Hadoop学习(1)——分布式存储系统HDFS
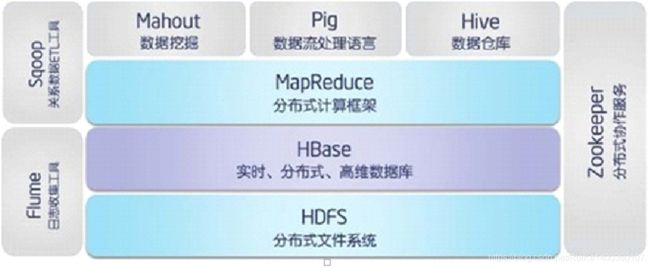
Hadoop生态
一、分布式存储系统HDFS 介绍
(1)存储模型:字节
文件线性切割成块(Block):偏移量 offset ;
Block分散存储在集群节点中,单一文件Block大小一致,文件与文件可以不一致;
Block可以设置副本数,副本无序分散在不同节点中(副本数不要超过节点数量);
文件上传可以设置Block大小和副本数,已上传的文件Block副本数可以调整,大小不变;
–只支持一次写入多次读取,同一时刻只有一个写入者;
–可以append追加数据。
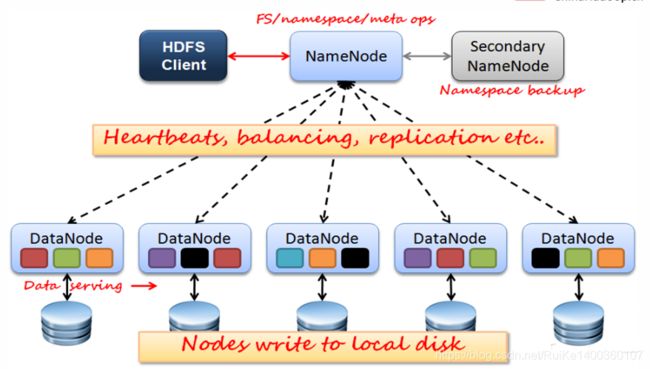
(2)架构模型:
–文件元数据MetaData,文件数据
- 元数据
- 数据本身
–(主)NameNode节点保存文件元数据:单节点 posix
–(从)DataNode节点保存文件Block数据:多节点
–DataNode与NameNode保持心跳,提交Block列表
–HdfsClient与NameNode交互元数据信息
–HdfsClient与DataNode交互文件Block数据(cs)
–DataNode 利用服务器本地文件系统存储数据块
(3)HDFS架构:
NameNode(NN):
(1)基于内存存储 :不会和磁盘发生交换(双向)
- 只存在内存中
- 持久化(单向)
(2)NameNode主要功能:接受客户端的读写服务、收集DataNode汇报的Block列表信息
(3)NameNode保存metadata信息包括:
- 文件owership和permissions
- 文件大小,时间
- (Block列表:Block偏移量),位置信息(持久化不存)
- Block每副本位置(由DataNode上报)
(4)NameNode持久化:
- NameNode的metadata信息在启动后会加载到内存
- metadata存储到磁盘文件名为”fsimage”(时点备份)
- Block的位置信息不会保存到fsimage
- edits记录对metadata的操作日志…>Redis
SecondaryNameNode(SNN):
(1)作用:它不是NN的备份(但可以做备份),它的主要工作是帮助NN合并edits log,减少NN启动时间。
(2)SNN执行合并时机:
- 根据配置文件设置的时间间隔fs.checkpoint.period 默认3600秒
- 根据配置文件设置edits log大小 fs.checkpoint.size 规定edits文件的最大值默认是64MB
DataNode(DN):
- 本地磁盘目录存储数据(Block),文件形式
- 同时存储Block的元数据信息文件
- 启动DN时会向NN汇报block信息
- 通过向NN发送心跳保持与其联系(3秒一次),如果NN 10分钟没有收到DN的心跳,则认为其已经lost,并copy其上的block到其它DN
(4)HDFS写流程
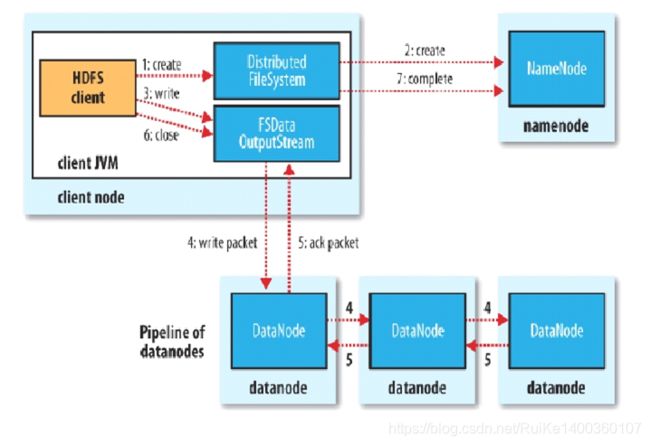
Client:切分文件Block
-->按Block线性和NN获取DN列表(副本数)
-->验证DN列表后以更小的单位流式传输数据
-->各节点,两两通信确定可用
-->Block传输结束后:
- DN向NN汇报Block信息
- DN向Client汇报完成
- Client向NN汇报完成获取下一个Block存放的DN列表.
-->最终Client汇报完成NN会在写流程更新文件状态
(5)HDFS读流程
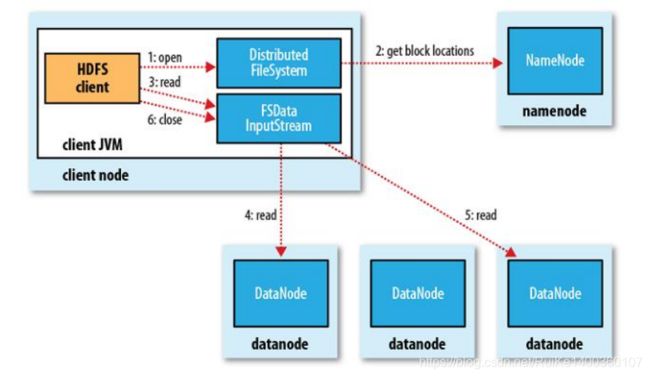
Client:
- 和NN获取一部分Block副本位置列表
- 线性和DN获取Block,最终合并为一个文件
- 在Block副本列表中按距离择优选取
- MD5验证数据完整性
二、HDFS常用命令
2.1、帮助命令
一切命令都从帮助开始,命令是记不完的,只有学会使用帮助,才能免却记忆的痛苦。
hdfs dfs -help2.2、查看命令
(1)列出文件系统目录下的目录和文件:
# -h 以更友好的方式列出,主要针对文件大小显示成相应单位K、M、G等
# -r 递归列出,类似于linux中的tree命令
hdfs dfs -ls [-h] [-r] (2)查看文件内容:
hdfs dfs -cat (3)查看文件末尾的1KB数据:
hdfs dfs -tail [-f] 2.3、创建命令
(1)新建目录:
hdfs dfs -mkdir (2)创建多级目录:
hdfs dfs -mkdir -p (3)新建一个空文件:
# linux下是touchz,不知道为什么在hdfs要加个z?
hdfs dfs -touchz (4)上传本地文件到hdfs:
# -f 如果hdfs上已经存在要上传的文件,则覆盖
hdfs dfs -put [-f] ... 举例:将/usr/local/hadoop-2.7.3/etc/hadoop下的所有配置文件都上传到hdfs的/hadoop目录:
hdfs dfs -mkdir /config
hdfs dfs -put /usr/local/hadoop-2.7.3/etc/hadoop /config2.4、删除命令
(1)删除文件或目录:
# -r 递归删除目录下的所有文件
# -f为直接删除,不予提示
# -skipTrash为彻底放入文件,不放入回收站
hdfs dfs -rm [-r] [-f] [-skipTrash] 2.5、获取命令
(1)将hdfs文件下载到本地:
hdfs dfs -get < hdfs path> < localpath>
举例:将hdfs的/config目录下载到本地的/config目录下
hdfs dfs -get /config /config(2)将hdfs文件合并起来下载到本地:
hdfs hdfs -getmerge [-nl]
举例:将hdfs的/config/hadoop目录下的所有文件合并下载到本地的config.txt中
hdfs dfs -getmerge /config/hadoop config.txt 2.6、其他hdfs文件操作命令
拷贝:hdfs dfs -cp [-r] < hdfs path > < hdfs path1 >
移动:hdfs dfs -mv < hdfs path > < hdfs path1 >
统计目录下的对象数:hdfs dfs -count < hdfs path >
统计目录下的对象大小:hdfs dfs -du [-s] [-h] < hdfs path >
修改hdfs文件权限
修改所属组[-chgrp [-R] GROUP PATH...]
修改权限模式[-chmod [-R] PATH...]
修改所需组和所有者[-chown [-R] [OWNER][:[GROUP]] PATH...] 2.7、hdfs管理命令
(1)显示帮助:
hdfs dfsadmin -help(2)查看文件系统健康状态:
显示hdfs的容量、数据块和数据节点的信息
hdfs dfsadmin -report(3)安全模式管理:
安全模式是hadoop的一种保护机制,用于保证集群中的数据块的安全性。当hdfs进入安全模式时不允许客户端进行任何修改文件的操作,包括上传文件,删除文件,重命名,创建文件夹等操作。
当集群启动的时候,会首先进入安全模式。当系统处于安全模式时会检查数据块的完整性。假设我们设置的副本数(即参数dfs.replication)是5,那么在datanode上就应该有5个副本存在,假设只存在3个副本,那么比例就是3/5=0.6。通过配置dfs.safemode.threshold.pct定义最小的副本率,默认为0.999。
1、查看安全模式状态
hdfs dfsadmin -safemode get
2、强制进入安全模式
hdfs dfsadmin -safemode enter
3、强制离开安全模式
hdfs dfsadmin -safemode leave
常用命令汇总:
1.hdfs命令行
(1)查看帮助
hdfs dfs -help
(2)查看当前目录信息
hdfs dfs -ls /
(3)上传文件
hdfs dfs -put /本地路径 /hdfs路径
(4)剪切文件
hdfs dfs -moveFromLocal a.txt /aa.txt
(5)下载文件到本地
hdfs dfs -get /hdfs路径 /本地路径
(6)合并下载
hdfs dfs -getmerge /hdfs路径文件夹 /合并后的文件
(7)创建文件夹
hdfs dfs -mkdir /hello
(8)创建多级文件夹
hdfs dfs -mkdir -p /hello/world
(9)移动hdfs文件
hdfs dfs -mv /hdfs路径 /hdfs路径
(10)复制hdfs文件
hdfs dfs -cp /hdfs路径 /hdfs路径
(11)删除hdfs文件
hdfs dfs -rm /aa.txt
(12)删除hdfs文件夹
hdfs dfs -rm -r /hello
(13)查看hdfs中的文件
hdfs dfs -cat /文件
hdfs dfs -tail -f /文件
(14)查看文件夹中有多少个文件
hdfs dfs -count /文件夹
(15)查看hdfs的总空间
hdfs dfs -df /
hdfs dfs -df -h /
(16)修改副本数
hdfs dfs -setrep 1 /a.txtZ-blog:www.361wx.com