Redis-缓存雪崩、击穿、穿透
提到Redis我相信各位在面试,或者实际开发过程中对缓存雪崩,穿透,击穿也不陌生吧,就 算没遇到过但是你肯定听过,那三者到底有什么区别,我们又应该怎么去防止这样的情况发生 呢,我们有请下一位受害者。
面试开始
一个大腹便便,穿着格子衬衣的中年男子,拿着一个满是划痕的mac向你走来,看着快秃 顶的头发,心想着肯定是尼玛顶级架构师吧!但是我们腹有诗书气自华,虚都不虚

小伙子我看你的简历上写到了Redis,那么我们直接开门见山,直接 怼常见的几个大问题,Redis雪崩了解么?
帅气迷人的面试官您好,我了解的,目前电商首页以及热点数据都会去做缓存 ,一般缓存都 是定时任务去刷新,或者是查不到之后去更新的,定时任务刷新就有一个问题。
举个简单的例子:如果所有首页的Key失效时间都是12小时,中午12点刷新的,我零点有个秒 杀活动大量用户涌入,假设当时每秒 6000 个请求,本来缓存在可以扛住每秒 5000 个请求, 但是缓存当时所有的Key都失效了。此时 1 秒 6000 个请求全部落数据库,数据库必然扛不 住,它会报一下警,真实情况可能DBA都没反应过来就直接挂了。此时,如果没用什么特别的 方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。 这就是我理解的缓存雪崩。
我刻意看了下我做过的项目感觉再吊的都不允许这么大的QPS直接打DB去,不过没慢SQL加 上分库,大表分表可能还还算能顶,但是跟用了Redis的差距还是很大

同一时间大面积失效,那一瞬间Redis跟没有一样,那这个数量级别的请求直接打到数据库几 乎是灾难性的,你想想如果打挂的是一个用户服务的库,那其他依赖他的库所有的接口几乎都 会报错,如果没做熔断等策略基本上就是瞬间挂一片的节奏,你怎么重启用户都会把你打挂, 等你能重启的时候,用户早就睡觉去了,并且对你的产品失去了信心,什么垃圾产品。
面试官摸了摸自己的头发,嗯还不错,那这种情况咋整?你都是怎么 去应对的?
处理缓存雪崩简单,在批量往Redis存数据的时候,把每个Key的失效时间都加个随机值就好 了,这样可以保证数据不会在同一时间大面积失效,我相信,Redis这点流量还是顶得住的。
setRedis(Key,value,time + Math.random() * 10000);如果Redis是集群部署,将热点数据均匀分布在不同的Redis库中也能避免全部失效的问题, 不过本渣我在生产环境中操作集群的时候,单个服务都是对应的单个Redis分片,是为了方便 数据的管理,但是也同样有了可能会失效这样的弊端,失效时间随机是个好策略。
或者设置热点数据永远不过期,有更新操作就更新缓存就好了(比如运维更新了首页商品,那 你刷下缓存就完事了,不要设置过期时间),电商首页的数据也可以用这个操作,保险。
那你了解缓存穿透和击穿么,可以说说他们跟雪崩的区别么?
嗯,了解,我先说一下缓存穿透吧,缓存穿透是指缓存和数据库中都没有的数据,而用户不断 发起请求,我们数据库的 id 都是1开始自增上去的,如发起为id值为 -1 的数据或 id 为特别大 不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据 库。
小点的单机系统,基本上用postman就能搞死,比如我自己买的阿里服务

像这种你如果不对参数做校验,数据库id都是大于0的,我一直用小于0的参数去请求你,每次 都能绕开Redis直接打到数据库,数据库也查不到,每次都这样,并发高点就容易崩掉了。
至于缓存击穿嘛,这个跟缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓 存失效,打崩了DB,而缓存击穿不同的是缓存击穿是指一个Key非常热点,在不停的扛着大并 发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存, 直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。
面试官露出欣慰的眼光,那他们分别怎么解决
缓存穿透我会在接口层增加校验,比如用户鉴权校验,参数做校验,不合法的参数直接代码 Return,
比如:id 做基础校验,id <=0的直接拦截等。
这里我想提的一点就是,我们在开发程序的时候都要有一颗“不信任”的心,就是不要相信任 何调用方,比如你提供了API接口出去,你有这几个参数,那我觉得作为被调用方,任何可能 的参数情况都应该被考虑到,做校验,因为你不相信调用你的人,你不知道他会传什么参数给 你。
举个简单的例子,你这个接口是分页查询的,但是你没对分页参数的大小做限制,调用的人万 一一口气查 Integer.MAX_VALUE 一次请求就要你几秒,多几个并发你不就挂了么?是公司 同事调用还好大不了发现了改掉,但是如果是黑客或者竞争对手呢?在你双十一当天就调你这 个接口会发生什么,就不用我说了吧。这是之前的Leader跟我说的,我觉得大家也都应该了 解下。
从缓存取不到的数据,在数据库中也没有取到,这时也可以将对应Key的Value对写为null、位 置错误、稍后重试这样的值具体取啥问产品,或者看具体的场景,缓存有效时间可以设置短 点,如30秒(设置太长会导致正常情况也没法使用)。
这样可以防止攻击用户反复用同一个id暴力攻击,但是我们要知道正常用户是不会在单秒内发 起这么多次请求的,那网关层Nginx本渣我也记得有配置项,可以让运维大大对单个IP每秒访 问次数超出阈值的IP都拉黑。
那你还有别的办法么?
还有我记得Redis还有一个高级用法布隆过滤器(Bloom Filter)这个也能很好的防止缓存穿 透的发生,他的原理也很简单就是利用高效的数据结构和算法快速判断出你这个Key是否在数 据库中存在,不存在你return就好了,存在你就去查了DB刷新KV再return。
那又有小伙伴说了如果黑客有很多个IP同时发起攻击呢?这点我一直也不是很想得通,但是一 般级别的黑客没这么多肉鸡,再者正常级别的Redis集群都能抗住这种级别的访问的,小公司 我想他们不会感兴趣的。把系统的高可用做好了,集群还是很能顶的。
缓存击穿的话,设置热点数据永远不过期。或者加上互斥锁就能搞定了
代码我肯定帮你们准备好了
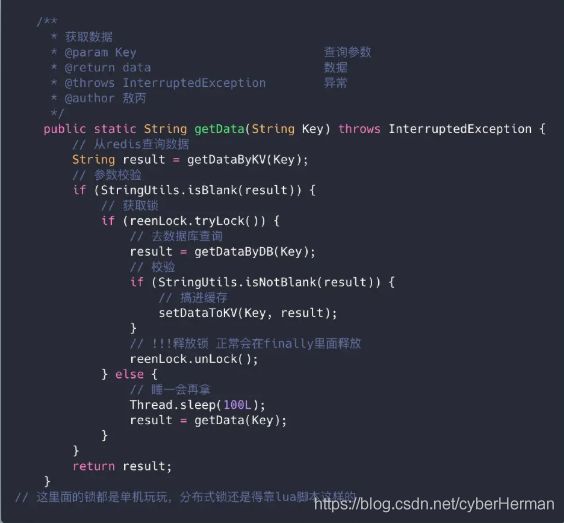
面试结束
在此感谢B站up主,三太子敖丙,大家可以多多关注他哦。很牛的一位大佬。-->摘自B站 三太子敖丙