算法模型-RMF
算法模型-RMF
原文链接:
https://blog.csdn.net/u012535605/article/details/79945009
https://www.jianshu.com/p/4b60880f24e2
https://blog.csdn.net/weixin_41548698/article/details/79975220?utm_source=blogxgwz0
https://blog.csdn.net/u013421629/article/details/80655969?utm_source=blogxgwz1
信息时代的来临使得企业营销的焦点从产品中心转化为客户中心,客户关系关系成为企业的核心问题,客户关系管理的核心问题是客户分类,
通过客户分类区分无价值、高价值客户,针对不同价值的客户采取不同的营销策略,以实现企业利润的最大化;
一、RFM模型概述
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。在众多的客户关系管理(CRM)的分析模式中,RFM模型是被广泛提到的。
该机械模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。
R(Recency):(最近一次消费)客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则交易发生的日期越近。
F(Frequency):(消费频率)客户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
M(Monetary):(消费金额)客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
1、R值:最近一次消费(Recency)
消费指的是客户在店铺消费最近一次和上一次的时间间隔,理论上R值越小的客户是价值越高的客户,即对店铺的回购几次最有可能产生回应。
目前网购便利,顾客已经有了更多的购买选择和更低的购买成本,去除地域的限制因素,客户非常容易流失,
因此CRM操盘手想要提高回购率和留存率,需要时刻警惕R值。
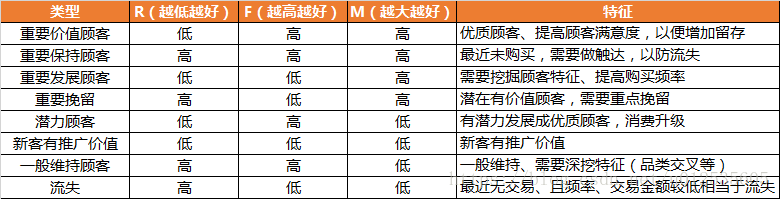
如下图,某零食网店用户最近一次消费R值分布图(时间截至2016年12月31日):
- 1、客户R值呈规律性的“波浪形”分布,时间越长,波浪越小;
- 2、最近一年内用户占比50%(真的很巧);
数据分析:这个数据是比较理想了的。说明每引入2个客户,就有一位用户在持续购买。说明店铺复购做的比较好,R值在不断的变为0。
2、F值:消费频率(Frequency)
消费频率是客户在固定时间内的购买次数(一般是1年)。但是如果实操中实际店铺由于受品类宽度的原因,
比如卖3C产品,耐用品等即使是忠实粉丝用户也很难在1年内购买多次。
所以,一般店铺在运营RFM模型时,会把F值的时间范围去掉,替换成累计购买次数。
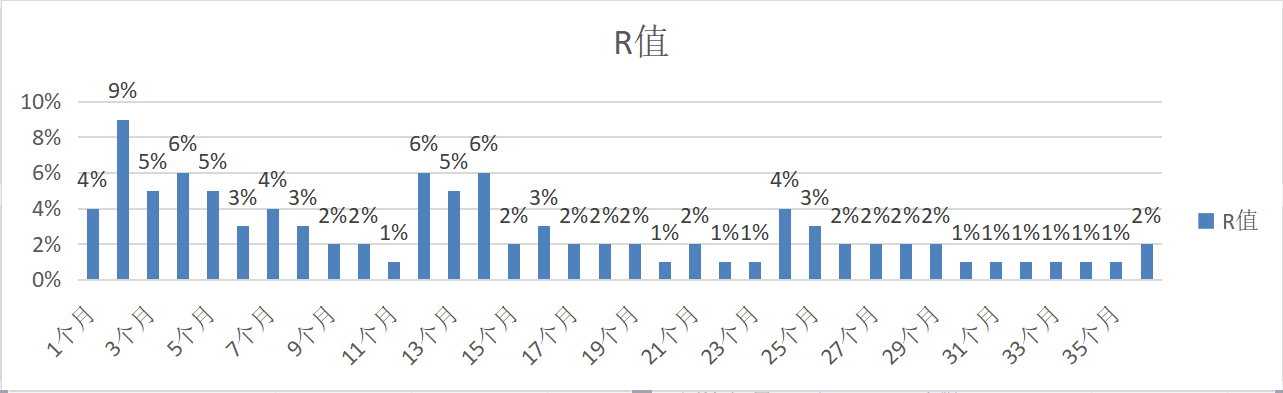
如下图,某零食网店用户购买频次图(如1个客户在1天内购买多笔订单,则自动合并为1笔订单):
- 1、购买1次(新客户)占比为65.5%,产生重复购买(老客户)的占比为34.4%;
- 2、购买3次及以上(成熟客户)的占比为17%,购买5次及以上(忠实客户)的占比为6%。
数据分析:影响复购的核心因素是商品,因此复购不适合做跨类目比较。比如食品类目和美妆类目:食品是属于“半标品”,产品的标品化程度越高,
客户背叛的难度就越小,越难形成忠实用户;但是相对美妆,食品又属于易耗品,
消耗周期短,购买频率高,相对容易产生重复购买,因此跨类目复购并不具有可比性。
3、M值:消费金额(Monetary)
M值是RFM模型中相对于R值和F值最难使用,但最具有价值的指标。大家熟知的“二八定律”(又名“帕雷托法则”)曾作出过这样
的解释:公司80%的收入来自于20%的用户。
这个数据我在自己所从事的公司总都得到过验证!可能有些店铺不会那么精确,一般也很会控制在30%客户贡献70%收入,
或者40%贡献60%收入。
理论上M值和F值是一样的,都带有时间范围,指的是一段时间(通常是1年)内的消费金额,在工作中我认为对于一般店铺
的类目而言,产品的价格带都是比较单一的,比如:同一品牌美妆类,价格浮动范围基本在某个特定消费群的可接受范围内,
加上单一品类购买频次不高,所以对于一般店铺而言,M值对客户细分的作用相对较弱。
所以我认为用店铺的累计购买金额和平均客单价替代传统的M值能更好的体现客户消费金额的差异。
教大家一个特别简单的累积金额划分方法:将1/2的客单价作为累积消费金额的分段,比如客单价是300元,则按照150元进行累计
消费金额分段,得出十个分段。
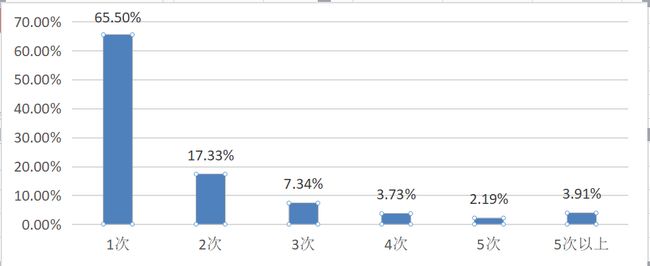
现以国内某知名化妆品店铺举例,店铺平均客单为160元,因此以80元作为间隔将累积消费金额分段,从表中可以很明显发现,
累计消费160元以下用户占比为65.5%(近2/3),贡献的店铺收入比例只占31.6%(近1/3),具体如下:
二、基于RFM模型的实践应用
作为CRM操盘手,主要有两种方法来分析RFM模型的结果:用基于RFM模型的划分标准来进行客户细分,
用基于RFM模型的客户评分来进行客户细分。
1、基于RFM模型进行客户细分
CRM实操时可以选择RFM模型中的1-3个指标进行客户细分,如下表所示。切记细分指标需要在自己可操控的合理范围内,
并非越多越好,一旦用户细分群组过多,一来会给自己的营销方案执行带来较大的难度,而来可能会遗漏用户群或者
对同个用户造成多次打扰。
最终选择多少个指标有两个参考标准:店铺的客户基数,店铺的商品和客户结构。
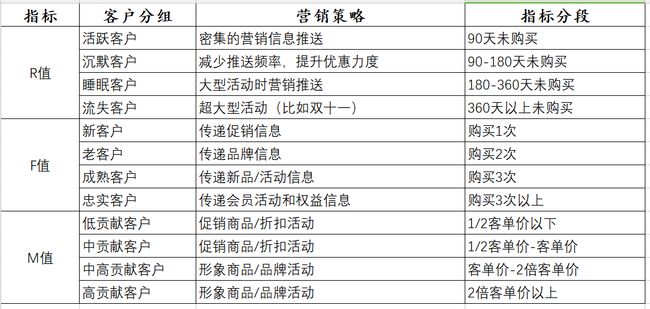
店铺的客户基数:在店铺客户一定的情况下选择的维度越多,细分出来每一组的用户越少。
对于店铺基数不大(5万以下客户数)的店铺而言,选择1-2个维度进行细分即可。
对于客户超过50万的大卖家而言可以选择2-3个指标。
店铺的商品和客户结构:如果在店铺的商品层次比较单一,客单价差异幅度不大的情况下,
购买频次(F值)和消费金额(M值)高度相关的情况下,可以只选择比较容易操作的购买频次(F值)代替消费金额(M值)。
对于刚刚开店还没形成客户粘性的店铺,则可以放弃购买频次(F值),直接用最后一次消费(R值)或者消费金额(M值)。
通过RFM模型评分后输出目标用户
除了直接用RFM模型对用户进行分组之外,还有一种常见的方法是利用RFM模型的三个属性对客户进行打分,
通过打分确定每个用户的质量,最终筛选出自己的目标用户。
2、RFM模型评分
主要有三个部分:
- 1、确定RFM三个指标的分段和每个分段的分值;
- 2、计算每个客户RFM三个指标的得分;
- 3、计算每个客户的总得分,并且根据总得分筛选出优质的客户
比如,实操的过程中一般每个指标分为3-5段,其中R值可以根据开店以来的时间和产品的回购周期来判定,
F值根据现有店铺的平均购买频次,M值可参考上文客单价的分段指标。

确认RFM的分段和对应分段的分值之后,就可以按照用户情况对应进行打分。
这个时候可能有人会对此产生质疑,我如何验证这个给予的分值就是合理的呢?
确实我也暂时没有办法给予和科学研究的回复,如果需要验证的话,每次对用户数据进行导入之后,需要用算法模型进行回归验证。
但是这样太复杂也太麻烦,如果有感兴趣的话可以进行验证,能够根据不同店铺的情况,
对于每个指标的赋值进行一个更加科学合理的定值。
三、R语言实现RMF
1、RMF模型说明
RMF模型是客户管理中,常被用来衡量客户价值和客户创利能力的重要方法。它主要考量三个指标:
- 最近一次消费-Recency:近期购买的客户倾向于再度购买
- 消费频率-Frequency:经常购买的客户再次购买概率高
- 消费金额-Monetary:消费金额较多的客户再次消费可能性更大
根据上述三个维度,对客户做细分,假定每个维度划分成五个等级,得到客户的R值(1-5),F值(1-5),M值(1-5)。
那么客户就被分作555 <- 125个细分群,我们可以根据客户交易行为的差异针对不同群体做不同的推荐。
或者进一步针对不同的业务场景,对R、F、M赋予不同权重Wr、Wf、Wm,得到每个用户的得分:W=WrR+WfF+Wm*M。
根据最终得分W排序,再划分等级,采用不用的营销策略。
RFM模型其实很简单,其重点应该是在:
一,如何做划分,不管是针对三个维度的划分还是三个维度取不同权重的和W的划分,都要依据实际业务场景情况确定。
二,针对不同的客户群如何选定合适的营销手段,这个则需要对每个客户群体有正确的解读,并且对实际业务场景理解比较深入。
2、R语言实现RMF
用来做分析的数据应该是一段时间里累计的客户的消费记录,每笔记录至少需要客户名称、消费时间、消费金额三个要素。
用R生成模拟随机消费记录数据。客户编号为1000-1999共100人,消费记录10000条,
消费记录产生时间在2014-01-01到2015-12-29之间。
观察数据结构:
str(sales)
'data.frame': 10000 obs. of 4 variables:
$ 用户ID : int 1017 1583 1351 1013 1720 1938 1770 1319 1896 1067 ...
$ 消费金额: num 157 201 228 199 302 173 131 218 191 232 ...
$ 消费时间: Date, format: "2014-01-01" ...
$ 距离时间: num 1565 1565 1565 1565 1565 ...
head(sales)
用户ID 消费金额 消费时间 距离时间
1 1017 157 2014-01-01 1565
2 1583 201 2014-01-01 1565
3 1351 228 2014-01-01 1565
4 1013 199 2014-01-01 1565
5 1720 302 2014-01-01 1565
6 1938 173 2014-01-01 1564
客户编号为1000-1999共100人,消费记录10000条,消费记录产生时间在2014-01-01到2015-12-29之间。
根据上述消费记录,得到Recency、Frequency、Monetary的值。
- 总消费金额
sales$距离时间 <- round(as.numeric(difftime(Sys.Date(),sales[,3],units = "days")))
names(salesM) <- c("用户ID","总消费")
- 消费次数
salesF <- aggregate(sales[,2],list(sales$用户ID),length)
names(salesF) <- c("用户ID","消费次数")
- 最近一次消费时间
saleR <- aggregate(sales[,4],list(sales$用户ID),min)
names(salesR) <- c("用户ID","最近消费时间")
test1<- merge(salesF,salesR,"用户ID")
salesRFM<- merge(salesM,test1,"用户ID")
head(salesRFM)
用户ID 总消费 消费次数 最近消费时间
1 1000 1281 8 855
2 1001 1442 8 1019
3 1002 919 5 887
4 1003 1437 7 893
5 1004 1461 8 917
6 1005 964 7 970
根据上述说明,对三个维度每个维度划分为5个层次,做均值划分。
并给R、F、M分别赋权重0.5,0.3,0.2来求客户最终得分,客户最终得分在1-5之间。
salesRFM0 <- salesRFM
salesRFM0$rankR <- cut(salesRFM$Recency,5,labels=F)
salesRFM0$最近消费时间 <- cut(salesRFM$Recency,5,labels=F)
salesRFM0$rankR <- cut(salesRFM$最近消费时间,5,labels=F)
salesRFM0$rankR <- 6- salesRFM0$rankR
salesRFM0$rankF <- cut(salesRFM0$消费次数,5,labels=F)
salesRFM0$rankM <- cut(salesRFM0$总消费,5,labels=F)
salesRFM0$rankRMF <- 0.5*rankR + 0.3*rankF+ 0.2*rankM
salesRFM0$rankRMF <- 0.5*salesRFM0$rankR+0.3*salesRFM0$rankF+0.2*salesRFM0$rankM
> head(salesRFM0)
用户ID 总消费 消费次数 最近消费时间 rankR rankF
1 1000 1281 8 855 5 2
2 1001 1442 8 1019 4 2
3 1002 919 5 887 5 1
4 1003 1437 7 893 5 2
5 1004 1461 8 917 5 2
6 1005 964 7 970 4 2
rankM rankRMF
1 2 3.5
2 2 3.0
3 1 3.0
4 2 3.5
5 2 3.5
6 1 2.8
对Receny、Frequency、Monetary标准化后,以权重权重0.5,0.3,0.2来求客户最终得分,客户最终得分在0-1之间。
> salesRFM1$rankF <- (salesRFM1$消费次数-min(salesRFM1$消费次数))/(max(salesRFM1$消费次数)-min(salesRFM1$消费次数))
> salesRFM1$rankM <- (salesRFM1$总消费)-min(salesRFM1$总消费))/(max(salesRFM1$总消费)-min(salesRFM1$总消费))
Error: unexpected ')' in "salesRFM1$rankM <- (salesRFM1$总消费)-min(salesRFM1$总消费))"
> salesRFM1$rankM <- (salesRFM1$总消费-min(salesRFM1$总消费))/(max(salesRFM1$总消费)-min(salesRFM1$总消费))
> salesRFM1$rankRMF <- 0.5*salesRFM1$rankR+03*salesRFM1$rankF+0.2*salesRFM1$rankM
> head(salesRFM1)
用户ID 总消费 消费次数 最近消费时间 rankR
1 1000 1281 8 855 0.9649805
2 1001 1442 8 1019 0.6459144
3 1002 919 5 887 0.9027237
4 1003 1437 7 893 0.8910506
5 1004 1461 8 917 0.8443580
6 1005 964 7 970 0.7412451
rankF rankM rankRMF
1 0.2777778 0.2621606 1.3682557
2 0.2777778 0.3076923 1.2178290
3 0.1111111 0.1597851 0.8166522
4 0.2222222 0.3062783 1.1734476
5 0.2777778 0.3130656 1.3181254
6 0.2222222 0.1725113 1.0717915
以上用到的权重需要根据实际情况考量选定。得到的客户评分rankRMF,是客户细分的一个参考依据,
实际场景中,我们可能还有客户的其他数据,可以综合来看。
四、python实现RMF
1、RFM算法步骤:
1.1、计算RFM各项分值
R_S,距离当前日期越近,得分越高,最高7分,最低1分,按实际数据分布情况切割依次从高到低取分数。
F_S,交易频率越高,得分越高,最高7分,最低1分,按实际数据分布情况切割依次从高到低取分数。
M_S,交易金额越高,得分越高,最高7分,最低1分,按实际数据分布情况切割依次从高到低取分数。
1.2、归总RFM分值
RFM赋予权重(目前权重采用R:F:M = 1:1:1),权重乘以分数归总RFM分值。这个总RFM分值作为衡量用户价值的关键指标。
公式如下:
2、根据RFM分值对客户分类
# encoding: utf-8
# 导入包
import pandas as pd
####写入excel设置问题####
import xlsxwriter
# 定义RFM函数
def RFM(aggData):
"""
:param aggData: 输入数据集,数据集字段要包含recency,frequency,monetary等三个字段
:return:返回数据集结果
"""
# 计算R_S
bins = aggData.recency.quantile(q=[0, 0.28, 0.38, 0.46, 0.53, 0.57, 0.77, 1], interpolation='nearest')
bins[0] = 0
labels = [7, 6, 5, 4, 3, 2, 1]
R_S = pd.cut(aggData.recency, bins, labels=labels)
# 计算F_S
bins = aggData.frequency.quantile(q=[0, 0.29, 0.45, 0.60, 0.71, 0.76, 0.90, 1], interpolation='nearest')
bins[0] = 0
labels = [1, 2, 3, 4, 5, 6, 7]
F_S = pd.cut(aggData.frequency, bins, labels=labels)
# 计算M_S
bins = aggData.monetary.quantile(q=[0, 0.20, 0.26, 0.45, 0.55, 0.76, 0.85, 1], interpolation='nearest')
bins[0] = 0
labels = [1, 2, 3, 4, 5, 6, 7]
M_S = pd.cut(aggData.monetary, bins, labels=labels)
# 赋值
aggData['R_S'] = R_S
aggData['F_S'] = F_S
aggData['M_S'] = M_S
# 计算FRM值
aggData['RFM'] = R_S.astype(int)*1 + F_S.astype(int)*1 + M_S.astype(int)*1
# 根据RFM分值对客户分类
#分五类
bins = aggData.RFM.quantile(q=[0, 0.2, 0.4, 0.6, 0.8, 1],interpolation='nearest')
bins[0] = 0
labels = [1, 2, 3, 4, 5]
aggData['level'] = pd.cut(aggData.RFM,bins, labels=labels)
return aggData
# 主函数
if __name__ == '__main__':
# 读取数据
aggData = pd.read_csv('C:\\Users\\xiaohu\\Desktop\\月刊数据\\4月份用户价值数据.csv')
# 调用模型函数
result=RFM(aggData)
# 打印结果
print(result)
# 计算每个类别的数据量
c1=list(result["level"].value_counts())
# 计算每个类别所占的百分比
c2 = list(result["level"].value_counts()/len(result)*100)
c3=(list(map(lambda x:str(round(x,3))+"%",c2)))
c=pd.DataFrame({"level":range(1,len(c1)+1),"数量":c1,"百分比":c3})
print(c)
# 写出csv
result.to_csv('C:\\result5_50_四月份.csv',index=False)
3、RFM+kmeans算法
# 导入包
from __future__ import division
import pandas as pd
from sklearn.cluster import KMeans
#####python画图显示中文参数设置####
##设置中文显示##
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
font_size =11 # 字体大小
fig_size = (8, 6) # 图表大小
# 更新字体大小
mpl.rcParams['font.size'] = font_size
# 更新图表大小
mpl.rcParams['figure.figsize'] = fig_size
# 定义RFM函数
def RFM(aggData):
"""
:param aggData: 输入数据集,数据集字段要包含recency,frequency,monetary等三个字段
:return:返回数据集结果
"""
# 计算R_S
bins = aggData.recency.quantile(q=[0, 0.31, 0.38, 0.46, 0.53, 0.57, 0.77, 1], interpolation='nearest')
bins[0] = 0
labels = [7, 6, 5, 4, 3, 2, 1]
R_S = pd.cut(aggData.recency, bins, labels=labels)
# 计算F_S
bins = aggData.frequency.quantile(q=[0, 0.29, 0.45, 0.60, 0.71, 0.76, 0.90, 1], interpolation='nearest')
bins[0] = 0
labels = [1, 2, 3, 4, 5, 6, 7]
F_S = pd.cut(aggData.frequency, bins, labels=labels)
# 计算M_S
bins = aggData.monetary.quantile(q=[0, 0.20, 0.26, 0.45, 0.55, 0.76, 0.85, 1], interpolation='nearest')
bins[0] = 0
labels = [1, 2, 3, 4, 5, 6, 7]
M_S = pd.cut(aggData.monetary, bins, labels=labels)
# 赋值
aggData['R_S'] = R_S
aggData['F_S'] = F_S
aggData['M_S'] = M_S
# 计算FRM值
aggData['RFM'] = R_S.astype(int) + F_S.astype(int) + M_S.astype(int)
#分五类
bins = aggData.RFM.quantile(q=[0, 0.2, 0.4, 0.6, 0.8, 1],interpolation='nearest')
bins[0] = 0
labels = [1, 2, 3, 4, 5]
aggData['level'] = pd.cut(aggData.RFM,bins, labels=labels)
return aggData
# 读取数据
aggData = pd.read_csv('C:\\Users\\xiaohu\\Desktop\\用户价值分析\\用户价值分析RFM模型\\source\\RFM_Data_50.csv')
# print(aggData)
aggData2=RFM(aggData)
print(aggData2)
# 选择recency,frequency,monetary这三列
data=aggData2.loc[:,['recency','frequency','monetary']]
print(data)
# 定义数据标准化函数 Min-max 标准化
def Normalization(df):
return df.apply(lambda x: (x - np.min(x)) / (np.max(x) - np.min(x)))
# 调用函数进行数据标准化(0-1)之间
zsredfile=Normalization(data)
# 对列进行重命名
names = ['ZR','ZF','ZM']
zsredfile.columns = names
print(zsredfile)
#####选择最佳的K值#####
"""
一般我们可以 通过迭代的方式选出合适的聚类个数 ,即让k值从1到K依次执行一遍,
再查看每一次k值对应的簇内离差平方和之和的变化,
如果变化幅度突然由大转小时,那个k值就是我们选择的合理个数
"""
K = range(1,15)
GSSE = []
for k in K:
print(K)
SSE = []
kmeans = KMeans(n_clusters=k, random_state=10)
kmeans.fit(zsredfile)
labels = kmeans.labels_
centers = kmeans.cluster_centers_
for label in set(labels):
SSE.append(np.sum(np.sum((zsredfile[['ZR', 'ZF','ZM']].loc[labels == label,] - centers[label, :]) ** 2)))
GSSE.append(np.sum(SSE))
# 绘制K的个数与GSSE的关系
plt.plot(K, GSSE, 'b*-')
plt.xlabel('聚类个数')
plt.ylabel('簇内离差平方和')
plt.title('选择最优的聚类个数')
plt.show()
#选择最优的聚类个数为5
seed(123)
#调用sklearn的库函数
num_clusters = 5
kmeans = KMeans(n_clusters=num_clusters, random_state=1)
kmeans.fit(zsredfile)
# 聚类结果标签
data['cluster'] = kmeans.labels_
# 聚类中心
centers = kmeans.cluster_centers_
cluster_center = pd.DataFrame(kmeans.cluster_centers_)
# 绘制散点图
plt.scatter(x = zsredfile.iloc[:,0], y = zsredfile.iloc[:,1], c = data['cluster'], s=50, cmap='rainbow')
plt.scatter(centers[:,0], centers[:,1], c='k', marker = '*', s = 180)
plt.xlabel('ZR')
plt.ylabel('ZF')
plt.title('聚类效果图')
# 图形显示
plt.show()
#查看RFM模型8个类别中的用户数量以及占比多少
result=data
aggData2['cluster']=result["cluster"]
# 计算每个类别的数据量
c1 = list(result["cluster"].value_counts())
# 计算每个类别所占的百分比
c2 = list(result["cluster"].value_counts() / len(result) * 100)
c3 = (list(map(lambda x: str(round(x, 3)) + "%", c2)))
c = pd.DataFrame({"level": range(1, len(c1) + 1), "数量": c1, "百分比": c3})
print(c)
# 写出csv
aggData2.to_csv('C:\\Users\python_result_kmeans_50.csv', index=False)
cluster_center.to_csv('C:\\Users\\cluster_center.csv')
4、RFM+层次聚类
#加载相关库
#######################################
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.cluster import Birch
from sklearn import metrics
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.externals import joblib
import time
import datetime
#加载数据集及提取数列
customdata = pd.read_csv(r'C:\\Users\\xiaohu\\Desktop\\RFM\\out_custom_label.csv')
new_custom_data = customdata[["R_S","F_S","M_S"]]
new_custom_data = new_custom_data.astype(np.float32)
new_custom_data = new_custom_data.values
#数据标准化
new_custom_data = StandardScaler().fit_transform(new_custom_data)
#模型训练
Birch_model = Birch(threshold=0.85, branching_factor=500,
n_clusters=None,compute_labels=True, copy=True).fit(new_custom_data)
#提取分类结果
label = Birch_model.labels_
label = pd.DataFrame(label)
label.columns = ['cluster.label']
outresult = pd.concat([customdata, label], axis = 1)
cluster_center = pd.DataFrame(Birch_model.subcluster_centers_)
n_clusters = np.unique(label).size
print("n_clusters : %d" % n_clusters)
#结果输出
outresult.to_csv('C:\\Users\\birch_outresult.csv')
cluster_center.to_csv('C:\\Users\\cluster_center.csv')