29_多易教育之《yiee数据运营系统》附录:扩展知识点汇总系列二
目录
一、OLAP多维分析概念及函数
1、cube导论
2、cube核心操作
1)、cube核心操作
2)、DICE (切块)
3)、ROLL UP (上卷)
4)、DRILL DOWN (下钻)
5)、PIVOT (旋转)
二、hive 高阶聚合函数
1、with cube函数
2、grouping sets 函数
3、with rollup函数
三、with as 语法
四、经典数仓模型:拉链表介绍
五、经典数仓模型:拉链表实战
六、maven高级特性
1、maven的依赖实质
2、maven的打包、编译命令生命周期
3、maven的打包的依赖问题
七、Spark任务运行时依赖jar
八、Linux定时任务配置
九、Hive任务的脚本化
十、Shell脚本编写
1、参数传递
2、判断
3、日期获取
4、获取上一条命令的退出码
一、OLAP多维分析概念及函数
1、cube导论
数据立方体(Data Cube),是多维模型的一个形象的说法。
立方体其本身只有三维,多维模型不仅限于三维模型,可以组合更多的维度
为什么叫数据立方体?
一方面是出于更方便地解释和描述,同时也是给思维成像和想象的空间;
另一方面是为了与传统关系型数据库的二维表区别开来
下图为数据立方体的形象图
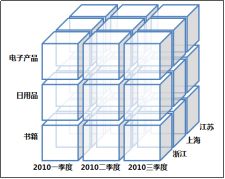
指标(衡量):销售额
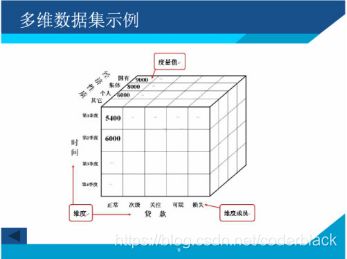
其实并不用把cube理解得很高大上,只要理解将衡量指标(事实)分别按照不同维度组合进行聚合.
hive中也有cube函数,可以实现多个任意维度的所有组合情况的统计查询
cube(a,b,c)则:
会对(a,b,c)进行group by,
然后依次是(a,b),(a,c),(a),(b,c),(b),©,
最后在对全表进行group by,
他会统计所选列中值的所有组合的聚合
用cube函数就可以完成所有维度的聚合工作.
2、cube核心操作
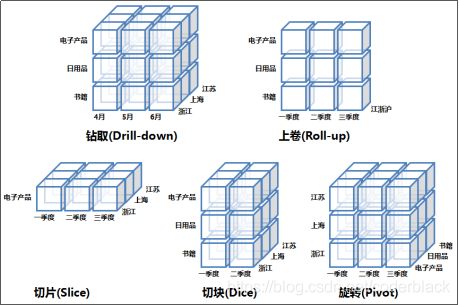
1)、cube核心操作
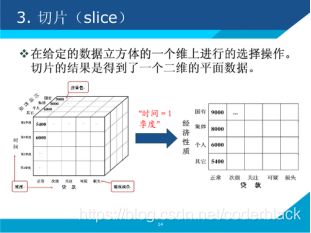
将某一个(或多个)维度上的值锁定,只观察当这个维度取这个值时的情形,相当于将一个立方体做了一个切片。
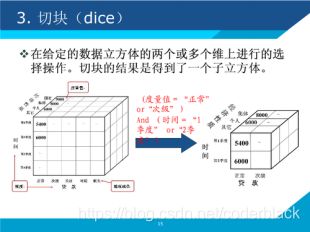
2)、DICE (切块)
将某一个(或多个)维度上的值固定在一个区间内,观察这个取值区间内cube的情形,相当于将一个立方体做了一个切块。
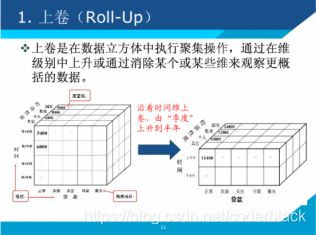
3)、ROLL UP (上卷)
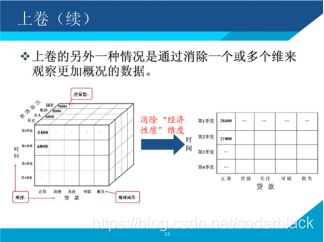
沿着某一个(或多个)维度进行聚合,观察聚合后其他维度上的汇总数据,相当于将一个立方体沿着某个维度压缩(聚合)在一起。
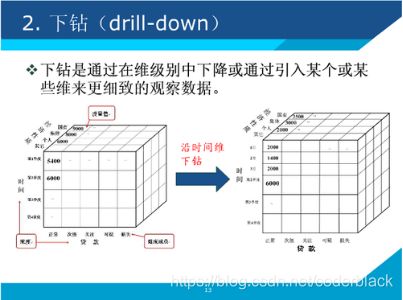
4)、DRILL DOWN (下钻)
沿着某一个(或多个)维度在更细粒度层面上进行展开,观察展开后其他维度上的对应数据,相当于将一个立方体沿着某个维度拉伸,拉伸的结果就是粒度变细,比如时间维度从季度拉伸到月。
下钻和上卷是两个相反的操作,取名上并不能很好地顾名思义,简单的解释两个操作就是:在某一个(或多个)维度上是进行更细粒度放大观察还是最粗粒度的聚合观察,就像是图片编辑工具中的
zoom in和zoom out!
5)、PIVOT (旋转)
将维度的位置互换。在二维表格中就是行变列,列变行。
二、hive 高阶聚合函数
1、with cube函数
cube简称数据魔方,可以实现hive多个任意维度的组合查询,cube(a,b,c)则首先会对(a,b,c)进行group by,然后依次是(a,b),(a,c),(a),(b,c),(b),(c),最后在对全表进行聚合,他会统计所选列中值的所有组合的聚合
cube即为grouping sets的简化过程函数
实例:
select
device_id,
os_id,
app_id,
client_version,
from_id,
count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id,client_version,from_id
with cube;
等价于:
SELECT device_id,null,null,null,null ,count(user_id) FROM test_xinyan_reg group by device_id
UNION ALL
SELECT null,os_id,null,null,null ,count(user_id) FROM test_xinyan_reg group by os_id
UNION ALL
SELECT device_id,os_id,null,null,null ,count(user_id) FROM test_xinyan_reg group by device_id,os_id
UNION ALL
SELECT null,null,app_id,null,null ,count(user_id) FROM test_xinyan_reg group by app_id
UNION ALL
SELECT device_id,null,app_id,null,null ,count(user_id) FROM test_xinyan_reg group by device_id,app_id
UNION ALL
SELECT null,os_id,app_id,null,null ,count(user_id) FROM test_xinyan_reg group by os_id,app_id
UNION ALL
SELECT device_id,os_id,app_id,null,null ,count(user_id) FROM test_xinyan_reg group by device_id,os_id,app_id
UNION ALL
SELECT null,null,null,client_version,null ,count(user_id) FROM test_xinyan_reg group by client_version
UNION ALL
SELECT device_id,null,null,client_version,null ,count(user_id) FROM test_xinyan_reg group by device_id,client_version
UNION ALL
SELECT null,os_id,null,client_version,null ,count(user_id) FROM test_xinyan_reg group by os_id,client_version
UNION ALL
SELECT device_id,os_id,null,client_version,null ,count(user_id) FROM test_xinyan_reg group by device_id,os_id,client_version
UNION ALL
SELECT null,null,app_id,client_version,null ,count(user_id) FROM test_xinyan_reg group by app_id,client_version
UNION ALL
SELECT device_id,null,app_id,client_version,null ,count(user_id) FROM test_xinyan_reg group by device_id,app_id,client_version
UNION ALL
SELECT null,os_id,app_id,client_version,null ,count(user_id) FROM test_xinyan_reg group by os_id,app_id,client_version
UNION ALL
SELECT device_id,os_id,app_id,client_version,null ,count(user_id) FROM test_xinyan_reg group by device_id,os_id,app_id,client_version
UNION ALL
SELECT null,null,null,null,from_id ,count(user_id) FROM test_xinyan_reg group by from_id
UNION ALL
SELECT device_id,null,null,null,from_id ,count(user_id) FROM test_xinyan_reg group by device_id,from_id
UNION ALL
SELECT null,os_id,null,null,from_id ,count(user_id) FROM test_xinyan_reg group by os_id,from_id
UNION ALL
SELECT device_id,os_id,null,null,from_id ,count(user_id) FROM test_xinyan_reg group by device_id,os_id,from_id
UNION ALL
SELECT null,null,app_id,null,from_id ,count(user_id) FROM test_xinyan_reg group by app_id,from_id
UNION ALL
SELECT device_id,null,app_id,null,from_id ,count(user_id) FROM test_xinyan_reg group by device_id,app_id,from_id
UNION ALL
SELECT null,os_id,app_id,null,from_id ,count(user_id) FROM test_xinyan_reg group by os_id,app_id,from_id
UNION ALL
SELECT device_id,os_id,app_id,null,from_id ,count(user_id) FROM test_xinyan_reg group by device_id,os_id,app_id,from_id
UNION ALL
SELECT null,null,null,client_version,from_id ,count(user_id) FROM test_xinyan_reg group by client_version,from_id
UNION ALL
SELECT device_id,null,null,client_version,from_id ,count(user_id) FROM test_xinyan_reg group by device_id,client_version,from_id
UNION ALL
SELECT null,os_id,null,client_version,from_id ,count(user_id) FROM test_xinyan_reg group by os_id,client_version,from_id
UNION ALL
SELECT device_id,os_id,null,client_version,from_id ,count(user_id) FROM test_xinyan_reg group by device_id,os_id,client_version,from_id
UNION ALL
SELECT null,null,app_id,client_version,from_id ,count(user_id) FROM test_xinyan_reg group by app_id,client_version,from_id
UNION ALL
SELECT device_id,null,app_id,client_version,from_id ,count(user_id) FROM test_xinyan_reg group by device_id,app_id,client_version,from_id
UNION ALL
SELECT null,os_id,app_id,client_version,from_id ,count(user_id) FROM test_xinyan_reg group by os_id,app_id,client_version,from_id
UNION ALL
SELECT device_id,os_id,app_id,client_version,from_id ,count(user_id) FROM test_xinyan_reg group by device_id,os_id,app_id,client_version,from_id
UNION ALL
SELECT null,null,null,null,null ,count(user_id) FROM test_xinyan_reg
2、grouping sets 函数
自由指定要计算的“维度组合”!
| grouping sets语句 | 等价hive |
|---|---|
| select device_id,os_id,app_id,count(user_id) from test_xinyan_reg group by device_id,os_id,app_id grouping sets((device_id)) |
SELECT device_id,null,null,count(user_id) FROM test_xinyan_reg group by device_id |
| select device_id,os_id,app_id,count(user_id) from test_xinyan_reg group by device_id,os_id,app_id grouping sets((device_id,os_id)) |
SELECT device_id,os_id,null,count(user_id) FROM test_xinyan_reg group by device_id,os_id |
| select device_id,os_id,app_id,count(user_id) from test_xinyan_reg group by device_id,os_id,app_id grouping sets((device_id,os_id),(device_id)) |
SELECT device_id,os_id,null,count(user_id) FROM test_xinyan_reg group by device_id,os_id UNION ALL SELECT device_id,null,null,count(user_id) FROM test_xinyan_reg group by device_id |
| select device_id,os_id,app_id,count(user_id) from test_xinyan_reg group by device_id,os_id,app_id grouping sets((device_id),(os_id),(device_id,os_id),()) |
SELECT device_id,null,null,count(user_id) FROM test_xinyan_reg group by device_id UNION ALL SELECT null,os_id,null,count(user_id) FROM test_xinyan_reg group by os_id UNION ALL SELECT device_id,os_id,null,count(user_id) FROM test_xinyan_reg group by device_id,os_id UNION ALL SELECT null,null,null,count(user_id) FROM test_xinyan_reg |
3、with rollup函数
Rollup可以实现将维度key从右到左递减多级的统计,显示统计某一层次结构的聚合。
非常适合于,维度之间不太适合自由组合,而是存在某种级联关系,如:
国家 省 市 区(县) 街道
它的有意义分析组合:
国 省 市 区 街
国 省 市 区
国 省 市
国 省
国
null
select
…
国,省,市,区,街
group by 国,省,市,区,街
with rollup;
==> 等价于
select
聚合运算,
国,省,市,区,街
group by 国,省,市,区,街
grouping sets((国,省,市,区,街),(国,省,市,区),(国,省,市),(国,省),(国),())
实例:`
select device_id,os_id,app_id,client_version,from_id,count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id,client_version,from_id
with rollup;
等价于:
select device_id,os_id,app_id,client_version,from_id,count(user_id)
from test_xinyan_reg
group by device_id,os_id,app_id,client_version,from_id
grouping sets ((device_id,os_id,app_id,client_version,from_id),
(device_id,os_id,app_id,client_version),(device_id,os_id,app_id),(device_id,os_id),(device_id),());
三、with as 语法
with as语法可以将一个子查询注册为一个临时表,拥有表名
这样,后续的逻辑中,如果需要反复使用这个表数据,就可以通过临时表的表名来指定
with
tmp1 as (select * from t_1 where x=8),
tmp2 as (select x,y,f,…… from t_2 where …… group by …. )
select …… from tmp1 where ……
union
select ……. from tmp2 where ……
四、经典数仓模型:拉链表介绍
拉链表是一种数据模型,需求背景:
- 数据量比较大;
- 表中的部分字段会被update,如用户的地址,产品的描述信息,订单的状态等等;
- 需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态,
比如,查看某一个用户在过去某一段时间内,更新过几次等等; - 变化的比例和频率不是很大,比如,总共有1000万的会员,每天新增和发生变化的有10万左右;
- 如果对这边表每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费;
拉链历史表,既能满足反应数据的历史状态,又可以最大程度的节省存储;
举个简单例子,比如有一张订单表,6月20号有3条记录:

到6月21日,表中有5条记录:

到6月22日,表中有6条记录:
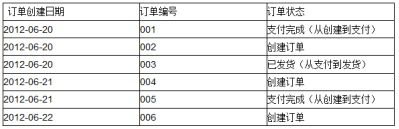
数据仓库中对该表的保留方法:
- 只保留一份全量,则数据和6月22日的记录一样,如果需要查看6月21日订单001的状态,则无法满足;
- 每天都保留一份全量,则数据仓库中的该表共有14条记录,但好多记录都是重复保存,没有任务变化,如订单002,004,数据量大了,会造成很大的存储浪费;
如果在数据仓库中设计成历史拉链表保存该表,则会有下面这样一张表:
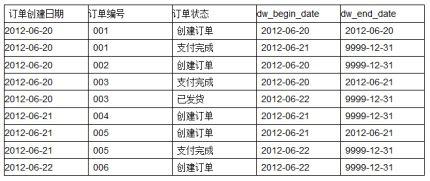
说明:
3. dw_begin_date表示该条记录的生命周期开始时间,dw_end_date表示该条记录的生命周期结束时间;
4. dw_end_date = '9999-12-31’表示该条记录目前处于有效状态;
5. 如果查询当前所有有效的记录,则select * from order_his where dw_end_date = ‘9999-12-31’
6. 如果查询2012-06-21的历史快照,则select * from order_his where dw_begin_date <= ‘2012-06-21’ and end_date >= ‘2012-06-21’,这条语句会查询到以下记录:
. 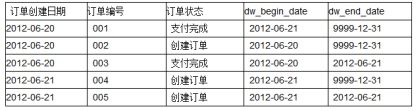
和源表在6月21日的记录完全一致:
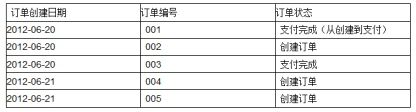
可以看出,这样的历史拉链表,既能满足对历史数据的查询需求,又能很大程度的节省存储资源;
拉链表的关键意义: 既保存了所有数据的变化过程,又比较节省空间!
五、经典数仓模型:拉链表实战
《详见: 38号sql文件》
六、maven高级特性
1、maven的依赖实质
需求:spark的预处理程序,打成jar包
基本概念:maven依赖的实质

本质上就是把一个jar包引入了工程的classpath(lib)
maven(程序)会跟pom中写的上述这种 GAV坐标去本地库寻找这个jar包,如果找不到,去maven官方的中央仓库去下载这个jar到本地库,然后把本地库的jar路径添加到工程的classpath;
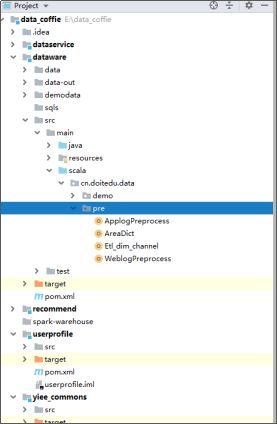
上例是引入了一个“别人”的依赖jar,那么,我们如果引用自己开发的jar包呢?
比如:假如在yiee_dataware工程中引入了一个我们自己的yiee_commons
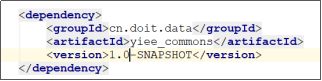
本质上,maven也是要去本地仓库找这个GAV所描述的jar,只是肯定找不到,它会在maven中央仓库去下载,肯定也下载不到!
那么对yiee_dataware打包时就会缺失 yiee_commons这个jar包
如何解决?
先对yiee_commons打jar包,而且要安装到maven的本地库
====》 这个操作只要一条maven的命令即可: install
2、maven的打包、编译命令生命周期
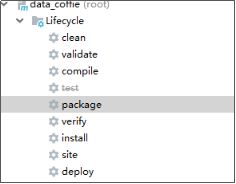
Clean : 清除之前编译、打包的结果文件(target目录)
Compile: 编译(java、scala代码变成 .class 文件)
Test : 运行项目中的test测试代码
Package: 打包
Install : 安装到本地库(中央仓库)
Site : 生成doc网站
Deploy: 将项目部署到运行环境中
这里面,每一个命令的生命周期都包含它的前置环节!
3、maven的打包的依赖问题
Maven打包,默认是不会把工程的依赖jar打出来的
如果需要把依赖jar跟我们自己的代码都打出来,则需要配置maven的插件
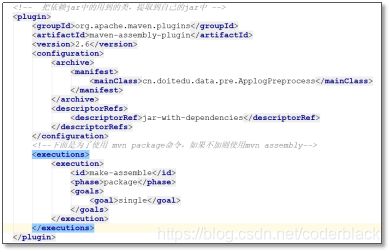
这个插件会把工程打成 fatjar(依赖和自己的代码都在结果jar中)
七、Spark任务运行时依赖jar
可以通过 --jars 添加依赖到executor的运行时环境中
还可以通过 --driver-class-path 添加依赖到driver的运行时环境中
当然,最省事的办法: 把需要的依赖都打进自己的程序jar中
命令模板示例:
bin/spark-submit \
--class cn.doitedu.data.pre.ApplogPreprocess \
--master yarn \
--deploy-mode client \
--num-executors 3 \
--executor-memory 2g \
--executor-cores 2 \
--driver-memory 2g \
--driver-cores 1 \
--jars hdfs://h1:8020/jars/mysql-connector-java-5.1.48.jar \
--driver-class-path /root/mysql-connector-java-5.1.48.jar \
/root/dw.jar /flumedata/applog/2019-10-28 /preout/applog/2019-10-28 /toparsegps/2019-10-28 jdbc:mysql://h3:3306/dicts root haitao.211123 yarn
八、Linux定时任务配置
Linux中有一个功能模块叫crond,它是一个定时调度服务,它会按照用户配置的方案,定时帮用户去启动一个程序(脚本)
crond(通常称呼为crontab)的配置方法:
crontab -e 编辑定时配置
crontab –e
0 1 * * * /root/bin/a.sh
0 2 * * * /root/bin/b.sh
0 3 * * * /root/bin/c.sh
0 4 * * * /root/bin/d.sh
这将会在每天早上1点运行 /root/bin/a.sh
这将会在每天早上2点运行 /root/bin/b.sh
以下是 crontab 配置文件的格式:
{minute} {hour} {day-of-month} {month} {day-of-week} {full-path-to-shell-script}
每个时间占位,可以给一个具体的值,比如在“时”占位上给一个值1,就代表1点
每个时间占位,可以给一个区间,比如在“时”占位上给 1-5,就代表1点到5点之间的每一点
区间还可以组合 1-5,8-10
每个时间占位,可以给一个频次,比如在“分”占位上给 */5,代表 每隔5分钟执行一次
分minute: 区间为 0 – 59
时hour: 区间为0 – 23
日day-of-month: 区间为0 – 31
月month: 区间为1 – 12; 1 是1月,12是12月.
周Day-of-week: 区间为0 – 7; 周日可以是0或7.
Crontab配置示例
1.在 12:01 a.m 运行,即每天凌晨过一分钟。
这是一个恰当的进行备份的时间,因为此时系统负载不大。
1 0 * * * /root/bin/backup.sh
2.每个工作日(Mon – Fri) 11:59 a.m 都进行备份作业。
59 11 * * 1,2,3,4,5 /root/bin/backup.sh
下面例子与上面的例子效果一样:
59 11 * * 1-5 /root/bin/backup.sh
3 每5分钟运行一次命令
*/5 * * * * /root/bin/check-status.sh
4.每个月的第一天 1:10 p.m 运行
10 13 1 * * /root/bin/full-backup.sh
5.每个工作日 11 p.m 运行。
0 23 * * 1-5 /root/bin/incremental-backup.sh
Crontab 命令选项
以下是 crontab 的有效选项:
crontab –e : 修改 crontab 配置文件,如果文件不存在会自动创建。
crontab –l : 显示 crontab 配置文件中配置的定时任务。
crontab -r : 删除 crontab 配置文件。
crontab -ir : 删除 crontab 文件前提醒用户。
九、Hive任务的脚本化
Hive可以在交互式界面中以交互方式运行sql;
也可以用一次性命令的方式来运行sql;
方式1:
hive -e “select * from yiee_dw.ods_apl_dtl”
方式2:
编辑一个sql语句的文件,如 vi /root/x.sql
然后: hive -f /root/x.sql
十、Shell脚本编写
《详见项目代码》
1、参数传递
脚本如何传参数
bin/my.sh param1 param2 paramn
内部如何获取参数
P1=$1
P1=$2
P1=$3
2、判断
判断一个变量是否为空
if [ $a ]
then
…
else
…
fi
判断一个变量是否满足某算术比较
if [ $a -gt 1 ] 大于
if [ $a -ge 1 ] 大于等于
if [ $a -lt 1 ] 小于
if [ $a -le 1 ] 小于等于
if [ $a -eq 1 ] 等于
3、日期获取
date -d”-1 day” +%Y-%m-%d
将一个命令的结果赋值给一个变量
DT=date -d”-1 day” +%Y-%m-%d
4、获取上一条命令的退出码
经常用于判断上一条命令执行是否成功;
$? 这个变量就代表上一条命令的退出码