CentOS-Debuginfo.repo CentOS-fasttrack.repo CentOS-Media.repo CentOS-Vault.repo elrepo.repo
[root@dbmaster81 ~]# yum -y install drbd84-utils kmod-drbd84
[root@dbmaster81 ~]# modprobe drbd # 加载drbd模块
[root@dbmaster81 ~]# lsmod |grep -i drbd
drbd 372759 0
libcrc32c 1246 1 drbd安装确认无误后,先格式化磁盘给drbd使用,然后来看是配置:
[root@dbmaster81 ~]# fdisk /dev/sdb # 划分一个分区为sdb1,master和backup分区大小一致。
[root@dbmaster81 ~]# cat /etc/drbd.conf
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
#include "drbd.d/global_common.conf"; #注释掉这行,避免和我们自己写的配置产生冲突。
include "drbd.d/*.res";
include "drbd.d/*.cfg";
[root@dbmaster81 ~]# cat /etc/drbd.d/drbd_basic.cfg #主要配置文件
global {
usage-count yes; # 是否参与DRBD使用者统计,默认为yes,yes or no都无所谓
}
common {
syncer { rate 30M; } # 设置主备节点同步的网络速率最大值,默认单位是字节,我们可以设定为兆
}
resource r0 { # r0为资源名,我们在初始化磁盘的时候就可以使用资源名来初始化。
protocol C; #使用 C 协议。
handlers {
pri-on-incon-degr "echo o > /proc/sysrq-trigger ; halt -f ";
pri-lost-after-sb "echo o > /proc/sysrq-trigger ; halt -f ";
local-io-error "echo o > /proc/sysrq-trigger ; halt -f";
fence-peer "/usr/lib4/heartbeat/drbd-peer-outdater -t 5";
pri-lost "echo pri-lst. Have a look at the log file. | mail -s 'Drbd Alert' root";
split-brain "/usr/lib/drbd/notify-split-brain.sh root";
out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
}
net {
cram-hmac-alg "sha1";
shared-secret "MySQL-HA";
# drbd同步时使用的验证方式和密码信息
}
disk {
on-io-error detach;
fencing resource-only;
# 使用DOPD(drbd outdate-peer deamon)功能保证数据不同步的时候不进行切换。
}
startup {
wfc-timeout 120;
degr-wfc-timeout 120;
}
device /dev/drbd0; # 这里/dev/drbd0是用户挂载时的设备名字,由DRBD进程创建
on dbmaster81 { #每个主机名的说明以on开头,后面是hostname(必须在/etc/hosts可解析)
disk /dev/sdb1; # 使用这个磁盘作为drbd的磁盘/dev/drbd0。
address 172.16.22.81:7788; #设置DRBD的监听端口,用于与另一台主机通信
meta-disk internal; # drbd的元数据存放方式
}
on dbbackup136 {
disk /dev/sdb1;
address 172.16.22.136:7788;
meta-disk internal;
}
}
[root@dbmaster81 ~]# drbdadm create-md r0 # 在/dev/sdb1分区上创建DRBD元数据库信息,也称元数据。
WARN:
You are using the 'drbd-peer-outdater' as fence-peer program.
If you use that mechanism the dopd heartbeat plugin program needs
to be able to call drbdsetup and drbdmeta with root privileges.
You need to fix this with these commands:
chgrp haclient /lib/drbd/drbdsetup-84
chmod o-x /lib/drbd/drbdsetup-84
chmod u+s /lib/drbd/drbdsetup-84
chgrp haclient /sbin/drbdmeta
chmod o-x /sbin/drbdmeta
chmod u+s /sbin/drbdmeta
initializing activity log
NOT initializing bitmap
Writing meta data...
New drbd meta data block successfully created. # 创建成功
success
#上面提示的命令如下,不必要执行:
useradd haclient
chgrp haclient /lib/drbd/drbdsetup-84
chmod o-x /lib/drbd/drbdsetup-84
chmod u+s /lib/drbd/drbdsetup-84
chgrp haclient /sbin/drbdmeta
chmod o-x /sbin/drbdmeta
chmod u+s /sbin/drbdmeta
[root@dbmaster81 ~]# service drbd start
[root@dbmaster81 ~]# drbdadm primary all #把当前服务器设置为primary状态(主节点),如果这一步执行不成功,那么执行这个命令“drbdadm -- --overwrite-data-of-peer primary all”- 如果可以正常启动,那么就把/etc/drbd.d/drbd_basic.cfg和/etc/drbd.conf复制到backup172.16.22.136上。
-
如果不正常启动,像下面这样的报错,那么就按步骤来:
[root@dbmaster81 ~]# drbdadm primary all 0: State change failed: (-2) Need access to UpToDate data # 报错,无法设置为Primary Command 'drbdsetup-84 primary 0' terminated with exit code 17 [root@dbmaster81 ~]# drbd-overview 0:r0/0 Connected Secondary/Secondary Inconsistent/Inconsistent [root@dbmaster81 ~]# drbdadm primary --force r0 # 强制设置为Primary。 [root@dbmaster81 ~]# drbd-overview 0:r0/0 SyncSource Secondary/Secondary UpToDate/Inconsistent [>....................] sync'ed: 0.1% (511600/511884)M #同步中 ,500G的磁盘,同步需要一会时间,取决于网速(交换机和网卡)
- 格式化磁盘,使用配置文件指定的/dev/sdb1,两者的容量要大小相同。
- 使用drbdadm create-md r0 创建元数据库在/dev/sdb1。
- 启动服务。service drbd start。
- 查看状态。service drbd status.
在backup服务器上做完上述说的操作后,我们在bakcup服务器查看drbd的状态:
[root@dbbackup136 ~]# service drbd status #dbbackup136上查看
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Secondary/Primary UpToDate/UpToDate C #进入的主备状态,刚开始启动的时候会进入同步状态,会显示同步进度的百分比
[root@dbmaster81 ~]# service drbd status # drbd master上查看
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C
##进入的主备状态
[root@dbmaster81 ~]# drbdadm dstate r0
UpToDate/UpToDate
[root@dbmaster81 ~]# drbdadm role r0
Primary/Secondary挂载DRBD的磁盘
我们在dbmaster81(drbd master)上操作:
[root@dbmaster81 ~]# mkfs.ext4 /dev/drbd0
[root@dbmaster81 ~]# mkdir /database
[root@dbmaster81 ~]# mount /dev/drbd0 /database/
[root@dbmaster81 ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda2 ext4 28G 2.8G 24G 11% /
tmpfs tmpfs 238M 0 238M 0% /dev/shm
/dev/sda1 ext4 283M 57M 212M 22% /boot
/dev/drbd0 ext4 11G 26M 9.6G 1% /database #g挂载成功主端挂载完后去格式化备端和挂载,主要是检测备端是否能够正常挂载和使用,格式化之前需要主备状态切换,切换的方法请看下面的DRBD设备角色切换的内容。下面就在备端格式化和挂载磁盘。
[root@dbbackup136 ~]# drbdadm primary r0
[root@dbbackup136 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C # 确保是Primary状态才可以格式化挂载使用。主要是
[root@dbbackup136 ~]# mkfs.ext4 /dev/drbd0 备端也可以这样挂载磁盘,但是挂载的前提是备端切换成master端。只有master端可以挂载磁盘。
问题经验总结
这里说说我当初遇到的一个问题:
drbd在一次使用LVM的时候,使用的是500M的逻辑卷,然后在Primary格式化挂载,发现是500M的容量后,就删除500M的逻辑卷通过lvremove命令。于是重新分了500G的逻辑卷,drbd同步元数据后,直接挂载在mysql数据目录下,通过df命令发现还是drbd0的大小还是500M的,找了半天的原因,最后发现,原来在使用新逻辑卷500G的时候,没有mkfs.ext4格式化磁盘就挂载在mysql数据目录下导致的。 解决方法就是重新格式化drbd0磁盘后挂载就可以使用500G的容量了
DRBD设备角色切换
DRBD设备在角色切换之前,需要在主节点执行umount命令卸载磁盘先,然后再把一台主机上的DRBD角色修改为Primary,最后把当前节点的磁盘挂载
第一种方法:
在172.16.22.81上操作(当前是primary)。
[root@dbmaster81 ~]# umount /database/
[root@dbmaster81 ~]# drbdadm secondary r0
[root@dbmaster81 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Secondary/Secondary UpToDate/UpToDate C #状态已经转变了在172.16.22.136上操作。
[root@dbbackup136 ~]# drbdadm primary r0
WARN:
You are using the 'drbd-peer-outdater' as fence-peer program.
If you use that mechanism the dopd heartbeat plugin program needs
to be able to call drbdsetup and drbdmeta with root privileges.
You need to fix this with these commands:
chgrp haclient /lib/drbd/drbdsetup-84
chmod o-x /lib/drbd/drbdsetup-84
chmod u+s /lib/drbd/drbdsetup-84
chgrp haclient /sbin/drbdmeta
chmod o-x /sbin/drbdmeta
chmod u+s /sbin/drbdmeta
[root@dbbackup136 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C #状态已经转变了
[root@dbbackup136 ~]# mkfs.ext4 /dev/drbd0 # 在没有切换成primary状态的时候,是没法格式化磁盘的。第二种方法:
在172.16.22.136上操作(当前是primary)。
[root@dbbackup136 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C /database ext4
[root@dbbackup136 ~]# service drbd stop # 先停止服务
Stopping all DRBD resources: 在172.16.22.81上操作
[root@dbmaster81 ~]# drbdadm -- --overwrite-data-of-peer primary all #强行切换为primary
[root@dbmaster81 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 WFConnection Primary/Unknown UpToDate/Outdated C # 切换成功DRBD的性能优化
1. 网络环境
使用千兆或多张千兆网卡绑定的网络接口,交换机也必须是千兆级别的,且数据同步网络需要和业务网络隔开,避免两者相互干扰。
2. 磁盘性能
给DRBD做磁盘分区的硬盘性能尽量好点,可以考虑转速15K/Min的SAS硬盘或者SSD,或者使用RAID5 或者RAID 0等,在网络环境很好的情况下,DRBD分区可能由于I/O的写性能成为瓶颈。
3. 更新系统
尽量把系统更新成最新的内容,同时使用最新的DRBD,目前kernel2.6.13已经准备把DRBD作为Linux Kernel的主干分支了。
4. syncer的参数
syncer主要用来设置同步相关参数,可以设置“重新”同步(re-synchronization)的速率,当节点间出现不一致的block时,DRBD就需要执行re-synchronization动作,而syncer中的参数rate就是设置同步速率的,rate设置与网络和磁盘IO能力密切相关。
对于这个rate值的设定,官方建议是同步速率和磁盘写入速率中最小者的30%带宽来设置re-synchronization是比较合适。
例如:网络是千兆的(速率为125MB/S),磁盘写入速度(110MB/S),那么rate应该设置为33MB(110*30%=33MB)。这样设置的原因是因为:DRBD同步由两个不同的进程来负责,一个replication进程用来同步block的更新,这个值受限于参数;一个synchronization进程来同步元数据信息,这个值不收参数设置限制。。如果写入量非常大,设置的参数超过了磁盘的写入性能,那么元数据同步就会收到干扰,传输速度变慢,导致机器负载很高,性能下降的很厉害,所这个这个rate值要根据实际环境设置,如果设置过大,就会把所有的带宽占满,导致replication进程没有带宽可用,最终导致I/O停止,出现同步不正常的现象。
5. al-extents 参数设置
al-extents控制着一次向磁盘写入多少个4MB的数据块。增大这个参数的值有以下几个好处:
- 可以减少更新元数据到DRBD设备的频率。
- 降低同步数据时对I/O流中断数量。
- 提高修改DRBD设备的速度。
但是也有一个风险,当主节点宕机以后,所有活动的数据(al-extends的值*4M的数据库)需要在同步连接建立后重新同步,即在主节点出现宕机时,备用节点出现数据不一致的情况。所以不建议在HA部署上调整这个参数。可以在极个别情况下根据需求调整。 -
更多内容请参考官网地址:http://www.drbd.org/en/doc/users-guide-84/ch-admin#s-check-status
安装并启动Mysql
为了方便,我一般采用yum安装Mysql。命令如下:
在172.16.22.81和172.16.22.136上安装
[root@dbmaster81 ~]# yum -y install mysql mysql-server mysql-devel mysql-test mysql-bench然后在172.16.22.81上挂载datadir(使用的DRBD的drbd0)
[root@dbmaster81 ~]# service drbd status
drbd driver loaded OK; device status:
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C # 首先确保drbd目前是primary状态,如果不是,运行drbdadm primary r0=
[root@dbmaster81 ~]# mount /dev/drbd0 /database/
[root@dbmaster81 ~]# mkdir /database/mysql
[root@dbmaster81 ~]# cp -Rp /var/lib/mysql/ /database/mysql/ # 复制数据库文件的时候,要保持mysql数据库文件的属组属主属性。
[root@dbmaster81 ~]# chown -R mysql.mysql /database/mysql/ # 确保属于mysql用户
[root@dbmaster81 ~]# vim /etc/my.cnf
datadir=/database/mysql
[root@dbmaster81 ~]# ln -s /etc/init.d/mysqld /etc/ha.d/resource.d/mysqld # 用于heartbeat管理mysqld。修改配置文件
两个db服务器一定要一模一样的配置除了server-id
[root@dbmaster81 ~]# cat /etc/my.cnf
[mysqld]
datadir=/database/mysql/ # 这里使用drbd的挂载的目录
socket=/var/lib/mysql/mysql.sock
user=mysql
server-id=1 # server-id必须不一样。
log-bin # 开启二进制日志。
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid启动mysql服务
只在172.16.22.81上启动,172.16.22.136的不起,因为没有挂载数据库datadir。
[root@dbmaster81 ~]# service mysqld start
MySQL Daemon failed to start.
Starting mysqld: [FAILED] 卧槽,什么情况,启动失败啊?查看下mysql日志,发现
[root@dbmaster81 ~]# cat /var/log/mysqld.log
/usr/libexec/mysqld: Table 'mysql.plugin' doesn't exist
161121 14:45:35 [ERROR] Can't open the mysql.plugin table. Please run mysql_upgrade to create it.
161121 14:45:36 [ERROR] Fatal error: Can't open and lock privilege tables: Table 'mysql.host' doesn't exist
161121 14:45:36 mysqld_safe mysqld from pid file /var/run/mysqld/mysqld.pid ended因为我之前第一次启动的时候datadir是/var/lib/mysql,更改配置文件后,重新启动时找不到对应 库文件,虽然我已经把/var/lib/mysql/* 复制到了/database/mysql下面
解决方法就是重新执行mysql_install_db来解决问题。
[root@dbmaster81 ~]# mysql_install_db --user=mysqlMysql主从配置
Mysql的复制是异步复制,即从一个Mysql实例或者端口(成为master)复制到另一个Mysql实例或者端口(成为slave)。复制操作有3个进程实现的,其中两个进程(Sql进程和IO进程)在Slave上,另一个进程在master(binlog dump)上。
要向实现复制,必须打开Master端的log-bin功能,这是因为整个复制实际上是slave从Master端获取该更新操作的日志,将其传输到本地并写到本地文件中,然后在读取本地内容执行日志中所记录的更新操作。如图所示:
不同版本Mysql二进制日志在某些语句上有些差别,因此最好是Master和Slave的Mysql版本相同。或者Master版本不高于Slave版本。
下面就开始配置Mysql-master
1. Master开启二进制日志并且创建同步需要的账户
修改/etc/my.cnf配置文件
[root@dbmaster81 ~]# vim /etc/my.cnf
[mysqld]
server-id=1 # 与slave不能相同。
log-bin
[root@dbmaster81 ~]# service mysqld restart
[root@dbmaster81 ~]# mysql -uroot -p # 登陆mysql后授权
mysql> grant replication slave on *.* to 'rep'@'172.16.22.0/24' identified by '123456'; # 授权给专门用来主从复制的用户
mysql> flush privileges;2. Master备份数据库
首先要进行锁表,防止打包数据的时候还有数据写入:
mysql> flush tables with read lock; #锁表不要退出这个终端,在其他终端完成下面的打包和scp的动作。
mysql> reset master;
[root@dbmaster81 mysql]# cd /database/mysql
[root@dbmaster81 mysql]# tar zcvf mysqlsql`date +%F`.tar.gz ib* mysql* test/ #直接打包文件,也可以选择通过mysqldump导出数据库。
[root@dbmaster81 mysql]# scp mysqlsql2016-11-21.tar.gz [email protected]:/var/lib/mysql/
[root@dbmaster81 mysql]# scp mysqlsql2016-11-21.tar.gz [email protected]:/var/lib/mysql/
[root@dbmaster81 mysql]# scp mysqlsql2016-11-21.tar.gz [email protected]:/var/lib/mysql/
mysql> unlock tables;查看master状态:
mysql> show master status;
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| mysqld-bin.000001 | 106 | | |
+-------------------+----------+--------------+------------------+3. 设置slave主机
-
安装好mysql-server
[root@dbrepslave134 ~]# yum -y install mysql mysql-server mysql-devel mysql-test mysql-bench -
然后把解压数据库文件到/etc/my.cnf指定的datadir目录下
[root@dbrepslave134 mysql]# tar zxf mysqlsql2016-11-21.tar.gz -
配置mysql,启动数据库
[root@dbrepslave134 mysql]# vim /etc/my.cnf
[mysqld]
server-id = 4
[root@dbrepslave134 mysql]# service mysqld start
Starting mysqld: [ OK ]- 做slave与master同步的动作。
[root@dbrepslave134 mysql]# mysql -uroot -p -e "change master to master_host='172.16.22.81',master_user='rep',master_password='123456',master_log_file='mysqld-bin.000001',master_log_pos=106;"
[root@dbrepslave134 mysql]# mysql -uroot -p -e "start slave ;"需要说的是:此时先和DRBD Primary(172.16.22.81)连接,因为还没搭建heartbeat服务,所以没有VIP,等下面我们搭建好heartbeat的时候,就连接VIP
-
确认同步状态
[root@dbrepslave134 mysql]# mysql -uroot -p -e "show slave status\G;" Enter password: *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.16.22.81 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysqld-bin.000001 Read_Master_Log_Pos: 106 Relay_Log_File: mysqld-relay-bin.000003 Relay_Log_Pos: 252 Relay_Master_Log_File: mysqld-bin.000001 Slave_IO_Running: Yes Slave_SQL_Running: Yes注意 Slave_IO_Running和Slave_SQL_Running:,如都是显示yes,那么说明同步正确。
注意的问题
-
如果在my.cnf中定义了log-bin,relay-log参数,那么要保证这些定义与主机名无关,因为如果这两类log的文件名和主机名有关,切换过程会导致slave主机不能够继续同步,例如可以如下设置:
log-bin = mysql-bin relay-log = mysql-relay-bin - 最好把my.cnf文件也放入DRBD分区的数据目录中,这样进行配置更改时,另一台也保持同步,避免由于修改配置文件导致后配置不一样。要把my.cnf文件放入DRBD分区的数据目录中,需要修改/etc/init.d/mysqld启动脚本中my.cnf文件的路径。
- 如果不是通过rpm安装的mysql,那么自己要写一个mysql的启动脚本,脚本能够接受start,stop,status三个参数。默认heartbeat采用LSB(linux standard base)风格。返回值包含OK或者running则表示资源正常。返回值表示stopped或者No表示资源不正常。
-
不要设置mysqld在机器重启动时自动启动,mysqld服务作为heartbeat的一项资源会统一管理。
安装和配置heartbeat
采用yum安装,dbmaster81和dbbackup136上都安装,安装命令如下:
[root@dbmaster81 ~]# rpm -vih http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm # 先安装这个yum源
[root@dbmaster81 ~]# yum -y install heartbeat heartbeat-devel heartbeat-stonith heartbeat-pils安装完成后,在dbmaster81上copy配置文件即可,dbmaster81配置完成后再scp给dbbackup136.
[root@dbmaster81 ha.d]# cp /usr/share/doc/heartbeat-3.0.4/ha.cf /etc/ha.d/ #heartbeat主配置文件
[root@dbmaster81 ha.d]# cp /usr/share/doc/heartbeat-3.0.4/haresources /etc/ha.d/ #资源信息定义文件
[root@dbmaster81 ha.d]# cp /usr/share/doc/heartbeat-3.0.4/authkeys /etc/ha.d/ # 心跳检测使用的认证文件,需要设置文件权限必须为600。
[root@dbmaster81 ha.d]# chmod 600 /etc/ha.d/authkeys # 必须是600权限
[root@dbmaster81 ha.d]# cp /etc/init.d/mysqld /etc/ha.d/resource.d/ # 把mysqld脚本复制到heartbeat下面,这样受heartbeat控制。修改配置文件。
主配置文件
[root@dbmaster81 ha.d]# cat /etc/ha.d/ha.cf
logfile /var/log/ha-log #指定heartbeat日志文件的位置
keepalive 1 # 心跳发送时间间隔
deadtime 15 # 备用节点15s内没有检测到master机的心跳,确认对方故障
warntime 5 # 警告5次
initdead 30 # 守护进程启动30s后,启动服务资源。
ucast eth0 172.16.22.136 # 另一台主机节点eth0的地址,注意是另一台。
auto_failback off # 当primary节点切换到secondary节点之后,primary节点恢复正常,不进行切回操作,因为切换一次mysql master成本很高。
node dbmaster81 # 定义两个节点的主机名,一行写一个
node dbbackup136
respawn hacluster /usr/lib64/heartbeat/ipfail #开启dopd功能
respawn hacluster /usr/lib64/heartbeat/dopd
apiauth ipfail gid=haclient uid=hacluster
apiauth dopd gid=haclient uid=hacluster认证文件:
[root@dbmaster81 ha.d]# grep -v ^# /etc/ha.d/authkeys
auth 1 #默认配置,去掉注释即可
1 sha1 HA_DB # 使用sha验证,密码为HA_DB资源说明文件:
[root@dbmaster81 ha.d]# grep -v ^# /etc/ha.d/haresources
dbmaster81 drbddisk::r0 Filesystem::/dev/drbd0::/database mysqld IPaddr::172.16.22.250/24/eth0 参数解释:
- dbmaster81
这个是在ha.cf里面node参数指明的,两者必须一致。 - 192.168.22.250/24/eth0
这是个VIP,在两台主机之间漂移 - drbddisk
这是一个管理drbd的脚本,heartbeat默认提供这个脚本文件,可以在/etc/ha.d/resource.d目录下找到。r0是一个启动资源,在DRBD配置文件中定义,通过“drbddisk::0”可以切换到drbd主机为primary节点或secondary节点,只有状态Primary节点才可以挂载DRBD分区。drbddisk脚本相当于执行了“drbdadm primary r0”,表示把DRBD资源的角色进行变更。 Filesystem::/dev/drbd0::/database
表示把/dev/drbd0设备挂载到/database分区下。
DRBDDISK脚本
[root@dbmaster81 ~]# vim /etc/ha.d/resource.d/drbddisk
69 $DRBDADM --force primary $RES && break
# 第69行,添加--force,使其强制成为Primary,如果不加的话,当master通过断电关机或者直接拔网线后,backup无法启动VIP以及drbd的,人工执行这个drbddisk脚本也是报错的,提示 State change failed: (-7) Refusing to be Primary while peer is not outdated ,导致无法切换。我们把上面配好的四个配置文件(/ha.cf,/etc/ha.d/authkeys,/etc/ha.d/haresources,/etc/ha.d/resource.d/drbddisk)复制到172.16.22.136(dbbackup136)上面。但是需要改ha.cf配置文件里的ucast参数。改成dbbackup136自身的,还有haresources的dbmaster81,需要改成另一台备份服务器的主机名,由dbmaster81改为dbbackup136。
Notice
mysql不需要开机自启动,drbd和heartbeat需要开机自启动。
[root@dbmaster81 ~]# chkconfig --list |grep -E "heartbeat|mysqld|drbd"
drbd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
heartbeat 0:off 1:off 2:on 3:on 4:on 5:on 6:off
mysqld 0:off 1:off 2:off 3:off 4:off 5:off 6:off启动heartbeat
在172.16.22.81上启动
[root@dbmaster81 ha.d]# service heartbeat start # 启动报错
Starting High-Availability services: CRITICAL: Resource drbddisk::r0 is active, and should not be!
CRITICAL: Non-idle resources can affect data integrity!
info: If you don't know what this means, then get help!
info: Read the docs and/or source to /usr/share/heartbeat/ResourceManager for more details.
CRITICAL: Resource drbddisk::r0 is active, and should not be!
CRITICAL: Non-idle resources can affect data integrity!
info: If you don't know what this means, then get help!
info: Read the docs and/or the source to /usr/share/heartbeat/ResourceManager for more details.
CRITICAL: Non-idle resources will affect resource takeback!
CRITICAL: Non-idle resources may affect data integrity!
Done.
[root@dbmaster81 ha.d]# service heartbeat status # 如没有启动成功,那么走下面的解决方法解决方法
[root@dbmaster81 ha.d]# service mysqld stop
Stopping mysqld: [ OK ]
[root@dbmaster81 ha.d]# umount /database/
[root@dbmaster81 /]# service drbd stop
[root@dbmaster81 ha.d]# service heartbeat start两者都启动后,检测是否有VIP,heartbeat是否成功启动
[root@dbmaster81 /]# ip a |grep 'inet' #检测IP是否有
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
inet 172.16.22.81/24 brd 172.16.22.255 scope global eth0
inet 172.16.22.250/24 scope global eth0
inet6 fe80::20c:29ff:fecb:9149/64 scope link
[root@dbmaster81 ~]# tail -f /var/log/ha-log # 查看日志是否正常启动
'''
ip-request-resp(default)[11422]: 2016/11/21_18:13:20 received ip-request-resp drbddisk::r0 OK yes
ResourceManager(default)[11443]: 2016/11/21_18:13:20 info: Acquiring resource group: dbmaster81 drbddisk::r0 Filesystem::/dev/drbd0::/database mysqld IPaddr::192.168.22.250/24/eth0 # 开始执行这条语句在haresource
ResourceManager(default)[11443]: 2016/11/21_18:13:20 info: Running /etc/ha.d/resource.d/drbddisk r0 start # 启动drbd
/usr/lib/ocf/resource.d//heartbeat/Filesystem(Filesystem_/dev/drbd0)[11507]: 2016/11/21_18:13:20 INFO: Resource is stopped
ResourceManager(default)[11443]: 2016/11/21_18:13:20 info: Running /etc/ha.d/resource.d/Filesystem /dev/drbd0 /database start # 挂载目录
Filesystem(Filesystem_/dev/drbd0)[11587]: 2016/11/21_18:13:20 INFO: Running start for /dev/drbd0 on /database
Filesystem(Filesystem_/dev/drbd0)[11587]: 2016/11/21_18:13:20 INFO: Starting filesystem check on /dev/drbd0
/usr/lib/ocf/resource.d//heartbeat/Filesystem(Filesystem_/dev/drbd0)[11579]: 2016/11/21_18:13:21 INFO: Success # 成功
ResourceManager(default)[11443]: 2016/11/21_18:13:23 info: Running /etc/ha.d/resource.d/IPaddr 192.168.22.250/24/eth0 start
IPaddr(IPaddr_192.168.22.250)[12005]: 2016/11/21_18:13:23 INFO: Adding inet address 192.168.22.250/24 to device eth0 # 启动VIP了
IPaddr(IPaddr_192.168.22.250)[12005]: 2016/11/21_18:13:23 INFO: Bringing device eth0 up
'''heartbeat进程在但是没有VIP
master和backup的heartbeat进程都在运行中,但是两者都没有VIP,此时,重启了master服务器上的drbd,mysql,heartbeat都不生效。最终,同时重启了master和backup上两台服务器上的heartbeat进程后,VIP才出现。
测试Mysql+Heartbeat+DRBD是否生效。
检测Mysql+Heartbeat+DRBD 是否正常联合工作,需要这么查看:
- 停掉master的heartheat看看是否能正常切换。
- 停掉master的网络或者直接将master系统shutdown,看看能否正常切换。
- 启动master的heartbeat看看是否能不切换回来,因为配置文件ha.cf中使auto_failback为off,不进行切回。
注意:这里说的切换是不是已经将mysql停掉、是否卸载了文件系统等等。
我们在172.16.22.81(dbmaster81)上查看当前状态
[root@dbmaster81 ~]# df -hT # 磁盘挂载中
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda2 ext4 28G 2.9G 23G 12% /
tmpfs tmpfs 238M 0 238M 0% /dev/shm
/dev/sda1 ext4 283M 57M 212M 22% /boot
/dev/drbd0 ext4 11G 48M 9.5G 1% /database
[root@dbmaster81 ~]# service mysqld status # 数据库在运行中
mysqld (pid 13035) is running...
[root@dbmaster81 ~]# ip a|grep 'inet '
inet 127.0.0.1/8 scope host lo
inet 172.16.22.81/24 brd 172.16.22.255 scope global eth0
inet 172.16.22.250/24 brd 172.16.22.255 scope global secondary eth0 # Vip在master上。此时看看172.16.22.136(dbbackup136)上的状态。
[root@dbbackup136 ~]# df -hT # 磁盘未挂载
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda2 ext4 28G 2.9G 23G 12% /
tmpfs tmpfs 238M 0 238M 0% /dev/shm
/dev/sda1 ext4 283M 59M 209M 22% /boot
[root@dbbackup136 ~]# service mysqld status # mysql停止运行的
mysqld is stopped
[root@dbbackup136 ~]# ip a|grep 'inet '
inet 127.0.0.1/8 scope host lo
inet 172.16.22.136/24 brd 172.16.22.255 scope global eth0 #没有VIP停止heartbeat进程或者使拔掉master网线
我们在172.16.22.81(dbmaster81)上关机,模拟服务器宕机
[root@dbmaster81 ~]# halt此时看看172.16.22.136(dbbackup136)上的状态。
[root@dbbackup136 ~]# service mysqld status # 数据库在运行中
mysqld (pid 26739) is running...
[root@dbbackup136 ~]# ip a|grep 'inet ' # Vip在master上。
inet 127.0.0.1/8 scope host lo
inet 172.16.22.136/24 brd 172.16.22.255 scope global eth0
inet 172.16.22.250/24 brd 172.16.22.255 scope global secondary eth0
[root@dbbackup136 ~]# df -hT # 磁盘挂载中
Filesystem Type Size Used Avail Use% Mounted on
/dev/sda2 ext4 28G 2.9G 23G 12% /
tmpfs tmpfs 238M 0 238M 0% /dev/shm
/dev/sda1 ext4 283M 59M 209M 22% /boot
/dev/drbd0 ext4 11G 48M 9.5G 1% /databasemaster关机后,backup能够正常接替master的服务,此时向Mysql插入数据,看能不能够正常使用Mysql,我这边用Navicat来操作Mysql,连接的是VIP(172.16.22.250),能够正常操作Mysql。说明Mysql+Heartbeat+DRBD联调成功。
等dbmaster81开机后,heartbeat的VIP等各项资源都没有回切回来,说明正确。因为配置文件配置的就是不回切,除非dbbackup136宕机了。
至此
我们已经把heartbeat安装成功,下面就说LVS+Mysql slave做负载均衡了。
Mysql+drbd+heart能够实现Mysql的高可用了,master出现故障的时候能够快速切换。在现在的业务情况下,读操作多,写操作少的情况下,一台DB server明显扛不住,这时候我们需要读写分离,一台master承担写操作,多台承担读操作。如果仍然采用heartbeat+DRBD来实现Slave的高可用性,那么成本太大了。而且,有时候DB slave宕机是在夜间,这个时候也就要求不及时处理故障也不会影响业务(也就是一有故障就会自动退出服务集群),这个时候我们可以采用LVS+Keepalived来实现我们要的功能。
切换mysql slave的master服务器IP
我们之前做mysql主从同步的时候,slave使用的是172.16.22.81作为master的IP,这个时候我们需要修改成heartbeat的VIP。
在master上查看master当前log-bin的状态:
mysql> show master status; # 在172.16.22.136上操作,因为VIP在这里
+-------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+-------------------+----------+--------------+------------------+
| mysqld-bin.000017 | 387 | | |
+-------------------+----------+--------------+------------------+在所有的slave上操作下面的语句,host为mysql的VIP
mysql> stop slave;
mysql> change master to master_host='172.16.22.250',master_user='rep',master_password='123456',master_log_file='mysqld-bin.000017',master_log_pos=387;
mysql> start slave;
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.22.250
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysqld-bin.000017
Read_Master_Log_Pos: 387
Relay_Log_File: mysqld-relay-bin.000002
Relay_Log_Pos: 253
Relay_Master_Log_File: mysqld-bin.000017
Slave_IO_Running: Yes #确认同步状态
Slave_SQL_Running: Yes #确认同步状态安装LVS+keepalived
我们采用yum安装keepalived和LVS。
在172.16.22.162和172.16.22.163上安装ipvsadm keepalived Mysql。要安装mysql,因为后面的健康探测脚本需要使用mysql命令。还有说下,安装完以后并没有对keepalived做开机自启动,自己根据实际情况做开机自启动。
[root@lvsbackup192 ~]# yum -y install ipvsadm keepalived mysql 安装好以后, 我们配置172.16.22.162的keepalived
[root@lvsmaster162 keepalived]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
18500777133@sina.cn
}
notification_email_from [email protected]
router_id lvs1
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.22.251
}
}
virtual_server 172.16.22.251 3306 {
delay_loop 6
lb_algo rr
lb_kind DR
nat_mask 255.255.255.0
persistence_timeout 50
protocol TCP
real_server 172.16.22.134 3306 {
MISC_CHECK {
misc_path "/etc/keepalived/check_alive.sh 172.16.22.134"
misc_dynamic
}
}
real_server 172.16.22.142 3306 {
MISC_CHECK {
misc_path "/etc/keepalived/check_alive.sh 172.16.22.142"
misc_dynamic
}
}
}然后是172.16.22.163的
[root@lvsbackup163 ~]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
18500777133@sina.cn
}
notification_email_from [email protected]
router_id lvs2
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.16.22.251
}
}
virtual_server 172.16.22.251 3306 {
delay_loop 6
lb_algo rr
lb_kind DR
nat_mask 255.255.255.0
persistence_timeout 50
protocol TCP
real_server 172.16.22.134 3306 {
MISC_CHECK {
misc_path "/etc/keepalived/check_alive.sh 172.16.22.134"
misc_dynamic
}
}
real_server 172.16.22.142 3306 {
MISC_CHECK {
misc_path "/etc/keepalived/check_alive.sh 172.16.22.142"
misc_dynamic
}
}
}这里说说MISC_CHECK的配置
misc_path里面指定的脚本需要返回值的,不同的返回值决定了RS是否健康。
- exit 0:健康检查正常,keepalived状态正常。
- exit 1:检测失败,keepalived 状态异常。
这里贴下脚本/etc/keepalived/check_alive.sh的内容,顺便说说脚本的思路。
监控项:
Seconds_Behind_Master: 表示slave上SQL thread与IO thread之间的延迟。
Slave_IO_Running: IO线程的是否正常运行。
Slave_SQL_Running: SQL线程是否正常运行。
脚本思路如下:
- 通过mysql命令远程对目标服务器执行show slave status\G。然后把输出结果获取。
- 通过grep命令匹配输出结果。首先匹配“Slave_IO_Running: Yes”,匹配成功设置标志位f为0,否则退出。
- 通过grep命令匹配输出结果。第二匹配“Slave_SQL_Running: Yes”,匹配成功设置标志位f为0,否则退出。
- 通过grep命令匹配输出结果,最后匹配“Seconds_Behind_Master: [0-9]*”,如果超过设定时间,那么退出,否则如果三个匹配都匹配上了,那么就说明RS服务正常。
脚本内容
[root@lvsbackup163 ~]# cat /etc/keepalived/check_alive.sh
#!/bin/bash
user='root';
passwd='123456';
command='show slave status\G;'
port=3306
rt=`mysql -u$user -p$passwd -h $1 -e "$command" `
echo $rt | grep -e "Slave_IO_Running: Yes" -o >/dev/null 2>&1
if [ $? -ne 0 ];then
exit 1
else
f1="0"
fi
echo $rt | grep -e "Slave_SQL_Running: Yes" -o >/dev/null 2>&1
if [ $? -ne 0 ];then
exit 1
else
f2="0"
fi
behind_time=`echo $rt | grep -e "Seconds_Behind_Master: [0-9]* " -o|awk '{print $2}'`
if [ $behind_time -ge 120 ];then
exit 1;
elif [ $f1 -eq 0 -a $f2 -eq 0 ];then
exit 0
fi记得脚本赋值777的权限
[root@lvsmaster162 keepalived]# chmod 777 /etc/keepalived/check_alive.sh两端都启动keepalived
[root@lvsmaster162 keepalived]# service keepalived start
[root@lvsmaster162 keepalived]# ip a|grep 'inet ' # master端上有VIP了,启动成功
inet 127.0.0.1/8 scope host lo
inet 172.16.22.162/24 brd 172.16.22.255 scope global eth0
inet 172.16.22.251/32 scope global eth0此时我们再看看ipvsadm调度情况
[root@lvsmaster162 keepalived]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.22.251:3306 rr persistent 50
-> 172.16.22.134:3306 Route 1 0 0
-> 172.16.22.142:3306 Route 1 0 0 配置RS(两台sql slave)
两台RS服务器一模一样的配置。
我们使用的LVS-DR模式,所以需要在RS配置VIP,以及更改arp的响应模式,LVS-DR模式原理流程请看我的另一篇博客:http://www.cnblogs.com/liaojiafa/p/6059652.html
[root@dbrepslave134 ~]# ifconfig lo:0 172.16.22.251 netmask 255.255.255.255 broadcast 172.16.22.251
[root@dbrepslave134 ~]# route add -host 172.16.22.251 dev lo:0
[root@dbrepslave142 ~]# tail /etc/sysctl.conf
'''''
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
[root@dbrepslave142 ~]# sysctl -p # 启用刚才的新添加在sysct.conf配置个人建议不要忘记在rc.local里面写入增加VIP的添加命令,省去开机后人工配置的麻烦:
[root@dbrepslave142 ~]# cat /etc/rc.local
ifconfig lo:0 172.16.22.251 netmask 255.255.255.255 broadcast 172.16.22.251
route add -host 172.16.22.251 dev lo:0检测LVS-keepalived是否能够正常切换如果master宕机后。
我们拿一台mysql-client(172.16.160.191)来测试,
[root@lvsmaster191 ~]# mysql -uroot -p123456 -h172.16.22.251
mysql> show databases # 登陆成功,命令执行正确
+--------------------+
| Database |
+--------------------+
| information_schema |
| hello |
| mysql |
| test |
+--------------------+
4 rows in set (0.15 sec) 查看lvs-keepalived-master(172.16.22.162)状态
[root@bogon ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.22.251:3306 rr persistent 50
-> 172.16.22.134:3306 Route 1 1 0
-> 172.16.22.142:3306 Route 1 2 0 下面我们关闭keepalived-master。模拟keepalived-master宕机,
[root@bogon ~]# ip a|grep 'inet '
inet 127.0.0.1/8 scope host lo
inet 172.16.22.162/24 brd 172.16.22.255 scope global eth0
inet 172.16.22.251/32 scope global eth0
[root@bogon ~]# halt查看keepalived-backup(172.16.22.163)的状态
[root@lvsbackup163 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.22.251:3306 rr persistent 50
-> 172.16.22.134:3306 Route 1 0 0
-> 172.16.22.142:3306 Route 1 0 0
[root@lvsbackup163 ~]# ip a|grep 'inet '
inet 127.0.0.1/8 scope host lo
inet 172.16.22.163/24 brd 172.16.22.255 scope global eth0
inet 172.16.22.251/32 scope global eth0再在客户端上查看
mysql> use hello; #没有报错,正常使用检测RS宕机后LVS是否能够正常剔除服务。
模拟服务宕机
在172.16.22.134上关闭数据库
[root@dbrepslave134 ~]# service mysqld stop
Stopping mysqld: [ OK ]在LVS-keepalived-master上看lvs负载状态:
[root@lvsmaster162 ~]# ipvsadm -Lm
Illegal 'forwarding-method' option with the 'list' command
[root@lvsmaster162 ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.16.22.251:3306 rr persistent 50
-> 172.16.22.142:3306 Route 1 0 0 # 已经把故障节点172.16.22.134提出服务了。模拟主从不一致了
造成主从不一致的状态,很简单,
- 在Master上上创建一张表,然后插入数据后,确认此时在两者是同步状态。
-
我们在172.16.22.134删除我们刚才新建的那张表,然后再在DBMaster上向刚才新建的表插入数据,一插就完蛋了,主从不同步了,因为172.16.22.134没有这个表了,导致两者数据库不一致,所以不同步了。
在172.16.22.134上查看当前状态mysql> show slave status\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.16.22.250 Master_User: rep Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysqld-bin.000019 Read_Master_Log_Pos: 788 Relay_Log_File: mysqld-relay-bin.000012 Relay_Log_Pos: 815 Relay_Master_Log_File: mysqld-bin.000019 Slave_IO_Running: Yes Slave_SQL_Running: No # IO线程不行了,因为缺少库我们在LVSmaster上查看状态:
[root@lvsmaster162 ~]# ipvsadm -Ln IP Virtual Server version 1.2.1 (size=4096) Prot LocalAddress:Port Scheduler Flags -> RemoteAddress:Port Forward Weight ActiveConn InActConn TCP 172.16.22.251:3306 rr persistent 50 -> 172.16.22.142:3306 Route 1 0 0 # 检测到134有问题,主从不同步了,剔除了服务。
至此,我们LVS+Keepalived+Mysql-Slave已经能够正常工作了。到此我们这套架构已经可以正常工作了。
Mysql+heartbeat+DRBD 作用于 Mysql写操作。
Lvs+keepalived+Mysql(Slave)作用于Mysql读操作。
高可用Slave集群的一些注意点。
- LVS有多种负载算法,采用DR模式是LVS发挥最大性能,
- 当Slave增加很多时候,超过10台以上建议通过垂直拆分来解决压力问题。因为后端RS健康检测是脚本定义的,性能问题会导致LVS机器负载过高。
- 目前DR模式在一个广播域(LAN)中部署。不能够实现多IDC容灾问题,IDC容灾问题需要另行考虑。
部署Mysql集群需要考虑的问题。
我们这个方案需要考虑以下几个问题:
- heartbeat+DRBD+MySql这个方案不能够实现毫秒级别切换速度,他的切换速度主要受两个因素影响:文件系统和表的恢复需要时间。这里需要说明的是,MyISAM引擎不适合做HA,因为MyISAM类型的表在宕机后需要 很长的修复时间,这违背了HA的初衷,所以把除系统表之外的所有表类型都修改为innodb引擎。
- 如果对可靠性要求比较高。写入的并发量非常大的时候,建议在my.cnf中修改“innodb_flush_log_at_trx_commit = 1”,以保证事务的安全性。但是这对I/O提出挑战。如何抉择,最终需要根据情况具体做出权衡。
- 如果写入量不大,可以考虑在my.cnf中加入"sync_bing = 0"来避免在某种特殊情况下Master突然宕机,出现Slave上关于Master的binlog位置(master_log_pos)点超于master宕机时写入的binlog点的情况。这对I/O很有挑战性。
- 在Slave上变更主库连接信息时,最好指定“Master_connect_retry”的值为一个合适的数值。在出现VIP漂移的时候,Slave可以更快的去重新连接VIP,避免因为切换master造成同步延迟的问题。
- 要为my.cnf中的“innodb_log_file_size”的“innodb_log_buffer_size”参数设置合适的值,设置太大会导致恢复时间比较长,降低故障切换的速度。
- 建议在ha.cf中使用“auto_failback off”选项,如果使用“on”选项会导致主备机之间来回切换,增加成本。
- 使用dopd保证在数据不一致时不进行切换,需要人工干预,同时要对drbd的同步进行监控,不同步时报警通知DBA。
- 如果是OS是64位,建议使用/usr/lib64/heartbeat目录下的ipfail和dopd。
- 在使用非3306端口或多个端口运行一台物理机时,修改/etc/init.d/mysqld的脚本使其支持status,start,stop参数。虽然可以在一台主机上部署多个DRBD分区,但建议一台主机部署一个DRBD分区,一个端口。这样做资源有一定的浪费,但是管理成本低。不建议在一台服务器上部署多个DRBD分区和搭建多个MYSQL,例如/dev/drbd0(primary/Secondary),/dev/drbd1(Secondary/Primary),这种模式下减少了机器成本,但是增加了管理成本以及恢复的复杂度,同时违背了这个方案的初衷,便捷管理,故障后修复速度快。
- HA也有自己的适合场所,不能利用它解决所有问题(因为HA并不能监控Mysql的服务状态,当Mysql主节点的连接断开出现宕机时,HA默认监控不到),这时候需要通过heartbeat的crm模式来实现对Mysql端口或者服务的监控。CRM可以参考这位兄台的博客:http://blog.csdn.net/kobeyan/article/details/7587899
- 顶起检测Mysql服务和系统是否正常运行,小概率事件往往是导致大故障的根源。
优化配置项
我们需要关注下面几个配置项,如果忽略了他们,那么会很快遇到性能问题。
-
innodb_buffer_pool_size
在使用innodb引擎的环境中,在安装完后,这个是第一个需要关注的配置项。缓冲池是数据和索引被缓存的地方,这个值要尽可能的大。典型的配置是5-6GB(8GB RAM),20-2GB(32GB RAM),100-120GB(128GB RAM)。 例如innodb_buffer_pool_size=4G,默认是128M -
innodb_log_file_size:
redo log的大小,redo log被用来保证写入的速度和故障恢复。建议设置为innodb_log_file_size=512MB,但对于频繁的数据库,这个值应该调整为innodb_log_file_size=4GB. -
max_connections:
默认是151个连接数,如果设置过大的话(1000或者以上),Mysql请求数会很大的,那么它可能会失去响应,容易报Too many connections的错误。
关于Innodb存储引擎的优化
-
innodb_file_per_table:
用于控制不同的表是否使用独立的.ibd文件。设置为on时,它可以在丢弃或者截断表时能够回收存储空间。在Mysql5.6版本以后,这个值默认就是on。因此需要在5.6版本以前的进行设置,设置后仅仅对新创建的表有效。 -
innodb_flush_log_at_trx_commit:
默认值是1,意味着Innodb是与ACID完全兼容的,如果考虑数据安全性第一需求的话,那么就要把这个值设置为1。在开启之后,额外的系统fsync调用对低速硬盘来说,是一个巨大的系统开销。设置为2时,在数据安全性方面稍微下降,因为此时每隔1s才把事务写入redo log中。在某些数据完整性要求不高的情况下,可以设置为2或者为0. -
query_cache_size:
建议一开始就设置为0,完全禁用查询缓存。 -
slow_query_log:
设置为1,表示启用满查询日志。慢查询日志是记录执行时间超过指定时间(long_query_time)的Mysql查询,是分析和优化Mysql的最重要的文件。 -
long_query_time:
默认值为10,建议修改为1,在大部分应用中,超过1s的查询基本可以判断为需要关注的执行语句。 -
slow_query_log_file:
指定慢查询日志的记录文件位置。