Java专项
面向对象的五个基本原则:
单一职责原则(Single-Resposibility Principle):一个类,最好只做一件事,只有一个引起它的变化。单一职责原则可以看做是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因。
开放封闭原则(Open-Closed principle):软件实体应该是可扩展的,而不可修改的。也就是,对扩展开放,对修改封闭的。
Liskov替换原则(Liskov-Substituion Principle):子类必须能够替换其基类。这一思想体现为对继承机制的约束规范,只有子类能够替换基类时,才能保证系统在运行期内识别子类,这是保证继承复用的基础。
依赖倒置原则(Dependecy-Inversion Principle):依赖于抽象。具体而言就是高层模块不依赖于底层模块,二者都同依赖于抽象;抽象不依赖于具体,具体依赖于抽象。
接口隔离原则(Interface-Segregation Principle):使用多个小的专门的接口,而不要使用一个大的总接口
普通的类方法是可以和类名同名的,和构造方法唯一的区分就是,构造方法没有返回值。Java不支持类的多继承,支持接口的多继承
在JAVA中,我们都知道对象比较不能用 ==, 但是通常会忽略Integer这个对象。
这是由于在Integer的源码实现中,Integer 把-128-127 之间的每个值都建立了一
个对应的Integer 对象放入了一个数组中,这里的数组类似于缓存,提前给你准备好这
个范围内的对象。由于Integer 是不可变类,因此这些缓存的Integer 对象可以安全
的重复使用。
就是说在-128~127的范围内,我们误用==来比较大小,会得到正确的结果。但是一旦超
出这个范围,他们就指向不同的对象了,就要用equals()。一个字符常量表示为一个字符或一个转义序列,被一对ASCII单引号关闭。四个答案都采用的是双引号关闭,所以是字符串常量而不是字符常量。
Java一律采用Unicode编码方式,每个字符无论中文还是英文字符都占用2个字节,Java虚拟机中通常使用UTF-16的方式保存一个字符.
从运行层面上来看,从四个选项选出不同的一个:Java,Python,ObjectC,C#:
Python是解释执行的,其他语言都需要先编译
Python 只有它是动态语言
动态语言的定义:动态编程语言是高级程序设计语言的一个类别,在计算机科学领域已被广泛应用。它是一类在运行时可以改变其结构的语言:例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。动态语言目前非常具有活力。众所周知的ECMAScript(JavaScript)便是一个动态语言,除此之外如 PHP、Ruby、Python等也都属于动态语言,而C、C++等语言则不属于动态语言sleep和wait的区别有:
1,这两个方法来自不同的类分别是Thread和Object
2,最主要是sleep方法没有释放锁,而wait方法释放了锁,使得敏感词线程可以使用同步控制块或者方法。
3,wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在
任何地方使用
synchronized(x){
x.notify()
//或者wait()
}
4,sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
wait指线程处于进入等待状态,形象地说明为“等待使用CPU”,此时线程不占用任何资源,不增加时间限制。
sleep指线程被调用时,占着CPU不工作,形象地说明为“占着CPU睡觉”,此时,系统的CPU部分资源被占用,其他线程无法进入,会增加时间限制。注意:
1、java语言参数之间只有值传递,包括按值调用和按引用调用。 一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。
按值调用:包括八大基本数据类型都是按值调用。传值的时候,也就是说方法得到的是所有参数值的一个拷贝。
按引用调用:数组、对象。传值时候,传递的是引用地址的拷贝,但是都是指向同一个对象。
2、String是不可变类(final and Immutable),这里只是把副本的指向修改成指向“test ok”,原地址str的指向的值没有发生改变。mock对象:也成为伪对象,在测试中的利用mock对象来代替真实对象,方便测试的进行。
java的封装性:指的是将对象的状态信息隐藏在对象内部,不允许外部程序直接访问对象内部信息,通过该类提供的方法实现对内部信息的操作访问。
反射机制:在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性Collection:
-----List
-----LinkedList 非同步
-----ArrayList 非同步,实现了可变大小的元素数组
-----Vector 同步
------Stack 同步
-----Set 不允许有相同的元素
Map:
-----HashTable 同步,实现一个key--value映射的哈希表
-----HashMap 非同步,
-----WeakHashMap 改进的HashMap,实现了“弱引用”,如果一个key不被引用,则被GC回收
简单记忆线程安全的集合类: 喂!SHE! 喂是指 vector,S是指 stack, H是指 hashtable,E是指:Eenumeration
StringBuffer是线程安全的,相当于一个线程安全的StringBuilder
耐心看完,保证能懂这道题!
1. 只看尖括号里边的!!明确点和范围两个概念
2. 如果尖括号里的是一个类,那么尖括号里的就是一个点,比如List<A>,List<B>,List<Object>
3. 如果尖括号里面带有问号,那么代表一个范围, extends A> 代表小于等于A的范围, super A>代表大于等于A的范围,>代表全部范围
4. 尖括号里的所有点之间互相赋值都是错,除非是俩相同的点
5. 尖括号小范围赋值给大范围,对,大范围赋值给小范围,错。如果某点包含在某个范围里,那么可以赋值,否则,不能赋值
6. List>和List 是相等的,都代表最大范围
7.补充:List既是点也是范围,当表示范围时,表示最大范围
###父类的范围比子类大
public static void main(String[] args) {
List a;
List list;
list = a; //A对,因为List就是List,代表最大的范围,A只是其中的一个点,肯定被包含在内
List<B> b;
a = b; //B错,点之间不能相互赋值
List> qm;
List代表最大的范围,List<Object>只是一个点,肯定被包含在内
List<D> d;
List extends B> downB;
downB = d; //D对,List代表小于等于B的范围,List是一个点,在其中
Listextends A> downA;
a = downA; //E错,范围不能赋值给点
a = o; //F错,List
downA = downB; //G对,小于等于A的范围包含小于等于B的范围,因为B本来就比A小,B时A的子类嘛
}
重写(override):
方法名相同,参数类型相同
子类返回类型等于父类方法返回类型,
子类抛出异常小于等于父类方法抛出异常,
子类访问权限大于等于父类方法访问权限
重载:
方法名称相同,参数个数、次序、类型不同
因此重载对返回值没有要求,可以相同,也可以不同
但是如果参数的个数、类型、次序都相同,方法名也相同,仅返回值不同,则无法构成重载
父类的实例方法被子类的同名实例方法覆盖,
父类的静态方法被子类的同名静态方法隐藏,
覆盖只能适用于实例方法,不能用于静态方法。
静态方法只能隐藏,不能被覆盖。
数据类型的转换,分为自动转换和强制转换。自动转换是程序在执行过程中 “ 悄然 ” 进行的转换,不需要用户提前声明,一般是从位数低的类型向位数高的类型转换;强制类型转换则必须在代码中声明,转换顺序不受限制。
自动数据类型转换
自动转换按从低到高的顺序转换。不同类型数据间的优先关系如下:
低 ---------------------------------------------> 高
byte,short,char-> int -> long -> float -> double
强制数据类型转换
强制转换的格式是在需要转型的数据前加上 “( )” ,然后在括号内加入需要转化的数据类型。有的数据经过转型运算后,精度会丢失,而有的会更加精确运算中,不同类型的数据先转化为同一类型,然后进行运算,转换规则如下:
| 操作数 1 类型 | 操作数 2 类型 | 转换后的类型 |
|---|---|---|
| byte 、 short 、 char | int | int |
| byte 、 short 、 char 、 int | long | long |
| byte 、 short 、 char 、 int 、 long | float | float |
| byte 、 short 、 char 、 int 、 long、float | double | double |
1. byte a1 = 2, a2 = 4, a3;
2. short s = 16;
3. a2 = s;
4. a3 = a1 * a2;
Line 3 and 4 都会出错。
因为byte类型运算的时候自动转换为int类型,a1*a2结果为int类型,转为byte类型出错
byte b1=1,b2=2,b3,b6;
final byte b4=4,b5=6;
b6=b4+b5;
b3=(b1+b2);
System.out.println(b3+b6);
被final修饰的变量是常量,这里的b6=b4+b5可以看成是b6=10;在编译时就已经变为b6=10了
而b1和b2是byte类型,java中进行计算时候将他们提升为int类型,再进行计算,b1+b2计算后已经是int类型,赋值给b3,b3是byte类型,类型不匹配,编译不会通过,需要进行强制转换。Java中的byte,short,char进行计算时都会提升为int类型。
final修饰类、方法、属性!不能修饰抽象类,因为抽象类一般都是需要被继承的,final修饰后就不能继承了。
final修饰的方法不能被重写而不是重载!
final修饰属性,此属性就是一个常量,不能被再次赋值! public class Example extends Thread{
@Override
public void run(){
try{
Thread.sleep(1000);
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.print("run");
}
public static void main(String[] args){
Example example=new Example();
example.run();
System.out.print("main");
}
}
/*这个类虽然继承了Thread类,但是并没有真正创建一个线程。
创建一个线程需要覆盖Thread类的run方法,然后调用Thread类的start()方法启动
这里直接调用run()方法并没有创建线程,跟普通方法调用一样,是顺序执行的*/
输出:run main建议看看这篇博客 入门 通俗易懂 http://blog.csdn.net/sivyer123/article/details/17139443
简单的来说 java的堆内存分为两块:permantspace(持久带) 和 heap space。
持久带中主要存放用于存放静态类型数据,如 Java Class, Method 等, 与垃圾收集器要收集的Java对象关系不大。
而heapspace分为年轻带和年老带
年轻代的垃圾回收叫 Young GC, 年老代的垃圾回收叫 Full GC。
在年轻代中经历了N次(可配置)垃圾回收后仍然存活的对象,就会被复制到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象
年老代溢出原因有 循环上万次的字符串处理、创建上千万个对象、在一段代码内申请上百M甚至上G的内存,既A B D选项
持久代溢出原因 动态加载了大量Java类而导致溢出以下代码在编译和运行过程中会出现什么情况:
public class TestDemo{
private int count;
public static void main(String[] args) {
TestDemo test=new TestDemo(88);
System.out.println(test.count);
}
TestDemo(int a) {
count=a;
}
}
//private是私有变量,只能用于当前类中,题目中的main方法也位于当前类,所以可以正确输出Java程序的种类有:
(a)内嵌于Web文件中,由浏览器来观看的_Applet
(b)可独立运行的 Application
(c)服务器端的 Servlets
Java:
构造函数:
在java中,子类构造器会默认调用super()(无论构造器中是否写有super()),用于初始化父类成员,同时当父类中存在有参构造器时,必须提供无参构造器,子类构造器中并不会自动继承有参构造器,仍然默认调用super(),使用无参构造器。因此,一个类想要被继承必须提供无参构造器。
PS:方法没有继承一说,只有重载和重写
初始化过程是这样的:
1.首先,初始化父类中的静态成员变量和静态代码块,按照在程序中出现的顺序初始化;
2.然后,初始化子类中的静态成员变量和静态代码块,按照在程序中出现的顺序初始化;
3.其次,初始化父类的普通成员变量和代码块,再执行父类的构造方法;
4.最后,初始化子类的普通成员变量和代码块,再执行子类的构造方法;
1:构造方法可以被重载,一个构造方法可以通过this关键字调用另一个构造方法,this语句必须位于构造方法的第一行;
重载:方法的重载(overload):重载构成的条件:方法的名称相同,但参数类型或参数个数不同,才能构成方法的重载。
2 当一个类中没有定义任何构造方法,Java将自动提供一个缺省构造方法;
3 子类通过super关键字调用父类的一个构造方法;
4 当子类的某个构造方法没有通过super关键字调用父类的构造方法,通过这个构造方法创建子类对象时,会自动先调用父类的缺省构造方法
5 构造方法不能被static、final、synchronized、abstract、native修饰,但可以被public、private、protected修饰;
6 构造方法不是类的成员方法;
7 构造方法不能被继承。java关键字:
java中true ,false , null在java中不是关键字,也不是保留字,它们只是显式常量值,但是你在程序中不能使用它们作为标识符。
其中const和goto是java的保留字。java中所有的关键字都是小写的,还有要注意true,false,null, friendly,sizeof不是java的关键字,但是你不能把它们作为java标识符用。
java包装类:
Java 语言是一个面向对象的语言,但是Java中的基本数据类型却是不面向对象的,这在实际使用时存在很多的不便,为了解决这个不足,在设计类时为每个基本数据类型设计了一个对应的类进行代表,即包装类。对应的基本类型和包装类如下表:

初始化:
类变量在不设置初始值时,会进行默认值赋值,而局部方法中声明的变量则必须进行初始化,他不会进行默认值赋值。
Java中基本数据类型默认值为:
short: 0 int: 0 long:0 float: 0.0 double: 0.0 char:0 String:null
Java中对象引用默认值为null: **包装类型的初始化为Null
子类构造方法在调用时必须先调用父类的,由于父类没有无参构造,必须在子类中显式调用,修改子类构造方法如下即可:
public Derived(String s){
super(“s”);
System.out.print(“D”);
}
class和interface:
public可以被当前类,子类,包,其他包,访问,
protected 可以被当前类,子类,包访问
default可以被可以被当前类,包内访问(default不能修饰变量);
private只能被当前类访问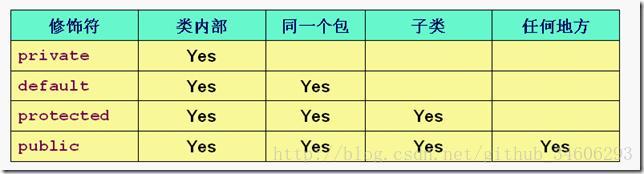
定义navtive方法时,并不提供实现体,因为其实现体是用非Java语言在外面实现的。native可以和任何修饰符连用,abstract除外。因为native暗示这个方法时有实现体的,而abstract却显式指明了这个方法没有实现体。
抽象类 : 类中至少有一个方法是抽象方法,则该类就是抽象类
接口 :类中的方法全部都是抽象方法。
下面比较一下两者的语法区别:
1.抽象类可以有构造方法,接口中不能有构造方法。
2.抽象类中可以有普通成员变量,接口中没有普通成员变量
3.抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
4. 抽象类中的抽象方法的访问类型可以是public,protected和(默认类型,虽然
eclipse下不报错,但应该也不行),但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。
5. 抽象类中可以包含静态方法,接口中不能包含静态方法
6. 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public static final类型。
7. 一个类可以实现多个接口,但只能继承一个抽象类。
8.接口中可以不声明任何方法,和成员变量
9.抽象类可以不包含抽象方法,但有抽象方法的类一定要声明为抽象类
用abstract修饰的方法表示抽象方法,抽象方法没有方法体。
一个抽象类中的方法不一定是抽象方法,即其中的方法可以有实现(有方法体),接口中的方法都是抽象方法,不能有方法体,只有声明;
接口中的变量默认是public static final 的,方法默认是public abstract 的Arrays.asList(),其将一个数组转化为一个List对象,这个方法会返回一个ArrayList类型的对象, 这个ArrayList类并非java.util.ArrayList类,而是Arrays类的内部类java.util.ArrayList.ArrayListJVM:
原因:jvm里面有两个存储区,一个是暂存区(是一个堆栈,以下称为堆栈),另一个是变量区。
步骤1:jvm会这样运行这条语句,JVM把count值(其值是0)拷贝到临时变量区。
步骤2:count值加1,这时候count的值是1。
步骤3:返回临时变量区的值,注意这个值是0,没修改过。
步骤4:返回值赋值给count,此时count值被重置成0。
c/c++中没有另外设置一个临时变量或是临时空间来保存i,所有操作都是在一个内存空间中完成的,所以在c/c++中是1。
Java中 i=i++与i++ 的结果不同JVM内存总体一共分为了
4个部分(stack segment、heap segment、code segment、data segment)
当我们在程序中声明一个局部变量的时候,此变量就存放在了 stack segment(栈)当中;
当new 一个对象的时候,此对象放在了heap segment(堆)当中;
static 的变量或者字符串常量 则存在在 data segment(数据区)中;
类中方法是存在在 code segment(代码区)中。-Xmx:最大堆大小
-Xms:初始堆大小
-Xmn:年轻代大小
-XXSurvivorRatio:年轻代中Eden区与Survivor区的大小比值
年轻代5120m, Eden:Survivor=3,Survivor区大小=1024m(Survivor区有两个,即将年轻代分为5份,每个Survivor区占一份),总大小为2048m。
-Xms初始堆大小即最小内存值为10240m
A: 垃圾回收在jvm中优先级相当相当低。
B:垃圾收集器(GC)程序开发者只能推荐JVM进行回收,但何时回收,回收哪些,程序员不能控制。
C:垃圾回收机制只是回收不再使用的JVM内存,如果程序有严重BUG,照样内存溢出。
D:进入DEAD的线程,它还可以恢复,GC不会回收类方法和实例方法:
关于类方法的使用,有如下一些限制:
1. 在类方法中不能引用对象变量。
2. 在类方法中不能使用super、this关键字。
3. 类方法不能调用类中的对象方法。
与类方法相比,实例方法几乎没有什么限制:
1. 实例方法可以引用对象变量(这是显然的),也可以引用类变量。
2. 实例方法中可以使用super、this关键字。
3. 实例方法中可以调用类方法。
实例方法可以对当前对象的实例变量进行操作,也可以对类变量进行操作,但类方法不能访问实例变量。实例方法必须由实例对象来调用,而类方法除了可由实例对象调用外,还可以由类名直接调用。
多态:
//多态:父类型的引用可以指向子类型的对象,但是无法调用子类独有的方法。
与函数重载不同
在方法调用的时候发现,父类里没有的函数,在多态实现的时候不能出现。
父类里如果有调用的是子类的同名方法。
Base base=new Son(); 是多态的表示形式。父类对象调用了子类创建了Son对象。
base调用的method()方法就是调用了子类重写的method()方法。
而此时base还是属于Base对象,base调用methodB()时Base对象里没有这个方法,所以编译不通过。
要想调用的话需要先通过SON son=(SON)base;强制转换,然后用son.methodB()调用就可以了。static:
类的静态成员与类直接相关,与对象无关,在一个类的所有实例之间共享同一个静态成员
静态成员函数中不能调用非静态成员
非静态成员函数中可以调用静态成员
常量成员才不能修改,静态成员变量必须初始化,但可以修改(例如我们常利用静态成员变量统计某个函数的调用次数)
类变量存储在方法区,不属于每个实例的私有public class TestClass {
private static void testMethod(){
System.out.println("testMethod");
}
public static void main(String[] args) {
((TestClass)null).testMethod();
}
}
1)此处是类对方法的调用,不是对象对方法的调用。
2)方法是static静态方法,直接使用"类.方法"即可,因为静态方法使用不依赖对象是否被创建。
null可以被强制类型转换成任意类型(不是任意类型对象),于是可以通过它来执行静态方法。
3)非静态的方法用"对象.方法"的方式,必须依赖对象被创建后才能使用,若将testMethod()方法前的static去掉,则会报 空指针异常 。
当然,不管是否静态方法,都是已经存在的,只是访问方式不同。public class B
{
public static B t1 = new B();
public static B t2 = new B();
{
System.out.println("构造块");
}
static
{
System.out.println("静态块");
}
public static void main(String[] args)
{
B t = new B();
}
}
静态块:用static申明,JVM加载类时执行,仅执行一次
构造块:类中直接用{}定义,每一次创建对象时执行
执行顺序优先级:静态块>main()>构造块>构造方法
静态块按照申明顺序执行,所以先执行publicstaticB t1 = newB();该语句创建对象,则又会调用构造块,输出构造块
接着执行public static B t1 = new B();输出构造块
再执行
static
{
System.out.println("静态块");
}输出静态块
最后main方法执行,创建对象,输出构造块。class Test {
public static void hello() {
System.out.println("hello");
}
}
public class MyApplication {
public static void main(String[] args) {
// TODO Auto-generated method stub
Test test=null;
test.hello();
}
}
A就相当于Test.hello()
值得一说的是有些人以为是空指针,这里你们所说的空指针必须是去引用堆对象才会有空指针
而这个hello是static类型的,人家static的方法本身就没有指针,所以当然不会有空指针
static 的变量或者字符串常量 则存在在 data segment(数据区)中;
类中方法是存在在 code segment(代码区)中。多线程:
wait()、notify()和notifyAll()是 Object类 中的方法
从这三个方法的文字描述可以知道以下几点信息:
1)wait()、notify()和notifyAll()方法是本地方法,并且为final方法,无法被重写。
2)调用某个对象的wait()方法能让当前线程阻塞,并且当前线程必须拥有此对象的monitor(即锁)
3)调用某个对象的notify()方法能够唤醒一个正在等待这个对象的monitor的线程,如果有多个线程都在等待这个对象的monitor,则只能唤醒其中一个线程;
4)调用notifyAll()方法能够唤醒所有正在等待这个对象的monitor的线程;
//有朋友可能会有疑问:为何这三个不是Thread类声明中的方法,而是Object类中声明的方法(当然由于Thread类继承了Object类,所以Thread也可以调用者三个方法)?其实这个问题很简单,由于每个对象都拥有monitor(即锁),所以让当前线程等待某个对象的锁,当然应该通过这个对象来操作了。而不是用当前线程来操作,因为当前线程可能会等待多个线程的锁,如果通过线程来操作,就非常复杂了。
Condition是在java 1.5中才出现的,它用来替代传统的Object的wait()、notify()实现线程间的协作,相比使用Object的wait()、notify(),使用Condition1的await()、signal()这种方式实现线程间协作更加安全和高效。因此通常来说比较推荐使用Condition,在阻塞队列那一篇博文中就讲述到了,阻塞队列实际上是使用了Condition来模拟线程间协作。
Condition是个接口,基本的方法就是await()和signal()方法;
Condition依赖于Lock接口,生成一个Condition的基本代码是lock.newCondition()
调用Condition的await()和signal()方法,都必须在lock保护之内,就是说必须在lock.lock()和lock.unlock之间才可以使用Conditon中的await()对应Object的wait(); Condition中的signal()对应Object的notify(); Condition中的signalAll()对应Object的notifyAll()
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
volatile只提供了保证访问该变量时,每次都是从内存中读取最新值,并不会使用寄存器缓存该值——每次都会从内存中读取。
而对该变量的修改,volatile并不提供原子性的保证。
由于及时更新,很可能导致另一线程访问最新变量值,无法跳出循环的情况
多线程下计数器必须使用锁保护。CopyOnWriteArrayList适合使用在读操作远远大于写操作的场景里,比如缓存。
ReadWriteLock 当写操作时,其他线程无法读取或写入数据,而当读操作时,其它线程无法写入数据,但却可以读取数据 。适用于 读取远远大于写入的操作。IO:
字节流继承于InputStream OutputStream,字符流继承于InputStreamReader OutputStreamWriter
字节流:
InputStream
- |– FileInputStream (基本文件流)
- |– BufferedInputStream
- |– DataInputStream
- |– ObjectInputStream
字符流:
Reader
- |– InputStreamReader (byte->char 桥梁)
- |– BufferedReader (常用)
Writer
- |– OutputStreamWriter (char->byte 桥梁)
- |– BufferedWriter
- |– PrintWriter (常用)
JSP:
getParameter()是获取POST/GET传递的参数值;
getInitParameter获取Tomcat的server.xml中设置Context的初始化参数
getAttribute()是获取对象容器中的数据值;
getRequestDispatcher是请求转发。
redirect:
请求重定向:客户端行为,本质上为2次请求,地址栏改变,前一次请求对象消失。举例:你去银行办事(forward.jsp),结果告诉你少带了东西,你得先去公安局办(index.html)临时身份证,这时你就会走出银行,自己前往公安局,地址栏变为index.html.
forward:
请求转发:服务器行为,地址栏不变。举例:你把钱包落在出租车上,你去警察局(forward.jsp)报案,警察局说钱包落在某某公司的出租车上(index.html),这时你不用亲自去找某某公司的出租车,警察局让出租车自己给你送来,你只要在警察局等就行。所以地址栏不变,依然为forward.jsp异常:
public void getCustomerInfo() {
try {
// do something that may cause an Exception
} catch (java.io.FileNotFoundException ex) {
System.out.print("FileNotFoundException!");
} catch (java.io.IOException ex) {
System.out.print("IOException!");
} catch (java.lang.Exception ex) {
System.out.print("Exception!");
}
}
/*代码块中的do something that may cause an Exception说明程序运行时只会抛出一个异常, 但没有 指明
是什么异常,三种异常均有可能。对于某个异常,只会被捕获一次, 因而只有A是可能的答案, 另外三个
选 项都 捕获了多个异常,与题意不符。*/
error类异常主要是运行时逻辑错误导致,一个正确程序中是不应该出现error的。当出现error一般jvm会终止。
exception表示可恢复异常,包括检查异常和运行时异常。 检查异常是最常见异常比如 io异常sql异常,都发生在编译阶段。这类通过try、catch捕捉
而运行时异常,编译器没有强制对其进行捕捉和处理。一般都会把异常向上抛出,直到遇到处理代码位置,若没有处理块就会抛到最上层,多线程用thread.run()抛出,单线程用main()抛出。常见的运行异常包括 空指针异常 类型转换异常 数组月结异常 数组存储异常 缓冲区溢出异常 算术异常等!
· 运行时异常没有要求必须通过try块来捕捉!!!!
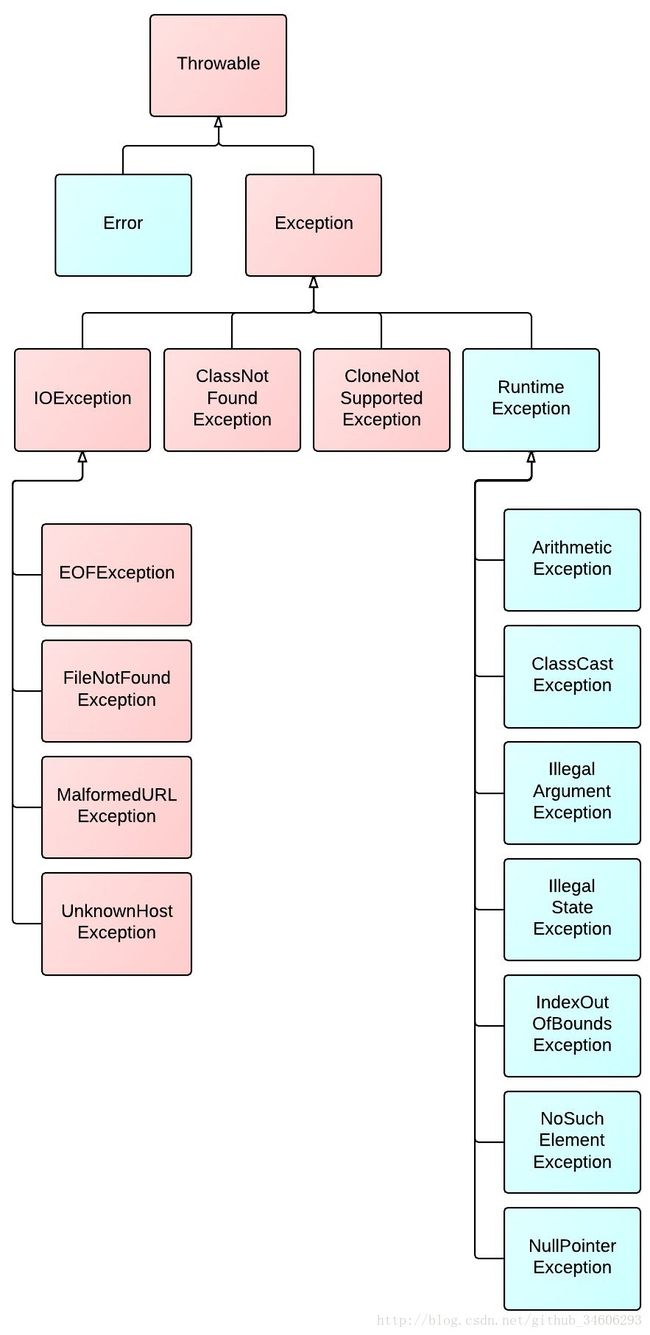
1. 粉红色的是受检查的异常(checked exceptions),其必须被 try{}catch语句块所捕获,或者在方法签名里通过throws子句声明.受检查的异常必须在编译时被捕捉处理,命名为 Checked Exception 是因为Java编译器要进行检查,Java虚拟机也要进行检查,以确保这个规则得到遵守.
2. 绿色的异常是运行时异常(runtime exceptions),需要程序员自己分析代码决定是否捕获和处理,比如 空指针,被0除…
3. 而声明为Error的,则属于严重错误,如系统崩溃、虚拟机错误、动态链接失败等,这些错误无法恢复或者不可能捕捉,将导致应用程序中断,Error不需要捕捉。
Java语言中的异常处理包括声明异常、抛出异常、捕获异常和处理异常四个环节。
- throw用于抛出异常。
- throws关键字可以在方法上声明该方法要抛出的异常,然后在方法内部通过throw抛出异常对象。
- try是用于检测被包住的语句块是否出现异常,如果有异常,则抛出异常,并执行catch语句。
- cacth用于捕获从try中抛出的异常并作出处理。
- finally语句块是不管有没有出现异常都要执行的内容。
finally:
try catch finally.
finally 并不一定会执行:
1.相应的try块没有执行到,finally就不执行
2.在try块中,调用了System.exit(),终止了Java虚拟机的运行,也不执行
3.执行 try 语句块或者 catch 语句块时被打断(interrupted)或者被终止(killed)在排除了以上 finally 语句块不执行的情况后,finally 语句块就得保证要执行,finally 语句块是在 try 或者 catch 中的 return 和 throw 语句之前执行的。更加一般的说法是,finally 语句块应该是在控制转移语句之前执行,控制转移语句除了 return 外,还有 break 和 continue。
参考关于 Java 中 finally 语句块的深度辨析
Servlet:
Servlet的生命周期分为5个阶段:加载、创建、初始化、处理客户请求、卸载。
(1)加载:容器通过类加载器使用servlet类对应的文件加载servlet
(2)创建:通过调用servlet构造函数创建一个servlet对象
(3)初始化:调用init方法初始化
(4)处理客户请求:每当有一个客户请求,容器会创建一个线程来处理客户请求
(5)卸载:调用destroy方法让servlet自己释放其占用的资源
//创建实例是在初始化之前,由Servlet容器来完成JDBC:
桥接模式:
定义 :将抽象部分与它的实现部分分离,使它们都可以独立地变化。
意图 :将抽象与实现解耦。
桥接模式所涉及的角色
1. Abstraction :定义抽象接口,拥有一个Implementor类型的对象引用
2. RefinedAbstraction :扩展Abstraction中的接口定义
3. Implementor :是具体实现的接口,Implementor和RefinedAbstraction接口并不一定完全一致,实际上这两个接口可以完全不一样Implementor提供具体操作方法,而Abstraction提供更高层次的调用
4. ConcreteImplementor :实现Implementor接口,给出具体实现
Jdk中的桥接模式:JDBC
JDBC连接 数据库 的时候,在各个数据库之间进行切换,基本不需要动太多的代码,甚至丝毫不动,原因就是JDBC提供了统一接口,每个数据库提供各自的实现,用一个叫做数据库驱动的程序来桥接就行了
PreparedStatement与Statement:
JDBC提供了Statement、PreparedStatement 和 CallableStatement三种方式来执行查询语句,其中 Statement 用于通用查询, PreparedStatement 用于执行参数化查询,而 CallableStatement则是用于存储过程
1:创建时的区别:
Statement statement = conn.createStatement();
PreparedStatement preStatement = conn.prepareStatement(sql);
执行的时候:
ResultSet rSet = statement.executeQuery(sql);
ResultSet pSet = preStatement.executeQuery();
由上可以看出,PreparedStatement有预编译的过程,已经绑定sql,之后无论执行多少遍,都不会再去进行编译,
而 statement 不同,如果执行多变,则相应的就要编译多少遍sql,所以从这点看,preStatement 的效率会比 Statement要高一些
所以总体而言, 验证 preStatement 的效率 比 Statement 的效率高
2>安全性问题
这个就不多说了,preStatement是预编译的,所以可以有效的防止 SQL注入等问题
所以 preStatement 的安全性 比 Statement 高
3>代码的可读性 和 可维护性
这点也不用多说了,你看老代码的时候 会深有体会
preStatement更胜一筹ResultSet跟普通的数组不同,索引从1开始而不是从0开始
Maven 和 Ant:
Ant和Maven都是基于Java的构建(build)工具。理论上来说,有些类似于(Unix)C中的make ,但没有make的缺陷。Ant是软件构建工具,Maven的定位是软件项目管理和理解工具。
Ant特点 :
没有一个约定的目录结构 ›必须明确让ant做什么,什么时候做,然后编译,打包 ›没有生命周期,必须定义目标及其实现的任务序列 ›没有集成依赖管理
Maven特点 :
拥有约定,知道你的代码在哪里,放到哪里去 ›拥有一个生命周期,例如执行 mvn install 就可以自动执行编译,测试,打包等构建过程 ›只需要定义一个pom.xml,然后把源码放到默认的目录,Maven帮你处理其他事情 ›拥有依赖管理,仓库管理
SpringMVC:
Struts工作原理
MVC即Model-View-Controller的缩写,是一种常用的设计模式。MVC 减弱了业务逻辑接口和数据接口之间的耦合,以及让视图层更富于变化。
Struts 是MVC的一种实现,它将 Servlet和 JSP 标记(属于 J2EE 规范)用作实现的一部分。Struts继承了MVC的各项特性,并根据J2EE的特点,做了相应的变化与扩展。
控 制:有一个XML文件Struts-config.xml,与之相关联的是Controller,在Struts中,承担MVC中Controller角 色的是一个Servlet,叫ActionServlet。ActionServlet是一个通用的控制组件。这个控制组件提供了处理所有发送到 Struts的HTTP请求的入口点。它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。另外控制组件也负责用相应的请求参数 填充 Action From(通常称之为FromBean),并传给动作类(通常称之为ActionBean)。动作类实现核心商业逻辑,它可以访问java bean 或调用EJB。最后动作类把控制权传给后续的JSP 文件,后者生成视图。所有这些控制逻辑利用Struts-config.xml文件来配置。
视图:主要由JSP生成页面完成视图,Struts提供丰富的JSP 标签库: Html,Bean,Logic,Template等,这有利于分开表现逻辑和程序逻辑。
模 型:模型以一个或多个java bean的形式存在。这些bean分为三类:Action Form、Action、JavaBean or EJB。Action Form通常称之为FormBean,封装了来自于Client的用户请求信息,如表单信息。Action通常称之为ActionBean,获取从 ActionSevlet传来的FormBean,取出FormBean中的相关信息,并做出相关的处理,一般是调用Java Bean或EJB等。
流程:在Struts中,用户的请求一般以*.do作为请求服务名,所有的*.do请求均被指向 ActionSevlet,ActionSevlet根据Struts-config.xml中的配置信息,将用户请求封装成一个指定名称的 FormBean,并将此FormBean传至指定名称的ActionBean,由ActionBean完成相应的业务操作,如文件操作,数据库操作等。 每一个*.do均有对应的FormBean名称和ActionBean名称,这些在Struts-config.xml中配置。
核心:Struts的核心是ActionSevlet,ActionSevlet的核心是Struts-config.xml。
- 在Struts中,承担MVC中Controller角色的是一个Servlet,叫ActionServlet。ActionServlet提供了处理所有发送到 Struts的HTTP请求的入口点。它截取和分发这些请求到相应的动作类(这些动作类都是Action类的子类)。
- Action 则是属于Model