DRBD+HeartBeat架构实验
HeartBeat模块
CRM:(Cluster Resource Manager)集群的大脑,根据heartbeart收集回来的节点状态交给CCM模块来更新集群的member ship,并指挥LRM对节点资源进行“启动”,“停止”,总之就是决定资源最终应该在那个节点上运行。
LRM:(Local Resource Manger)操作和管理资源的模块,负责对资源监控,启动,停止。三个资源脚本存放路径
heartbeat: /etc/ha.d/resoruce.d
ocf : /usr/lib/resource.d/heartbeat
lsb: /etc/init.d
CIB:收集资源的原始信息以及不断更新资源的状态变化,保存在cib.xml。相当于cluster.conf文件,即集群配置文件。
CCM:保持各节点之间的成员关系,heatbeat仅仅是一个通信工具,而CCM让所有节点组成了一个集群。
HeartBeat配置文件
keeplived 2 多长时间广播一次心跳
warntime 10 10秒内备用节点接受不到主节点的心跳,就向日志写一次警告,但不会发生资源切换。
deadtime 30 30秒内接收不到主节点的心跳,就判定主节点死亡,备用节点立即接管主节点资源。
initdead 120 主节点因故障重启,重启时间较长。
udpport 694 使用广播心跳的端口
ucast eth1 指定心跳网卡
auto_failback on 当主机服务器恢复正常,资源从备用节点上自动切回
node node1 设置主机名,通过uname命令查看
node node2
DRBD
Distributed Replicated Block Device(DRBD)是一种基于软件的,无共享,复制的存储解决方案,在服务器之间的对块设备(硬盘,分区,逻辑卷等)进行镜像。DRBD工作在内核 当中的,类似于一种驱动模块。DRBD相当于一个RAID1功能的存储。当本地系统出现故障时,远程主机上还会保留有一份相同的数据,可以继续使用。DRBD的架构如下图
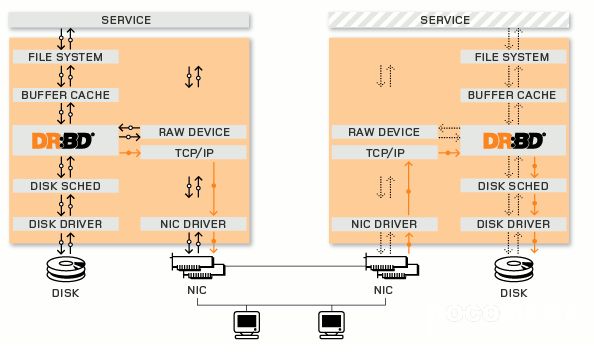
实验
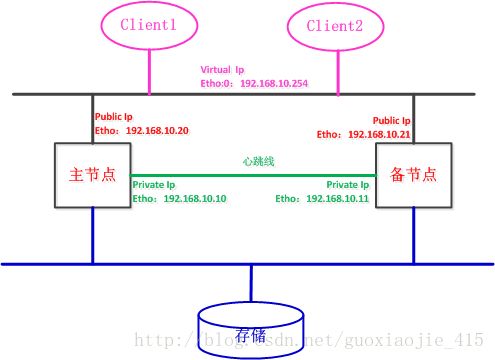
主机名称:HaMater和HaBack
HaMaster eth0:192.168.10.20
HaBack eth0: 192.168.10.21
HaMaster eth1: 192.168.10.10
HaBack eth1: 192.168.10.20
安装heartbeat yum install -y heartbeat
实验架构图如下
下载和安装DRBD(在HaMaster和HaBack上执行)
http://oss.linbit.com/drbd/
tar zxvf drbd-8.4.3.tar.gz
cd drbd-8.4.3
./configure --prefix=/usr/local/drbd --with-km
make KDIR=/usr/src/kernels/`uname -r`/(指定内核所在的绝对路径)
mkdir -p /usr/local/drbd/var/run/drbd/
cp /usr/local/drbd/etc/rc.d/init.d/drbd /etc/rc.d/init.d/
chkconfig --add drbd
chkconfig drbd on
安装DRDB模块(在HaMaster和HaBack上执行)
进入DRBD的解压目录的drbd中,cd /root/software/drbd-8.4.3/drbd
make clean
make KDIR=/usr/src/kernels/`uname -r`/
cp drbd.ko /lib/modules/`uname -r`/kernel/lib/
depmod
添加存储(实验对的存储为/dev/sdb1,在HaMaster和HaBack上执行)
fdisk /dev/sdb(进行分区)
fdisk -l 查看分区
配置DRBD(在HaMaster和HaBack上执行)
① DRBD主配置文件
/usr/local/drbd/etc/drbd.conf,该文件中包含一个全局配置文件和所有的资源文件,内容如下
include "drbd.d/global_common.conf";
include "drbd.d/*.res";② 修改global_common.conf文件,在net处添加上protocol C;
/usr/local/drbd/etc/drbd.d/global_common.conf

③ 添加资源文件,新建资源r0,命名为 r0.res,内容如下
resource r0{
on HaMaster{
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.10.20:7789;
meta-disk internal;
}
on HaBack{
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.10.21:7789;
meta-disk internal;
}
}④ 加载DRDB模块
modprobe drbd
查看 lsmod | grep drbd
(为什么执行下面一个步骤,不太清楚)
dd if=/dev/zero of=/dev/sdb1 bs=1M count=100
创建资源 r0:drbdadm create-md r0
启动资源:drbdadn up 0
启动服务:/etc/init.d/drbd start
⑤ 主从节点状态查看和主从节点设置
查看节点drbd状态:cat /proc/drbd
设置主节点:drbdadm primary --force r0
设置从节点:drbdadm secondary r0
⑥ 格式化drbd,并挂载
mkfs.ext3 /dev/drbd0
mkdir /db
mount /dev/drbd0 /db
⑦ 测试
手动切换主从节点,通过cat /proc/drbd查看

安装和配置HeartBeat(在HaMaster和HaBack上执行)
① 安装: yum -y install heartbeat
② 从安装路径下复制模板文件
cd /usr/share/doc/heartbeat-2.1.3
cp ha.cf authkeys haresources /etc/ha.d/
③ 配置 ha.cf
logfile /var/log/ha-log
keepalive 2
deadtime 30
warntime 10
initdead 120
udpport 694
ucast eth1 192.168.10.10(对方心跳网卡IP)
node HaMaster
node HaBack
④ 配置 authkeys
auth 1
1 crc⑤ 配置 haresources
HaMaster drbddisk::r0 Filesystem::/dev/drbd0::/db::ext3 mysqld测试
启动DRBD:service drbd start (HaMaster和HaBack)
启动heartbeat:service heartbeat(HaMaster和HaBack)
使用 tail -f /var/log/messages查看服务启动日志
使用 mount查看硬盘是否在HaMaster上挂载,而位在HaBack上挂载
使用 /etc/init.d/mysqld 查看mysql是否启动。
停止HaMaster上的heartbeat,查看资源是否能被HaBack全部接管
重新启动HaMaster上的heartbeat,查看资源能从HaBack上接管回来。
参考
1. 博客:http://czmmiao.iteye.com/blog/1773079
2. 51CTO视频:http://edu.51cto.com/course/course_id-2.html