Redis学习_第六章(Redis面试、进阶知识点)
目录
1:redis的数据类型和使用特点
2:redis实现分布式锁
3:如何保证redis的数据都是热点数据
4:redis数据的过期策略(懒汉模式和定期模式100毫秒)
5:redis的缓存穿透(一个key的并发数据库大量查询)
5.1:什么是缓存穿透
5.2:怎么解决缓存穿透
6:redis缓存雪崩(大量key失效的数据库大量查询)
6.1:什么是缓存雪崩
6.2:怎么解决雪崩
7:缓存击穿(大并发下才有,几率小)
7.1:什么是缓存击穿
7.2:怎么解决缓存击穿
8:缓存预热
8.1:什么是缓存预热
9:redis的线程模型
10:数据持久化
10.1:RDB方式
10.2:AOF方式
10.3:RDB和AOF对比
1:redis的数据类型和使用特点
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | --- |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除,查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 2、带权重的消息队列 |
| HyperLogLog |
每个 HyperLogLog 键只需要花费 12 KB 内存, 就可以计算接近 2^64 个不同元素的基 数。
这和计算基数时,
元素越多耗费内存就越多的集合形成鲜明对比。 |
key的大小固定,但是可以存储超过2的32次方的value。 牺牲精准性来提升性能和空间。 |
1、网站每日访问量 |
setnx("key","value")方法
如果key的值不存在,就是赋值,否则直接返回。不存在返回1,存在返回0
使用案例:多线程执行定时任务的时候,判断key的状态,如果存在就返回,不执行,否则某一个线程抢到直接执行
boolean setnx1= redisTemplate.opsForValue().setIfAbsent("setnx","true",10,TimeUnit.SECONDS);
3:如何保证redis的数据都是热点数据
1:(常用的数据不断加大淘汰时间)保证热点数据的数据生存日期不断更新,比如用户登陆信息,只要访问网站(命中一次)就把redis中的用户信息生存时间在当前时间的基础上累计一段时间,那么不是热点的数据,自然过期时间提前,就容易给回收,从而腾出内存空间
2:(优化存储结构)比如最近一个月用户最近登陆,用zset存储数据,每次有新用户就zadd一次,同时修改用户的分值,从而分值就是最近的登陆时间。
3:(设置数据过期策略)设置redis中的数据回收策略,当数据在到达内存的最大容量的时候,redis提供6中数据淘汰策略
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止插入数据,报错
4:redis数据的过期策略(懒汉模式和定期模式100毫秒)
redis数据的回收策略
1:定时删除(大量过期会消耗CPU资源,会创建定时器)
redis中的key存在的过期时间,每个key都有一个计时器,到了时间自动删除
2:懒汉删除(弊病是存在大量过期数据占用内存)
redis中的key存在的过期时间,到了时间不会自动删除,等待下次get的时候,先查看是否过期,然后在删除,
3:定期删除(两者的优缺点都有,100毫秒触发一次,配置文件的HZ属性设置)
redis中的key存在的过期时间,到了时间不会自动删除,redis每隔一段时间扫描key然后删除数据。
5:redis的缓存穿透(一个key的并发数据库大量查询)
5.1:什么是缓存穿透
缓存穿透的,大量的用户查询在redis中的数据,但是redis中的数据不存在,就会查询到数据库,导致数据库压力飙升,影响效率。
实际案例:春运抢票,很多人抢一趟车,但是这趟车没有票了,所以redis中的票务数据不存在,查询就会命中到数据库,造成压力暴增。
5.2:怎么解决缓存穿透
1:布隆过滤器(不存在就一定不存在,存在的不一定存在)
1.1:什么是布隆过滤器
本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
1.2:布隆过滤器数据结构
bit数组和哈希函数是布隆过滤器的核心要素。
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样:
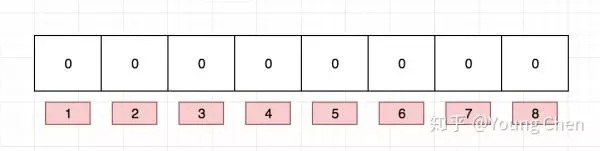
image
如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:

image
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:

值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
总结:存在的不一定存在,因为有哈希冲突,不存在的则一定不存在
1.3:布隆过滤器用法
1.3.1:导入谷歌的jar
com.google.guava
guava
1.3.2:定义布隆filter
package com.thit.util;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnel;
import com.google.common.hash.Funnels;
import com.thit.dao.OrderMapper;
import com.thit.entity.Order;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.util.List;
import java.util.Properties;
/**
* @author :huyiju
* @date :2020-06-12 17:23
*/
@Component
public class BloomFilters {
@Autowired
OrderMapper orderMapper;
BloomFilter bf;
/**
* 创建布隆过滤器
*
* @PostConstruct:程序启动时候加载此方法
*/
// @PostConstruct
// public void initBloomFilter() {
// List list= orderMapper.selectAll();
// System.out.println("======布隆过滤器缓存数据长度======:"+list.size());
//
//
// //创建布隆过滤器(默认3%误差)
// bf = BloomFilter.create(Funnels.integerFunnel(), list.size());
// for (Order order : list) {
// bf.put(order.getOrder_id());
// }
// }
@Bean
public BloomFilter bloomFilter() {
BloomFilter bf = BloomFilter.create(Funnels.integerFunnel(), 1000,0.00001);
return bf;
}
// @Bean
// public BloomFilterHelper initBloomFilterHelper() {
// return new BloomFilterHelper<>((Funnel) (from, into) -> into.putString(from, Charsets.UTF_8)
// .putString(from, Charsets.UTF_8), 1000000, 0.01);
// }
/**
* 判断id可能存在于布隆过滤器里面
*
* @param id
* @return
*/
public boolean userIdExists(int id) {
return bf.mightContain(id);
}
}
1.3.3:在代码中首先将所有的id都放进filter,然后在代码中判断布隆过滤器中的id是否存在
//1:首先将所有的id使用put方法放到布隆中
@Override
public Order selectAll() {
//1:查询全部 将数据存储到布隆过滤器
List list=orderMapper.selectAll();
System.out.println("查询数据长度:"+list.size());
for (Order order : list) {
bloomFilter.put(order.getOrder_id());
}
return null;
}
@Autowired
BloomFilter bloomFilter;
@Override
//2:通过id验证布隆过滤器,使用mightContain
public void selectid(int id) {
boolean a=bloomFilter.mightContain(id);
System.out.println("布隆过滤器是否存在"+id+":"+a);
//如果是false
if (a==false){
//false 布隆过滤器 不存在这个id 拦截不能查询 redis和数据库
}else {
// true 布隆过滤器 存在这个id 通过可以查询
}
}
2:暴力空值缓存(redis中的该辆车次数据不存在的时候查询数据库,数据库没有车票,我们就把0的值缓存到redis,设置过期时间为1分钟,其他的查询就会查到redis中不会再次查询数据库,不过依然显示没有车票)
//1:查询redis
String result=jedis.get("缓存穿透key");
if (result==null){
//2:查询数据库
result="数据库查询的值";
//3:数据库存在数据
if (result!=null){//数据库存在数据,设置redis 直接返回
jedis.set("缓存穿透key",result);
jedis.expire("缓存穿透key","合适的时间")
return result;
}else {
//4:数据库不存在数据,但是依然存到redis中
jedis.get("缓存穿透key","数据库在不存数据");
jedis.expire("缓存穿透key","短暂的时间")
return null;
}
}6:redis缓存雪崩(大量key失效的数据库大量查询)
6.1:什么是缓存雪崩
缓存雪崩的意思是在一个时间段大量的key失效,导致cpu集中回收这是失效的key,从而导致了大量key的查询落到了数据库。
实际案例:在双十一的时候会,有大量的秒杀商品会缓存到redis中,24小时失效,过了双十一,大量的key失效。用户的数据失效,查询就会落到数据上,造成大量波峰,系统压力大卡顿。
6.2:怎么解决雪崩
1:随机缓存时间,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。后者是热点商品和非热点商品采取不同的缓存失效时间。
jedis.expire("key","随机过期时间")
7:缓存击穿(大并发下才有,几率小)
7.1:什么是缓存击穿
缓存击穿,是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
7.2:怎么解决缓存击穿
互斥锁实现
String value=jedis.get("热点key");
if (value==null){//代表缓存过期
if(jedis.setnx("锁","1")==1){//加互斥锁
value="查询数据库返回值";//次数查询数据库
jedis.set("热点key","查询数据库返回值");//赋值到热点key
jedis.del("锁");//删除互斥锁
}else {
//这个时候代表已经再次把数据缓存到redis中了
value=jedis.get("热点key");
}
return value;
}8:缓存预热
8.1:什么是缓存预热
就是将热点数据缓存到数据库,比如电商的秒杀,系统有秒杀商品管理页面,通过添加秒杀商品的形式将商品库存信息添加到redis中,实现缓存预热。
9:redis的线程模型

epoll模型的IO多路复用
10:数据持久化
redis数据保存在电脑的内存中,当电脑断电、死机的时候。数据怎么保证不丢失,重启之后怎么保证数据存在,redis提供了两种数据持久化的策略。
10.1:RDB方式
在redis.conf配置文件中可见一下配置信息,rdb是定时保存,可能会丢失一个时间间隔的信息。通过save命令可以在文件下看到最新保存的dump.rdb文件
#在下面的示例中,行为将是保存:
#900秒(15分钟)后,如果至少更换了一个钥匙
#300秒(5分钟)后,如果至少10个键发生变化
#60秒后,如果至少10000个密钥更改
#默认保存文件名字
dbfilename "dump.rdb"
#默认保存文件地址
dir "/Users/huyiju/work/redis/z-redis-5.0.7/src"
10.2:AOF方式
把操作命令追加到日志的底部。保留所有的操作记录。
想比较与rdb的方式,数据完整,故障数据丢失少。可以对历史操作进行处理
#Append Only文件是另一种持久性模式,它提供
#更耐用。例如,使用默认的数据fsync策略
#(请参阅后面的配置文件)Redis在
#戏剧性的事件,比如服务器断电,或者如果发生了什么事情
#Redis进程本身会出错,但操作系统是
#仍然正常运行。
##可以同时启用AOF和RDB持久性,而不会出现问题。
#如果在启动时启用了AOF,Redis将加载AOF,即文件
#有更好的耐久性保证。
appendonly yes
#默认文件名字
appendfilename "appendonly.aof"
#每秒同步一次
appendfsync everysecaof缺点:
1:aof会把所有的操作拼接到文件中,导致文件过大,数据故障回复比较慢。
10.3:RDB和AOF对比
Redis崩溃后,重启redis会自动找备份恢复文件,下图大致描述了redis重启后的过程。

总结:
在实际应用中,根据场景不同,选择的方式也不尽相同,各有优缺点。但我个人看法,RDB的快照方式相比于AOF的逐步记录模式要好一些。至于RDB丢数据的风险,我们完全可以通过控制备份的时间间隔来避免这个问题。当然,也是可以两种方式同时使用的,只是大多不会这么做。