Python学习笔记(十四):文件的读写
打开文件:
python 内置的 open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程中,都需要使用这个对象;
注意:使用 open() 方法操作文件之后,一定要调用 close() 方法关闭文件;
open() 方法常用形式是接收两个参数,file(文件名)和 mode(打开模式):open(file, mode);
完整的语法格式为:
open(file, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)参数说明:
file:必须,文件名;
mode:可选,文件打开模式,默认为 r,表示只读;
buffering:设置缓冲;
encoding:设置编码方式,一般使用 utf8;
errors:报错级别;
newline:区分换行符;
closefd:传入的 file 参数类型;
mode 参数的取值有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(Python 3 不支持)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。一般用于非文本文件,如图片、视频等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件,如图片、视频等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,则创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,则创建新文件。一般用于非文本文件,如图片、视频等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在,则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,则创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,则创建新文件。一般用于非文本文件,如图片、视频等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
写入文件:
file.write(str):表示将指定字符串写入文件;
# 打开一个文件,如果文件不存在,则创建;如果存在,则清空文件内容;
fd = open("a.txt", "w")
# 定义一个字符串数据
str = "人生苦短,我用 python"
# 写入文件,返回写入数据的字节数
count = fd.write(str)
print(count)
# 关闭文件对象
fd.close()打开文件发现写入的中文数据变成了乱码:
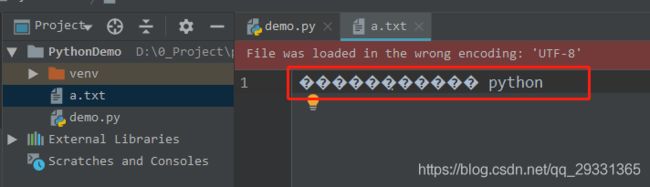
解决办法:使用 open() 方法打开文件的时候,指定 encoding 参数,如下:
fd = open("a.txt", "w", encoding="UTF-8")在文件关闭前,或缓冲区刷新前,字符串的内容存储在缓冲区中,这时在文件中是看不到写入的内容的;
比如上面的代码,如果我在 print(count) 位置打一个断点,调试运行到该位置,此时虽然已经调用了 fd.write() 方法写入数据,但是由于没有调用 close() 方法和 flush() 方法,所以数据还在缓冲区中,所以此时打开文件的时候,发现文件中是空的;
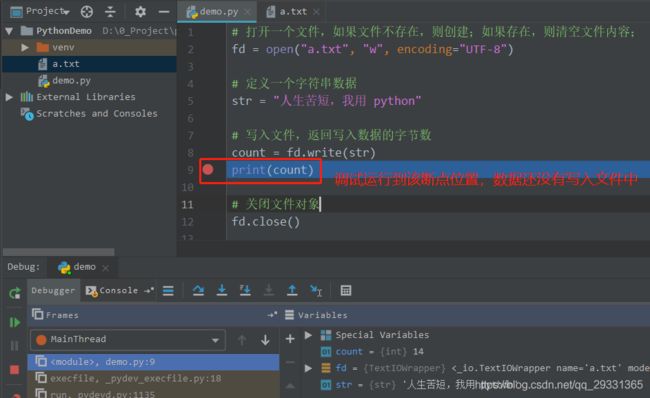
file.flush() 用于刷新缓冲区,表示将缓冲区的数据立刻写入到文件中,同时清空缓冲区;比如在下面的代码中,fd.write(str) 语句后面调用了 flush() 方法刷新缓冲区,此时再调试运行到 print(count) 语句,然后打开文件会发现,数据已经写入到文件中了。一般情况下,文件关闭时,会自动刷新缓冲区。
# 打开一个文件,如果文件不存在,则创建;如果存在,则清空文件内容;
fd = open("a.txt", "w", encoding="UTF-8")
# 定义一个字符串数据
str = "人生苦短,我用 python"
# 写入文件,返回写入数据的字节数
count = fd.write(str)
# 刷新缓冲区
fd.flush()
print(count)
# 关闭文件对象
fd.close()如果文件打开模式带 b,那写入文件内容时,str (参数)要用 encode 方法转为 bytes 形式,否则报错:TypeError: a bytes-like object is required, not 'str'。
# 以只写方式打开一个文件;打开模式带 b,表示以二进制的方式打开
fd = open("a.txt", "wb")
# 定义一个字符串数据
str = "人生苦短,我用 python"
# 写入文件,写入字符串数据就会报错
count = fd.write(str)
print(count)
# 关闭文件对象
fd.close()错误如下:

解决办法如下:
# 写入文件,str.encode() 方法用于将字符串转换成 bytes 类型
count = fd.write(str.encode())file.writelines(seq):向文件中写入一序列的字符串,这一序列字符串可以是由迭代器对象产生的,比如一个字符串列表;
# 打开一个文件,如果文件不存在,则创建;如果存在,则清空文件内容;
fd = open("a.txt", "w", encoding="UTF-8")
# 定义一个字符串列表
list1 = ["how", "are", "you"]
# 将一序列的字符串写入到文件中
fd.writelines(list1)
# 关闭文件对象
fd.close()
读取文件:
file.read([size]):该方法用于从文件中读取指定的字节数;如果未指定 size 参数,则读取所有;
# 打开一个文件,返回文件对象
fd = open("a.txt", "r")
# 读取文件中的所有内容
str = fd.read()
# 读取指定字节大小的数据
#str = fd.read(6)
print(str)
# 关闭文件对象
fd.close()发现报如下错误:

这是因为文件中含有中文;解决办法是使用 open() 打开文件的时候指定编码格式,如下:
# 打开一个文件,返回文件对象;指定编码格式,解决中文出错的问题
fd = open("a.txt", "r", encoding="UTF-8")file.readline([size]):该方法表示一次读取一行,包括换行符(\n);如果指定了参数 size,也表示读取指定大小的字节数;
# 打开一个文件,返回文件对象;指定编码格式,解决中文出错的问题
fd = open("a.txt", "r", encoding="UTF-8")
# 读取文件内容
str = fd.readline() # 读取一行,此时文件指针位于第二行的开始
print(str)
str = fd.readline() # 继续读取一行,从当前文件指针的位置开始读取
print(str)
# 关闭文件对象
fd.close()readlines():该方法用于读取所有行(直到结束符 EOF),并返回列表,该列表可以使用 for .. in .. 结构进行解析;如果碰到结束符 EOF,则返回空字符串;
# 打开一个文件,返回文件对象;指定编码格式,解决中文出错的问题
fd = open("a.txt", "r", encoding="UTF-8")
# 读取文件中的所有行
content = fd.readlines()
# 一次循环输入一行
for line in content:
# 因为读取一行数据的时候,就包括了行尾的换行符,
# 如果 print 输出的时候也换行,那就有两次换行了
print(line, end="")
file 对象的一些其他方法:
1、file.fileno():返回一个整形的文件描述符,可用于底层操作系统的 I/O 操作;
2、file.isatty():用于检测文件是否连接到一个终端设备,如果是返回 True,否则返回 False;
# 打开一个文件,返回文件对象
fd = open("a.txt", "r")
print(fd) # fd 是一个对象
# 返回一个整形的文件描述符
fid = fd.fileno()
print("fid = ", fid)
# 检测文件是否连接到一个终端设备
print(fd.isatty()) # False 表示没有连接到终端设备
# 关闭文件对象
fd.close()输出结果:
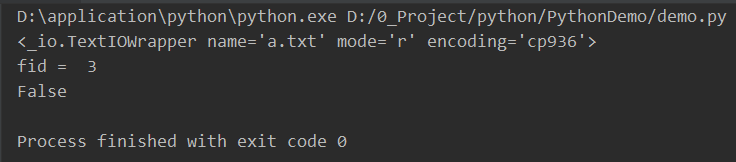
3、file.seek(offset[, whence]):用于移动文件指针到指定位置;成功返回新的位置,失败返回 -1;
-
offset:开始的偏移量,以字节为单位;如果为负数,表示从倒数第几位开始;
-
whence:可选参数,默认为 0;为 offset 定义一个参数,表示要从哪个位置开始偏移;0 表示从文件开头开始算起,1 表示从当前位置开始算起,2 表示从文件末尾开始算起;
4、file.tell():返回文件的当前位置;
# 以读写方式打开一个文件
fd = open("a.txt", "w+")
fd.write("abcdefg") # 写入数据,文件指针移动到文件末尾
print(fd.tell()) # 返回文件的当前位置
fd.seek(3) # 将文件指针从开始位置移动3个字节,开始位置为 0
print(fd.read()) # 从当前位置开始读取文件
fd.seek(-3, 2) # 将文件指针从末尾向前移动3个字节
print(fd.read(1))
fd.close() # 关闭文件对象程序运行报错:io.UnsupportedOperation: can't do nonzero end-relative seeks

这是因为没有使用 b 模式打开的文件,只允许从文件头开始计算相对位置,从文件末尾计算就会抛出上面异常;解决是打开文件的时候指定 b 模式,但是以 b 模式打开的文件,写入数据时需要将字符串转换成 bytes 类型:
# 以读写方式打开一个文件;指定 b 模式,表示以二进制的方式进行读写;
fd = open("a.txt", "wb+")
# 写入二进制数据,需要转换成 bytes 类型
fd.write("abcdefg".encode())
print(fd.tell()) # 返回文件的当前位置
fd.seek(3) # 将文件指针从开始位置移动3个字节,开始位置为 0
print(fd.read()) # 从当前位置开始读取文件
fd.seek(-3, 2) # 将文件指针从末尾向前移动3个字节
print(fd.read())
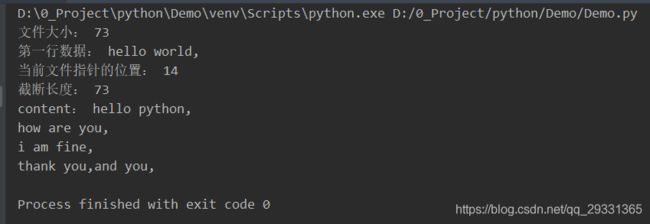
fd.close() # 关闭文件对象5、file.truncate([size]):从文件开头开始截断,截断 size 个字节;如果没有参数 size,表示从当前位置开始截断,截断之后后面的所有字节都被删除;windows 下的换行代表两个字节大小;
文件内容:

import os
# 以读写的方式打开文件
fd = open("a.txt", "r+", encoding="UTF-8")
# 获取文件大小
print("文件大小:", os.path.getsize("a.txt"))
# 读取一行
line = fd.readline()
print("第一行数据:", line, end="")
# 当前文件指针的位置
print("当前文件指针的位置:", fd.tell())
length = fd.truncate() # 截断,返回截断的字节长度
print("截断长度:", length)
content = fd.read()
print("content:", content)
# 关闭文件
fd.close()
输出结果: