hadoop集群安装 vmware15.5+CentOs7
环境
vmware15.5
centos7完成安装配置
可采用最小安装或gnome界面安装,根据电脑配置选择
1.配置网络
理论上采用NAT网络模式,但问题过于玄学,笔者这里使用桥接网络
本人使用两台centos7分别作为主从节点,使用ip可以根据主机网关进行设置。
这里以192.168.2.115和192.168.2.116为例(注:根据自己的网关进行合理配置)
vi /etc/sysconfig/network-scripts/ifcfg-ens33修改BOOTPROTO=static、ONBOOT=yes
IPADDR=192.168.2.115
NETWORK=255.255.255.0
GATEWAY=192.168.2.1
DNS1=119.29.29.29
DNS2=192.168.220.2
尽量手敲,复制可能出错
重启网卡
systemctl restart network
查看ip是否设置成功
ip addr
查看ens33的ip是否为设置的ip
ping www.baidu.com测试网络是否连接
2.关闭防火墙
firewall-cmd --state
看看防火墙状态
systemctl stop firewalld.service
关闭防火墙
systemctl disable firewalld.service
禁用防火墙3.安装Java
java -version
查看是否存在已安装的Java版本
rpm -qa |grep java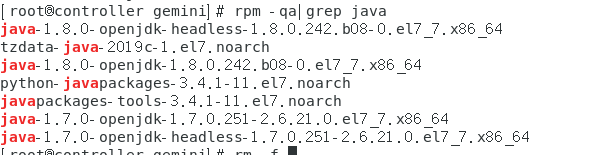
如果有,删除卸载
rm -f Java版本删除完毕之后,从官网下载对应的jdk二进制包,若网络较慢可以选择其他镜像文件
创建安装目录
mkdir /usr/local/java解压到目录
tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/java/设置环境变量
vim /etc/profile添加
export JAVA_HOME=/usr/local/java/对应的安装版本
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH生效
source /etc/profile检查版本
java -version4.克隆本虚拟机
可以根据需求选择克隆数量
5.修改信息
接下来将用master和slave1区分主从节点
修改命令
master:
hostnamectl set-hostname master
slave1:
hostnamectl set-hostname slave1修改slave1的ip为192.168.2.116(与masterip不同)
分别更改hosts文件
vi /etc/hosts
192.168.2.115 master
192.168.2.116 slave1全部重启
6.配置免密登录
查看ssh状态
systemctl status sshd.service 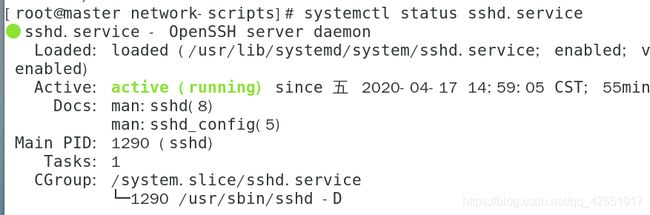
设置开机自启
systemctl enable sshd.service生成秘钥,两台虚拟机都需要执行以下步骤
ssh-keygen -t rsa一路回车到最后
进入文件夹
cd /root/.ssh将公钥放入授权文件
cat id_rsa.pub >> authorized_keys更改文件权限
chmod 644 authorized_keys交换秘钥
master:
scp /root/.ssh/authorized_keys slave1:/root/.ssh
slave1:
scp /root/.ssh/authorized_keys master:/root/.ssh 重启ssh后可登录测试
ssh slave1
ssh master7.安装hadoop
注意:
一下涉及到目录的配置,一定要以实际为准!!!
下载地址:http://hadoop.apache.org/releases.html
选择binary二进制下载
解压到目录:
tar -zxvf hadoop-2.6.0-cdh5.15.1.tar.gz -C /usr配置HADOOP_HAME环境变量
vim /etc/profile添加
export HADOOP_HOME=/usr/hadoop-2.10.0 这里hadoop-2.10.0以自己的名称为准
export PATH=$PATH:$HADOOP_HOME/bin生效
source /etc/profile配置hadoop-env.sh
cd $HADOOP_HOME/etc/hadoop
vim hadoop-env.sh添加
export JAVA_HOME=/usr/Java/jdk1.8.231 目录地址以实际为准配置core-site.xml
vim core-site.xml添加
fs.defaultFS
hdfs://master:8020
hadoop.tmp.dir
/usr/hadoop-2.10.0
master 指的是主节点的名称;8020是使用的虚拟机端口(可以设别的,但是要记住!)
hadoop.tmp.dir的文件目录可以自行设定
配置hdfs-site.xml
vim hdfs-site.xml添加
dfs.replication
1
dfs.namenode.name.dir
/usr/hadoop-2.10.0/name
dfs.datanode.data.dir
/usr/hadoop-2.10.0/data
fs.checkpoint.dir
...
dfs.http.address
master:50070
dfs.secondary.http.address
master:50090
dfs.webhdfs.enabled
false
dfs.permissions
false
1指的是从节点的数量
配置yarn-site.xml
vim yarn-site.xml添加
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
master
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
配置mapred-site.xml
vim mapred-site.xml
添加
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
配置slaves
vim slaves输入master,slave1
远程发送到slave1或者在slave1上重复操作安装步骤
远程指令
scp -r /usr/hadoop-2.10.0 slave1:/usr/hadoop-2.10.08.启动hadoop
hdfs格式化
cd $HADOOP_HOME/bin
hdfs namenode -format启动hdfs
cd $HADOOP_HOME/sbin
./start-dfs.sh查看master
[root@master sbin]# jps
7429 ResourceManager
7063 NameNode
7545 Jps
7260 SecondaryNameNode
查看slave1
[root@slave1 admin]# jps
4435 NodeManager
4634 Jps
4303 DataNode
出现hadoop2.0以后的版本不在有jobtracker进程;DataNode也可以设置在master节点
以上进程则安装成功,否则进入hadoop-2.10.0/logs目录查看对应缺少进程的日志寻找问题
主要与hadoop-2.10.0/etc/hadoop内的配置文件内容相关,若以上配置不能解决问题,建议寻找其他配置方法尝试
网页查看
浏览器键入master:8088或master:50070