【jsoup爬虫2】用jsoup来实现简单的java爬虫-图片篇
继上一篇抓小说(http://blog.csdn.net/suqi356/article/details/78547137)后,我们对用过的jsoup进行一个简单的小结。
先总结jsoup 的主要功能如下:
1. 从一个 URL,文件或字符串中解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找、取出数据;
3. 可操作 HTML 元素、属性、文本;
其次,对我们用到的方法进行一个简单梳理:
1.pare(String html,String baseUrl) 这个方法能够将输入的HTML解析为一个新的文档 (Document),参数 baseUri 是用来将相对 URL 转成绝对URL,并指定从哪个网站获取文档。如这个方法不适用,你可以使用pare(String html)方法来解析成HTML字符串如上面的示例.
2.Document对象(一个文档的对象模型):文档由多个Elements和TextNodes组成 ,一个Element包含一个子节点集合,并拥有一个父Element。他们还提供了一个唯一的子元素过滤列表。
3.connect(String url) 方法创建一个新的connection 和 get() 取得和解析一个HTML文件。如果从该URL获取HTML时发生错误,便会抛出 IOException,应适当处理。常会出现403,504等4XX和5XX开头的,主要是服务端拒绝访问,拒绝连接,是服务端网页的反爬虫措施,下文讲爬虫图片的时候会提到。
最后,介绍一个“很厉害”的内容:使用选择器语法来查找元素(select),使用 Element.select(String selector) 和 Elements,select(String selector) ,使用类似于CSS或jQuery的语法来查找和操作元素。这个选择范围很广,使用起来很方便。
对总结,我这里查到一篇别人写的博客,比我总结的好,可以参考一下:http://blog.csdn.net/u010814849/article/details/52526582
现在进入正文,本篇的图片篇
先介绍一下爬虫http://image.baidu.com这个页面的图片,然后介绍一下CSDN推荐那篇python 3简单入门爬虫(http://mp.weixin.qq.com/s/lGenb6F-r8YyoE2ZO0cVSw)里的例子https://unsplash.com
这里都需要用到一个对请求和响应抓包的工具Fiddler,其实浏览器自带的开发者模式下的NetWorks也可以,但是我用过后发现前者要比后者详细一点,这个凭借个人爱好选择。
一、百度图片
我们先访问image.baidu.com这个网站,看看页面上相关代码,上一篇我们知道,我们找到前端的关键字就能利用jsoup来获取里面的内容,然后利用IO来输出图片保存就可以了。但是我们发现页面的图片地址并没有很规律的地址。

我们发现地址差不多都是http://X.hiphotos.baidu.com/image/h%3D300/sign=XXXXXXXXXXXXXX这种地址,而根据不同的时间段访问这个页面,图片也是在变化的,经过发现,我推测它应该是动态加载的,并不像小说一样是静态页面,里面的资源一成不变的。我们也不知道这里的X代表的什么的,毕竟这个X并没有规律应该是利用类似UUID这种随机生成的技术。于是打开Fiddler进行抓包,看看里面具体有什么。
逐步一一分析发现,有一个GET很有问题:
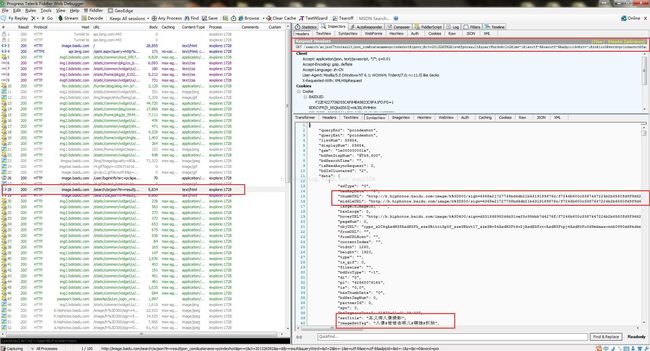
发现我们页面的图片地址和内容以及相关数据,比如标题标签都能对的上,那么一定是这个请求是发给服务器的,于是我们尝试写代码,利用这个请求来获取地址来抓包。
抓包时候我们需要写成完整的地址,加上前缀http://image.baidu.com,同时我们可以利用String处理字符串的方式来获取到需要的URL地址,来打开图片地址来利用IO下载图片。
import java.io.File;
import java.io.IOException;
import java.io.*;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.net.URLEncoder;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Test4 {
public static void get_html(String url) {
try {
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(999999999)
.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8")
.header("Accept-Encoding", "gzip, deflate")
.header("Accept-Language", "zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3")
.header("Connection", "keep-alive")
.header("Host", "image.baidu.com")
.header("Referer", "http://image.baidu.com/")
//是忽略请求类型
.ignoreContentType(true)
.get();
/*
* Accept:告知服务器,客户端可以接受的数据类型(MIME类型)
* 文件系统:通过文件的扩展名区分不同的文件的。txt jpeg
* MIME类型:大类型/小类型。
* txt--->text/plain html---->text/html js---->text/javascript
* (具体对应关系:Tomcat\conf\web.xml)
*Accept-Encoding:告知服务器,客户端可以接受的压缩编码。比如gzip
*Accept-Language:告知服务器,客户端支持的语言。
* Referer:告知服务器,从哪个页面过来的。
*Content-Type:告知服务器,请求正文的MIME类型
* 默认类型:application/x-www-form-urlencoded(表单enctype属性的默认取值)
* 具体体现:username=abc&password=123
* 其他类型:multipart/form-data(文件上传时用的)
*User-Agent:告知服务器,浏览器的类型
*Content-Length:请求正文的数据长度
*Cookie:会话管理有关
*/
String str = doc.text();
int start = str.indexOf("\"thumbURL\":\"");
int end = str.indexOf("\",\"middleURL");
String need = null;
while (start != -1) {
need = str.substring(start + 12, end);
downImages("d:/img", need);
System.out.println(need);
start = str.indexOf("\"thumbURL\":\"", start + 1);
end = str.indexOf("\",\"middleURL", end + 1);
}
} catch (Exception e) {
e.printStackTrace();
}
}
//下载图片
private static void downImages(String filePath, String imgUrl) {
// 若指定文件夹没有,则先创建
File dir = new File(filePath);
if (!dir.exists()) {
dir.mkdirs();
}
// 截取图片文件名
String fileName = imgUrl.substring(imgUrl.lastIndexOf('/') + 1, imgUrl.length());
try {
// 文件名里面可能有中文或者空格,所以这里要进行处理。但空格又会被URLEncoder转义为加号
String urlTail = URLEncoder.encode(fileName, "UTF-8");
// 因此要将加号转化为UTF-8格式的%20
imgUrl = imgUrl.substring(0, imgUrl.lastIndexOf('/') + 1)
+ urlTail.replaceAll("\\+", "\\%20");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
// 写出的路径
File file = new File(filePath + File.separator + fileName);
try {
// 获取图片URL
URL url = new URL(imgUrl);
// 获得连接
URLConnection connection = url.openConnection();
// 设置10秒的相应时间
connection.setConnectTimeout(10 * 1000);
// 获得输入流
InputStream in = connection.getInputStream();
// 获得输出流
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(file));
// 构建缓冲区
byte[] buf = new byte[1024];
int size;
// 写入到文件
while (-1 != (size = in.read(buf))) {
out.write(buf, 0, size);
}
out.close();
in.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url =
"http://image.baidu.com/search/acjson?tn=resultjson_com&catename=pcindexhot&ipn=rj&ct=201326592&is=&fp=result&queryWord=&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&word=pcindexhot&face=0&istype=2&qc=&nc=1&fr=&pn=0&rn=15";
get_html(url);
}
}
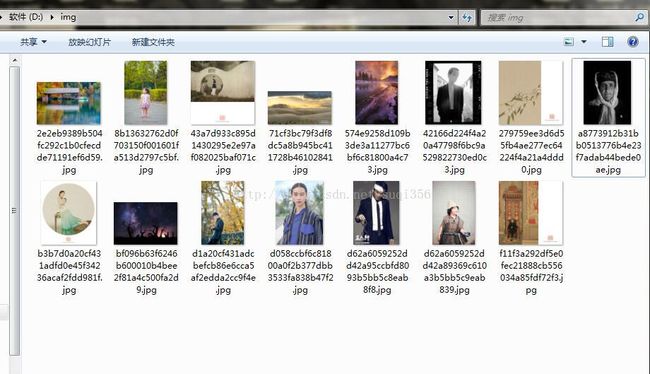
这样我们发现图片下载下来了,在这里我们还可以对抓到这个地址进行分析来获取其余效果,比如更改rn=15这个参数值,比如把15改成30会发生什么呢?会发现我们可以下载30张照片,同理你还可以更改别的参数,这里就不多说了,自己探索。
那这只是获取image.baidu.com这个页面的图片,那么如果我们要获取搜到的图片,如何写代码呢?这里给一个关于利用jsoup百度图片瀑布模型抓包的例子:http://blog.csdn.net/greatkendy123/article/details/51759040
其实这种网页重点是对动态资源加载的捕获,这个需要对抓包、分析就有一定的要求了。
二、unsplash图片网站
根据上面对百度图片的抓包爬虫,同样unsplash也需要,但是unsplash有一个他是https的链接,是拥有SSL证书的网站,这个就需要对SSL证书一些处理。
这里对SSL证书最简单的处理的就是用最新的JDK1.8和最新的jsoup会自动对SSL证书验证处理的,如果用的老版本JDK不对证书处理的话,会出现SSL异常。

具体为何1.8对会SSL证书处理,这个我还在研究,如果有知道的请留言告诉我一声。
这个网站的图片同样是动态资源加载,同理利用Fiddler来抓包一下,我们逐步一一分析发现

根据CSDN推荐那位博客博主的提到的,这个网站会对authorization进行验证,所以需要抓到你自己的authorization,然后粘贴进去就能获取到了。
代码和上面百度的差不多,只需要改一个主方法里的地址连接,给get_html方法增加一个.header("authorization", 你的Client-ID值)就可以了。
这里还有一个说明,有些图片网站的图片保存到服务器,我们爬虫这些内容的时候,有些网站还会对这里进行反爬虫处理,那么我们仅需要对下载图片方法里的连接模拟成浏览器来处理就可以了。
private static void downImages(String filePath, String imgUrl) {
// 若指定文件夹没有,则先创建
File dir = new File(filePath);
if (!dir.exists()) {
dir.mkdirs();
}
// 截取图片文件名
String fileName = imgUrl.substring(imgUrl.lastIndexOf('/') + 1, imgUrl.length());
try {
// 文件名里面可能有中文或者空格,所以这里要进行处理。但空格又会被URLEncoder转义为加号
String urlTail = URLEncoder.encode(fileName, "UTF-8");
// 因此要将加号转化为UTF-8格式的%20
imgUrl = imgUrl.substring(0, imgUrl.lastIndexOf('/') + 1) + urlTail.replaceAll("\\+", "\\%20");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
// 写出的路径
File file = new File(filePath + File.separator + fileName);
try {
// 获取图片URL
URL url = new URL(imgUrl);
// 获得连接
URLConnection connection = url.openConnection();
connection.setConnectTimeout(100000);
connection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
connection.setRequestProperty("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
connection.setRequestProperty("Referer", "http://127.0.0.1/");
// 设置10秒的相应时间
connection.setConnectTimeout(100000 * 10000);
// 获得输入流
InputStream in = connection.getInputStream();
// 获得输出流
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(file));
// 构建缓冲区
byte[] buf = new byte[1024];
int size;
// 写入到文件
while (-1 != (size = in.read(buf))) {
out.write(buf, 0, size);
}
out.close();
in.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}这里对connection加几个属性模拟是浏览器访问。这样处理能对大多数反爬虫的网站抓图片。
三、关于静态网站或者没有反爬虫的网站爬虫图片
上面的主要是反爬虫网站,SSL认证网站和动态加载资源网站的爬虫,如果没有上面的这些技术的网站爬虫就很简单了。分析前端代码,找到img属性,利用select方法,写一个简单的属性名+正则表达式img[src]就可以处理了。