python3的异常处理、操作excel和数据库
本篇主要讲python的异常处理、python操作excel、python操作mysql数据库、python操作redis数据库和操作mongodb数据库。
- 一、异常处理
针对python里出现的语法错误和不被程序处理的异常,为了让程序继续运行,这个时候就需要我们捕捉异常,通过捕捉到的异常,我们再进行相应的处理。通过try-except来处理,我们把所有可能引发错误的语句放在try块中,然后在except从句/块中处理所有的错误或异常。except从句可以专门处理单一的错误或异常,或者一组包括在圆括号内的错误/异常。如果没有给出错误或异常的名称,它会处理所有的错误和异常。对于每个try从家,至少都有一个相关联的except从句。
举个栗子:

python3异常处理的基本语法:
try:
#可能出现异常的代码
except Error as e: #把error错误归类成e
#出现异常怎么处理
else: #这部分可写也可不写
#如果没有出异常,执行else的语句
finally:#这部分可写也可不写
#无论try是否发生异常,finally的语句都会执行
举个栗子:name = ['rr','ww'] try: print(name[2]) except IndexError as e: print('下标越界')
举个完整的代码栗子:def calc(x,y): print('---------------------') try: res = x / y except TypeError as e: return '传入对象类型与要求不符' except Exception as e: print('其他异常') return e else: print('无异常,一切正常') return res finally: print('无论是否有异常,都要走到这里') print(calc(1,2))#这个没有出异常,走else和finally语句 print(calc(1,'x'))#这个出现传入参数类型不正确的异常,会返回传入对象类型与要求不符合,和执行finally的代码 print(calc(1,0))#由于除数不能为0,所以这里出现异常,就走捕获所有异常的代码,和执行finall的代码
1.except可以处理多个异常,将多个异常放入()并使用,逗号隔开x = input('input x:') y = input('input y:') try: print('x/y=',x/z) except (ZeroDivisionError,TypeError,NameError) as a:#捕捉多个可能的异常 print('异常')
2.python2.x语法跟python3.x存在差异:except语句上
name = ['rr','ww'] try: print(name[2]) except IndexError ,e: print('下标越界')
3.捕获多个异常的第二种写法x = int(input('input x:')) y = input('inpput y:') try: print('x+y=',x+z) except ZeroDivisionError:#捕捉除数为0的异常 print('除数不能为0') except TypeError as a: print('输入的类型不是整数')#输入的不是整数 except: print('其他异常')
常见的异常:
- Exception 所有异常的基类(当不知道具体的异常可用这个处理)
- AssertionError assert语句失败
- AttributeError 特性应用或赋值时引发(试图访问一个对象没有的属性)
- IOError 试图打开不存在的文件或者无全新的文件等操作时,就会引发(输入输入异常,基本是无法打开文件)
- ImportError 无法引入模块或包,基本是路径问题
- IndexError 在使用系列中不存在的索引时引发(下标索引超出序列边界)
- KeyError 试图访问你字典里不存在的键key
- KeyboardInterrupt Ctrl+C被按下
- NameError 使用一个未被赋予对象的变量
- SyntaxError Python代码逻辑语法出错不能执行
- TypeError 传入的对象类型与要求不符
- UnboundLocalError 试图访问一个还未被设置的全局变量,基本上是由于另有一个同名的全局变量
- ValueError 传入一个不被期望的值,即使类型正确
- ZeroDivisonError 在除数为零发生的一个异常
主动抛出异常:
raise语句运行程序,遇到异常不想处理,可以强制抛出一个具体的异常。a = 3 if a !=2: try: raise KeyError except KeyError as e: print('这是我们主动爆出的一个异常') else: print('3')
- 二、python 操作excel
python的操作分三种:读、写、修改。读excel操作用xlrd模块,写操作用xlwt模块,修改excel用xlutils模块。若你电脑已支持pip命令安装,则只需要cmd内输入pip install xlrd或pip install xlwt或pip install xlutils ,按回车就可安装成功。
1.读excel:基本用法如下
先打款一个excel文件,再选择一个sheet,最后读取表格信息#读excel:打开一个excel文件,选择一个sheet,再读取表格信息 import xlrd wb = xlrd.open_workbook('du.xlsx') #打开excel print(wb.sheet_names())#获取所有sheet页的名字 #sheet = wb.sheet_by_name('明天')#根据sheet页的名称获取到sheet页 sheet = wb.sheet_by_index(0)#根据sheet页的索引获取到sheet页 print(sheet.nrows)#获取sheet页的行 print(sheet.ncols)#获取sheet页的列 for num in range(sheet.nrows): print(sheet.row_values(num)) #获取每行的信息 xx = sheet.cell(2,0).value#获取指定单元格的值,第一个值是行,第二个值是列 print(xx)
2.写excel:基本用法如下
先新建一个excel对象,再新建一个sheet,最后开始在表格内写入信息import xlwt title=['姓名', '年龄', '爱好', '身高'] list = [['杭甬','34','打篮球','178'],['huhy','22','看书','200'],['dada','12','9','145']] #写excel:新建一个excel对象,再新建一个sheet页,最后开始在表格内写入信息 wbb = xlwt.Workbook()#新建一个excel对象 sheet = wbb.add_sheet('swrite')#新建一个名为'swrite'的sheet页 # sheet.write(0,0,'姓名')#逐个单元格写入信息 for i in range(len(title)):#写入表头 sheet.write(0,i,title[i])#写入第一行的每个表格,第一值是行,第二个值是列,最后一个是写入的值 for i in range(len(list)+1): if i != 0:#如果不是表头的话 for j in range(4): sheet.write(i,j,list[i-1][j])#循环写入每行 wbb.save('write.xls')
还有一种简单循环写入的逻辑,直接从第二行开始写入list的信息:for i in range(len(list)): for j in range(4): sheet.write(i+1,j,list[i][j])#从第二行开始循环写入每行 wbb.save('write.xls')
3.修改excel:具体方法如下:
先通过xlrd中的open_workbook方法读取excel,再通过xlutils模块的copy方法,复制一个新的excel,最后通过xlutils模块的write方法再对新的excel进行修改#修改excel from xlrd import open_workbook #导入xlrd模块中打开excel模块 from xlutils.copy import copy #导入xlutils模块的复制excel模块 rb = open_workbook('du.xlsx') wb = copy(rb)#复制一个新的excel wbsheet = wb.get_sheet(0)#通过xlutils模块中的get_sheet()方法获取sheet wbsheet.write(1,0,'huhuhy')#通过xlutils模块中的write方法修改单元格,第一个值是行,第二个值是列表,最后一个是修改的值 wb.save('duNew.xls')#这边保存的文件名称不要.xlsx做后缀,若保存成.xlsx后缀,文件打开会出现错误。提倡保存成.xls后缀
4.读写excel注意点:
(1)读Excel,后缀.xls/.xlsx都可以读
(2)写Excel的时候,保存的文件名必须以‘.xls’结尾,若保存成后缀‘.xlsx’的话,用微软的office打开excel会报错。 - 三、python操作mysql
操作mysql需要安装pymysql模块,操作包括查询数据、修改数据库数据、更新数据库的数据。import pymysql #创建连接,指定数据库的ip地址,账号、密码、端口号、要操作的数据库、字符集。其中端口号默认是3306 conn = pymysql.connect(host='xxx.xxx.x.xxx',port=3306,user='root',password='123456', db='test',charset='utf8' ) cursor = conn.cursor()#创建游标,游标类似指针(比如一条条获取数据的时候,游标也会跟着移动)
sql='select * from hhy' cur.execute(sql)#执行sql语句
##执行select查询语句,返回影响的行数 effect_row = cursor.execute('select * from user') ##执行insert插入数据语句,返回影响的行数 effect_row = cursor.execute("insert into user(name) values('hu2')") ##用executemay(sql,args)方法,执行插入多条数据,返回影响的行数 effect_row = cursor.executemany("insert into user(name) values(%s);",[("yys"),('hym')]) ##执行update更新数据,返回影响的行数# effect_row = cursor.execute("update user set name = '月月' where id =1;") #执行更新多条数据,返回影响的行数 effect_row = cursor.executemany("update user set name= '古hu古' where id = %s;",[1,2]) print(effect_row) print(cursor.fetchone())#获取查询结果的第一条数据,返回的是一个元组 print(cursor.fetchall())#获取查询的所有的数据,返回的是一个元组 print(cursor.fetchmany(2))#获取查询结果的前N条数据,返回的是一个元组 cur.scroll(0,mode='absolute')#移动游标,其中mode='relative':相对位置,mode='absolute':绝对位置 conn.commit()#提交事务,不然无法保存新建或者修改的数据,注意:select语句不需要commit() new_id = cursor.lastrowid #获取最新自增的ID cursor.close() #关闭游标 conn.close() #关闭连接
上面的查询语句,获取返回的都是元组,若想返回的是字典数据的话,方法如下:#如果想获取到的查询结果是一个字典类型的话,使用DictCursor()方法 import pymysql conn = pymysql.connect(host='xxx.168.xx.xxx',port=3306,user='root',password='123456', db='test',charset='utf8' ) cursor = conn.cursor() #指定游标的类型为字典 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) cursor.execute("select * from user") res = cursor.fetchall() print(res[2]['name'])
- python 操作redis数据库,操作redis需要安装redis模块。redis是一个key-value存储系统。它支持存储的value类型包含字符串string、list列表、set集合、hash哈希类型。redis是一种面向“键/值”对类型数据的分布式NoSQL数据库系统,数据存储在内存中,有很快的读写速度。redis没有表、没有SQL。
1.redis的安装参考牛牛大神的博客:http://nnzhp.cn/article/9/,安装成功后,通过Redis Desktop Manager 图形化工具连接redis,进行操作。
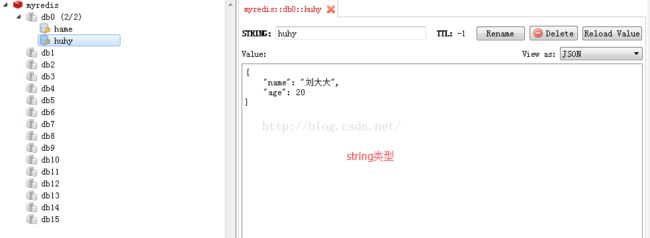
2.操作string类型import redis #连接redis,默认端口6379 r = redis.Redis(host='192.xxx.xx.xxx',port=6379,db=0) #其中的db指定数据库 #set string类型的值 r.set('huhy','{"name":"刘大大","age":20}') print(r.get('huhy').decode())#获得对应key的value值,若key不存在则返回None r.set('name_file:huhy','33')#建立文件夹name_file,在文件下建立key r.setnx('huhy','你好') #设置key的值,若key存在则不更新,若不存在的时候才会设置 print(r.get('huhy').decode())#获得对应key的value值,默认获取获得的value是字节类型,加上decode()转换成字符串 r.setex('name','value111',10)#设置name这个key的值,超时时间,过了时间key就会自动失效 print(r.get('name').decode()) r.mset({"name1":{"age":20,"性别":"女"},"name2":30})#批量设置key的值 print(r.mget('name1',"name2"))#批量获取key的value print(r.keys())#获取所有的key r.delete("name1")#删除key r.delete("name","name2")#批量删除key
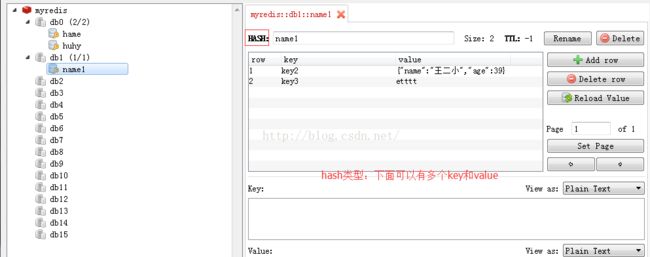
3.操作哈希类型r.hset("hame","hkey","hvalue")#设置哈希类型,给hame设置key和value r.hset("hame","hkey2","hvalue2")#hame下可以有多个key #给hame设置key和value,由于hkey1这个key已存在,所以不更改;只有key不存在才会添加key r.hsetnx("hame","hkey1","hvalue1111") r.hmset("hame",{"k1":"v1","k2":"v2"})#批量设置哈希类型的key和value #print(r.hget("hame","k1")#获取哈希类型hame下的k1这个key的值 print(r.hgetall('hame'))#获取哈希类型hame下所有key和value r.hdel("hame","k1")#删除hame下的k1这个key和value print(r.keys())#获取所有的key
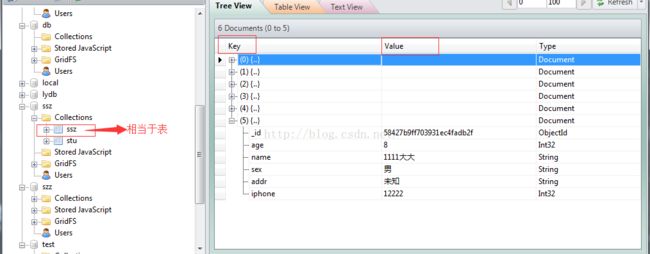
- python操作mongodb
Mongodb是一种nosql类型的数据库,Mongodb是把数据放在磁盘上。操作Mongodb数据库需要安装mongodb模块
1.Mongodb的安装参考牛牛大神的博客:http://nnzhp.cn/article/10/,安装成功后,通过MongoVUE图形化工具连接mongodb,进行操作
2.操作具体包含更新数据、查询数据、删除数据import pymongo #连接mongodb conn = pymongo.MongoClient(host='211.xxxx.xxx.xx',port=27017) db = conn.ssz# collection =db.ssz#使用数据库里面的某个集合,相当于表 #删除指定的集合,也就是删除表,导致key和valuew为空 #collection.drop() stu ={ 'name':'huhy', 'age':34, 'sex':'女' } stu2 ={ 'name':'王二', 'age':23, 'sex':'男', 'addr':'ee' } stus =[ { 'name': '1111大大', 'age': 23, 'sex': '男', 'addr': '未知' }, { 'name': '梅haunted', 'age': 899, 'sex': '未知', 'addr': '北极' } ] #collection.save(stu2)#插入单条数据到表中 #collection.insert(stus) #插入多条数据到表中,要插入多条的话,需要传一个list #$set 获取前面的结果集 #----更新数据 #collection.update({'name':'1111大大'},{'$set':{'age':8,'iphone':12222}},multi=True) #上面的update方法是在原来基础上更新数据,不加multi是默认更新第一条数据,加上multi=True则会更新所有key='1111大大'的value #collection.update({'name':'梅haunted'},{'name':'梅花','age':11,'iphone':12455}) #上面的update方法是更新数据,会破坏原来的数据结构 #-----删除数据 #collection.remove({'age':899})#删除指定的数据 #collection.remove()#删除全部的数据,全部的key和value #-----查询数据 #data = collection.find({'addr':'未知'})#查询指定的数据 #data = collection.find()#默认查询所有的数据 data = collection.find({'age':{'$ne':8}})#查询age不等于18的数据 for d in data:#通过循环来获取所有查询的数据 print(d)#每一条都是字典