带你揭开JVM的神秘面纱
JVM学习文档
引言
1.什么是JVM?
2.学习JVM有什么用呢?
3.常见的JVM有哪些?
4.学习线路
JVM介绍
定义:Java Virtual Machine = java 程序的运行环境 ( java二进制字节码的运行环境 )。 JVM是一套规范,由不同的厂商实现。
好处:
1.使得java程序可以一次编写,到处运行,Java虚拟机从软件层面屏蔽了不同操作系统之间的底层差异。
2.提供了自动内存管理机制,垃圾回收功能。
3.数组下标越界检查。
4.多态机制的实现。
比较:
面试题:jvm、jdk、jre 三者之间的关系? 包含关系。
jdk = jvm + 基础类库+编译工具
jre = jvm + 基础类库
学习JVM有什么用?
1.面试。
2.理解底层的实现原理。(更好理解:自动拆装箱、动态代理的原理。)
3.中高级程序员的必备既能!
常见的JVM:
此次学习以HotSpot vm 为准。
学习线路图
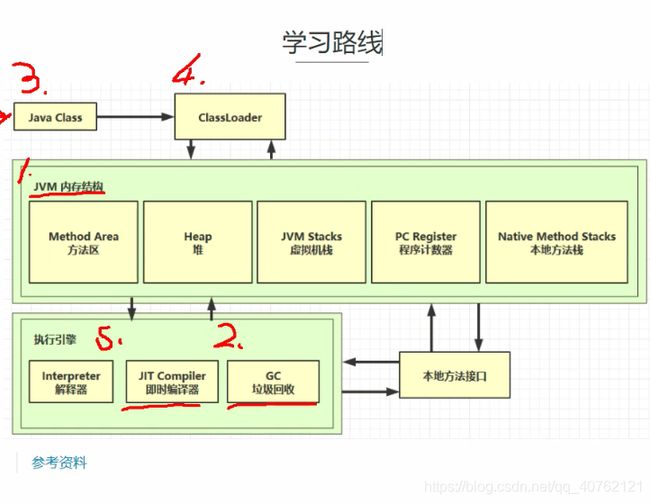
一、JVM内存结构
1.程序计数器
1.1 作用
记住下一条JVM指令的执行地址。
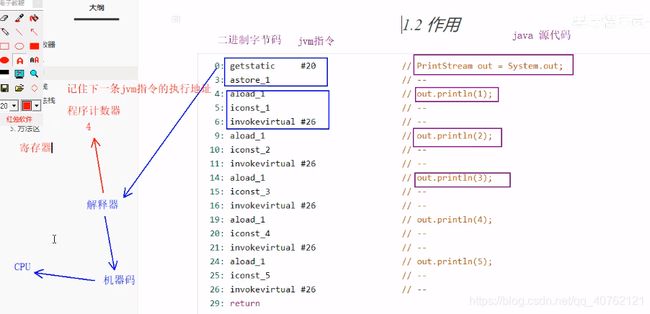
1.2 特点
1.是线程私有的。每一个线程都会有一个程序计数器。
2.唯一一个不会存在内存溢出结构。
2.虚拟机栈
2.1 定义
每一条线程运行时需要的总内存空间,称为虚拟机栈。也称为 线程栈。
2.2 特点
一个线程栈由多个【栈帧】组成。当需要调用方法时,线程栈会为该方法开辟一块栈帧空间,方法执行完后栈帧弹栈并释放栈帧内存。
栈帧:每个方法运行时需要的内存。
活动栈帧:指的就是正在执行的那个方法。
2.3 问题辨析
1.垃圾回收是否涉及栈内存?
不涉及,线程栈内存仅涉及到方法的一次次的调用与释放。
2.栈内存分配越大越好吗?
栈内存分配越大,线程数就会变少。
3.方法内的局部变量是否线程安全?
如果方法内的局部变量没有逃离方法的作用范围,是线程安全的。
如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全问题。
2.4 栈内存溢出问题
栈内存溢出异常:java.lang.StackOverflowError
原因:
1.栈帧过多导致栈内存溢出。如:递归调用。
2.栈帧过大导致栈内存溢出。
2.5 线程运行诊断
案例1: CPU占用过多
定位:(Linux环境下)
1.用top定位那个进程对cpu的占用过高
2.ps H -eo pid,tid,%cpu | grep +进程id (用ps命令进一步定位是那个线程引起的cpu占用过高)
3.使用jdk自带工具 jstack + 进程id
可以根据线程id找到有问题的线程,进一步定位到问题代码的源代码行号。
案例2: 迟迟得不到结果。 考虑 线程死锁
3.本地方法栈
3.1 定义
jvm在调用本地方法时为本地方法提供的内存空间。
指的就是那些不是由Java代码编写的方法。底层与操作系统打交道的是 c/c++ 如:clone()、notify()方法等。
4.堆内存
4.1 定义
通过new关键字创建的对象,都会使用堆内存。
4.2 特点
1.是线程共享的内存区域,堆中的对象都要考虑线程安全的问题。
2.有垃圾回收机制。
4.3 堆内存溢出
java.lang.OutOfMemoryError Java heap space
4.4 堆内存诊断
1.jps 工具
查看当前系统中存在哪些Java进程
2.jmap 工具 使用:jmap + -heap + 进程id
查看当前线程堆内存占用情况。
3.jconsole 工具
图形界面的,多功能的检测工具,可以连续监测。
案例:
垃圾回收后,内存占用仍然很高,怎么查看并排除?【有实际价值】
解决方法:
使用更实用的jdk官方工具: jvirsualvm 内存占用可视化工具--使用 堆dump 將占用情况抓取下来分析。
5.方法区
5.1 定义
方法区是线程共享的一块区域,存储的是与类结构相关的如常量池等,还包括在类、实例、接口初始化时用到的特殊方法。在虚拟机启动时被创建,逻辑上是属于堆内存的一部分,但是在具体实现上不同虚拟机的厂商不一定遵从jvm逻辑规范,实现方式有所不同。
方法区的内存结构变化图
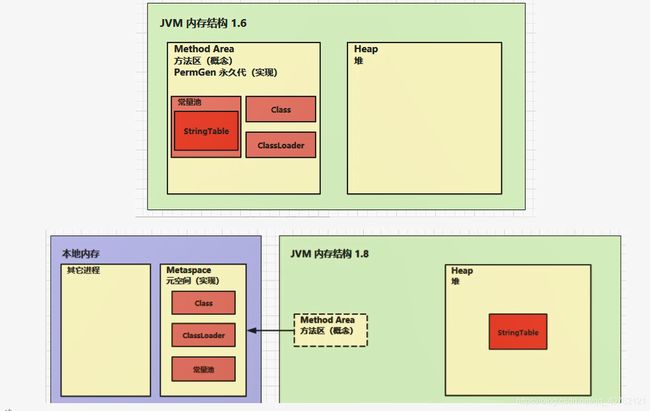
5.2 特点
1.线程共享
2.方法区中存储的是与类相关的一些信息,如:成员变量,成员方法,构造方法、运行时常量池等。
3.由虚拟机启动时创建,逻辑上是堆内存的一部分。
4.jdk 1.8之前 被称为永久代,属于堆内存的一部分。1.8之后,被称为元空间,使用的是本地内存(使用操作系统的内存)。
5.3 方法区的内存溢出
实际场景:框架中使用Cglib来动态生成并加载代理类,很容易产生永久代内存溢出。如: spring、 Mybatis
5.4 常量池
5.4.1 定义
常量池是 *.class中的概念,本质就是一张表,虚拟机指令根据符号地址从这张常量表找到要执行的类名、方法名、参数类型、字面值常量等信息。
5.4.2 作用
给JVM指令提供一些常量符号,虚拟机执行引擎中的解释器会根据符号找到对应的信息。
5.4.3 常量池与StringTable的关系
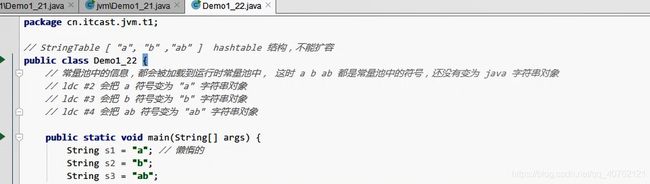
在程序运行时,常量池中的信息,都会被加载到运行时常量池中,字符串对象在未使用时仅仅是常量池中的一个符号,当执行到 String s = "a" 时,才会创建字符串对象,此时,会把 a 作为 key值从 StringTable 查找,如果有则直接用,如果没有则把 符号 "a"变为字符串对象,放入StringTable中。
5.5 运行时常量池
5.5.1定义
当类被加载进内存时,他的常量池信息就会被放入到运行时常量池(在方法区中),并将常量池中的符号地址变为真实的内存地址。
5.5.2 StringTable的内存位置
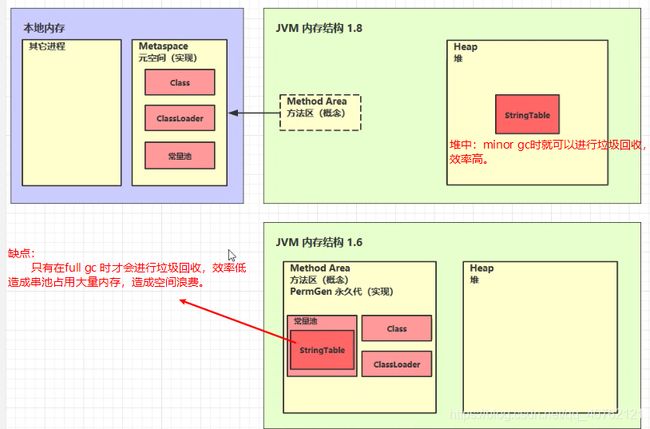
5.5.3 StringTable特性
1. 常量池中的字符创仅是符号,第一次使用时才会变成对象。
2. 利用串池的机制,可以避免重复创建字符串对象。
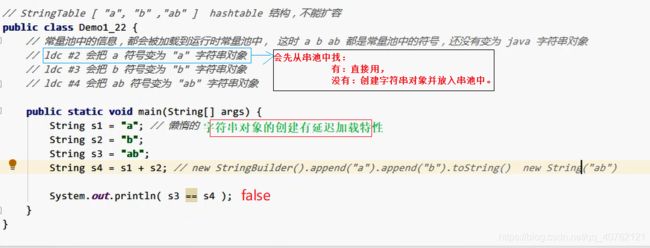
3. 字符串变量拼接的底层原理是使用StringBuiler对象拼接。(jdk1.8)
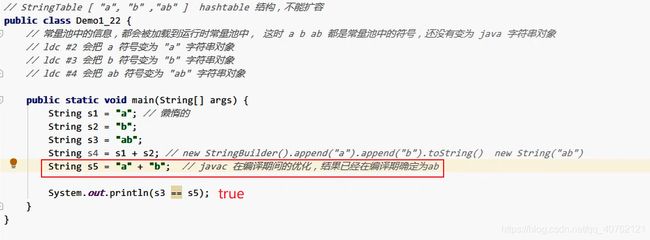
4. 字符串常量拼接的原理是编译期的优化。
5. 可以使用intern方法,主动将串池中还没有的字符串对象放入串池。
* intern()方法在jdk1.6和jdk1.8 底层实现的区别?
jdk1.8中,将内存中的字符串对象尝试放入串池,如果串池中有则不会放入,如果没有则放入串池,并把放入串池中的对象返回。
jdk1.6中,将内存中的字符串对象尝试放入串池,如果串池中有则不会放入,如果没有则【会把该字符串对象复制一份】放入串池,并把放入串池中的对象返回。
案例1
案例2
5.5.4 StringTable的性能调优
pass
6.直接内存
6.1 特点
1.属于操作系统内存。
2.常见于NIO操作时,用于数据缓冲区。
3.分配回收成本较高,但读写性能高。
4.不受JVM内存回收管理。
- Java文件读写过程之BIO
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NDfzW3E1-1591013381172)(.\images\Java文件读写过程_BIO_01.png)]
- Java文件读写过程之NIO 提高了文件读写的效率。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QZpb9Anx-1591013381173)(.\images\Java文件读写过程_NIO_02.png)]
6.2 直接内存分配和回收的原理
1.使用了Java最底层的一个 Unsafe 对象完成了直接内存的分配回收,并且通过主动调用 freeMemory 方法来回收直接内存。
2.ByteBuffer 的实现类内部,使用了Cleaner(虚引用) 来监测ByteBuffer对象,一旦 ByteBuffer对象被垃圾回收,那么就会由ReferenceHandler线程
3.通过Cleaner的clean()方法调用 freeMemory来释放直接内存。
二、垃圾回收机制
内容介绍
1.如何判断对象可以回收
2.垃圾回收算法
3.分代垃圾回收算法
4.垃圾回收器
5.垃圾回收调优
1. 如何判断对象可以回收?
1.1 两个对象回收算法
引用计数法:指一个对象被其他变量引用,就让引用计数加1,当被两个对象引用时就加2,如果没有变量引用时,计数为 0.
【缺点】:
1.循环引用问题。 A对象引用B,B引用A,AB均无其他对象引用。由于AB对象的引用计数均为1,
所以AB对象不会被当作垃圾回收,从而造成了内存泄漏问题。
2.早期Python虚拟机在进行垃圾回收时就采用了引用计数算法。
可达性分析算法(JAVA虚拟机采用)
根对象:肯定不能当成垃圾被回收的对象就是根对象。(例子:一串葡萄,掉在盘子里的就可被回收。)
特点:
1. java虚拟机中的垃圾回收机器采用可达性分析来探索所有存活的对象。
2. 扫描堆中的对象,看是否能够沿着GC Root对象为起点的引用链找到该对象,找不到,表示可以回收。
问:哪些对象可以作为GC Root?
a.虚拟机栈(栈桢中的本地变量表)中的引用的对象
b.方法区中的类静态属性引用的对象
c.方法区中的常量引用的对象
d.本地方法栈中JNI的引用的对象
1.2对象的四种引用
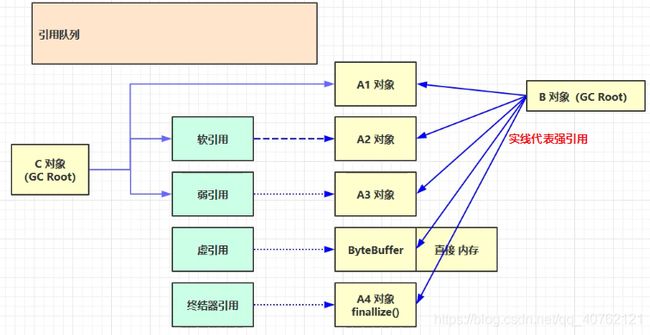
面试题: 请你说一下Java虚拟中的四种引用?
常见的是五种,分别是强引用、弱引用、虚引用、软饮用、终结器引用。
1.2.1 强引用
定义:
我们平常用的对象都是强引用。如 Student s = new Student();通过【赋值号】s就【强引用】了学生对象。
特点:
* 只要沿着GC Root根对象的引用链能够找到该对象,就不会被回收。只有所有的GC Root对象都不通过【强引用】引用该对象,该对象才能被垃圾回收。
1.2.2软引用
特点:
* 只有没有被直接的强引用而引用,当垃圾回收发生后,内存仍然不足时,就会回收软引用对象。
* 可以配合引用队列来释放软引用自身。
1.2.3 弱引用
特点:
* 只要没有被直接的强引用而引用,只要垃圾回收动作发生,不管内存是否充足,都会回收弱引用对象。
* 可以配合引用队列来释放弱引用自身。
1.2.4 虚引用
特点:
* 虚引用必须配合引用队列使用,主要配合 ByteBuffer使用,被引用对象回收时,会将虚引用入队,由
Reference Handler线程调用虚引用相关方法释放直接内存。
1.2.5终结器引用
特点:
无需手动编码,但是内部配合引用队列使用,在垃圾回收时,终结器引用入队(被引用对象暂时没有被回收),再由
Finalizer 线程通过终结器引用找到被引用的对象并调用它的finalize()方法,第二次GC 时才能被回收。
2.垃圾回收算法
2.1 标记清除算法

2.2 标记整理算法
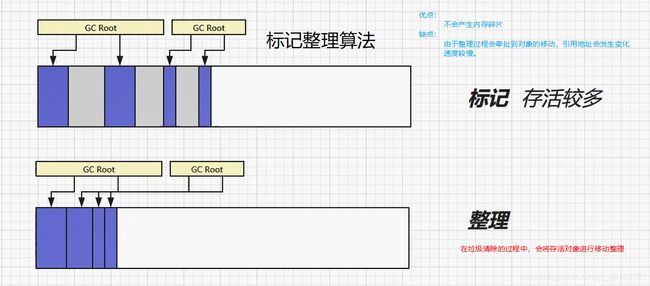
2.3 复制算法
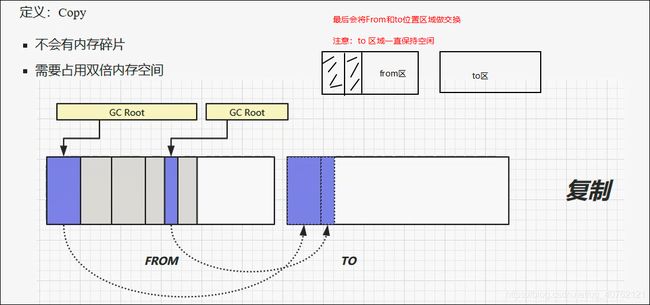
3.分代垃圾回收机制
3.1 垃圾回收执行流程

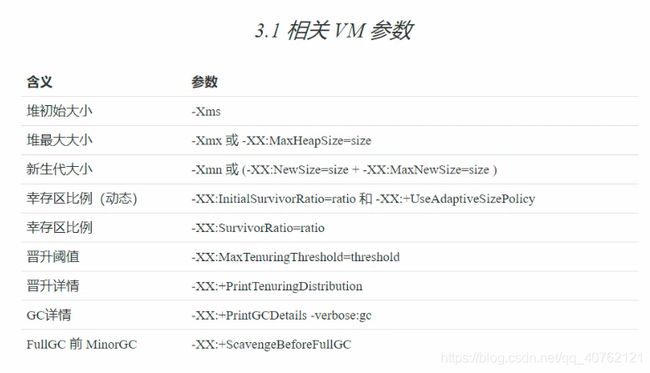
3.2 与GC 相关 vm参数
4. 垃圾回收器的分类
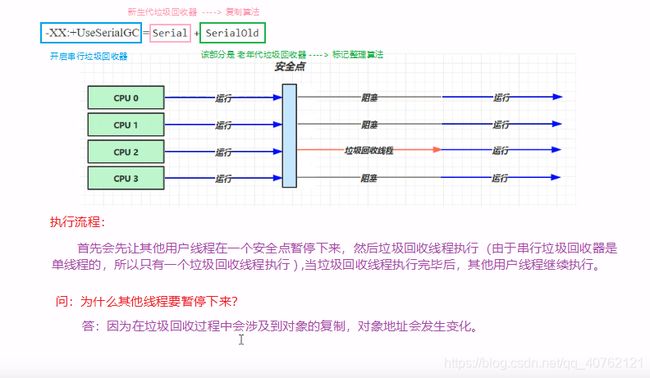
4.1.串行
特点:
* 单线程
* 适用于 堆内存较小,适合个人电脑。
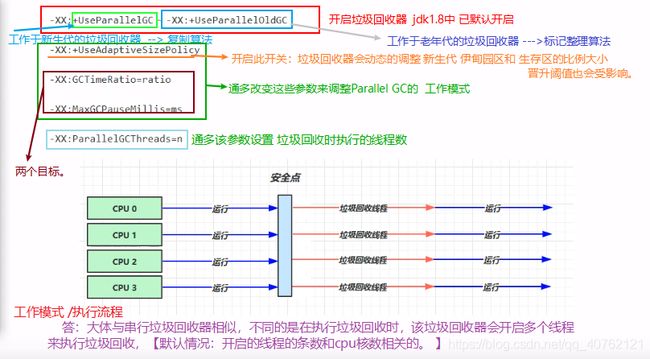
4.2.吞吐量优先
特点:
* 多线程
* 堆内存较大,多核cpu
* 让单位时间内,STW的时间最短
吞吐量: 垃圾回收时间占程序运行时间的比重,垃圾回收时间越短,吞吐量越大。
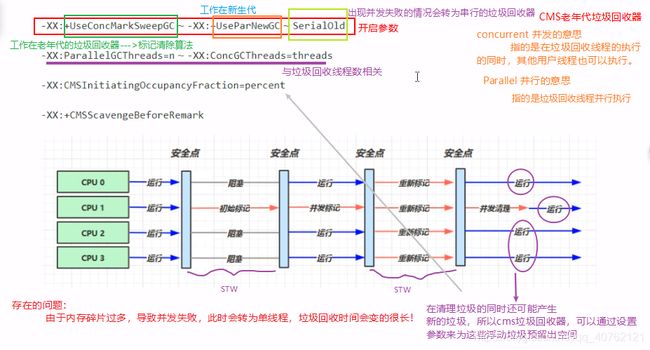
4.3.响应时间优先
特点:
* 多线程
* 堆内存较大,多核cpu
* 尽可能让单次STW的时间最短
4. 4G1 垃圾回收器
4.4.1 定义:
Garbage First
4.4.2 适用场景/特点
1、同时注重吞吐量和低延迟、默认的暂停目标是 200ms.
2、超大堆内存,会将堆内存划分为多个大小相等的Region.
注意:每个区域都可以独立作为伊甸园区、幸存区、和老年代区。
3、整体上是标记+清除算法,两个区域之间采用的是复制算法.
相关的jvm参数:
-xx:+UseG1Gc
-xx:G1HeapRegionSize = size
-xx:MaxGCPauseMillis = time
4.4.3 G1垃圾回收阶段
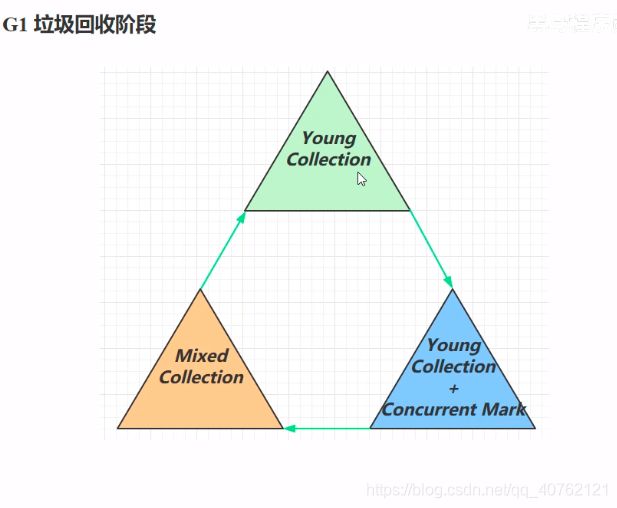
4.4.4 Young COllection 新生代垃圾回收
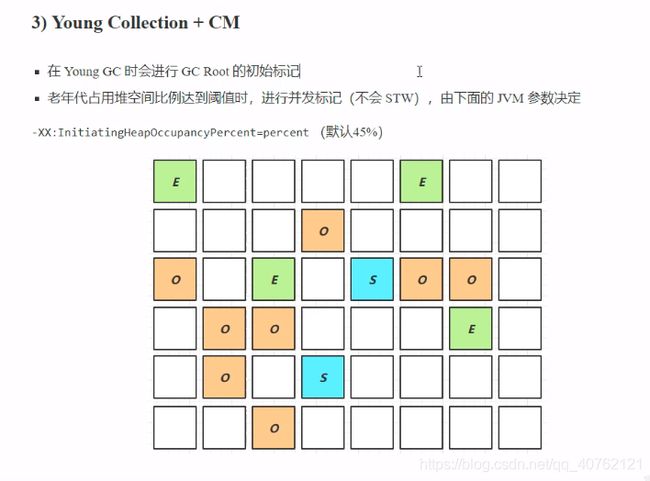
4.4.5 Young Collection + CM 垃圾回收阶段
4.4.6 Mixed Collection垃圾回收阶段
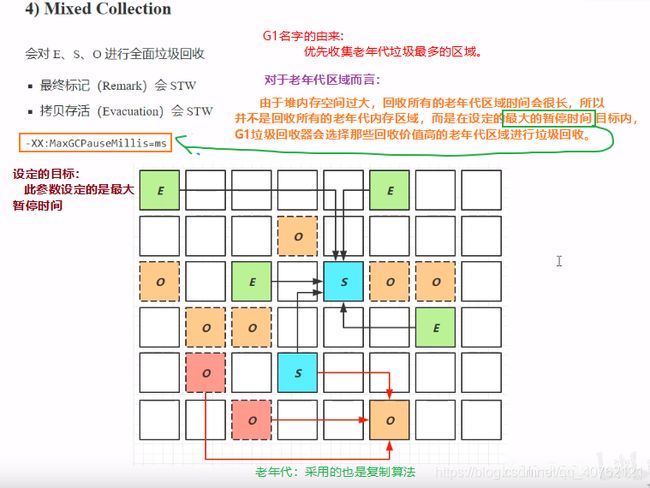
垃圾回收阶段
未完待续…