Webmagic爬取文章列表详情页的两种方式
通常webmagic爬取数据,无非就是分析页面结构,然后解析数据,一般这种类型的页面,网站都是get请求。但是有些数据,是通过js渲染的,通过post请求获取到json数据,然后渲染到页面上。所以针对这种类型的网站单单通过分析页面结构是行不通的,所以则需要模拟post请求返回数据,然后进行获取。
准备工作:导入需要的maven依赖包
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
一、普通文章列表页面数据的爬取。(非js渲染的页面)
1.步骤
(1)爬虫程序的启动。(添加初始的url,当然url可以用正则表达式来进行过滤)
Spider.create(new TestDemo()).addUrl("http://www...").thread(5).run();
(2)在当前页面发现文章详情页的url,然后将其添加到待爬队列中
List
(3)抽取页面内容
//抽取所有数据对象当用到.all()的时候---适用于列表页面
List
//抽取单个数据对象---适用于详情页面
Selectable titles =page.getHtml().xpath("//div[@id='ivs_title']/text()");
(4)将其元素信息插入到数据库中去
2.代码
package com.sxsihe.base;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Selectable;
public class TestDemo implements PageProcessor{
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
@Override
public void process(Page page) {
//从页面发现后续的url地址加入到队列中去
List urls = page.getHtml().xpath("//div[@id='pageList']/ul/li/a").links().regex(".*html.*").all();
page.addTargetRequests(urls);
//从详情页面获取数据----文本内容
Selectable content =page.getHtml().xpath("//div[@id='ivs_content']/html()");//outerHtml()
//从详情页面获取数据----标题
Selectable titles =page.getHtml().xpath("//div[@id='ivs_title']/text()");
//从详情页面获取数据----发布时间
Selectable datess =page.getHtml().xpath("//div[@id='ivs_title']/small[@class='PBtime']/html()");
//从详情页面获取数据列表----发布日期
List dates2 =page.getHtml().xpath("//div[@id='pageList']/ul/li/span/html()").all();
for(int i=0;i 3.小技巧
(1)分析页面结构的时候,可以打开开发工具自己copy,不需要自己分析。

(2)每次执行这个process()方法的时候,只是执行一次url。
二、普通文章列表页面数据的爬取。(js渲染的页面)
1.步骤
(1)爬虫程序的启动
(2)分析返回的json数据,进行分析json数据格式
(3)将抓取到的数据插入到数据库中去
2.代码
package com.sxsihe.base;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Request;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.JsonPathSelector;
import us.codecraft.webmagic.utils.HttpConstant;
public class TestPostDemo implements PageProcessor{
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(10000);
@Override
public void process(Page page) {
// TODO Auto-generated method stub
List Notice_SD_ID = new JsonPathSelector("$.data[*].areaSamllCode").selectList(page.getRawText());
List x= new JsonPathSelector("$.data[*].name").selectList(page.getRawText());
//当前循环的应该是页面大小---即当前页的12条数据
for (int j=0;j nameValuePair = new HashMap();
NameValuePair[] values = new NameValuePair[3];
values[0] = new BasicNameValuePair("pageSize", "12");
values[1] = new BasicNameValuePair("condition.ifsigned", "1");
values[2] = new BasicNameValuePair("currentNo", String.valueOf(i));
nameValuePair.put("nameValuePair", values);
request.setExtras(nameValuePair);*/
request.setMethod(HttpConstant.Method.POST);
spider.addRequest(request);
}
spider.thread(3).run();
}
}
3.小技巧
(1)该类型的爬取,是模拟post请求数据的形式。所以,可以先在postman中先进行接口的运行,看是否能走通接口,然后在进行数据的爬取。
(2)打开开发者工具,点击Network,在点击请求的接口,其中Headers显示的是接口的地址,和一些参数信息(在form data中)。如:下图
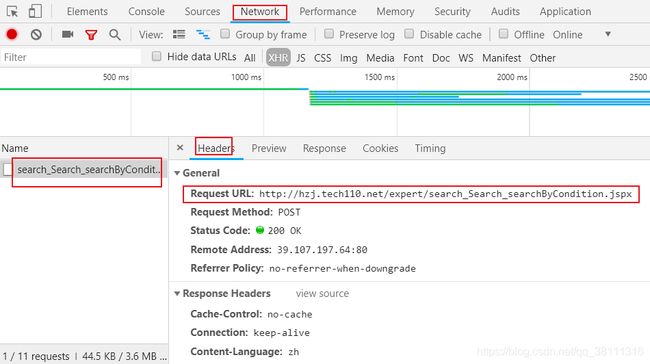
下图是显示的是一些参数:

参考链接:
https://webmagic.io/docs/zh/posts/ch1-overview/thinking.html
https://gitee.com/evenchow/Littleant_spider/blob/master/webmagicPost.java