优化 AIX 7 内存性能: 监视内存的使用情况(ps、sar、svmon 和 vmstat)并分析其结果
http://www.csdn.net/article/a/2011-01-18/290363
在本节中,我们概述在所有 UNIX 发行版中都可以使用的一些通用 UNIX 工具,包括 ps、sar 和 vmstat。其中的大多数工具都允许快速地对性能问题进行故障排除,但是它们并不适用于进行历史趋势研究和分析。
大多数管理员不经常使用 ps 命令对可能存在的内存瓶颈进行故障排除。但是,ps 可以提供关于系统运行情况的大量信息,因此有助于了解使用内存的情况。ps 最常用的功能是查看系统中正在运行的进程(见 清单 1)。
清单 1. 使用 ps 查看系统中正在运行的进程
# ps -ef | more
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Jul 30 - 0:01 /etc/init
root 1442014 3211408 0 Jul 30 - 0:00 /usr/sbin/snmpd
root 1638422 3211408 0 Jul 30 - 0:00 /usr/sbin/rsct/bin/IBM.DRMd
pconsole 1769544 5570756 0 Jul 30 - 1:53 /usr/java5/bin/java -Xmx512m -Xms20m
-Xscmx10m -Xshareclasses
-Dfile.encoding=UTF-8
root 1900682 1 0 Jul 30 - 0:00 /usr/lib/errdemon
root 2031702 1 0 Jul 30 - 0:00 /usr/ccs/bin/shlap64
root 2097252 1 0 Jul 30 - 1:20 /usr/sbin/syncd 60
root 2162756 3211408 0 Jul 30 - 0:00 /usr/sbin/qdaemon
root 2556078 1 0 Jul 30 - 0:01 /opt/ibm/director/cimom/bin/tier1slp
root 2687168 1 0 Jul 30 - 0:25 [cimserve]
root 2752744 3211408 0 Jul 30 - 0:00 /opt/freeware/cimom/pegasus/bin/cimssys
platform_agent
root 2949134 3211408 0 Jul 30 - 0:00 /opt/freeware/cimom/pegasus/bin/cimssys
cimsys
root 3211408 1 0 Jul 30 - 0:00 /usr/sbin/srcmstr
root 3408036 3211408 0 Jul 30 - 0:00 /usr/sbin/sshd
root 3473482 1 0 Jul 30 - 1:14 /usr/bin/topasrec -L -s 300 -R 1 -r 6
-o /etc/perf/daily/ -ypersistent=1 -O
type=bi
root 3539136 1 0 Jul 30 - 0:06 bin/nonstop_aix @config/
nonstop.properties
root 3670254 3211408 0 Jul 30 - 3:53 /usr/sbin/rsct/bin/rmcd -a
IBM.LPCommands -r
root 3735688 1 0 Jul 30 - 0:35 /opt/ibm/icc/cimom/bin/dirsnmpd
daemon 3801316 3211408 0 Jul 30 - 0:00 /usr/sbin/rpc.statd -d 0 -t 50
root 3866638 3211408 0 Jul 30 - 0:00 /usr/sbin/rpc.lockd -d 0
root 3932310 3211408 0 Jul 30 - 0:04 /usr/sbin/snmpmibd
root 3997880 1 0 Jul 30 - 0:00 /usr/sbin/uprintfd
root 4063408 3211408 0 Jul 30 - 0:00 /usr/sbin/inetd
root 4128912 1 0 Jul 30 - 0:00 /opt/freeware/cimom/pegasus/bin
/CIM_diagd
root 4260046 3539136 0 Jul 30 - 7:33 /var/opt/tivoli/ep/_jvm/jre/bin/java
-Xmx384m -Xminf0.01 -Xmaxf0.4 -Dsun.rmi
.dgc.cli
root 4325546 1 0 Jul 30 - 2:36 ./slp_srvreg -D
root 4391132 3211408 0 Jul 30 - 0:00 /usr/sbin/writesrv
root 4456636 1 1 Jul 30 - 13:45 /usr/sbin/getty /dev/console
root 4522186 3211408 0 Jul 30 - 1:23 sendmail: accepting connections
root 4718632 3211408 0 Jul 30 - 0:50 /usr/sbin/aixmibd
root 4784288 3211408 0 Jul 30 - 6:03 /usr/sbin/syslogd
root 4849826 3211408 0 Jul 30 - 0:00 /usr/sbin/biod 6
root 4915382 3211408 0 Jul 30 - 0:05 /usr/sbin/hostmibd
root 4980920 3211408 0 Jul 30 - 0:05 /usr/sbin/portmap
root 5111980 1 0 Jul 30 - 0:00 /usr/dt/bin/dtlogin -daemon
root 5177510 1 0 Jul 30 - 0:07 /usr/sbin/cron
root 5243044 1 0 Jul 30 - 0:10 /usr/bin/cimlistener
root 5505206 3211408 0 Jul 30 - 0:00 /bin/ksh /pconsole/lwi/bin/
lwistart_src.sh
pconsole 5570756 5505206 0 Jul 30 - 0:00 /bin/ksh /pconsole/lwi/bin/
lwistart_src.sh
root 5701642 3211408 0 Jul 30 - 0:00 /usr/sbin/rsct/bin/IBM.ServiceRMd
root 6094978 7602204 11 09:16:46 pts/0 0:00 ps -ef
u0009539 6881324 7733258 0 08:09:42 pts/0 0:00 -ksh
root 7602204 6881324 0 08:09:45 pts/0 0:00 -ksh
u0009539 7733258 8126660 1 08:09:42 - 0:00 sshd: u0009539@pts/0
root 8126660 3408036 0 08:09:38 - 0:00 sshd: u0009539 [priv]
|
最常见的 ps 输出格式对于研究内存问题不太有用,但是有时候能让您回忆起在使用大量内存的系统上运行的一个进程。
但是,还有其他输出格式,其中最有用的是使用 BSD 风格的格式 u 或 v,它们显示每个进程的内存使用情况报告。下面的示例显示系统中每个活动进程的内存使用情况,并以恰当的方式排序。
清单 2. 每个活动进程的内存使用情况
.
# ps gv | head -n 1; ps gv | egrep -v "RSS" | sort +6b -7 -n -r
PID TTY STAT TIME PGIN SIZE RSS LIM TSIZ TRS %CPU %MEM COMMAND
...lines skipped for clarity
4980920 - A 0:05 14 972 1028 32768 41 56 0.0 0.0 /usr/sb
5111980 - A 0:00 12 620 772 32768 135 152 0.0 0.0 /usr/dt
5177510 - A 0:07 20 580 656 32768 58 76 0.0 0.0 /usr/sb
5243044 - A 0:10 1 7176 7232 32768 34 56 0.0 0.0 /usr/bi
5505206 - A 0:00 4 560 840 32768 241 280 0.0 0.0 /bin/ks
5570756 - A 0:00 5 564 844 32768 241 280 0.0 0.0 /bin/ks
5701642 - A 0:00 118 1772 1984 xx 258 212 0.0 0.0 /usr/sb
6881324 pts/0 A 0:00 0 556 836 32768 241 280 0.0 0.0 -ksh
7602204 pts/0 A 0:00 0 560 840 32768 241 280 0.0 0.0 -ksh
7667774 pts/0 A 0:00 0 720 828 32768 82 108 0.0 0.0 ps gv
7733258 - A 0:00 0 828 1052 32768 450 556 0.0 0.0 sshd: u
8126660 - A 0:00 0 704 928 32768 450 556 0.0 0.0 sshd: u
264 - A 1:20 0 448 448 xx 0 0 0.0 0.0 swapper
|
各个列提供关于内存使用情况的详细信息:
RSS — 每个进程用于文本和数据段的 RAM 量。PID 15256 使用 7232k 内存。这是此进程正在使用的真实内存。
%MEM — RSS 的实际量 / RAM 总量。应该进一步检查使用的内存百分比高的进程,但是应该记住数据库和 HPC 应用程序在正常情况下可以使用大量内存,可以不理会它们。在通用的系统上,任何进程都可能使用大量内存。
TRS — 用于进程文本段的 RAM 量(单位为 KB)。
SIZE — 为此进程(文本和数据)分配的分页空间的实际大小。
尽管这个命令提供一些有价值的信息,但是除非有可信的管理员已经诊断出系统中存在某种内存问题,否则我们通常不会首先使用这个命令。应该使用 vmstat 来确定瓶颈的原因,即使在尚未确定它是否与内存有关的时候。vmstat 报告内核线程、CPU 活动、虚拟内存、分页、阻塞的磁盘 I/O 以及相关信息(见 清单 3)。要了解系统的运行情况,这是最快捷且最直接的方法。
清单 3. 使用 vmstat 确定瓶颈的原因
# vmstat 1 4 System configuration: lcpu=4 mem=2048MB ent=0.25 kthr memory page faults cpu ----- ----------- ------------------------ ------------ ----------------------- r b avm fre re pi po fr sr cy in sy cs us sy id wa pc ec 0 0 419100 30643 0 0 0 0 0 0 36 241 271 0 7 93 0 0.03 13.7 0 0 419100 30643 0 0 0 0 0 0 44 40 250 0 7 93 0 0.03 12.5 0 0 419100 30643 0 0 0 0 0 0 22 155 242 0 7 93 0 0.03 12.2 0 0 419101 30642 0 0 0 0 0 0 60 62 259 0 8 92 0 0.03 13.5 |
我们先来说明这些列所表示的含义:
内存数据
avm — 正在使用的活动虚拟内存量(4k 页面的数量),不包括文件页面。
fre — 内存空闲列表的大小。在大多数情况下,当这个值变得很小时我们并不担心,因为 AIX 7 总是会充分地使用内存,不会像希望的那样尽早地释放内存。这个设置由 vmo 命令的 minfree 参数确定。归根结底,分页信息更加重要。
pi — 从分页空间换入的页面数。
po — 换出到分页空间的页面数。
fr — 空闲的(被替换的)页面数。
sr — 为了判断是否需要替换而扫描的页面数。
cy — 为了替换而扫描页面所用的时钟周期数。
CPU 和 I/O
r — 在指定的时间间隔内,可运行内核线程的平均数量。
b — 在指定的时间间隔内,位于虚拟内存等待队列中的内核线程的平均数量。如果 r 不大于 b,通常是 CPU 问题的现象,这可能是由于 I/O 或者内存瓶颈造成的。
us — 用户时间。
sy — 系统时间。
id — 空闲时间。
wa — 等待 I/O。
ec — 消耗容量的百分比,即,在运行共享处理器的系统上,您正使用的分配 CPU 时间多少的一个指标。
rc — 消耗的共享处理器资源的百分比。
对于工作负载分区 (WPAR),还应该监视特定 WPAR 的内存使用情况,从而了解是否需要重新配置 WPAR。可以使用 -@ 命令行参数并指定 WPAR 名称来查明这一信息。
让我们回到 vmstat 的输出,系统究竟出现了什么问题呢?首先是一条警告:请不要只根据 vmstat 的简单输出,向高级管理人员提交详细的分析和调优战略建议。必须做更多的工作,才能正确地诊断出系统的问题。当碰到生产性能问题并需要立即了解系统的运行状况时,应该使用 vmstat,以便可以警告其他人出现了什么问题,或者马上采取合适的措施(如果可行的话)。
在 vmstat 的输出中,要查看的主要内容是分页信息。如果有大量页面换出活动 (po),这常常说明真实内存不足,VMM 正在把分配的内存页面发送到磁盘上,以便为要换入的其他进程的页面让出空间。另外,要注意 I/O 统计数据,当发现阻塞的进程或者等待 I/O 的值 (wa) 很高时,这通常表示出现了实际的 I/O 问题,可能是正在等待文件访问,或者是与由于系统缺少内存而引起的分页相关的 I/O 问题。在这个示例中,看起来是后一种情况。我们碰到了 VMM 问题,这些问题可能导致了阻塞的进程和等待 I/O 的状况。通过优化内存参数,或者执行动态的 LPAR (DLPAR) 操作并在 LPAR 中添加更多 RAM,可以解决这个问题。
最后,如果使用动态的页面大小,还应该监视页面大小分配,以便更好地了解使用不同页面大小的情况。这有助于判断页面大小和配置是否正确。可以使用 vmstat -P ALL 获得此信息,见 清单 4。
清单 4. 获得页面大小统计信息
# vmstat -P ALL
System configuration: mem=2048MB
pgsz memory page
----- -------------------------- ------------------------------------
siz avm fre re pi po fr sr cy
4K 356160 266177 15406 0 0 0 0 0 0
64K 10508 9509 999 0 0 0 0 0 0
|
这里应用的规则与一般性统计数据一样,空闲页面少或页面换入/换出数量高都可能表明系统内存不足。
让我们进行更深入的研究。可以使用前面介绍过的 ps 命令尝试确定影响系统的进程。通常在这种情况下,我们会运行 sar 以检查该问题是否在使用另一种工具进行分析时依然存在。最好是使用多种工具以便提供进一步的帮助,从而确保诊断结果是正确的。
尽管与其他工具相比我们并不是很喜欢 sar(因为需要使用过多的标志,而且在诊断问题之前必须输入过多的命令),但是它允许实时地收集数据并查看以前捕捉的数据(使用 sadc)。大多数较早的工具只允许其中一种操作。差不多自从有了 UNIX,就有了 sar 命令,每个人都曾经使用过这个命令。使用 -r 标志可以提供一些 VMM 信息(见 清单 5)。
清单 5. 使用带 -r 标志的 sar 以获得 VMM 的信息
# sar -r 1 5 System Configuration: lcpu=4 mem=4096MB 06:18:05 slots cycle/s fault/s odio/s 06:18:06 1048052 0.00 387.25 0.00 06:18:07 1048052 0.00 112.97 0.00 06:18:08 1048052 0.00 45.00 79.21 06:18:09 1048052 0.00 216.00 0.00 06:18:10 1048052 0.00 8.00 0.00 Average 1048052 0 79 16 |
那么,这个结果究竟意味着什么呢?
slots — 提供分页空间中空闲页面的数量。
cycle/s — 报告每秒的页面置换周期数。
fault/s — 提供每秒的缺页次数。
odio/s — 提供每秒的非分页磁盘 I/O 次数。
在这个示例中,可以看到每秒有许多次缺页,但是其他值并不大。还可以看到,分页空间中有 1048052 个 4k 的页面可用,等于 4 GB。接下来,让我们再来深入地研究 AIX 7 特有的工具。
AIX 7 特有的内存监视
在本节中,我们概述 AIX 7 特有的工具:svmon、topas 和 nmon。其中的大多数工具都允许快速地进行故障排除,并捕捉用于历史趋势研究和分析的数据。
svmon 是一种分析实用工具。它专门针对 VMM。它提供许多信息,包括所使用的实际、虚拟和分页空间内存。-G 标志可以为主机中的内存使用情况提供全局视图(见 清单 6)
清单 6. 使用带 -G 标志的 svmon
# svmon -G
size inuse free pin virtual mmode memory
524288 492911 31377 329706 418311 Ded
pg space 196608 4137
work pers clnt other
pin 245850 0 0 83856
in use 418311 0 74600
PageSize PoolSize inuse pgsp pin virtual
s 4 KB - 340879 4137 195754 266279
m 64 KB - 9502 0 8372 9502
|
size 报告 RAM 的总量(4k 页面的数量),但是还显示不同页面大小的统计信息。inuse 报告进程所使用的 RAM 中的页面数量,还有属于已终止的进程但仍驻留在 RAM 中的持久页面数量。free 报告空闲列表中的页面数量。pin 报告物理内存 (RAM) 中固定的页面数量。固定的页面不能被换出。
paging space 报告分页空间的实际使用情况(4k 页面的数量)。重要的是,应该清楚这个结果与 vmstat 所报告的结果之间的差异。vmstat 中的 avm 列显示访问的所有虚拟内存,即使它没有被换出。我们还喜欢查看工作和持久页面数量。这些参数显示 RAM 中工作和持久页面的数量。
这些内容为什么非常重要呢?也许您还记得,我们在 第 1 部分 中曾介绍了工作和持久页面之间的区别。当进程对计算信息进行处理时,将使用计算内存。它们使用工作段,而这些工作段是临时的(暂时的),当进程终止或者页面被偷取时,这些工作段将不复存在。文件内存使用持久段,在磁盘上具有持久的存储位置。数据文件或可执行程序通常都映射到持久段,而不是工作段。在可以选择的情况下,更希望将文件内存换出到磁盘,而不是换出计算内存。在这个示例中,与文件内存相比,计算内存更有可能被换出。对 vmo 参数稍做优化也许就可以极大地提高系统的性能。svmon 的另一个有用特性是,可以显示给定进程的内存统计信息。清单 7 提供了一个示例。
清单 7. 使用 svmon 显示给定进程的内存统计信息
#svmon -P 8126660
-------------------------------------------------------------------------------
Pid Command Inuse Pin Pgsp Virtual 64-bit Mthrd 16MB
8126660 sshd 25818 11972 0 25677 N N N
PageSize Inuse Pin Pgsp Virtual
s 4 KB 234 4 0 93
m 64 KB 1599 748 0 1599
Vsid Esid Type Description PSize Inuse Pin Pgsp Virtual
9000 d work shared library text m 809 0 0 809
4002 0 work fork tree m 790 748 0 790
children=964bd8, 0
804702 1 clnt code,/dev/hd2:214195 s 139 0 - -
8116a9 2 work process private sm 62 4 0 62
parent=8075e2
81f4ae f work shared library data sm 31 0 0 31
parent=823610
83e05f - clnt /dev/hd2:111000 s 2 0 - -
81f54e 3 mmap maps 2 source(s) sm 0 0 -
|
还可以使用 ps -Z 选项查看不同进程使用的页面大小,见 清单 8。
清单 8. 查看各个进程的页面大小
# ps -eZ
PID TTY TIME DPGSZ SPGSZ TPGSZ SHMPGSZ CMD
1 - 0:01 4K 4K 4K 4K init
1442014 - 0:00 4K 4K 4K 4K snmpdv3ne
1638422 - 0:00 4K 4K 4K 4K IBM.DRMd
1769544 - 1:53 4K 4K 4K 4K java
...
|
其中的各个列显示每个进程的数据、堆栈和文本页面大小。可以根据这些信息判断需要进一步研究哪些进程,从而了解它们的页面大小和分配。
根据清单 7,可以确定此进程并没有使用分页空间(Pgsp 列),还可以看出它同时使用 4KB 和 64KB 页面大小。详细的信息显示此应用程序的哪些部分正在使用什么类型的内存页面,PSize 列显示使用的是小页面 (4KB) 还是中等页面 (64KB)。在这个示例中,很难看出在 shell 服务器中有什么地方可以改进;但是,检查另一个进程(比如 DB2 或 Oracle)可能更有意义。使用前面介绍过的 ps 命令,再加上 svmon,就可以找出大量消耗内存资源的位置。
我们来使用一种对用户来说更加友好的工具 — topas。topas 是一种非常优秀的小型性能监视工具,它可以用于许多目的(见 图 1)。
图 1. topas 工具

运行 topas 将提供进程信息、CPU、I/O 和 VMM 活动的列表。从这个视图中可以看到,此系统仅使用了很少的分页空间。我们喜欢使用这个命令快速地进行故障排除,特别是当希望在屏幕上显示比 vmstat 更丰富的信息时。我们将 topas 看作 vmstat 的图形化版本。经过最近的改进,现在它可以捕捉数据以进行历史分析。
在所有性能工具中,我们最喜欢的实际上是一种不受支持的 IBM 工具 nmon。它在某些方面与 topas 类似,通过 nmon 收集到的数据可以显示在屏幕上(类似于 topas),也可以通过报告提供它们(可以捕捉相关的信息以进行趋势研究和分析)。这个工具提供了其他工具所没有的一些功能,它可以在 Microsoft® Excel 电子表格中显示美观的图表,可以将图表交给高级管理人员或者其他技术团队进行更深入地分析。可以使用另一种不受支持的工具 nmon analyzer 进行分析,它为 nmon 提供了挂钩。图 2 给出 nmon 分析的输出示例。
图 2. nmon 分析输出
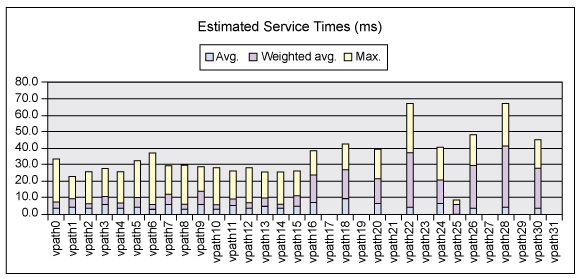
在使用这个工具的过程中,可以看到许多不同类型的 nmon 视图,这些视图可以提供各种 CPU、I/O 和内存使用情况信息。
结束语
在本文中,您了解了可用于捕捉数据以进行 AIX 7 内存分析的各种工具。还学习了如何对确实存在与虚拟内存有关的性能问题的系统进行故障排除。调优工作本身实际上只是调优方法中的一小部分,这一点重申多少次都不为过。如果不捕捉数据并仔细地、正确地分析系统,那么所做的工作就好像是一名医生根本不对患者进行检查就胡乱地使用抗生素。
可以使用许多不同类型的性能监视工具。有些工具可以从命令行运行,以便快速地检查系统的运行情况。有些工具更适合于进行长期的趋势研究和分析。有些工具甚至可以提供图形格式的数据,可以将这些数据交给非技术人员。无论使用哪种工具,都必须仔细地了解信息的真正含义。不要只根据少量的数据样本急于得出结论。另外,不要仅依赖于某一种工具。为了证实结论,在进行分析时,应该使用至少两种工具。我们还简要地介绍了调优方法和建立系统正常运行时的基准数据的重要性。在检查数据并实施调优之后,必须继续捕捉数据并分析所做更改的结果。另外,应该一次只进行一项更改,这样才能真正地确定每项更改的效果。