【python实现网络爬虫(9)】Selenium框架实现笑话大全数据爬取(点赞数和被踩数无法获取的问题)
回顾
经过前两个爬虫的实际操作,发现在爬取笑话大全网址上面,无法获得点赞量和被踩量的数据,相应的标签如下
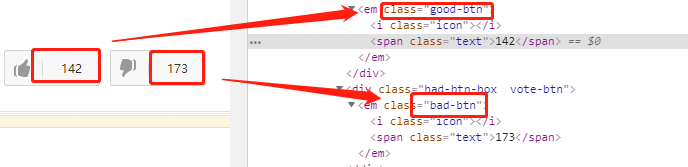
1)在scrapy中获取相应的标签信息输出的结果为:(可以看出可以找到匹配的标签,但是里面的内容是空的)
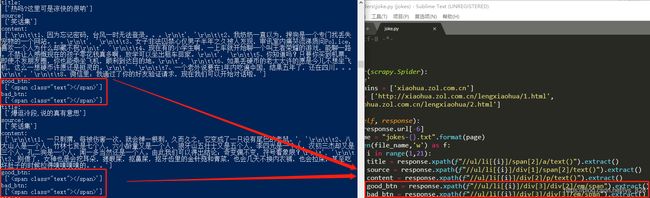
2) 使用requests+bs4进行获取:(可以看出这里和上面的输出结果一样,标签里面都是没有信息的)
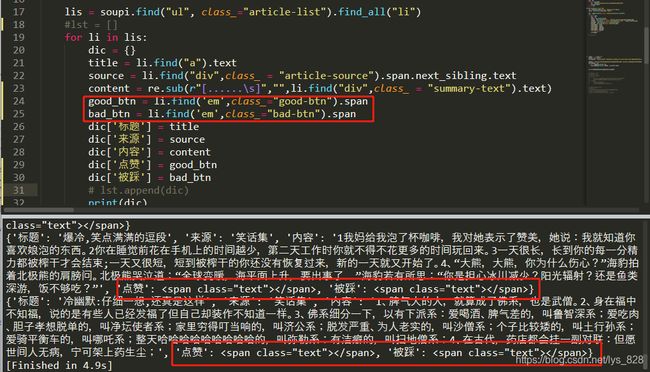
原因在于?
查看网页源代码,发现其中关于这部分的数据的确是和输出的一样,是没有的,如下

这就有一个问题,我们在标签上可以看到的数据,却不能够进行爬取吗?
1) 这时候就可以试试刷新network,尝试抓包,看看这里数据究竟藏在哪里
2)还有一种办法,就是使用Selenium框架,只要是在浏览器上面可以看到的信息一般都是可以通过这种方式获取信息的
实战解析
这里就以第二页的20个笑话进行举例,尝试获取里面的标题、来源、正文内容、点赞数量和被踩数量,最后将爬取的数据存入excel表格中
步骤一、前期准备(运行环境spyder)
from selenium import webdriver
import re
import pandas as pd
browser = webdriver.Chrome()
browser.get("http://xiaohua.zol.com.cn/lengxiaohua/2.html")
该部分的代码实现的是:导入相关的库,并跳出浏览器,跳转到指定页面
步骤二、以单个笑话内容为例进行试错
title = browser.find_element_by_xpath("/html/body/div[7]/div[1]/ul/li[1]/span[2]/a").text
source = browser.find_element_by_xpath("/html/body/div[7]/div[1]/ul/li[1]/div[1]/span[2]").text
content = re.sub(r"\s","",browser.find_element_by_xpath("/html/body/div[7]/div[1]/ul/li[1]/div[2]").text).replace("......","")
good_btn = browser.find_element_by_xpath("/html/body/div[7]/div[1]/ul/li[1]/div[3]/div[2]/em/span").text
bad_btn = browser.find_element_by_xpath("/html/body/div[7]/div[1]/ul/li[1]/div[3]/div[3]/em/span").text
print(title,source,good_btn,bad_btn,content)
输出的结果为:

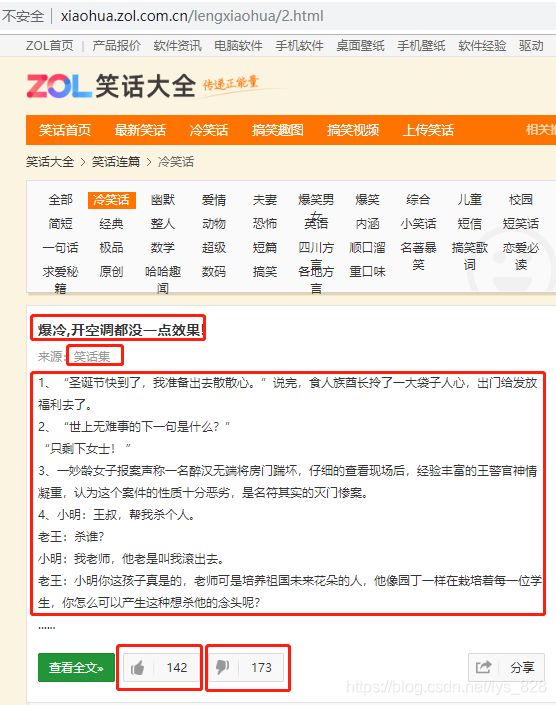
对照一下第二页第一个笑话的内容:(五项内容可以全部正常输出)
步骤三、遍历循环输出20个笑话内容
这一步将数据遍历循环,为了生成excel格式的数据,这里将数据以字典的格式按条存放列表中,方便下一步数据的导出
data_lst = []
for i in range(1,21):
dic = {}
title = browser.find_element_by_xpath(f"/html/body/div[7]/div[1]/ul/li[{i}]/span[2]/a").text
source = browser.find_element_by_xpath(f"/html/body/div[7]/div[1]/ul/li[{i}]/div[1]/span[2]").text
content = re.sub(r"\s","",browser.find_element_by_xpath(f"/html/body/div[7]/div[1]/ul/li[{i}]/div[2]").text).replace("......","")
good_btn = browser.find_element_by_xpath(f"/html/body/div[7]/div[1]/ul/li[{i}]/div[3]/div[2]/em/span").text
bad_btn = browser.find_element_by_xpath(f"/html/body/div[7]/div[1]/ul/li[{i}]/div[3]/div[3]/em/span").text
dic['标题'] = title
dic['来源'] = source
dic['内容'] = content
dic['点赞数'] = good_btn
dic['被踩数'] = bad_btn
data_lst.append(dic)
print(data_lst[0])
输出的结果为:(为了清晰地看出数据的结构,这里尝试输出第一条数据)

步骤四、将数据存放至Excel中
前面的工作都做好了,这里只需要两行代码
data = pd.DataFrame(data_lst)
data.to_excel("data.xlsx",index = False)
输出的结果为:(spyder中的数据)
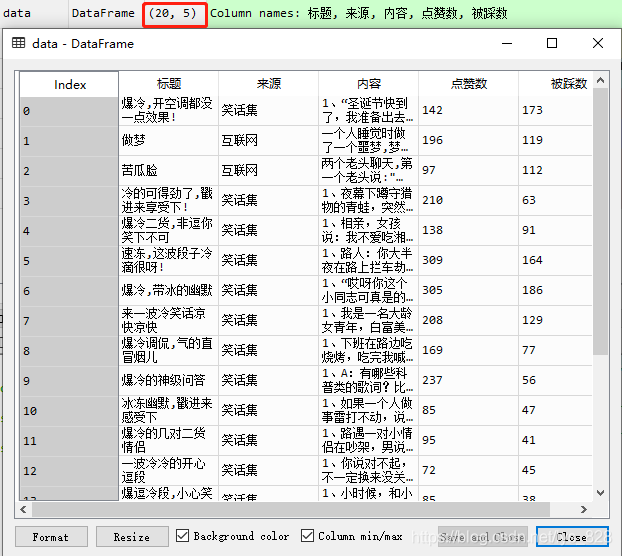
Excel中的数据:
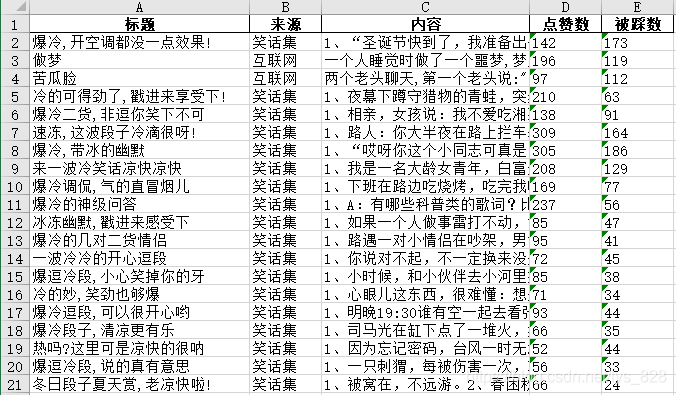
至此,爬取笑话大全的工作就此结束