卷积神经网络(五)-ResNet
卷积神经网络(一)-LeNet
卷积神经网络(二)-AlexNet
卷积神经网络(三)-ZF-Net和VGG-Nets
卷积神经网络(四)-GoogLeNet
卷积神经网络(五)-ResNet
卷积神经网络(六)-DenseNet
2015年何恺明推出的ResNet在ISLVRC和COCO上横扫所有选手,获得冠军。ResNet在网络结构上做了大创新,而不再是简单的堆积层数,ResNet在卷积神经网络的新思路,绝对是深度学习发展历程上里程碑式的事件。
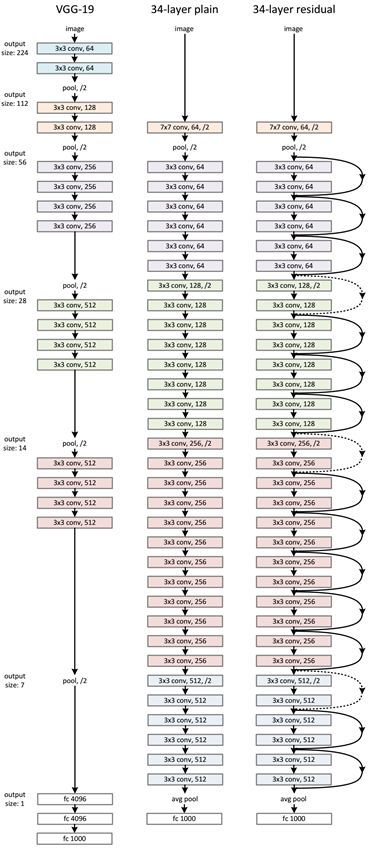
闪光点:
- 层数非常深,已经超过百层
- 引入残差单元来解决退化问题
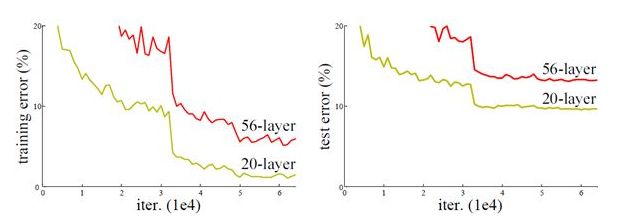
从前面可以看到,随着网络深度增加,网络的准确度应该同步增加,当然要注意过拟合问题。但是网络深度增加的一个问题在于这些增加的层是参数更新的信号,因为梯度是从后向前传播的,增加网络深度后,比较靠前的层梯度会很小。这意味着这些层基本上学习停滞了,这就是梯度消失问题。深度网络的第二个问题在于训练,当网络更深时意味着参数空间更大,优化问题变得更难,因此简单地去增加网络深度反而出现更高的训练误差,深层网络虽然收敛了,但网络却开始退化了,即增加网络层数却导致更大的误差,比如下图,一个56层的网络的性能却不如20层的性能好,这不是因为过拟合(训练集训练误差依然很高),这就是烦人的退化问题。残差网络ResNet设计一种残差模块让我们可以训练更深的网络。
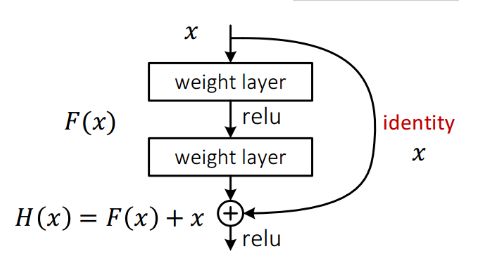
这里详细分析一下残差单元来理解ResNet的精髓。
从下图可以看出,数据经过了两条路线,一条是常规路线,另一条则是捷径(shortcut),直接实现单位映射的直接连接的路线,这有点类似与电路中的“短路”。通过实验,这种带有shortcut的结构确实可以很好地应对退化问题。我们把网络中的一个模块的输入和输出关系看作是y=H(x),那么直接通过梯度方法求H(x)就会遇到上面提到的退化问题,如果使用了这种带shortcut的结构,那么可变参数部分的优化目标就不再是H(x),若用F(x)来代表需要优化的部分的话,则H(x)=F(x)+x,也就是F(x)=H(x)-x。因为在单位映射的假设中y=x就相当于观测值,所以F(x)就对应着残差,因而叫残差网络。为啥要这样做,因为作者认为学习残差F(X)比直接学习H(X)简单!设想下,现在根据我们只需要去学习输入和输出的差值就可以了,绝对量变为相对量(H(x)-x 就是输出相对于输入变化了多少),优化起来简单很多。
考虑到x的维度与F(X)维度可能不匹配情况,需进行维度匹配。这里论文中采用两种方法解决这一问题(其实是三种,但通过实验发现第三种方法会使performance急剧下降,故不采用):
- zero_padding:对恒等层进行0填充的方式将维度补充完整。这种方法不会增加额外的参数
- projection:在恒等层采用1x1的卷积核来增加维度。这种方法会增加额外的参数
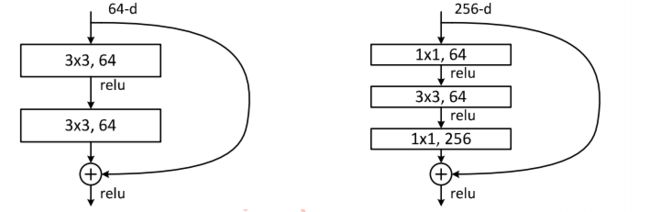
下图展示了两种形态的残差模块,左图是常规残差模块,有两个3×3卷积核卷积核组成,但是随着网络进一步加深,这种残差结构在实践中并不是十分有效。针对这问题,右图的“瓶颈残差模块”(bottleneck residual block)可以有更好的效果,它依次由1×1、3×3、1×1这三个卷积层堆积而成,这里的1×1的卷积能够起降维或升维的作用,从而令3×3的卷积可以在相对较低维度的输入上进行,以达到提高计算效率的目的。
ResNet-50的Keras实现:
def Conv2d_BN(x, nb_filter,kernel_size, strides=(1,1), padding='same',name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter,kernel_size,padding=padding,strides=strides,activation='relu',name=conv_name)(x)
x = BatchNormalization(axis=3,name=bn_name)(x)
return x
def Conv_Block(inpt,nb_filter,kernel_size,strides=(1,1), with_conv_shortcut=False):
x = Conv2d_BN(inpt,nb_filter=nb_filter[0],kernel_size=(1,1),strides=strides,padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter[1], kernel_size=(3,3), padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter[2], kernel_size=(1,1), padding='same')
if with_conv_shortcut:
shortcut = Conv2d_BN(inpt,nb_filter=nb_filter[2],strides=strides,kernel_size=kernel_size)
x = add([x,shortcut])
return x
else:
x = add([x,inpt])
return x
def ResNet50():
inpt = Input(shape=(224,224,3))
x = ZeroPadding2D((3,3))(inpt)
x = Conv2d_BN(x,nb_filter=64,kernel_size=(7,7),strides=(2,2),padding='valid')
x = MaxPooling2D(pool_size=(3,3),strides=(2,2),padding='same')(x)
x = Conv_Block(x,nb_filter=[64,64,256],kernel_size=(3,3),strides=(1,1),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[64,64,256],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[64,64,256],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3),strides=(2,2),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[128,128,512],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3),strides=(2,2),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[256,256,1024],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[512,512,2048],kernel_size=(3,3),strides=(2,2),with_conv_shortcut=True)
x = Conv_Block(x,nb_filter=[512,512,2048],kernel_size=(3,3))
x = Conv_Block(x,nb_filter=[512,512,2048],kernel_size=(3,3))
x = AveragePooling2D(pool_size=(7,7))(x)
x = Flatten()(x)
x = Dense(1000,activation='softmax')(x)
model = Model(inputs=inpt,outputs=x)
return model