Python网络爬虫小试刀——抓取ZOL桌面壁纸图片4
前篇回顾:获得一个类型集合页面中所有集合中的图片
本篇目标:获取整个网站所有类型集合的壁纸图片
使用urllib2,正则表达式,threading等高效下载网站’http://desk.zol.com.cn‘中壁纸图片。
使用urllib2获取url = ‘http://desk.zol.com.cn‘中HTML代码,从HTML中使用正则表达式截取我们所需要的内容。
建立函数def getImgTotal(url, filePath):
首先,获取HTML。
代码如下:
115 def getImgTotal(url, filePath):
116 if not os.path.exists(filePath):
117 os.makedirs(urlPath)
118 if not filePath.endswith('/'):
119 filePath += '/'
120
121 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
122 headers = {'User-Agent' : user_agent}
123
124 request = urllib2.Request(url, headers=headers)
125 content = urllib2.urlopen(request).read().decode('GBK')
126
127 f = open('url.txt', 'w')
128 f.write(content.encode('utf-8'))
129 f.close()
130
131 print content
132部分结果截图:

我们要获取的部分为图片类型分类如下图:
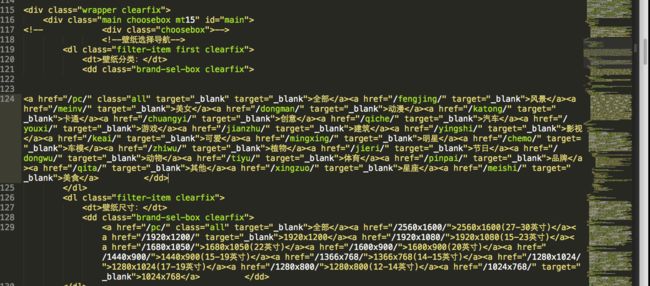
从中要获取类型集合的url和类型集合的名称。
使用正则表达式截取如下:
‘
115 def getImgTotal(url, filePath):
116 if not os.path.exists(filePath):
117 os.makedirs(urlPath)
118 if not filePath.endswith('/'):
119 filePath += '/'
120
121 user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
122 headers = {'User-Agent' : user_agent}
123
124 request = urllib2.Request(url, headers=headers)
125 content = urllib2.urlopen(request).read().decode('GBK')
126
127 pattern = re.compile('(.+?)' , \
128 re.S)
129 imgList = re.findall(pattern, content)
130
131 for item in imgList:
132 tmpUrl = ''
133 tmpPath = ''
134 tmpUrl = mUrl + '/' + item[0] + '/'
135 tmpPath = filePath + item[1]
136 print tmpUrl
137 print tmpPath
138结果如下:
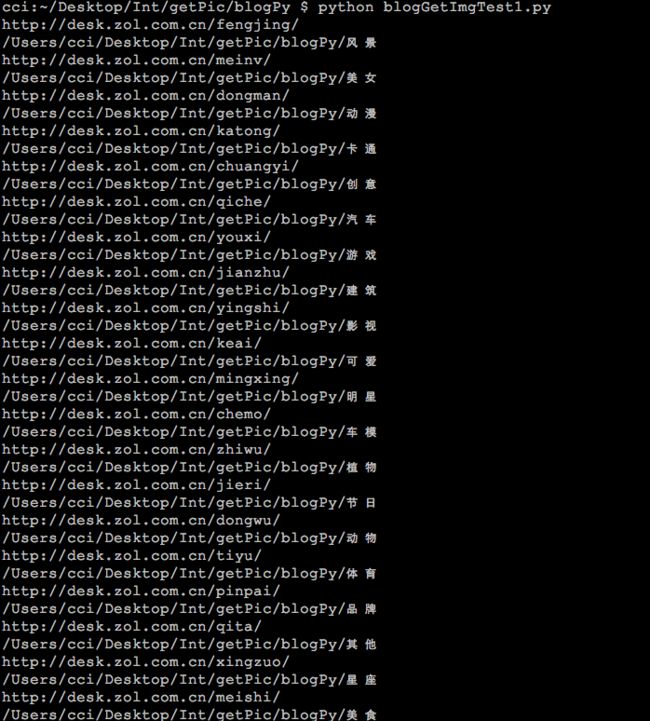
现在可以将上篇所写下载一个类型集合的函数def getImgCatalog(url, filePath):加进去了,再添加多线程和线程锁增加下载速度。
整体代码如下:
#/usr/bin/env python
import os
import re
import urllib
import urllib2
import datetime
import threading
mUrl = 'http://desk.zol.com.cn'
def downloadImg(url, imgName, savePath):
if savePath == '':
return 'image save path is nil.'
if imgName == '':
return 'image is nil.'
if url == '':
return 'url is nil.'
if not os.path.exists(savePath):
os.makedirs(savePath)
if not savePath.endswith('/'):
savePath += '/'
savePathName = savePath + imgName
urllib.urlretrieve(url, savePathName)
print url
def getImgAssemble(url, fileName, filePath):
if not os.path.exists(filePath):
os.makedirs(filePath)
if not filePath.endswith('/'):
filePath += '/'
if not fileName in filePath:
filePath += fileName
print '******', url
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent' : user_agent}
tmpUrl = url
while True:
try:
request = urllib2.Request(tmpUrl, headers=headers)
content = urllib2.urlopen(request).read().decode('GBK')
imgUrl = re.search('' , \
content).group(1)
imgCount = re.search('.+?.+?(\d+).+?
', \
content).group(1)
imgSuffix = re.search('http://.+?\..+?/.+?\.(.+?)$', \
imgUrl).group(1)
imgName = fileName + imgCount + '.' + imgSuffix
downloadImg(imgUrl, imgName, filePath)
nextUrlFlag = re.search('' , \
content).group(1)
if not "javascript:" in nextUrlFlag:
tmpUrl = mUrl + nextUrlFlag
continue
else:
print '\n'
break
except AttributeError:
print 'attributeError'
except urllib2.URLError, e:
if hasattr(e, 'code'):
print e.code
if hasattr(e, 'reason'):
print e.reason
catalogLock = threading.Lock()
def getImgCatalog(url, filePath):
if not os.path.exists(filePath):
os.makedirs(filePath)
if not filePath.endswith('/'):
filePath += '/'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent' : user_agent}
tmpUrl = url
while True:
request = urllib2.Request(tmpUrl, headers=headers)
content = urllib2.urlopen(request).read().decode('GBK')
pattern = re.compile('' , \
content).group(1)
imgTotalLock = threading.Lock()
def getImgTotal(url, filePath):
if not os.path.exists(filePath):
os.makedirs(urlPath)
if not filePath.endswith('/'):
filePath += '/'
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent' : user_agent}
request = urllib2.Request(url, headers=headers)
content = urllib2.urlopen(request).read().decode('GBK')
pattern = re.compile('(.+?)' , \
re.S)
imgList = re.findall(pattern, content)
threads = []
for item in imgList:
tmpUrl = ''
tmpPath = ''
tmpUrl = mUrl + '/' + item[0] + '/'
tmpPath = filePath + item[1]
if imgTotalLock.acquire():
t = threading.Thread(target=getImgCatalog, args=(tmpUrl, tmpPath))
t.setDaemon(True)
threads.append(t)
imgTotalLock.release()
for i in range(len(threads)):
threads[i].start()
for i in range(len(threads)):
threads[i].join(100)
def main():
startTime = datetime.datetime.now()
#img save path
savePath = os.getcwd()
url = 'http://b.zol-img.com.cn/desk/bizhi/image/7/960x600/1450950428732.jpg'
#img name4
imgName = 'pic1.jpg'
#downloadImg(url, imgName, savePath)
sUrl = 'http://desk.zol.com.cn/bizhi/6128_75825_2.html'
fileName = 'meinv'
#getImgAssemble(sUrl, fileName, savePath)
cUrl = 'http://desk.zol.com.cn/meinv/'
cFilePath = savePath+'/meinv'
#getImgCatalog(cUrl, cFilePath)
getImgTotal(mUrl, savePath)
endTime = datetime.datetime.now()
print '\ntotal running time : %d s' %(endTime-startTime).seconds
if __name__ == '__main__':
main()假死问题。
还请高人指点。。。
the end
谢谢