ECCV2020 | 爱奇艺提出用于时序动作提名生成的融合边界内容图神经网络
写在前面
近日,计算机视觉顶会 ECCV 2020 已正式公布论文接收结果。本文介绍的是来自爱奇艺团队一篇论文,研究者提出了 Boundary Content Graph Neural Network (BC-GNN),通过图神经网络对边界和内容预测之间的关系进行建模,生成更精确的时序边界和可靠的内容置信度分数。

时序动作提名生成 (Temporal action proposal generation) 任务需要从未处理的长视频中精确定位包含高质量动作内容的片段,该任务在视频理解中起着重要的作用。现有的方法多为先生成起止边界,再将起止边界组合成候选动作提名,然后再生成候选时序片段的内容置信度,这种处理方式忽略了边界预测与内容预测之间的联系。
为了解决这个问题,爱奇艺提出了 Boundary Content Graph Neural Network (BC-GNN),通过图神经网络对边界和内容预测之间的关系进行建模,通过利用两者之间的内在联系生成更精确的时序边界和可靠的内容置信度分数。

在 BC-GNN 中,将候选时序片段的内容(content)作为图的边(edge),将候选时序片段的边界(boundary,开始点和结束点)作为图的节点(node),然后设计了一种更新边和节点特征的推理方法,将更新之后的特征用来预测起始点概率和内容的置信度,最终生成高质量的 proposal。该方法最终在 ActivityNet-1.3 和 THUMOS14 这两个公开数据集的时序动作提名生成任务以及时序行为检测任务上均达到了领先水平。
论文链接:
https://arxiv.org/abs/2008.01432研究方法

上图是 BC-GNN 的整体框架图,主要包括五个流程,分别为:
1)特征提取(Feature Encoding)
2)基础模块(Base Module)
3)图构建模块(Graph Construction Module, GCM)
4)图推理模块(Graph Reasoning Module, GRM)
5)输出模块 (Output Module)
特征提取模块
研究者使用在视频行为识别中取得良好效果的 two-stream 网络将视频编码成特征。Two-stream 由 spatial 和 temporal 两个分支网络构成,spatial 分支网络的输入是单张 rgb 图像,用来提取空间特征,temporal 分支网络的输入是多张光流图像,用来提取运动特征。对于一个未处理的长视频,将对应的视频帧切分为 T 个可处理单元(snippet),每个可处理单元经 two-stream 之后被编码成为 D 维的特征向量,其中 D 维特征向量由 spatial 和 temporal 分支网络的最后一层输出拼接而成,从而视频被编码成一个 TxD 的特征矩阵,T 是特征序列的长度,D 表示特征的维度。
BC-GNN 主要包括四个模块:基础模块、图构建模块、图推理模块和输出模块。
基础模块
基础模块由两层 1D 卷积组成,主要用来扩大感受野并作为整个网络的基础。
图构建模块

图构建模块用来构建一个边界内容图,构建图的过程如上图所示。研究者构建的边界内容图是一个二分图,二分图是一类特殊的图,它的顶点由两个独立集 U 和 V 组成,并且所有的边都是连结一个 U 中的点和一个 V 中的点。在构建图的过程中,视频的每个处理单元 snippet 对应的时刻可以看作是 proposal 的起始点和结束点,从而可以得到起始点集合 N_s 和结束点集合 N_e,N_s 和 N_e 作为边界内容图的两个互相独立的顶点集。用 t_s,i、t_e,j 分别表示 Ns 中的任意起始点 n_s,i 和 N_e 中的任意结束点 n_e,j 对应的时刻,其中 i,j=1,2,…,T,当满足 t_e,j > t_s,i 时 n_s,i 和 n_e,j 之间有边连接,用 d_i,j 表示。
当连接起始点和结束点之间的边没有方向时可以得到(a)所示的无向图。由于起始点代表 proposal 的开始时间,结束点代表 proposal 的结束时间,连接起始点和结束点的边应该带有方向性,并且从起始点到结束点的边代表的信息与从结束点到起始点的边代表的信息是不同的,因此研究者将(a)所示的无向图转换为图(b)所示的有向图。具体的转换过程为,将无向图中的无向边分成两个有相同节点和相反方向的有向边。
在进行图推理操作之前,研究者为构建的边界内容图中的每个节点和边赋予其特征。为了得到节点和边的特征,研究者在基础模块后面连接三个并行的 1D 卷积,从而得到三个特征矩阵,分别为起始点特征矩阵 F_s、结束点特征矩阵 F_e 和内容特征矩阵 F_c,这三个特征矩阵的时间维度和特征维度均相同,大小为 TxD。对于任意起始节点 n_s,i,对应的时间为 t_s,i,则该节点的特征为 F_s 特征矩阵第 i-1 行对应的特征向量。同理,对于任意的结束节点 n_e,j,其特征为 Fe 特征矩阵第 j-1 行对应的特征向量。若 n_s,i 和 n_e,j 之间有边连接,边 d_i,j 对应的特征获取过程为:
1)首先对 F_c 特征矩阵第 i-1 行到 j-1 对应的特征矩阵在时序方向上进行线性插值,得到固定大小的特征矩阵 NxD’(N 为人为设置的常数);
2)然后将 NxD’转化为(N·D’)x1;
3)在 (N·D’)x1 特征后连接一个全连接层,得到维度为 D’的特征向量即为边 d_i,j 对应的特征。
在有向图中,节点和边的特征更新之前,连接两个节点方向不同的两条边共享同一个特征向量。
图推理模块
为了实现节点和边缘之间的信息交换,研究者提出了一种新的图推理方法,该推理方法可分为边特征更新和节点特征更新两个步骤。边特征更新步骤旨在汇总有边连接的两个节点的属性,更新过程如下所示:

其中σ表示激活函数 ReLU,θs2e 和θe2s 代表不同的可训练的参数,× 代表矩阵相乘,∗ 代表 element-wise 相乘。
节点特征更新步骤旨在聚合边及其相邻节点的属性,更新过程如下所示:


其中 e_(h,t)表示从头结点 h 指向尾节点 t 的边对应的特征,K 表示以 h 为头节点的边的总数。为了避免输出特征数值规模的增加,研究者在更新节点特征前先对对应的边的特征进行归一化,之后再把更新后的边的特征作为相应头结点特征的权重。σ表示激活函数 ReLU,θ_node 代表可训练的参数。
输出模块
如 BC-GNN 的整体框架图所示,候选 proposal 由一对节点与连接它的边产生,并且其起始点、结束点和内容的置信度分别基于更新后的节点特征和边特征生成,具体过程如下所示:
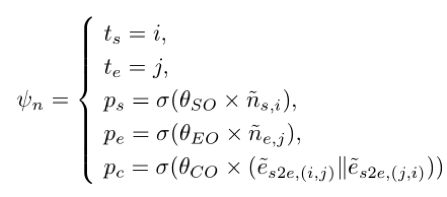
实验介绍
时序动作提名生成实验


从上面两个表中可以看出,研究者在两个通用的数据集上的效果均达到领先水平。
时序行为检测实验


采用对 proposal 进行分类的方式得到时序行为检测结果,从上面两个图中可以看出,在两个数据上研究者提出的方法均取得领先的结果。
消融实验
在 BC-GNN 算法中,相比于直接使用传统的 GCN,将无向图转变成有向图,并且增加了边特征更新步骤,为了验证这两个策略的有效性,在 ActivityNet-1.3 数据集的时序动作提名生成任务上进行了消融实验。从下图的表格和结果曲线上可以看出,这两种策略均有利于结果的提升。


相比于目前通用的将边界预测与内容预测划分为两个步骤的算法,本文提出的方法使用图神经网络,对边界预测与内容预测的关系进行建模,将边界预测和内容预测的过程联系起来。高质量的动作内容有利于边界的调整,同时精确的边界定位会帮助内容置信度的预测。此外,研究者还提出一种新的图推理方法,融合边界信息和内容信息去更新对应的节点和边的信息。本文提出的对有关联的两个步骤进行建模的方法可以应用于其他相似任务中。
包括本文在内,目前学术界在时序行为检测任务上取得不错效果的方法大多采用先提取动作提名再对动作提名进行分类的方法,这种两阶段的方式增加了整个流程的复杂度和运算量,未来将针对这类问题将有更多的设计与探索。

也许你还想看
ICCV 2019论文 | 爱奇艺提出利用无标签数据优化人脸识别模型
2019 ICME论文解析 | 爱奇艺首创实时自适应码率算法评估系统

扫一扫下方二维码,更多精彩内容陪伴你!
