服务治理导论
一、服务治理背景
1.高并发带来的问题
1.io压力过大
连接池只有这么多连接资源,短时间大量请求,资源很快会耗尽,那么其他连接请求就只有被阻塞等待了。
2.cpu压力过大
一个线程处理的内容运算量比较大,一直占用着CPU,如果短时间成百上千的请求同时占用CPU,那么CPU压力也好比较大。
2.服务雪崩
1.导致雪崩的常见原因
1.大流量请求
2.硬件故障
3.缓存击穿
3.高性能之道
高性能程序就是高效的利用CPU、内存、网络和磁盘等资源,在短时间内处理大量的请求。
那如何衡量“短 时间和大量”呢?其实就是两个关键指标:响应时间和每秒事务处理量(TPS)。
那什么是资源的高效利用呢?
我觉得有两个原则:
1. 减少资源浪费。比如尽量避免线程阻塞,因为一阻塞就会发生线程上下文切换,就需要耗费CPU资源;再 比如网络通信时数据从内核空间拷贝到Java堆内存,需要通过本地内存中转。
2. 当某种资源成为瓶颈时,用另一种资源来换取。比如缓存和对象池技术就是用内存换CPU;数据压缩后再 传输就是用CPU换网络。
二、 服务治理常见方案
1. 超时机制
如果我们加入超时机制,例如2s,那么超过2s就会直接返回了,那么这样是不是一定程度上可以抑制消费者资源耗尽的问题。
2. 服务限流
关于限流的核心相关内容请参考我的另一篇博文
服务限流治理_daiwei-dave的博客-CSDN博客
3. 服务降级
关于服务降级的核心相关内容请参考我的另一篇博文
服务熔断降级治理_etcd服务熔断_daiwei-dave的博客-CSDN博客
4. 服务熔断
在固定时间窗口内,接口调用超时比率达到一个阈值,会开启熔断,不在调用服务资源,而是引导进入到降级页面。
关于服务熔断的详细设计,请转入到我的另一篇博文
服务熔断治理_服务的熔断处理_daiwei-dave的博客-CSDN博客
三.弹性设计
首先,我们的服务不能是单点,所以,我们需要在架构中冗余服务,也就是说有多个服务的副本。这需要使用到的具体技术有:
- 负载均衡 + 服务健康检查–可以使用像 Nginx 或 HAProxy 这样的技术;
- 服务发现 + 动态路由 + 服务健康检查,比如 Consul 或 ZooKeeper;
- 自动化运维,Kubernetes 服务调度、伸缩和故障迁移。
然后,我们需要隔离我们的业务,要隔离我们的服务我们就需要对服务进行解耦和拆分,这需要使用到以前的相关技术。
-
bulkheads 模式:业务分片 、用户分片、数据库拆分。
-
自包含系统:所谓自包含的系统是从单体到微服务的中间状态,其把一组密切相关的微服务给拆分出来,只需要做到没有外部依赖就行。
-
异步通讯:服务发现、事件驱动、消息队列、业务工作流。
-
自动化运维:需要一个服务调用链和性能监控的监控系统。
然后,接下来,我们就要进行和能让整个架构接受失败的相关处理设计,也就是所谓的容错设计。这会用到下面的这些技术。
-
错误方面:调用重试 + 熔断 + 服务的幂等性设计。
-
一致性方面:强一致性使用两阶段提交、最终一致性使用异步通讯方式。
-
流控方面:使用限流 + 降级技术。
-
自动化运维方面:网关流量调度,服务监控。
我不敢保证有上面这些技术可以解决所有的问题,但是,只要我们设计得当,绝大多数的问题应该是可以扛得住的了。
下面我画一个图来表示一下。
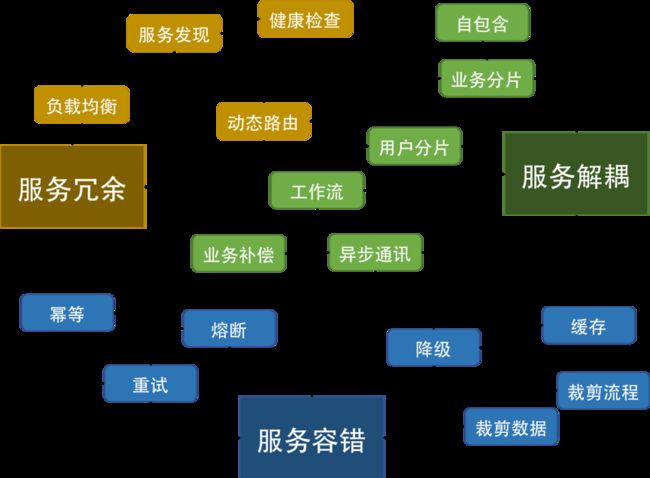
在上面这个图上,我们可以看到,有三大块的东西。
-
冗余服务。通过冗余服务的复本数可以消除单点故障。这需要服务发现,负载均衡,动态路由和健康检查四个功能或组件。
-
服务解耦。通过解耦可以做到把业务隔离开来,不让服务间受影响,这样就可以有更好的稳定性。在水平层面上,需要把业务或用户分片分区(业分做隔离,用户做多租户)。在垂直层面上,需要异步通讯机制。因为应用被分解成了一个一个的服务,所以在服务的编排和聚合上,需要有工作流(像 Spring 的 Stream 或 Akka 的 flow 或是 AWS 的 Simple Workflow)来把服务给串联起来。而一致性的问题又需要业务补偿机制来做反向交易。
-
服务容错。服务容错方面,需要有重试机制,重试机制会带来幂等操作,对于服务保护来说,熔断,限流,降级都是为了保护整个系统的稳定性,并在可用性和一致性方面在出错的情况下做一部分的妥协。
当然,除了这一切的架构设计外,你还需要一个或多个自动运维的工具,否则,如果是人肉运维的话,那么在故障发生的时候,不能及时地做出运维决定,也就空有这些弹力设计了。比如:监控到服务性能不够了,就自动或半自动地开始进行限流或降级。
3.服务隔离设计
隔离设计对应的单词是 Bulkheads,中文翻译为隔板。但其实,这个术语是用在造船上的,也就是船舱里防漏水的隔板。一般的船无论大小都会有这个东西,大一点的船都会把船舱隔成若干个空间。这样,如果船舱漏水,只会进到一个小空间里,不会让整个船舱都进水而导致整艘船都沉了。
我们的软件设计当然也“漏水”,所以为了不让这个“故障”蔓延开来,需要使用“隔板”技术,来将架构分隔成多个“船舱”来隔离故障。
在分布式软件架构中,我们同样需要使用类似这样的技术来让我们的故障得到隔离。
这就需要我们对系统进行分离。一般来说,对于系统的分离有两种方式,一种是以服务的种类来做分离,一种是以用户来做分离。
隔离设计的重点
要能做好隔离设计,我们需要有如下的一些设计考量。
-
我们需要定义好隔离业务的大小和粒度,过大和过小都不好。这需要认真地做业务上的需求和系统分析。
-
无论是做系统版块还是多租户的隔离,你都需要考虑系统的复杂度、成本、性能、资源使用的问题,找到一个合适的均衡方案,或是分布实施的方案尤其重要,这其中需要你定义好要什么和不要什么。因为,我们不可能做出一个什么都能满足的系统。
-
隔离模式需要配置一些高可用、重试、异步、消息中间件,流控、熔断等设计模式的方式配套使用。
-
不要忘记了分布式系统中的运维的复杂度的提升,要能驾驭得好的话,还需要很多自动化运维的工具,尤其是使用像容器或是虚拟机这样的虚拟化技术可以帮助我们更方便地管理,和对比资源更好地利用。否则做出来了也管理不好。
-
最后,你需要一个非常完整的能够看得到所有服务的监控系统,这点非常重要。
下面具体说明一下这两种方式。
服务的隔离就不用说了,因为拆分服务实际上就是在进行服务隔离。
用户分离
下图是一个按用户请求来做分离的图示。
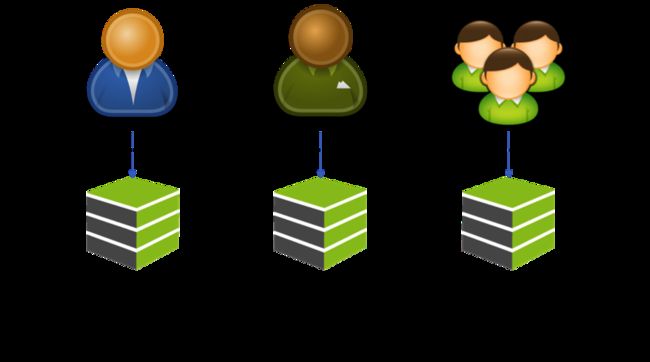
在这个图中,可以看到,我们将用户分成不同的组,并把后端的同一个服务根据这些不同的组分成不同的实例。让同一个服务对于不同的用户进行冗余和隔离,这样一来,当服务实例挂掉时,只会影响其中一部分用户,而不会导致所有的用户无法访问。
这种分离和上面按功能的分离可以融合。说白了,这就是所谓的“多租户”模式。对于一些比较大的客户,我们可以为他们设置专门独立的服务实例,或是服务集群与其他客户隔离开来,对于一些比较小的用户来说,可以让他们共享一个服务实例,这样可以节省相关的资源。
关于多租户的架构设计可参考我的另一篇博文
saas-多租户架构_saas架构_daiwei-dave的博客-CSDN博客
参考资料
4.服务熔断、降级、限流、异步RPC -- HyStrix https://blog.csdn.net/chunlongyu/article/details/53259014
5.防雪崩利器:熔断器 Hystrix 的原理与使用 https://segmentfault.com/a/1190000005988895