0097 系统设计——必知必会
系统设计入门
翻译自:源地址
目的
学习如何设计大型系统。
为系统设计的面试做准备。
学习如何设计大型系统
学习如何设计可扩展的系统将会有助于你成为一个更好的工程师。
系统设计是一个很宽泛的话题。在互联网上,关于系统设计原则的资源也是多如牛毛。
这个仓库就是这些资源的组织收集,它可以帮助你学习如何构建可扩展的系统。
从开源社区学习
这是一个不断更新的开源项目的初期的版本。
欢迎贡献!
为系统设计的面试做准备
在很多科技公司中,除了代码面试,系统设计也是技术面试过程中的一个必要环节。
实践常见的系统设计面试题并且把你的答案和例子的解答进行对照:讨论,代码和图表。
面试准备的其他主题:
- 学习指引
- 如何处理一个系统设计的面试题
- 系统设计的面试题,含解答
- 面向对象设计的面试题,含解答
- 其它的系统设计面试题
抽认卡
这里提供的抽认卡堆使用间隔重复的方法,帮助你记忆关键的系统设计概念。
随时随地都可使用。
代码资源:互动式编程挑战
你正在寻找资源以准备编程面试吗?
请查看我们的姐妹仓库互动式编程挑战,其中包含了一个额外的抽认卡堆:
- 代码卡堆
贡献
从社区中学习。
欢迎提交 PR 提供帮助:
- 修复错误
- 完善章节
- 添加章节
- 帮助翻译
一些还需要完善的内容放在了正在完善中。
请查看贡献指南。
系统设计主题的索引
各种系统设计主题的摘要,包括优点和缺点。每一个主题都面临着取舍和权衡。
每个章节都包含着更多的资源的链接。

- 系统设计主题:从这里开始
- 第一步:回顾可扩展性的视频讲座
- 第二步:回顾可扩展性的文章
- 接下来的步骤
- 性能与拓展性
- 延迟与吞吐量
- 可用性与一致性
- CAP 理论
- CP - 一致性和分区容错性
- AP - 可用性和分区容错性
- CAP 理论
- 一致模式
- 弱一致性
- 最终一致性
- 强一致性
- 可用模式
- 故障切换
- 复制
- 域名系统
- CDN
- CDN 推送
- CDN 拉取
- 负载均衡器
- 工作到备用切换(Active-passive)
- 双工作切换(Active-active)
- 四层负载均衡
- 七层负载均衡
- 水平扩展
- 反向代理(web 服务器)
- 负载均衡与反向代理
- 应用层
- 微服务
- 服务发现
- 数据库
- 关系型数据库管理系统(RDBMS)
- Master-slave 复制集
- Master-master 复制集
- 联合
- 分片
- 非规范化
- SQL 调优
- NoSQL
- Key-value 存储
- 文档存储
- 宽列存储
- 图数据库
- SQL 还是 NoSQL
- 关系型数据库管理系统(RDBMS)
- 缓存
- 客户端缓存
- CDN 缓存
- Web 服务器缓存
- 数据库缓存
- 应用缓存
- 数据库查询级别的缓存
- 对象级别的缓存
- 何时更新缓存
- 缓存模式
- 直写模式
- 回写模式
- 刷新
- 异步
- 消息队列
- 任务队列
- 背压机制
- 通讯
- 传输控制协议(TCP)
- 用户数据报协议(UDP)
- 远程控制调用协议(RPC)
- 表述性状态转移(REST)
- 安全
- 附录
- 2 的次方表
- 每个程序员都应该知道的延迟数
- 其它的系统设计面试题
- 真实架构
- 公司的系统架构
- 公司工程博客
- 正在完善中
- 致谢
- 联系方式
- 许可
学习指引
基于你面试的时间线(短、中、长)去复习那些推荐的主题。
问:对于面试来说,我需要知道这里的所有知识点吗?
答:不,如果只是为了准备面试的话,你并不需要知道所有的知识点。
在一场面试中你会被问到什么取决于下面这些因素:
- 你的经验
- 你的技术背景
- 你面试的职位
- 你面试的公司
- 运气
那些有经验的候选人通常会被期望了解更多的系统设计的知识。架构师或者团队负责人则会被期望了解更多除了个人贡献之外的知识。顶级的科技公司通常也会有一次或者更多的系统设计面试。
面试会很宽泛的展开并在几个领域深入。这会帮助你了解一些关于系统设计的不同的主题。基于你的时间线,经验,面试的职位和面试的公司对下面的指导做出适当的调整。
- 短期 - 以系统设计主题的广度为目标。通过解决一些面试题来练习。
- 中期 - 以系统设计主题的广度和初级深度为目标。通过解决很多面试题来练习。
- 长期 - 以系统设计主题的广度和高级深度为目标。通过解决大部分面试题来练习。
| 短期 | 中期 | 长期 | |
|---|---|---|---|
| 阅读 系统设计主题 以获得一个关于系统如何工作的宽泛的认识 | |||
| 阅读一些你要面试的公司工程博客的文章 | |||
| 阅读 真实架构 | |||
| 复习 如何处理一个系统设计面试题 | |||
| 完成 系统设计的面试题和解答 | 一些 | 很多 | 大部分 |
| 完成 面向对象设计的面试题和解答 | 一些 | 很多 | 大部分 |
| 复习 其它的系统设计面试题 | 一些 | 很多 | 大部分 |
如何处理一个系统设计的面试题
系统设计面试是一个开放式的对话。他们期望你去主导这个对话。
你可以使用下面的步骤来指引讨论。为了巩固这个过程,请使用下面的步骤完成系统设计的面试题和解答这个章节。
第一步:描述使用场景,约束和假设
把所有需要的东西聚集在一起,审视问题。不停的提问,以至于我们可以明确使用场景和约束。讨论假设。
- 谁会使用它?
- 他们会怎样使用它?
- 有多少用户?
- 系统的作用是什么?
- 系统的输入输出分别是什么?
- 我们希望处理多少数据?
- 我们希望每秒钟处理多少请求?
- 我们希望的读写比率?
第二步:创造一个高层级的设计
使用所有重要的组件来描绘出一个高层级的设计。
- 画出主要的组件和连接
- 证明你的想法
第三步:设计核心组件
对每一个核心组件进行详细深入的分析。举例来说,如果你被问到设计一个 url 缩写服务,开始讨论:
- 生成并储存一个完整 url 的 hash
- MD5 和 Base62
- Hash 碰撞
- SQL 还是 NoSQL
- 数据库模型
- 将一个 hashed url 翻译成完整的 url
- 数据库查找
- API 和面向对象设计
第四步:扩展设计
确认和处理瓶颈以及一些限制。举例来说就是你需要下面的这些来完成扩展性的议题吗?
- 负载均衡
- 水平扩展
- 缓存
- 数据库分片
论述可能的解决办法和代价。每件事情需要取舍。可以使用可扩展系统的设计原则来处理瓶颈。
预估计算量
你或许会被要求通过手算进行一些估算。附录涉及到的是下面的这些资源:
- 使用预估计算量
- 2 的次方表
- 每个程序员都应该知道的延迟数
相关资源和延伸阅读
查看下面的链接以获得我们期望的更好的想法:
- 怎样通过一个系统设计的面试
- 系统设计的面试
- 系统架构与设计的面试简介
系统设计的面试题和解答
普通的系统设计面试题和相关事例的论述,代码和图表。
与内容有关的解答在
solutions/文件夹中。
| 问题 | |
|---|---|
| 设计 Pastebin.com (或者 Bit.ly) | 解答 |
| 设计 Twitter 时间线和搜索 (或者 Facebook feed 和搜索) | 解答 |
| 设计一个网页爬虫 | 解答 |
| 设计 Mint.com | 解答 |
| 为一个社交网络设计数据结构 | 解答 |
| 为搜索引擎设计一个 key-value 储存 | 解答 |
| 通过分类特性设计 Amazon 的销售排名 | 解答 |
| 在 AWS 上设计一个百万用户级别的系统 | 解答 |
| 添加一个系统设计问题 | 贡献 |
设计 Pastebin.com (或者 Bit.ly)
查看实践与解答
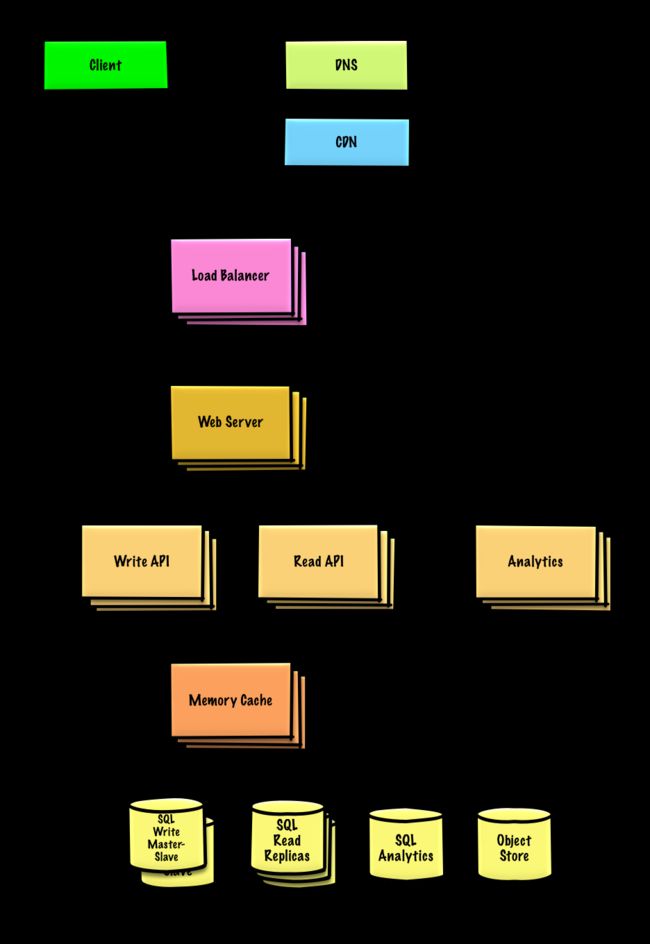
设计 Twitter 时间线和搜索 (或者 Facebook feed 和搜索)
查看实践与解答
设计一个网页爬虫
查看实践与解答
设计 Mint.com
查看实践与解答
为一个社交网络设计数据结构
查看实践与解答
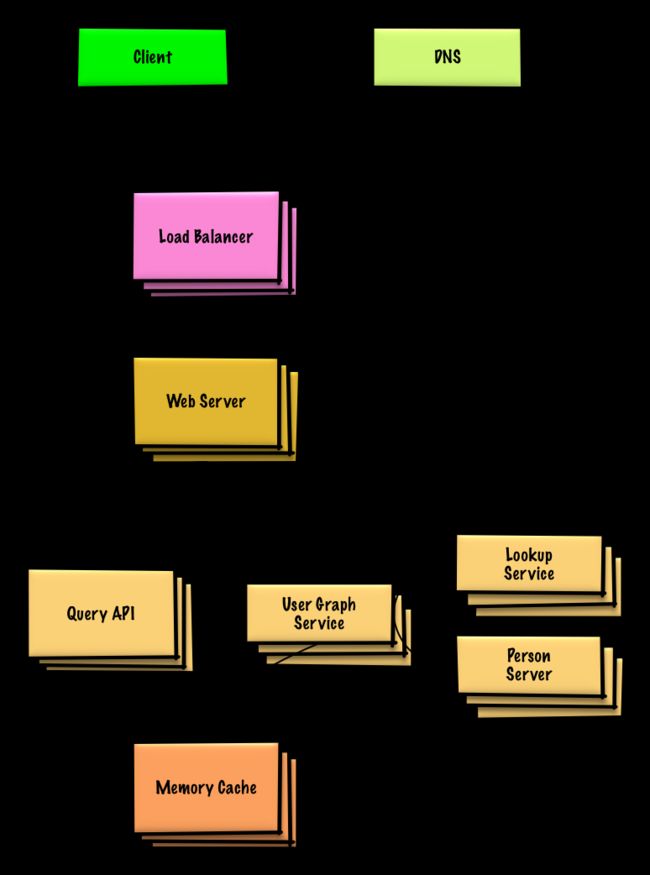
为搜索引擎设计一个 key-value 储存
查看实践与解答
设计按类别分类的 Amazon 销售排名
查看实践与解答

在 AWS 上设计一个百万用户级别的系统
查看实践与解答
面向对象设计的面试问题及解答
常见面向对象设计面试问题及实例讨论,代码和图表演示。
与内容相关的解决方案在
solutions/文件夹中。
注:此节还在完善中
| 问题 | |
|---|---|
| 设计 hash map | 解决方案 |
| 设计 LRU 缓存 | 解决方案 |
| 设计一个呼叫中心 | 解决方案 |
| 设计一副牌 | 解决方案 |
| 设计一个停车场 | 解决方案 |
| 设计一个聊天服务 | 解决方案 |
| 设计一个环形数组 | 待解决 |
| 添加一个面向对象设计问题 | 待解决 |
系统设计主题:从这里开始
不熟悉系统设计?
首先,你需要对一般性原则有一个基本的认识,知道它们是什么,怎样使用以及利弊。
第一步:回顾可扩展性(scalability)的视频讲座
哈佛大学可扩展性讲座
- 主题涵盖
- 垂直扩展(Vertical scaling)
- 水平扩展(Horizontal scaling)
- 缓存
- 负载均衡
- 数据库复制
- 数据库分区
第二步:回顾可扩展性文章
可扩展性
- 主题涵盖:
- Clones
- 数据库
- 缓存
- 异步
接下来的步骤
接下来,我们将看看高阶的权衡和取舍:
- 性能与可扩展性
- 延迟与吞吐量
- 可用性与一致性
记住每个方面都面临取舍和权衡。
然后,我们将深入更具体的主题,如 DNS、CDN 和负载均衡器。
性能与可扩展性
如果服务性能的增长与资源的增加是成比例的,服务就是可扩展的。通常,提高性能意味着服务于更多的工作单元,另一方面,当数据集增长时,同样也可以处理更大的工作单位。1
另一个角度来看待性能与可扩展性:
- 如果你的系统有性能问题,对于单个用户来说是缓慢的。
- 如果你的系统有可扩展性问题,单个用户较快但在高负载下会变慢。
来源及延伸阅读
- 简单谈谈可扩展性
- 可扩展性,可用性,稳定性和模式
延迟与吞吐量
延迟是执行操作或运算结果所花费的时间。
吞吐量是单位时间内(执行)此类操作或运算的数量。
通常,你应该以可接受级延迟下最大化吞吐量为目标。
来源及延伸阅读
- 理解延迟与吞吐量
可用性与一致性
CAP 理论
来源:再看 CAP 理论
在一个分布式计算系统中,只能同时满足下列的两点:
- 一致性 ─ 每次访问都能获得最新数据但可能会收到错误响应
- 可用性 ─ 每次访问都能收到非错响应,但不保证获取到最新数据
- 分区容错性 ─ 在任意分区网络故障的情况下系统仍能继续运行
网络并不可靠,所以你应要支持分区容错性,并需要在软件可用性和一致性间做出取舍。
CP ─ 一致性和分区容错性
等待分区节点的响应可能会导致延时错误。如果你的业务需求需要原子读写,CP 是一个不错的选择。
AP ─ 可用性与分区容错性
响应节点上可用数据的最近版本可能并不是最新的。当分区解析完后,写入(操作)可能需要一些时间来传播。
如果业务需求允许最终一致性,或当有外部故障时要求系统继续运行,AP 是一个不错的选择。
来源及延伸阅读
- 再看 CAP 理论
- 通俗易懂地介绍 CAP 理论
- CAP FAQ
一致性模式
有同一份数据的多份副本,我们面临着怎样同步它们的选择,以便让客户端有一致的显示数据。回想 CAP 理论中的一致性定义 ─ 每次访问都能获得最新数据但可能会收到错误响应
弱一致性
在写入之后,访问可能看到,也可能看不到(写入数据)。尽力优化之让其能访问最新数据。
这种方式可以 memcached 等系统中看到。弱一致性在 VoIP,视频聊天和实时多人游戏等真实用例中表现不错。打个比方,如果你在通话中丢失信号几秒钟时间,当重新连接时你是听不到这几秒钟所说的话的。
最终一致性
在写入后,访问最终能看到写入数据(通常在数毫秒内)。数据被异步复制。
DNS 和 email 等系统使用的是此种方式。最终一致性在高可用性系统中效果不错。
强一致性
在写入后,访问立即可见。数据被同步复制。
文件系统和关系型数据库(RDBMS)中使用的是此种方式。强一致性在需要记录的系统中运作良好。
来源及延伸阅读
- Transactions across data centers
可用性模式
有两种支持高可用性的模式: 故障切换(fail-over)**和**复制(replication)。
故障切换
工作到备用切换(Active-passive)
关于工作到备用的故障切换流程是,工作服务器发送周期信号给待机中的备用服务器。如果周期信号中断,备用服务器切换成工作服务器的 IP 地址并恢复服务。
宕机时间取决于备用服务器处于“热”待机状态还是需要从“冷”待机状态进行启动。只有工作服务器处理流量。
工作到备用的故障切换也被称为主从切换。
双工作切换(Active-active)
在双工作切换中,双方都在管控流量,在它们之间分散负载。
如果是外网服务器,DNS 将需要对两方都了解。如果是内网服务器,应用程序逻辑将需要对两方都了解。
双工作切换也可以称为主主切换。
缺陷:故障切换
- 故障切换需要添加额外硬件并增加复杂性。
- 如果新写入数据在能被复制到备用系统之前,工作系统出现了故障,则有可能会丢失数据。
复制
主─从复制和主─主复制
这个主题进一步探讨了数据库部分:
- 主─从复制
- 主─主复制
域名系统
来源:DNS 安全介绍
域名系统是把 www.example.com 等域名转换成 IP 地址。
域名系统是分层次的,一些 DNS 服务器位于顶层。当查询(域名) IP 时,路由或 ISP 提供连接 DNS 服务器的信息。较底层的 DNS 服务器缓存映射,它可能会因为 DNS 传播延时而失效。DNS 结果可以缓存在浏览器或操作系统中一段时间,时间长短取决于存活时间 TTL。
- NS 记录(域名服务) ─ 指定解析域名或子域名的 DNS 服务器。
- MX 记录(邮件交换) ─ 指定接收信息的邮件服务器。
- A 记录(地址) ─ 指定域名对应的 IP 地址记录。
- CNAME(规范) ─ 一个域名映射到另一个域名或
CNAME记录( example.com 指向 www.example.com )或映射到一个A记录。
CloudFlare 和 Route 53 等平台提供管理 DNS 的功能。某些 DNS 服务通过集中方式来路由流量:
- 加权轮询调度
- 防止流量进入维护中的服务器
- 在不同大小集群间负载均衡
- A/B 测试
- 基于延迟路由
- 基于地理位置路由
缺陷:DNS
- 虽说缓存可以减轻 DNS 延迟,但连接 DNS 服务器还是带来了轻微的延迟。
- 虽然它们通常由政府,网络服务提供商和大公司管理,但 DNS 服务管理仍可能是复杂的。
- DNS 服务最近遭受 DDoS 攻击,阻止不知道 Twitter IP 地址的用户访问 Twitter。
来源及延伸阅读
- DNS 架构
- Wikipedia
- 关于 DNS 的文章
内容分发网络(CDN)
来源:为什么使用 CDN
内容分发网络(CDN)是一个全球性的代理服务器分布式网络,它从靠近用户的位置提供内容。通常,HTML/CSS/JS,图片和视频等静态内容由 CDN 提供,虽然亚马逊 CloudFront 等也支持动态内容。CDN 的 DNS 解析会告知客户端连接哪台服务器。
将内容存储在 CDN 上可以从两个方面来提供性能:
- 从靠近用户的数据中心提供资源
- 通过 CDN 你的服务器不必真的处理请求
CDN 推送(push)
当你服务器上内容发生变动时,推送 CDN 接受新内容。直接推送给 CDN 并重写 URL 地址以指向你的内容的 CDN 地址。你可以配置内容到期时间及何时更新。内容只有在更改或新增是才推送,流量最小化,但储存最大化。
CDN 拉取(pull)
CDN 拉取是当第一个用户请求该资源时,从服务器上拉取资源。你将内容留在自己的服务器上并重写 URL 指向 CDN 地址。直到内容被缓存在 CDN 上为止,这样请求只会更慢,
存活时间(TTL)决定缓存多久时间。CDN 拉取方式最小化 CDN 上的储存空间,但如果过期文件并在实际更改之前被拉取,则会导致冗余的流量。
高流量站点使用 CDN 拉取效果不错,因为只有最近请求的内容保存在 CDN 中,流量才能更平衡地分散。
缺陷:CDN
- CDN 成本可能因流量而异,可能在权衡之后你将不会使用 CDN。
- 如果在 TTL 过期之前更新内容,CDN 缓存内容可能会过时。
- CDN 需要更改静态内容的 URL 地址以指向 CDN。
来源及延伸阅读
- 全球性内容分发网络
- CDN 拉取和 CDN 推送的区别
- Wikipedia
负载均衡器
来源:可扩展的系统设计模式
负载均衡器将传入的请求分发到应用服务器和数据库等计算资源。无论哪种情况,负载均衡器将从计算资源来的响应返回给恰当的客户端。负载均衡器的效用在于:
- 防止请求进入不好的服务器
- 防止资源过载
- 帮助消除单一的故障点
负载均衡器可以通过硬件(昂贵)或 HAProxy 等软件来实现。 增加的好处包括:
-
SSL 终结
─ 解密传入的请求并加密服务器响应,这样的话后端服务器就不必再执行这些潜在高消耗运算了。
- 不需要再每台服务器上安装 X.509 证书。
-
Session 留存 ─ 如果 Web 应用程序不追踪会话,发出 cookie 并将特定客户端的请求路由到同一实例。
通常会设置采用工作─备用 或 双工作 模式的多个负载均衡器,以免发生故障。
负载均衡器能基于多种方式来路由流量:
- 随机
- 最少负载
- Session/cookie
- 轮询调度或加权轮询调度算法
- 四层负载均衡
- 七层负载均衡
四层负载均衡
四层负载均衡根据监看传输层的信息来决定如何分发请求。通常,这会涉及来源,目标 IP 地址和请求头中的端口,但不包括数据包(报文)内容。四层负载均衡执行网络地址转换(NAT)来向上游服务器转发网络数据包。
七层负载均衡器
七层负载均衡器根据监控应用层来决定怎样分发请求。这会涉及请求头的内容,消息和 cookie。七层负载均衡器终结网络流量,读取消息,做出负载均衡判定,然后传送给特定服务器。比如,一个七层负载均衡器能直接将视频流量连接到托管视频的服务器,同时将更敏感的用户账单流量引导到安全性更强的服务器。
以损失灵活性为代价,四层负载均衡比七层负载均衡花费更少时间和计算资源,虽然这对现代商用硬件的性能影响甚微。
水平扩展
负载均衡器还能帮助水平扩展,提高性能和可用性。使用商业硬件的性价比更高,并且比在单台硬件上垂直扩展更贵的硬件具有更高的可用性。相比招聘特定企业系统人才,招聘商业硬件方面的人才更加容易。
缺陷:水平扩展
- 水平扩展引入了复杂度并涉及服务器复制
- 服务器应该是无状态的:它们也不该包含像 session 或资料图片等与用户关联的数据。
- session 可以集中存储在数据库或持久化缓存(Redis、Memcached)的数据存储区中。
- 缓存和数据库等下游服务器需要随着上游服务器进行扩展,以处理更多的并发连接。
缺陷:负载均衡器
- 如果没有足够的资源配置或配置错误,负载均衡器会变成一个性能瓶颈。
- 引入负载均衡器以帮助消除单点故障但导致了额外的复杂性。
- 单个负载均衡器会导致单点故障,但配置多个负载均衡器会进一步增加复杂性。
来源及延伸阅读
- NGINX 架构
- HAProxy 架构指南
- 可扩展性
- Wikipedia
- 四层负载平衡
- 七层负载平衡
- ELB 监听器配置
反向代理(web 服务器)
资料来源:维基百科
反向代理是一种可以集中地调用内部服务,并提供统一接口给公共客户的 web 服务器。来自客户端的请求先被反向代理服务器转发到可响应请求的服务器,然后代理再把服务器的响应结果返回给客户端。
带来的好处包括:
-
增加安全性 - 隐藏后端服务器的信息,屏蔽黑名单中的 IP,限制每个客户端的连接数。
-
提高可扩展性和灵活性 - 客户端只能看到反向代理服务器的 IP,这使你可以增减服务器或者修改它们的配置。
-
本地终结 SSL 会话
- 解密传入请求,加密服务器响应,这样后端服务器就不必完成这些潜在的高成本的操作。
- 免除了在每个服务器上安装 X.509 证书的需要
-
压缩 - 压缩服务器响应
-
缓存 - 直接返回命中的缓存结果
-
静态内容
- 直接提供静态内容
- HTML/CSS/JS
- 图片
- 视频
- 等等
负载均衡器与反向代理
- 当你有多个服务器时,部署负载均衡器非常有用。通常,负载均衡器将流量路由给一组功能相同的服务器上。
- 即使只有一台 web 服务器或者应用服务器时,反向代理也有用,可以参考上一节介绍的好处。
- NGINX 和 HAProxy 等解决方案可以同时支持第七层反向代理和负载均衡。
不利之处:反向代理
- 引入反向代理会增加系统的复杂度。
- 单独一个反向代理服务器仍可能发生单点故障,配置多台反向代理服务器(如故障转移)会进一步增加复杂度。
来源及延伸阅读
- 反向代理与负载均衡
- NGINX 架构
- HAProxy 架构指南
- Wikipedia
应用层
资料来源:可缩放系统构架介绍
将 Web 服务层与应用层(也被称作平台层)分离,可以独立缩放和配置这两层。添加新的 API 只需要添加应用服务器,而不必添加额外的 web 服务器。
单一职责原则提倡小型的,自治的服务共同合作。小团队通过提供小型的服务,可以更激进地计划增长。
应用层中的工作进程也有可以实现异步化。
微服务
与此讨论相关的话题是 微服务,可以被描述为一系列可以独立部署的小型的,模块化服务。每个服务运行在一个独立的线程中,通过明确定义的轻量级机制通讯,共同实现业务目标。1
例如,Pinterest 可能有这些微服务: 用户资料、关注者、Feed 流、搜索、照片上传等。
服务发现
像 Consul,Etcd 和 Zookeeper 这样的系统可以通过追踪注册名、地址、端口等信息来帮助服务互相发现对方。Health checks 可以帮助确认服务的完整性和是否经常使用一个 HTTP 路径。Consul 和 Etcd 都有一个内建的 key-value 存储 用来存储配置信息和其他的共享信息。
不利之处:应用层
- 添加由多个松耦合服务组成的应用层,从架构、运营、流程等层面来讲将非常不同(相对于单体系统)。
- 微服务会增加部署和运营的复杂度。
来源及延伸阅读
- 可缩放系统构架介绍
- 破解系统设计面试
- 面向服务架构
- Zookeeper 介绍
- 构建微服务,你所需要知道的一切
数据库
资料来源:扩展你的用户数到第一个一千万
关系型数据库管理系统(RDBMS)
像 SQL 这样的关系型数据库是一系列以表的形式组织的数据项集合。
校对注:这里作者 SQL 可能指的是 MySQL
ACID 用来描述关系型数据库事务的特性。
- 原子性 - 每个事务内部所有操作要么全部完成,要么全部不完成。
- 一致性 - 任何事务都使数据库从一个有效的状态转换到另一个有效状态。
- 隔离性 - 并发执行事务的结果与顺序执行事务的结果相同。
- 持久性 - 事务提交后,对系统的影响是永久的。
关系型数据库扩展包括许多技术:主从复制、主主复制、联合、分片、非规范化和 SQL调优。
资料来源:可扩展性、可用性、稳定性、模式
主从复制
主库同时负责读取和写入操作,并复制写入到一个或多个从库中,从库只负责读操作。树状形式的从库再将写入复制到更多的从库中去。如果主库离线,系统可以以只读模式运行,直到某个从库被提升为主库或有新的主库出现。
不利之处:主从复制
- 将从库提升为主库需要额外的逻辑。
- 参考不利之处:复制中,主从复制和主主复制共同的问题。
资料来源:可扩展性、可用性、稳定性、模式
主主复制
两个主库都负责读操作和写操作,写入操作时互相协调。如果其中一个主库挂机,系统可以继续读取和写入。
不利之处: 主主复制
- 你需要添加负载均衡器或者在应用逻辑中做改动,来确定写入哪一个数据库。
- 多数主-主系统要么不能保证一致性(违反 ACID),要么因为同步产生了写入延迟。
- 随着更多写入节点的加入和延迟的提高,如何解决冲突显得越发重要。
- 参考不利之处:复制中,主从复制和主主复制共同的问题。
不利之处:复制
- 如果主库在将新写入的数据复制到其他节点前挂掉,则有数据丢失的可能。
- 写入会被重放到负责读取操作的副本。副本可能因为过多写操作阻塞住,导致读取功能异常。
- 读取从库越多,需要复制的写入数据就越多,导致更严重的复制延迟。
- 在某些数据库系统中,写入主库的操作可以用多个线程并行写入,但读取副本只支持单线程顺序地写入。
- 复制意味着更多的硬件和额外的复杂度。
来源及延伸阅读
- 扩展性,可用性,稳定性模式
- 多主复制
联合
资料来源:扩展你的用户数到第一个一千万
联合(或按功能划分)将数据库按对应功能分割。例如,你可以有三个数据库:论坛、用户和产品,而不仅是一个单体数据库,从而减少每个数据库的读取和写入流量,减少复制延迟。较小的数据库意味着更多适合放入内存的数据,进而意味着更高的缓存命中几率。没有只能串行写入的中心化主库,你可以并行写入,提高负载能力。
不利之处:联合
- 如果你的数据库模式需要大量的功能和数据表,联合的效率并不好。
- 你需要更新应用程序的逻辑来确定要读取和写入哪个数据库。
- 用 server link 从两个库联结数据更复杂。
- 联合需要更多的硬件和额外的复杂度。
来源及延伸阅读:联合
- 扩展你的用户数到第一个一千万
分片
资料来源:可扩展性、可用性、稳定性、模式
分片将数据分配在不同的数据库上,使得每个数据库仅管理整个数据集的一个子集。以用户数据库为例,随着用户数量的增加,越来越多的分片会被添加到集群中。
类似联合的优点,分片可以减少读取和写入流量,减少复制并提高缓存命中率。也减少了索引,通常意味着查询更快,性能更好。如果一个分片出问题,其他的仍能运行,你可以使用某种形式的冗余来防止数据丢失。类似联合,没有只能串行写入的中心化主库,你可以并行写入,提高负载能力。
常见的做法是用户姓氏的首字母或者用户的地理位置来分隔用户表。
不利之处:分片
- 你需要修改应用程序的逻辑来实现分片,这会带来复杂的 SQL 查询。
- 分片不合理可能导致数据负载不均衡。例如,被频繁访问的用户数据会导致其所在分片的负载相对其他分片高。
- 再平衡会引入额外的复杂度。基于一致性哈希的分片算法可以减少这种情况。
- 联结多个分片的数据操作更复杂。
- 分片需要更多的硬件和额外的复杂度。
来源及延伸阅读:分片
- 分片时代来临
- 数据库分片架构
- 一致性哈希
非规范化
非规范化试图以写入性能为代价来换取读取性能。在多个表中冗余数据副本,以避免高成本的联结操作。一些关系型数据库,比如 PostgreSQL 和 Oracle 支持物化视图,可以处理冗余信息存储和保证冗余副本一致。
当数据使用诸如联合和分片等技术被分割,进一步提高了处理跨数据中心的联结操作复杂度。非规范化可以规避这种复杂的联结操作。
在多数系统中,读取操作的频率远高于写入操作,比例可达到 100:1,甚至 1000:1。需要复杂的数据库联结的读取操作成本非常高,在磁盘操作上消耗了大量时间。
不利之处:非规范化
- 数据会冗余。
- 约束可以帮助冗余的信息副本保持同步,但这样会增加数据库设计的复杂度。
- 非规范化的数据库在高写入负载下性能可能比规范化的数据库差。
来源及延伸阅读:非规范化
- 非规范化
SQL 调优
SQL 调优是一个范围很广的话题,有很多相关的书可以作为参考。
利用基准测试和性能分析来模拟和发现系统瓶颈很重要。
- 基准测试 - 用 ab 等工具模拟高负载情况。
- 性能分析 - 通过启用如慢查询日志等工具来辅助追踪性能问题。
基准测试和性能分析可能会指引你到以下优化方案。
改进模式
-
为了实现快速访问,MySQL 在磁盘上用连续的块存储数据。
-
使用
CHAR类型存储固定长度的字段,不要用
VARCHAR。
CHAR在快速、随机访问时效率很高。如果使用VARCHAR,如果你想读取下一个字符串,不得不先读取到当前字符串的末尾。
-
使用
TEXT类型存储大块的文本,例如博客正文。TEXT还允许布尔搜索。使用TEXT字段需要在磁盘上存储一个用于定位文本块的指针。 -
使用
INT类型存储高达 2^32 或 40 亿的较大数字。 -
使用
DECIMAL类型存储货币可以避免浮点数表示错误。 -
避免使用
BLOBS存储实际对象,而是用来存储存放对象的位置。 -
VARCHAR(255)是以 8 位数字存储的最大字符数,在某些关系型数据库中,最大限度地利用字节。 -
在适用场景中设置
NOT NULL约束来提高搜索性能。
使用正确的索引
- 你正查询(
SELECT、GROUP BY、ORDER BY、JOIN)的列如果用了索引会更快。 - 索引通常表示为自平衡的 B 树,可以保持数据有序,并允许在对数时间内进行搜索,顺序访问,插入,删除操作。
- 设置索引,会将数据存在内存中,占用了更多内存空间。
- 写入操作会变慢,因为索引需要被更新。
- 加载大量数据时,禁用索引再加载数据,然后重建索引,这样也许会更快。
避免高成本的联结操作
- 有性能需要,可以进行非规范化。
分割数据表
- 将热点数据拆分到单独的数据表中,可以有助于缓存。
调优查询缓存
- 在某些情况下,查询缓存可能会导致性能问题。
来源及延伸阅读
- MySQL 查询优化小贴士
- 为什么 VARCHAR(255) 很常见?
- Null 值是如何影响数据库性能的?
- 慢查询日志
NoSQL
NoSQL 是键-值数据库、文档型数据库、列型数据库或图数据库的统称。数据库是非规范化的,表联结大多在应用程序代码中完成。大多数 NoSQL 无法实现真正符合 ACID 的事务,支持最终一致。
BASE 通常被用于描述 NoSQL 数据库的特性。相比 CAP 理论,BASE 强调可用性超过一致性。
- 基本可用 - 系统保证可用性。
- 软状态 - 即使没有输入,系统状态也可能随着时间变化。
- 最终一致性 - 经过一段时间之后,系统最终会变一致,因为系统在此期间没有收到任何输入。
除了在 SQL 还是 NoSQL 之间做选择,了解哪种类型的 NoSQL 数据库最适合你的用例也是非常有帮助的。我们将在下一节中快速了解下 键-值存储、文档型存储、列型存储和图存储数据库。
键-值存储
抽象模型:哈希表
键-值存储通常可以实现 O(1) 时间读写,用内存或 SSD 存储数据。数据存储可以按字典顺序维护键,从而实现键的高效检索。键-值存储可以用于存储元数据。
键-值存储性能很高,通常用于存储简单数据模型或频繁修改的数据,如存放在内存中的缓存。键-值存储提供的操作有限,如果需要更多操作,复杂度将转嫁到应用程序层面。
键-值存储是如文档存储,在某些情况下,甚至是图存储等更复杂的存储系统的基础。
来源及延伸阅读
- 键-值数据库
- 键-值存储的劣势
- Redis 架构
- Memcached 架构
文档类型存储
抽象模型:将文档作为值的键-值存储
文档类型存储以文档(XML、JSON、二进制文件等)为中心,文档存储了指定对象的全部信息。文档存储根据文档自身的内部结构提供 API 或查询语句来实现查询。请注意,许多键-值存储数据库有用值存储元数据的特性,这也模糊了这两种存储类型的界限。
基于底层实现,文档可以根据集合、标签、元数据或者文件夹组织。尽管不同文档可以被组织在一起或者分成一组,但相互之间可能具有完全不同的字段。
MongoDB 和 CouchDB 等一些文档类型存储还提供了类似 SQL 语言的查询语句来实现复杂查询。DynamoDB 同时支持键-值存储和文档类型存储。
文档类型存储具备高度的灵活性,常用于处理偶尔变化的数据。
来源及延伸阅读:文档类型存储
- 面向文档的数据库
- MongoDB 架构
- CouchDB 架构
- Elasticsearch 架构
列型存储
资料来源: SQL 和 NoSQL,一个简短的历史
抽象模型:嵌套的
ColumnFamily>映射
类型存储的基本数据单元是列(名/值对)。列可以在列族(类似于 SQL 的数据表)中被分组。超级列族再分组普通列族。你可以使用行键独立访问每一列,具有相同行键值的列组成一行。每个值都包含版本的时间戳用于解决版本冲突。
Google 发布了第一个列型存储数据库 Bigtable,它影响了 Hadoop 生态系统中活跃的开源数据库 HBase 和 Facebook 的 Cassandra。像 BigTable,HBase 和 Cassandra 这样的存储系统将键以字母顺序存储,可以高效地读取键列。
列型存储具备高可用性和高可扩展性。通常被用于大数据相关存储。
来源及延伸阅读:列型存储
- SQL 与 NoSQL 简史
- BigTable 架构
- Hbase 架构
- Cassandra 架构
图数据库
资料来源:图数据库
抽象模型: 图
在图数据库中,一个节点对应一条记录,一个弧对应两个节点之间的关系。图数据库被优化用于表示外键繁多的复杂关系或多对多关系。
图数据库为存储复杂关系的数据模型,如社交网络,提供了很高的性能。它们相对较新,尚未广泛应用,查找开发工具或者资源相对较难。许多图只能通过 REST API 访问。
相关资源和延伸阅读:图
- 图数据库
- Neo4j
- FlockDB
来源及延伸阅读:NoSQL
- 数据库术语解释
- NoSQL 数据库 - 调查及决策指南
- 可扩展性
- NoSQL 介绍
- NoSQL 模式
SQL 还是 NoSQL
资料来源:从 RDBMS 转换到 NoSQL
选取 SQL 的原因:
- 结构化数据
- 严格的模式
- 关系型数据
- 需要复杂的联结操作
- 事务
- 清晰的扩展模式
- 既有资源更丰富:开发者、社区、代码库、工具等
- 通过索引进行查询非常快
选取 NoSQL 的原因:
- 半结构化数据
- 动态或灵活的模式
- 非关系型数据
- 不需要复杂的联结操作
- 存储 TB (甚至 PB)级别的数据
- 高数据密集的工作负载
- IOPS 高吞吐量
适合 NoSQL 的示例数据:
- 埋点数据和日志数据
- 排行榜或者得分数据
- 临时数据,如购物车
- 频繁访问的(“热”)表
- 元数据/查找表
来源及延伸阅读:SQL 或 NoSQL
- 扩展你的用户数到第一个千万
- SQL 和 NoSQL 的不同
缓存
资料来源:可扩展的系统设计模式
缓存可以提高页面加载速度,并可以减少服务器和数据库的负载。在这个模型中,分发器先查看请求之前是否被响应过,如果有则将之前的结果直接返回,来省掉真正的处理。
数据库分片均匀分布的读取是最好的。但是热门数据会让读取分布不均匀,这样就会造成瓶颈,如果在数据库前加个缓存,就会抹平不均匀的负载和突发流量对数据库的影响。
客户端缓存
缓存可以位于客户端(操作系统或者浏览器),服务端或者不同的缓存层。
CDN 缓存
CDN 也被视为一种缓存。
Web 服务器缓存
反向代理和缓存(比如 Varnish)可以直接提供静态和动态内容。Web 服务器同样也可以缓存请求,返回相应结果而不必连接应用服务器。
数据库缓存
数据库的默认配置中通常包含缓存级别,针对一般用例进行了优化。调整配置,在不同情况下使用不同的模式可以进一步提高性能。
应用缓存
基于内存的缓存比如 Memcached 和 Redis 是应用程序和数据存储之间的一种键值存储。由于数据保存在 RAM 中,它比存储在磁盘上的典型数据库要快多了。RAM 比磁盘限制更多,所以例如 least recently used (LRU) 的缓存无效算法可以将「热门数据」放在 RAM 中,而对一些比较「冷门」的数据不做处理。
Redis 有下列附加功能:
- 持久性选项
- 内置数据结构比如有序集合和列表
有多个缓存级别,分为两大类:数据库查询和对象:
- 行级别
- 查询级别
- 完整的可序列化对象
- 完全渲染的 HTML
一般来说,你应该尽量避免基于文件的缓存,因为这使得复制和自动缩放很困难。
数据库查询级别的缓存
当你查询数据库的时候,将查询语句的哈希值与查询结果存储到缓存中。这种方法会遇到以下问题:
- 很难用复杂的查询删除已缓存结果。
- 如果一条数据比如表中某条数据的一项被改变,则需要删除所有可能包含已更改项的缓存结果。
对象级别的缓存
将您的数据视为对象,就像对待你的应用代码一样。让应用程序将数据从数据库中组合到类实例或数据结构中:
- 如果对象的基础数据已经更改了,那么从缓存中删掉这个对象。
- 允许异步处理:workers 通过使用最新的缓存对象来组装对象。
建议缓存的内容:
- 用户会话
- 完全渲染的 Web 页面
- 活动流
- 用户图数据
何时更新缓存
由于你只能在缓存中存储有限的数据,所以你需要选择一个适用于你用例的缓存更新策略。
缓存模式
资料来源:从缓存到内存数据网格
应用从存储器读写。缓存不和存储器直接交互,应用执行以下操作:
- 在缓存中查找记录,如果所需数据不在缓存中
- 从数据库中加载所需内容
- 将查找到的结果存储到缓存中
- 返回所需内容
def get_user(self, user_id):
user = cache.get("user.{0}", user_id)
if user is None:
user = db.query("SELECT * FROM users WHERE user_id = {0}", user_id)
if user is not None:
key = "user.{0}".format(user_id)
cache.set(key, json.dumps(user))
return user
Memcached 通常用这种方式使用。
添加到缓存中的数据读取速度很快。缓存模式也称为延迟加载。只缓存所请求的数据,这避免了没有被请求的数据占满了缓存空间。
缓存的缺点:
- 请求的数据如果不在缓存中就需要经过三个步骤来获取数据,这会导致明显的延迟。
- 如果数据库中的数据更新了会导致缓存中的数据过时。这个问题需要通过设置� TTL 强制更新缓存或者直写模式来缓解这种情况。
- 当一个节点出现故障的时候,它将会被一个新的节点替代,这增加了延迟的时间。
直写模式
资料来源:可扩展性、可用性、稳定性、模式
应用使用缓存作为主要的数据存储,将数据读写到缓存中,而缓存负责从数据库中读写数据。
- 应用向缓存中添加/更新数据
- 缓存同步地写入数据存储
- 返回所需内容
应用代码:
set_user(12345, {"foo":"bar"})
缓存代码:
def set_user(user_id, values):
user = db.query("UPDATE Users WHERE id = {0}", user_id, values)
cache.set(user_id, user)
由于存写操作所以直写模式整体是一种很慢的操作,但是读取刚写入的数据很快。相比读取数据,用户通常比较能接受更新数据时速度较慢。缓存中的数据不会过时。
直写模式的缺点:
- 由于故障或者缩放而创建的新的节点,新的节点不会缓存,直到数据库更新为止。缓存应用直写模式可以缓解这个问题。
- 写入的大多数数据可能永远都不会被读取,用 TTL 可以最小化这种情况的出现。
回写模式
资料来源:可扩展性、可用性、稳定性、模式
在回写模式中,应用执行以下操作:
- 在缓存中增加或者更新条目
- 异步写入数据,提高写入性能。
回写模式的缺点:
- 缓存可能在其内容成功存储之前丢失数据。
- 执行直写模式比缓存或者回写模式更复杂。
刷新
资料来源:从缓存到内存数据网格
你可以将缓存配置成在到期之前自动刷新最近访问过的内容。
如果缓存可以准确预测将来可能请求哪些数据,那么刷新可能会导致延迟与读取时间的降低。
刷新的缺点:
- 不能准确预测到未来需要用到的数据可能会导致性能不如不使用刷新。
缓存的缺点:
- 需要保持缓存和真实数据源之间的一致性,比如数据库根据缓存无效。
- 需要改变应用程序比如增加 Redis 或者 memcached。
- 无效缓存是个难题,什么时候更新缓存是与之相关的复杂问题。
相关资源和延伸阅读
- 从缓存到内存数据
- 可扩展系统设计模式
- 可缩放系统构架介绍
- 可扩展性,可用性,稳定性和模式
- 可扩展性
- AWS ElastiCache 策略
- 维基百科
异步
资料来源:可缩放系统构架介绍
异步工作流有助于减少那些原本顺序执行的请求时间。它们可以通过提前进行一些耗时的工作来帮助减少请求时间,比如定期汇总数据。
消息队列
消息队列接收,保留和传递消息。如果按顺序执行操作太慢的话,你可以使用有以下工作流的消息队列:
- 应用程序将作业发布到队列,然后通知用户作业状态
- 一个 worker 从队列中取出该作业,对其进行处理,然后显示该作业完成
不去阻塞用户操作,作业在后台处理。在此期间,客户端可能会进行一些处理使得看上去像是任务已经完成了。例如,如果要发送一条推文,推文可能会马上出现在你的时间线上,但是可能需要一些时间才能将你的推文推送到你的所有关注者那里去。
Redis 是一个令人满意的简单的消息代理,但是消息有可能会丢失。
RabbitMQ 很受欢迎但是要求你适应「AMQP」协议并且管理你自己的节点。
Amazon SQS 是被托管的,但可能具有高延迟,并且消息可能会被传送两次。
任务队列
任务队列接收任务及其相关数据,运行它们,然后传递其结果。 它们可以支持调度,并可用于在后台运行计算密集型作业。
Celery 支持调度,主要是用 Python 开发的。
背压
如果队列开始明显增长,那么队列大小可能会超过内存大小,导致高速缓存未命中,磁盘读取,甚至性能更慢。背压可以通过限制队列大小来帮助我们,从而为队列中的作业保持高吞吐率和良好的响应时间。一旦队列填满,客户端将得到服务器忙或者 HTTP 503 状态码,以便稍后重试。客户端可以在稍后时间重试该请求,也许是指数退避。
异步的缺点:
- 简单的计算和实时工作流等用例可能更适用于同步操作,因为引入队列可能会增加延迟和复杂性。
相关资源和延伸阅读
- 这是一个数字游戏
- 超载时应用背压
- 利特尔法则
- 消息队列与任务队列有什么区别?
通讯
资料来源:OSI 7层模型
超文本传输协议(HTTP)
HTTP 是一种在客户端和服务器之间编码和传输数据的方法。它是一个请求/响应协议:客户端和服务端针对相关内容和完成状态信息的请求和响应。HTTP 是独立的,允许请求和响应流经许多执行负载均衡,缓存,加密和压缩的中间路由器和服务器。
一个基本的 HTTP 请求由一个动词(方法)和一个资源(端点)组成。 以下是常见的 HTTP 动词:
| 动词 | 描述 | *幂等 | 安全性 | 可缓存 |
|---|---|---|---|---|
| GET | 读取资源 | Yes | Yes | Yes |
| POST | 创建资源或触发处理数据的进程 | No | No | Yes,如果回应包含刷新信息 |
| PUT | 创建或替换资源 | Yes | No | No |
| PATCH | 部分更新资源 | No | No | Yes,如果回应包含刷新信息 |
| DELETE | 删除资源 | Yes | No | No |
多次执行不会产生不同的结果。
HTTP 是依赖于较低级协议(如 TCP 和 UDP)的应用层协议。
来源及延伸阅读:HTTP
- README +
- HTTP 是什么?
- HTTP 和 TCP 的区别
- PUT 和 PATCH的区别
传输控制协议(TCP)
资料来源:如何制作多人游戏
TCP 是通过 IP 网络的面向连接的协议。 使用握手建立和断开连接。 发送的所有数据包保证以原始顺序到达目的地,用以下措施保证数据包不被损坏:
- 每个数据包的序列号和校验码。
- 确认包和自动重传
如果发送者没有收到正确的响应,它将重新发送数据包。如果多次超时,连接就会断开。TCP 实行流量控制和拥塞控制。这些确保措施会导致延迟,而且通常导致传输效率比 UDP 低。
为了确保高吞吐量,Web 服务器可以保持大量的 TCP 连接,从而导致高内存使用。在 Web 服务器线程间拥有大量开放连接可能开销巨大,消耗资源过多,也就是说,一个 memcached 服务器。连接池 可以帮助除了在适用的情况下切换到 UDP。
TCP 对于需要高可靠性但时间紧迫的应用程序很有用。比如包括 Web 服务器,数据库信息,SMTP,FTP 和 SSH。
以下情况使用 TCP 代替 UDP:
- 你需要数据完好无损。
- 你想对网络吞吐量自动进行最佳评估。
用户数据报协议(UDP)
资料来源:如何制作多人游戏
UDP 是无连接的。数据报(类似于数据包)只在数据报级别有保证。数据报可能会无序的到达目的地,也有可能会遗失。UDP 不支持拥塞控制。虽然不如 TCP 那样有保证,但 UDP 通常效率更高。
UDP 可以通过广播将数据报发送至子网内的所有设备。这对 DHCP 很有用,因为子网内的设备还没有分配 IP 地址,而 IP 对于 TCP 是必须的。
UDP 可靠性更低但适合用在网络电话、视频聊天,流媒体和实时多人游戏上。
以下情况使用 UDP 代替 TCP:
- 你需要低延迟
- 相对于数据丢失更糟的是数据延迟
- 你想实现自己的错误校正方法
来源及延伸阅读:TCP 与 UDP
- 游戏编程的网络
- TCP 与 UDP 的关键区别
- TCP 与 UDP 的不同
- 传输控制协议
- 用户数据报协议
- Memcache 在 Facebook 的扩展
远程过程调用协议(RPC)
Source: Crack the system design interview
在 RPC 中,客户端会去调用另一个地址空间(通常是一个远程服务器)里的方法。调用代码看起来就像是调用的是一个本地方法,客户端和服务器交互的具体过程被抽象。远程调用相对于本地调用一般较慢而且可靠性更差,因此区分两者是有帮助的。热门的 RPC 框架包括 Protobuf、Thrift 和 Avro。
RPC 是一个“请求-响应”协议:
- 客户端程序 ── 调用客户端存根程序。就像调用本地方法一样,参数会被压入栈中。
- 客户端 stub 程序 ── 将请求过程的 id 和参数打包进请求信息中。
- 客户端通信模块 ── 将信息从客户端发送至服务端。
- 服务端通信模块 ── 将接受的包传给服务端存根程序。
- 服务端 stub 程序 ── 将结果解包,依据过程 id 调用服务端方法并将参数传递过去。
RPC 调用示例:
GET /someoperation?data=anId
POST /anotheroperation
{
"data":"anId";
"anotherdata": "another value"
}
RPC 专注于暴露方法。RPC 通常用于处理内部通讯的性能问题,这样你可以手动处理本地调用以更好的适应你的情况。
当以下情况时选择本地库(也就是 SDK):
- 你知道你的目标平台。
- 你想控制如何访问你的“逻辑”。
- 你想对发生在你的库中的错误进行控制。
- 性能和终端用户体验是你最关心的事。
遵循 REST 的 HTTP API 往往更适用于公共 API。
缺点:RPC
- RPC 客户端与服务实现捆绑地很紧密。
- 一个新的 API 必须在每一个操作或者用例中定义。
- RPC 很难调试。
- 你可能没办法很方便的去修改现有的技术。举个例子,如果你希望在 Squid 这样的缓存服务器上确保 RPC 被正确缓存的话可能需要一些额外的努力了。
表述性状态转移(REST)
REST 是一种强制的客户端/服务端架构设计模型,客户端基于服务端管理的一系列资源操作。服务端提供修改或获取资源的接口。所有的通信必须是无状态和可缓存的。
RESTful 接口有四条规则:
- 标志资源(HTTP 里的 URI) ── 无论什么操作都使用同一个 URI。
- 表示的改变(HTTP 的动作) ── 使用动作, headers 和 body。
- 可自我描述的错误信息(HTTP 中的 status code) ── 使用状态码,不要重新造轮子。
- HATEOAS(HTTP 中的HTML 接口) ── 你的 web 服务器应该能够通过浏览器访问。
REST 请求的例子:
GET /someresources/anId
PUT /someresources/anId
{"anotherdata": "another value"}
REST 关注于暴露数据。它减少了客户端/服务端的耦合程度,经常用于公共 HTTP API 接口设计。REST 使用更通常与规范化的方法来通过 URI 暴露资源,通过 header 来表述并通过 GET、POST、PUT、DELETE 和 PATCH 这些动作来进行操作。因为无状态的特性,REST 易于横向扩展和隔离。
缺点:REST
- 由于 REST 将重点放在暴露数据,所以当资源不是自然组织的或者结构复杂的时候它可能无法很好的适应。举个例子,返回过去一小时中与特定事件集匹配的更新记录这种操作就很难表示为路径。使用 REST,可能会使用 URI 路径,查询参数和可能的请求体来实现。
- REST 一般依赖几个动作(GET、POST、PUT、DELETE 和 PATCH),但有时候仅仅这些没法满足你的需要。举个例子,将过期的文档移动到归档文件夹里去,这样的操作可能没法简单的用上面这几个 verbs 表达。
- 为了渲染单个页面,获取被嵌套在层级结构中的复杂资源需要客户端,服务器之间多次往返通信。例如,获取博客内容及其关联评论。对于使用不确定网络环境的移动应用来说,这些多次往返通信是非常麻烦的。
- 随着时间的推移,更多的字段可能会被添加到 API 响应中,较旧的客户端将会接收到所有新的数据字段,即使是那些它们不需要的字段,结果它会增加负载大小并引起更大的延迟。
RPC 与 REST 比较
| 操作 | RPC | REST |
|---|---|---|
| 注册 | POST /signup | POST /persons |
| 注销 | POST /resign { “personid”: “1234” } | DELETE /persons/1234 |
| 读取用户信息 | GET /readPerson?personid=1234 | GET /persons/1234 |
| 读取用户物品列表 | GET /readUsersItemsList?personid=1234 | GET /persons/1234/items |
| 向用户物品列表添加一项 | POST /addItemToUsersItemsList { “personid”: “1234”; “itemid”: “456” } | POST /persons/1234/items { “itemid”: “456” } |
| 更新一个物品 | POST /modifyItem { “itemid”: “456”; “key”: “value” } | PUT /items/456 { “key”: “value” } |
| 删除一个物品 | POST /removeItem { “itemid”: “456” } | DELETE /items/456 |
资料来源:你真的知道你为什么更喜欢 REST 而不是 RPC 吗
来源及延伸阅读:REST 与 RPC
- 你真的知道你为什么更喜欢 REST 而不是 RPC 吗
- 什么时候 RPC 比 REST 更合适?
- REST vs JSON-RPC
- 揭开 RPC 和 REST 的神秘面纱
- 使用 REST 的缺点是什么
- 破解系统设计面试
- Thrift
- 为什么在内部使用 REST 而不是 RPC
安全
这一部分需要更多内容。一起来吧!
安全是一个宽泛的话题。除非你有相当的经验、安全方面背景或者正在申请的职位要求安全知识,你不需要了解安全基础知识以外的内容:
- 在运输和等待过程中加密
- 对所有的用户输入和从用户那里发来的参数进行处理以防止 XSS 和 SQL 注入。
- 使用参数化的查询来防止 SQL 注入。
- 使用最小权限原则。
来源及延伸阅读
- 为开发者准备的安全引导
- OWASP top ten
附录
一些时候你会被要求做出保守估计。比如,你可能需要估计从磁盘中生成 100 张图片的缩略图需要的时间或者一个数据结构需要多少的内存。2 的次方表和每个开发者都需要知道的一些时间数据(译注:OSChina 上有这篇文章的译文)都是一些很方便的参考资料。
2 的次方表
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
来源及延伸阅读
- 2 的次方
每个程序员都应该知道的延迟数
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from disk 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
基于上述数字的指标:
- 从磁盘以 30 MB/s 的速度顺序读取
- 以 100 MB/s 从 1 Gbps 的以太网顺序读取
- 从 SSD 以 1 GB/s 的速度读取
- 以 4 GB/s 的速度从主存读取
- 每秒能绕地球 6-7 圈
- 数据中心内每秒有 2,000 次往返
延迟数可视化
来源及延伸阅读
- 每个程序员都应该知道的延迟数 — 1
- 每个程序员都应该知道的延迟数 — 2
- 关于建设大型分布式系统的的设计方案、课程和建议
- 关于建设大型可拓展分布式系统的软件工程咨询
其它的系统设计面试题
常见的系统设计面试问题,给出了如何解决的方案链接
| 问题 | 引用 |
|---|---|
| 设计类似于 Dropbox 的文件同步服务 | youtube.com |
| 设计类似于 Google 的搜索引擎 | queue.acm.org stackexchange.com ardendertat.com stanford.edu |
| 设计类似于 Google 的可扩展网络爬虫 | quora.com |
| 设计 Google 文档 | code.google.com neil.fraser.name |
| 设计类似 Redis 的键值存储 | slideshare.net |
| 设计类似 Memcached 的缓存系统 | slideshare.net |
| 设计类似亚马逊的推荐系统 | hulu.com ijcai13.org |
| 设计类似 Bitly 的短链接系统 | n00tc0d3r.blogspot.com |
| 设计类似 WhatsApp 的聊天应用 | highscalability.com |
| 设计类似 Instagram 的图片分享系统 | highscalability.com highscalability.com |
| 设计 Facebook 的新闻推荐方法 | quora.com quora.com slideshare.net |
| 设计 Facebook 的时间线系统 | facebook.com highscalability.com |
| 设计 Facebook 的聊天系统 | erlang-factory.com facebook.com |
| 设计类似 Facebook 的图表搜索系统 | facebook.com facebook.com facebook.com |
| 设计类似 CloudFlare 的内容传递网络 | cmu.edu |
| 设计类似 Twitter 的热门话题系统 | michael-noll.com snikolov .wordpress.com |
| 设计一个随机 ID 生成系统 | blog.twitter.com github.com |
| 返回一定时间段内次数前 k 高的请求 | ucsb.edu wpi.edu |
| 设计一个数据源于多个数据中心的服务系统 | highscalability.com |
| 设计一个多人网络卡牌游戏 | indieflashblog.com buildnewgames.com |
| 设计一个垃圾回收系统 | stuffwithstuff.com washington.edu |
| 添加更多的系统设计问题 | 贡献 |
真实架构
关于现实中真实的系统是怎么设计的文章。
Source: Twitter timelines at scale
不要专注于以下文章的细节,专注于以下方面:
- 发现这些文章中的共同的原则、技术和模式。
- 学习每个组件解决哪些问题,什么情况下使用,什么情况下不适用
- 复习学过的文章
| 类型 | 系统 | 引用 |
|---|---|---|
| Data processing | MapReduce - Google的分布式数据处理 | research.google.com |
| Data processing | Spark - Databricks 的分布式数据处理 | slideshare.net |
| Data processing | Storm - Twitter 的分布式数据处理 | slideshare.net |
| Data store | Bigtable - Google 的列式数据库 | harvard.edu |
| Data store | HBase - Bigtable 的开源实现 | slideshare.net |
| Data store | Cassandra - Facebook 的列式数据库 | slideshare.net |
| Data store | DynamoDB - Amazon 的文档数据库 | harvard.edu |
| Data store | MongoDB - 文档数据库 | slideshare.net |
| Data store | Spanner - Google 的全球分布数据库 | research.google.com |
| Data store | Memcached - 分布式内存缓存系统 | slideshare.net |
| Data store | Redis - 能够持久化及具有值类型的分布式内存缓存系统 | slideshare.net |
| File system | Google File System (GFS) - 分布式文件系统 | research.google.com |
| File system | Hadoop File System (HDFS) - GFS 的开源实现 | apache.org |
| Misc | Chubby - Google 的分布式系统的低耦合锁服务 | research.google.com |
| Misc | Dapper - 分布式系统跟踪基础设施 | research.google.com |
| Misc | Kafka - LinkedIn 的发布订阅消息系统 | slideshare.net |
| Misc | Zookeeper - 集中的基础架构和协调服务 | slideshare.net |
| 添加更多 | 贡献 |
公司的系统架构
| Company | Reference(s) |
|---|---|
| Amazon | Amazon 的架构 |
| Cinchcast | 每天产生 1500 小时的音频 |
| DataSift | 每秒实时挖掘 120000 条 tweet |
| DropBox | 我们如何缩放 Dropbox |
| ESPN | 每秒操作 100000 次 |
| Google 的架构 | |
| 1400 万用户,达到兆级别的照片存储 是什么在驱动 Instagram | |
| Justin.tv | Justin.Tv 的直播广播架构 |
| Facebook 的可扩展 memcached TAO: Facebook 社交图的分布式数据存储 Facebook 的图片存储 | |
| Flickr | Flickr 的架构 |
| Mailbox | 在 6 周内从 0 到 100 万用户 |
| 从零到每月数十亿的浏览量 1800 万访问用户,10 倍增长,12 名员工 | |
| Playfish | 月用户量 5000 万并在不断增长 |
| PlentyOfFish | PlentyOfFish 的架构 |
| Salesforce | 他们每天如何处理 13 亿笔交易 |
| Stack Overflow | Stack Overflow 的架构 |
| TripAdvisor | 40M 访问者,200M 页面浏览量,30TB 数据 |
| Tumblr | 每月 150 亿的浏览量 |
| Making Twitter 10000 percent faster 每天使用 MySQL 存储2.5亿条 tweet 150M 活跃用户,300K QPS,22 MB/S 的防火墙 可扩展时间表 Twitter 的大小数据 Twitter 的行为:规模超过 1 亿用户 | |
| Uber | Uber 如何扩展自己的实时化市场 |
| Facebook 用 190 亿美元购买 WhatsApp 的架构 | |
| YouTube | YouTube 的可扩展性 YouTube 的架构 |
公司工程博客
你即将面试的公司的架构
你面对的问题可能就来自于同样领域
- Airbnb Engineering
- Atlassian Developers
- Autodesk Engineering
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Cloudera Developer Blog
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Flickr Code
- Foursquare Engineering Blog
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- High Scalability
- Instagram Engineering
- Intel Software Blog
- Jane Street Tech Blog
- LinkedIn Engineering
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Quora Engineering
- Reddit Blog
- Salesforce Engineering Blog
- Slack Engineering Blog
- Spotify Labs
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
来源及延伸阅读
-
kilimchoi/engineering-blogs
-
使用 MapReduce 进行分布式计算
-
一致性哈希
-
直接存储器访问(DMA)控制器
-
贡献
-
Hired in tech
-
Cracking the coding interview
-
High scalability
-
checkcheckzz/system-design-interview
-
shashank88/system_design
-
mmcgrana/services-engineering
-
System design cheat sheet
-
A distributed systems reading list
-
Cracking the system design interview