程序员经常要面临的一个问题就是:如何提高程序性能?
这篇文章,我们循序渐进,从内存、磁盘I/O、网络I/O、CPU、缓存、架构、算法等多层次递进,串联起高性能开发十大必须掌握的核心技术。
-
- I/O优化:零拷贝技术
-
- I/O优化:多路复用技术
-
- 线程池技术
-
- 无锁编程技术
-
- 进程间通信技术
-
- RPC && 序列化技术
-
- 数据库索引技术
-
- 缓存技术 && 布隆过滤器
-
- 全文搜索技术
-
- 负载均衡技术
准备好了吗,坐稳了,发车!
首先,我们从最简单的模型开始。
老板告诉你,开发一个静态web服务器,把磁盘文件(网页、图片)通过网络发出去,怎么做?
你花了两天时间,撸了一个1.0版本:
- 主线程进入一个循环,等待连接
- 来一个连接就启动一个工作线程来处理
- 工作线程中,等待对方请求,然后从磁盘读文件、往套接口发送数据,完事儿
上线一天,老板发现太慢了,大一点的图片加载都有卡顿感。让你优化,这个时候,你需要:
I/O优化:零拷贝技术
上面的工作线程,从磁盘读文件、再通过网络发送数据,数据从磁盘到网络,兜兜转转需要拷贝四次,其中CPU亲自搬运都需要两次。
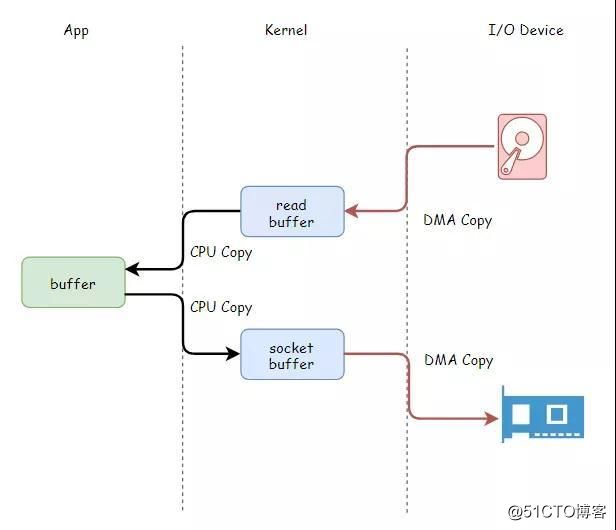
零拷贝技术,解放CPU,文件数据直接从内核发送出去,无需再拷贝到应用程序缓冲区,白白浪费资源。

Linux API:
ssize_t sendfile(
int out_fd,
int in_fd,
off_t *offset,
size_t count
); 函数名字已经把函数的功能解释的很明显了:发送文件。指定要发送的文件描述符和网络套接字描述符,一个函数搞定!
用上了零拷贝技术后开发了2.0版本,图片加载速度明显有了提升。不过老板发现同时访问的人变多了以后,又变慢了,又让你继续优化。这个时候,你需要:
I/O优化:多路复用技术
前面的版本中,每个线程都要阻塞在recv等待对方的请求,这来访问的人多了,线程开的就多了,大量线程都在阻塞,系统运转速度也随之下降。
这个时候,你需要多路复用技术,使用select模型,将所有等待(accept、recv)都放在主线程里,工作线程不需要再等待。
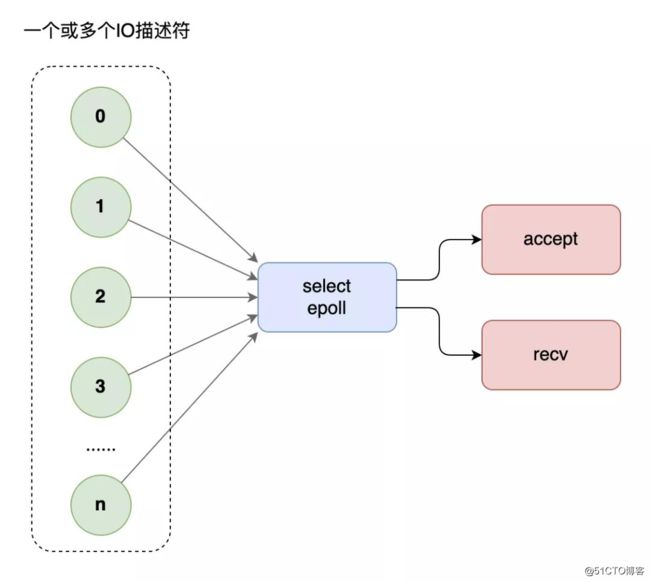
过了一段时间之后,网站访问的人越来越多了,就连select也开始有点应接不暇,老板继续让你优化性能。
这个时候,你需要升级多路复用模型为epoll。
select有三弊,epoll有三优。
- select底层采用数组来管理套接字描述符,同时管理的数量有上限,一般不超过几千个,epoll使用树和链表来管理,同时管理数量可以很大。
- select不会告诉你到底哪个套接字来了消息,你需要一个个去询问。epoll直接告诉你谁来了消息,不用轮询。
- select进行系统调用时还需要把套接字列表在用户空间和内核空间来回拷贝,循环中调用select时简直浪费。epoll统一在内核管理套接字描述符,无需来回拷贝。
用上了epoll多路复用技术,开发了3.0版本,你的网站能同时处理很多用户请求了。
但是贪心的老板还不满足,不舍得升级硬件服务器,却让你进一步提高服务器的吞吐量。你研究后发现,之前的方案中,工作线程总是用到才创建,用完就关闭,大量请求来的时候,线程不断创建、关闭、创建、关闭,开销挺大的。这个时候,你需要:
线程池技术
我们可以在程序一开始启动后就批量启动一波工作线程,而不是在有请求来的时候才去创建,使用一个公共的任务队列,请求来临时,向队列中投递任务,各个工作线程统一从队列中不断取出任务来处理,这就是线程池技术。
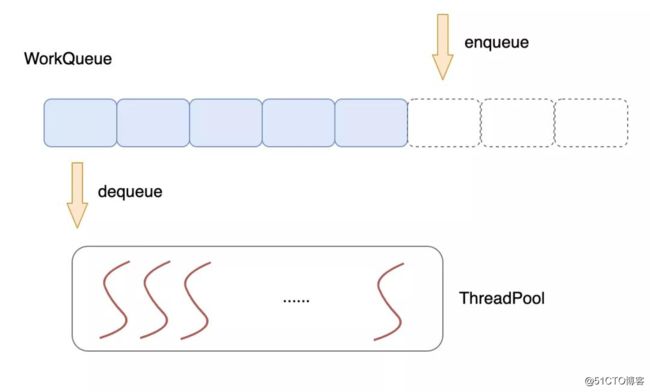
多线程技术的使用一定程度提升了服务器的并发能力,但同时,多个线程之间为了数据同步,常常需要使用互斥体、信号、条件变量等手段来同步多个线程。这些重量级的同步手段往往会导致线程在用户态/内核态多次切换,系统调用,线程切换都是不小的开销。
在线程池技术中,提到了一个公共的任务队列,各个工作线程需要从中提取任务进行处理,这里就涉及到多个工作线程对这个公共队列的同步操作。
有没有一些轻量级的方案来实现多线程安全的访问数据呢?这个时候,你需要:
无锁编程技术
多线程并发编程中,遇到公共数据时就需要进行线程同步。而这里的同步又可以分为阻塞型同步和非阻塞型同步。
阻塞型同步好理解,我们常用的互斥体、信号、条件变量等这些操作系统提供的机制都属于阻塞型同步,其本质都是要加“锁”。

与之对应的非阻塞型同步就是在无锁的情况下实现同步,目前有三类技术方案:
- Wait-free
- Lock-free
- Obstruction-free
三类技术方案都是通过一定的算法和技术手段来实现不用阻塞等待而实现同步,这其中又以Lock-free最为应用广泛。
Lock-free能够广泛应用得益于目前主流的CPU都提供了原子级别的read-modify-write原语,这就是著名的CAS(Compare-And-Swap)操作。在Intel x86系列处理器上,就是cmpxchg系列指令。
// 通过CAS操作实现Lock-free
do {
...
} while(!CAS(ptr,old_data,new_data )) 我们常常见到的无锁队列、无锁链表、无锁HashMap等数据结构,其无锁的核心大都来源于此。在日常开发中,恰当的运用无锁化编程技术,可以有效地降低多线程阻塞和切换带来的额外开销,提升性能。
服务器上线了一段时间,发现服务经常崩溃异常,排查发现是工作线程代码bug,一崩溃整个服务都不可用了。于是你决定把工作线程和主线程拆开到不同的进程中,工作线程崩溃不能影响整体的服务。这个时候出现了多进程,你需要:
进程间通信技术
提起进程间通信,你能想到的是什么?
- 管道
- 命名管道
- socket
- 消息队列
- 信号
- 信号量
- 共享内存
以上各种进程间通信的方式详细介绍和比较,推荐一篇文章一文掌握进程间通信,这里不再赘述。
对于本地进程间需要高频次的大量数据交互,首推共享内存这种方案。
现代操作系统普遍采用了基于虚拟内存的管理方案,在这种内存管理方式之下,各个进程之间进行了强制隔离。程序代码中使用的内存地址均是一个虚拟地址,由操作系统的内存管理算法提前分配映射到对应的物理内存页面,CPU在执行代码指令时,对访问到的内存地址再进行实时的转换翻译。
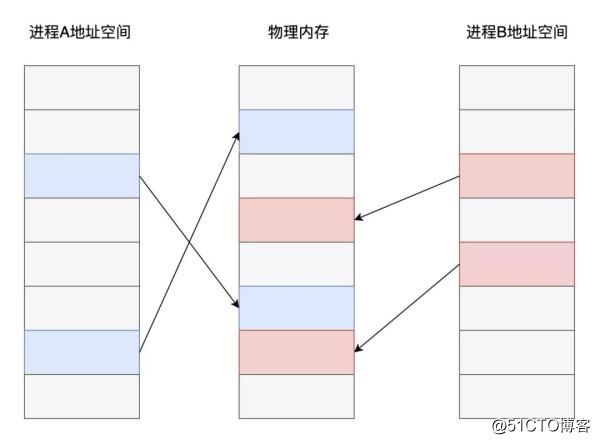
从上图可以看出,不同进程之中,虽然是同一个内存地址,最终在操作系统和CPU的配合下,实际存储数据的内存页面却是不同的。
而共享内存这种进程间通信方案的核心在于:如果让同一个物理内存页面映射到两个进程地址空间中,双方不是就可以直接读写,而无需拷贝了吗?
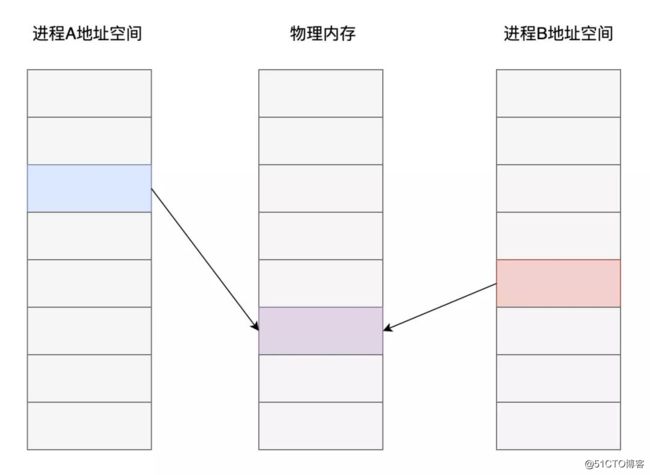
当然,共享内存只是最终的数据传输载体,双方要实现通信还得借助信号、信号量等其他通知机制。
用上了高性能的共享内存通信机制,多个服务进程之间就可以愉快的工作了,即便有工作进程出现Crash,整个服务也不至于瘫痪。
不久,老板增加需求了,不再满足于只能提供静态网页浏览了,需要能够实现动态交互。这一次老板还算良心,给你加了一台硬件服务器。
于是你用Java/PHP/Python等语言搞了一套web开发框架,单独起了一个服务,用来提供动态网页支持,和原来等静态内容服务器配合工作。
这个时候你发现,静态服务和动态服务之间经常需要通信。
一开始你用基于HTTP的RESTful接口在服务器之间通信,后来发现用JSON格式传输数据效率低下,你需要更高效的通信方案。
这个时候你需要:
RPC && 序列化技术
什么是RPC技术?
RPC全称Remote Procedure Call,远程过程调用。我们平时编程中,随时都在调用函数,这些函数基本上都位于本地,也就是当前进程某一个位置的代码块。但如果要调用的函数不在本地,而在网络上的某个服务器上呢?这就是远程过程调用的来源。
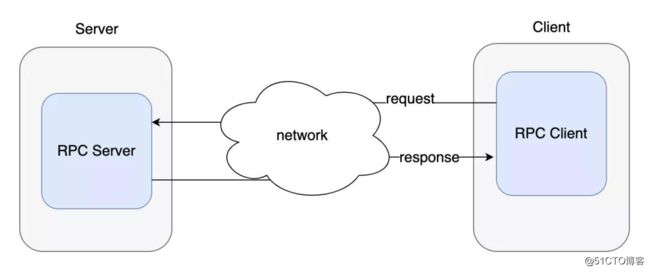
从图中可以看出,通过网络进行功能调用,涉及参数的打包解包、网络的传输、结果的打包解包等工作。而其中对数据进行打包和解包就需要依赖序列化技术来完成。
什么是序列化技术?

序列化简单来说,是将内存中的对象转换成可以传输和存储的数据,而这个过程的逆向操作就是反序列化。序列化 && 反序列化技术可以实现将内存对象在本地和远程计算机上搬运。好比把大象关进冰箱门分三步:
- 将本地内存对象编码成数据流
- 通过网络传输上述数据流
- 将收到的数据流在内存中构建出对象
序列化技术有很多免费开源的框架,衡量一个序列化框架的指标有这么几个:
- 是否支持跨语言使用,能支持哪些语言
- 是否只是单纯的序列化功能,包不包含RPC框架
- 序列化传输性能
- 扩展支持能力(数据对象增删字段后,前后的兼容性)
- 是否支持动态解析(动态解析是指不需要提前编译,根据拿到的数据格式定义文件立即就能解析)
下面流行的三大序列化框架protobuf、thrift、avro的对比:
ProtoBuf:
厂商:Google
支持语言:C++、Java、Python等
动态性支持:较差,一般需要提前编译
是否包含RPC:否
简介:ProtoBuf是谷歌出品的序列化框架,成熟稳定,性能强劲,很多大厂都在使用。自身只是一个序列化框架,不包含RPC功能,不过可以与同是Google出品的GPRC框架一起配套使用,作为后端RPC服务开发的黄金搭档。

缺点是对动态性支持较弱,不过在更新版本中这一现象有待改善。总体来说,ProtoBuf都是一款非常值得推荐的序列化框架。
Thrift
厂商:Facebook
支持语言:C++、Java、Python、PHP、C#、Go、JavaScript等
动态性支持:差
是否包含RPC:是
简介:这是一个由Facebook出品的RPC框架,本身内含二进制序列化方案,但Thrift本身的RPC和数据序列化是解耦的,你甚至可以选择XML、JSON等自定义的数据格式。在国内同样有一批大厂在使用,性能方面和ProtoBuf不分伯仲。缺点和ProtoBuf一样,对动态解析的支持不太友好。
Avro
支持语言:C、C++、Java、Python、C#等
动态性支持:好
是否包含RPC:是
简介:这是一个源自于Hadoop生态中的序列化框架,自带RPC框架,也可独立使用。相比前两位最大的优势就是支持动态数据解析。

为什么我一直在说这个动态解析功能呢?在之前的一段项目经历中,轩辕就遇到了三种技术的选型,摆在我们面前的就是这三种方案。需要一个C++开发的服务和一个Java开发的服务能够进行RPC。
Protobuf和Thrift都需要通过“编译”将对应的数据协议定义文件编译成对应的C++/Java源代码,然后合入项目中一起编译,从而进行解析。
当时,Java项目组同学非常强硬的拒绝了这一做法,其理由是这样编译出来的强业务型代码融入他们的业务无关的框架服务,而业务是常变的,这样做不够优雅。
最后,经过测试,最终选择了AVRO作为我们的方案。Java一侧只需要动态加载对应的数据格式文件,就能对拿到的数据进行解析,并且性能上还不错。(当然,对于C++一侧还是选择了提前编译的做法)
自从你的网站支持了动态能力,免不了要和数据库打交道,但随着用户的增长,你发现数据库的查询速度越来越慢。
这个时候,你需要:
数据库索引技术
想想你手上有一本数学教材,但是目录被人给撕掉了,现在要你翻到讲三角函数的那一页,你该怎么办?
没有了目录,你只有两种办法,要么一页一页的翻,要么随机翻,直到找到三角函数的那一页。
对于数据库也是一样的道理,如果我们的数据表没有“目录”,那要查询满足条件的记录行,就得全表扫描,那可就恼火了。所以为了加快查询速度,得给数据表也设置目录,在数据库领域中,这就是索引。
一般情况下,数据表都会有多个字段,那根据不同的字段也就可以设立不同的索引。
索引的分类
- 主键索引
- 聚集索引
- 非聚集索引
主键我们都知道,是唯一标识一条数据记录的字段(也存在多个字段一起来唯一标识数据记录的联合主键),那与之对应的就是主键索引了。
聚集索引是指索引的逻辑顺序与表记录的物理存储顺序一致的索引,一般情况下主键索引就符合这个定义,所以一般来说主键索引也是聚集索引。但是,这不是绝对的,在不同的数据库中,或者在同一个数据库下的不同存储引擎中还是有不同。
聚集索引的叶子节点直接存储了数据,也是数据节点,而非聚集索引的叶子节点没有存储实际的数据,需要二次查询。
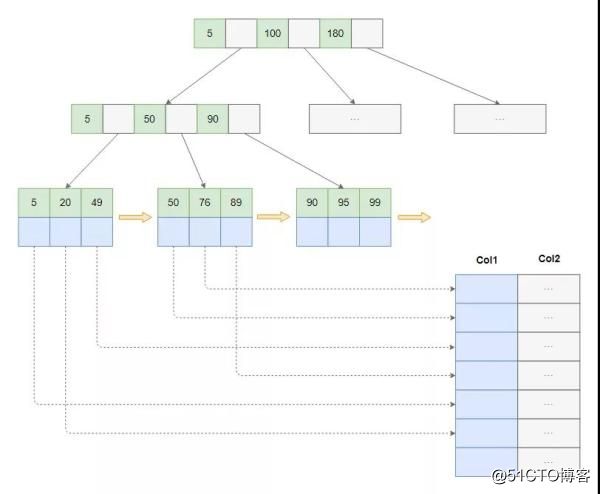
索引的实现原理
索引的实现主要有三种:
- B+树
- 哈希表
- 位图
其中,B+树用的最多,其特点是树的节点众多,相较于二叉树,这是一棵多叉树,是一个扁平的胖树,减少树的深度有利于减少磁盘I/O次数,适宜数据库的存储特点。
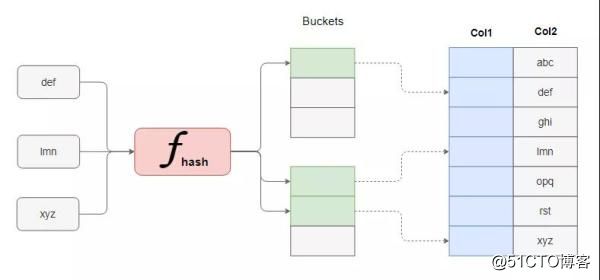
哈希表实现的索引也叫散列索引,通过哈希函数来实现数据的定位。哈希算法的特点是速度快,常数阶的时间复杂度,但缺点是只适合准确匹配,不适合模糊匹配和范围搜索。
位图索引相对就少见了。想象这么一个场景,如果某个字段的取值只有有限的少数几种可能,比如性别、省份、血型等等,针对这样的字段如果用B+树作为索引的话会出现什么情况?会出现大量索引值相同的叶子节点,这实际上是一种存储浪费。
位图索引正是基于这一点进行优化,针对字段取值只有少量有限项,数据表中该列字段出现大量重复时,就是位图索引一展身手的时机。
所谓位图,就是Bitmap,其基本思想是对该字段每一个取值建立一个二进制位图来标记数据表的每一条记录的该列字段是否是对应取值。

索引虽好,但也不可滥用,一方面索引最终是要存储到磁盘上的,无疑会增加存储开销。另外更重要的是,数据表的增删操作一般会伴随对索引的更新,因此对数据库的写入速度也是会有一定影响。
你的网站现在访问量越来越大了,同时在线人数大大增长。然而,大量用户的请求带来了后端程序对数据库大量的访问。渐渐的,数据库的瓶颈开始出现,无法再支持日益增长的用户量。老板再一次给你下达了性能提升的任务。
缓存技术 && 布隆过滤器
从物理CPU对内存数据的缓存到浏览器对网页内容的缓存,缓存技术遍布于计算机世界的每一个角落。
面对当前出现的数据库瓶颈,同样可以用缓存技术来解决。
每次访问数据库都需要数据库进行查表(当然,数据库自身也有优化措施),反映到底层就是进行一次或多次的磁盘I/O,但凡涉及I/O的就会慢下来。如果是一些频繁用到但又不会经常变化的数据,何不将其缓存在内存中,不必每一次都要找数据库要,从而减轻对数据库对压力呢?

有需求就有市场,有市场就会有产品,以memcached和Redis为代表的内存对象缓存系统应运而生。
缓存系统有三个著名的问题:
- 缓存穿透: 缓存设立的目的是为了一定层面上截获到数据库存储层的请求。穿透的意思就在于这个截获没有成功,请求最终还是去到了数据库,缓存没有产生应有的价值。
- 缓存击穿: 如果把缓存理解成一面挡在数据库面前的墙壁,为数据库“抵御”查询请求,所谓击穿,就是在这面墙壁上打出了一个洞。一般发生在某个热点数据缓存到期,而此时针对该数据的大量查询请求来临,大家一股脑的怼到了数据库。
- 缓存雪崩: 理解了击穿,那雪崩就更好理解了。俗话说得好,击穿是一个人的雪崩,雪崩是一群人的击穿。如果缓存这堵墙上处处都是洞,那这面墙还如何屹立?吃枣药丸。
关于这三个问题的更详细阐述,推荐一篇文章什么是缓存系统的三座大山。
有了缓存系统,我们就可以在向数据库请求之前,先询问缓存系统是否有我们需要的数据,如果有且满足需要,我们就可以省去一次数据库的查询,如果没有,我们再向数据库请求。
注意,这里有一个关键的问题,如何判断我们要的数据是不是在缓存系统中呢?
进一步,我们把这个问题抽象出来:如何快速判断一个数据量很大的集合中是否包含我们指定的数据?
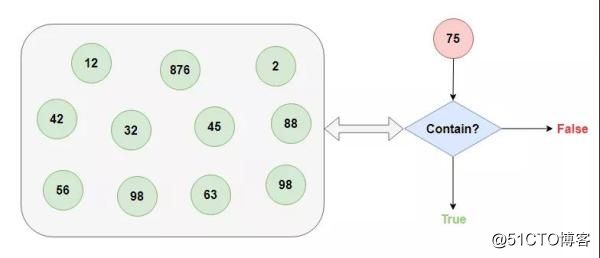
这个时候,就是布隆过滤器大显身手的时候了,它就是为了解决这个问题而诞生的。那布隆过滤器是如何解决这个问题的呢?
先回到上面的问题中来,这其实是一个查找问题,对于查找问题,最常用的解决方案是搜索树和哈希表两种方案。
因为这个问题有两个关键点:快速、数据量很大。树结构首先得排除,哈希表倒是可以做到常数阶的性能,但数据量大了以后,一方面对哈希表的容量要求巨大,另一方面如何设计一个好的哈希算法能够做到如此大量数据的哈希映射也是一个难题。
对于容量的问题,考虑到只需要判断对象是否存在,而并非拿到对象,我们可以将哈希表的表项大小设置为1个bit,1表示存在,0表示不存在,这样大大缩小哈希表的容量。
而对于哈希算法的问题,如果我们对哈希算法要求低一些,那哈希碰撞的机率就会增加。那一个哈希算法容易冲突,那就多弄几个,多个哈希函数同时冲突的概率就小的多。
布隆过滤器就是基于这样的设计思路:
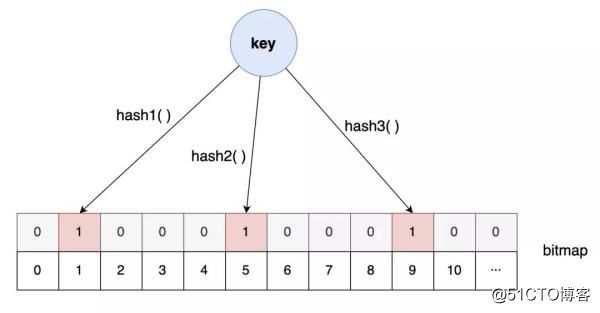
当设置对应的key-value时,按照一组哈希算法的计算,将对应比特位置1。
但当对应的key-value删除时,却不能将对应的比特位置0,因为保不准其他某个key的某个哈希算法也映射到了同一个位置。
也正是因为这样,引出了布隆过滤器的另外一个重要特点:布隆过滤器判定存在的实际上不一定存在,但判定不存在的则一定不存在。
你们公司网站的内容越来越多了,用户对于快速全站搜索的需求日益强烈。这个时候,你需要:
全文搜索技术
对于一些简单的查询需求,传统的关系型数据库尚且可以应付。但搜索需求一旦变得复杂起来,比如根据文章内容关键字、多个搜索条件但逻辑组合等情况下,数据库就捉襟见肘了,这个时候就需要单独的索引系统来进行支持。

如今行业内广泛使用的ElasticSearch(简称ES)就是一套强大的搜索引擎。集全文检索、数据分析、分布式部署等优点于一身,成为企业级搜索技术的首选。

ES使用RESTful接口,使用JSON作为数据传输格式,支持多种查询匹配,为各主流语言都提供了SDK,易于上手。
另外,ES常常和另外两个开源软件Logstash、Kibana一起,形成一套日志收集、分析、展示的完整解决方案:ELK架构。

其中,Logstash负责数据的收集、解析,ElasticSearch负责搜索,Kibana负责可视化交互,成为不少企业级日志分析管理的铁三角。
无论我们怎么优化,一台服务器的力量终究是有限的。公司业务发展迅猛,原来的服务器已经不堪重负,于是公司采购了多台服务器,将原有的服务都部署了多份,以应对日益增长的业务需求。
现在,同一个服务有多个服务器在提供服务了,需要将用户的请求均衡的分摊到各个服务器上,这个时候,你需要:
负载均衡技术
顾名思义,负载均衡意为将负载均匀平衡分配到多个业务节点上去。

和缓存技术一样,负载均衡技术同样存在于计算机世界到各个角落。
按照均衡实现实体,可以分为软件负载均衡(如LVS、Nginx、HAProxy)和硬件负载均衡(如A10、F5)。
按照网络层次,可以分为四层负载均衡(基于网络连接)和七层负载均衡(基于应用内容)。
按照均衡策略算法,可以分为轮询均衡、哈希均衡、权重均衡、随机均衡或者这几种算法相结合的均衡。
而对于现在遇到等问题,可以使用nginx来实现负载均衡,nginx支持轮询、权重、IP哈希、最少连接数目、最短响应时间等多种方式的负载均衡配置。
轮询
upstream web-server {
server 192.168.1.100;
server 192.168.1.101;
} 权重
upstream web-server {
server 192.168.1.100 weight=1;
server 192.168.1.101 weight=2;
} IP哈希值
upstream web-server {
ip_hash;
server 192.168.1.100 weight=1;
server 192.168.1.101 weight=2;
} 最少连接数目
upstream web-server {
ip_hash;
server 192.168.1.100 weight=1;
server 192.168.1.101 weight=2;
} 最短响应时间
upstream web-server {
server 192.168.1.100 weight=1;
server 192.168.1.101 weight=2;
fair;
} 总结
高性能是一个永恒的话题,其涉及的技术和知识面其实远不止上面列出的这些。
从物理硬件CPU、内存、硬盘、网卡到软件层面的通信、缓存、算法、架构每一个环节的优化都是通往高性能的道路。
路漫漫其修远兮,吾将上下而求索。
本文转载自微信公众号「编程技术宇宙」,可以通过以下二维码关注。转载本文请联系编程技术宇宙公众号。

【编辑推荐】
- 性能up!面向前端开发人员的14个JavaScript代码优化技巧
- 高性能 Java 应用层网关设计实践
- 软件开发平台之争:NET VS Java,谁是更好的选择?
- 程序员专为韭菜开源设计的项目,股票分析、代码学习两不误!
- 效率之王!这些令人惊叹的开发工具不可不知
【责任编辑:武晓燕 TEL:(010)68476606】