利用java爬取网页数据的方法与思路,以爬取“食品许可公示的数据”为例
- 项目背景
先说下背景,前几天老哥让帮忙从网上抓点数据,因为他是做食品添加剂的推广工作的,所以需要知道有哪些工厂或者厂家可能需要食品添加剂,然后他给了我一个网址----湖北省食品药品行政许可公示平台。既然是公示平台,数据应该就是公开的,爬起来应该不会被查水表吧,看这个警徽还是怕怕的 .......>_>
如下:
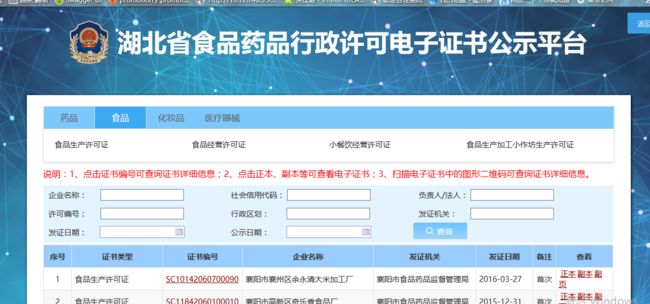
抓取的数据类似图上列表中的数据,但是他说还要厂家地址和食品类型,能有其他数据更好。
然后我研究了下,发现图上页面是没有厂家地址的(但是我这个页面也抓了,服务器返回的是json格式的数据,解析下json数据存入数据库就行,这个公示平台貌似是近几个月才出的),也不够详细,在其他页面有带厂家地址的数据,给服务器发送请求返回的是html的数据,解析html数据,将所需数据存入数据库。
带地址的网页长这样:
(URL:http://******websearch/SearchCardAction.do?operate=searchGyEntCard&operPage=card_spscxkz_list&cardtype=103):

点击每个生产者名称都会跳出一个弹窗,该弹窗显示的是食品许可证的详细数据(后台服务器实际应该是以该公司在数据库中的uuid为条件,去详细查了下该生产许可证的信息,然后返回给了前端):
(URL:http://******/websearch/SearchCardAction.do?operate=viewGyEntCard&operPage=card_spscxkz_view&recid=2c9080845707bcc30159a66100300bd3)

ok,现在目标很明确,就是从带厂家地址的网页上把所有公司的uuid拿到,然后以每个uuid作为URL变化的条件(“recid=”后面是变化的,拼接URL的时候将uuid拼在具体的链接上来访问服务器),从弹窗的那个页面拿到详细的数据,存入数据库。
- 项目环境
ide:intellij IDEA 2017.2.5
编程语言:java
数据库:mysql
管理工具:maven
需要导包:mysql-connector-java,jsoup(解析html)等,如果要解析json可能还要导入gson的包。
我把重要的依赖贴出来(默认大家都是使用过maven的,如果不使用maven,你可以到网上下载jar包添加到项目里):
-
<dependency>
-
<groupId>com.google.code.gson
groupId>
-
<artifactId>gson
artifactId>
-
<version>2.8.0
version>
-
dependency>
-
<dependency>
-
<groupId>mysql
groupId>
-
<artifactId>mysql-connector-java
artifactId>
-
<version>5.1.38
version>
-
dependency>
-
<dependency>
-
<groupId>org.jsoup
groupId>
-
<artifactId>jsoup
artifactId>
-
<version>1.9.2
version>
-
dependency>
- 项目详情
思路上面说的差不多了,要补充的是,我们使用HttpURLConnection来连接服务器(httpclient等开源项目或者工具应该也行),对于POST请求和GET请求稍微有些区别,这个网上也比较多,大家可以自行百度或者Google。然后是代码,我把主要部分都贴出来,可能代码会有些不规范的地方,大家也可以指出,项目结构比较简单,代码也不长,直接主函数里面就执行完了所有的内容,新人拿来练手也不错。
项目整体的结构:

1.主类部分
-
package main; /**
-
* @Author tang_zhen
-
* @Date 2018/3/7
-
* @Description
-
*/
-
import model.DataBase;
-
import com.google.gson.JsonObject;
-
import service.dao.DBUtils;
-
import service.MyParse;
-
-
import java.io.*;
-
import java.net.HttpURLConnection;
-
import java.net.URL;
-
import java.sql.Connection;
-
import java.sql.PreparedStatement;
-
import java.sql.ResultSet;
-
import java.sql.SQLException;
-
import java.util.List;
-
-
public class GetData {
-
/**
-
* 发起http请求并获取结果
-
* @param requestUrl 请求地址
-
*/
-
public static String getRequest(String requestUrl){
-
String res="";
-
// JsonObject object = null;
-
StringBuffer buffer = new StringBuffer();
-
try{
-
URL url = new URL(requestUrl);
-
//打开连接
-
HttpURLConnection urlCon= (HttpURLConnection)url.openConnection();
-
if(200==urlCon.getResponseCode()){//连接正常,获取输入流
-
InputStream is = urlCon.getInputStream();
-
InputStreamReader isr = new InputStreamReader(is,"GBK");
-
BufferedReader br = new BufferedReader(isr);
-
-
String str = null;
-
while((str = br.readLine())!=null){
-
buffer.append(str);
-
}
-
//关闭流
-
br.close();
-
isr.close();
-
is.close();
-
res = buffer.toString();
-
//如果是json数据可以这样解析然后返回JsonObject类型的对象
-
// JsonParser parse =new JsonParser();
-
// JsonObject res2 = (JsonObject)parse.parse(buffer.toString());
-
}
-
}catch(IOException e){
-
e.printStackTrace();
-
}
-
return res;
-
}
-
-
public static String postDownloadRes(String path,String post){
-
URL url = null;
-
try {
-
url = new URL(path);
-
HttpURLConnection httpURLConnection = (HttpURLConnection) url.openConnection();
-
httpURLConnection.setRequestMethod("POST");// Post请求
-
// conn.setConnectTimeout(10000);//连接超时 单位毫秒
-
// conn.setReadTimeout(2000);//读取超时 单位毫秒
-
// POST需设置如下两行
-
httpURLConnection.setDoOutput(true);
-
httpURLConnection.setDoInput(true);
-
// 获取URLConnection对象对应的输出流
-
PrintWriter printWriter = new PrintWriter(httpURLConnection.getOutputStream());
-
// 发送请求参数(post请求的参数一般可以从浏览器里查请求的时候看到参数是哪些)
-
printWriter.write(post);//post的参数 形式为xx=xx&yy=yy
-
-
// flush输出流的缓冲
-
printWriter.flush();
-
//开始获取数据
-
BufferedInputStream bis = new BufferedInputStream(httpURLConnection.getInputStream());
-
ByteArrayOutputStream bos = new ByteArrayOutputStream();
-
int len;
-
byte[] arr = new byte[1024];
-
while((len=bis.read(arr))!= -1){
-
bos.write(arr,0,len);
-
bos.flush();
-
}
-
bos.close();
-
//如果是json数据可以这样解析然后返回JsonObject类型的对象
-
// JsonParser parse =new JsonParser();
-
// JsonObject res2 = (JsonObject)parse.parse(bos.toString("utf-8"));
-
return bos.toString("utf-8");
-
} catch (Exception e) {
-
e.printStackTrace();
-
}
-
return null;
-
}
-
-
//测试
-
public static void main(String args [] ) {
-
// JsonObject res = null;
-
String responseStr = null;
-
JsonObject res2 = null;
-
// for (int k=1;k
<=631;k++) {
-
// //获取某一页的数据可以根据“nextPageNo=*”来指定,就是字符串拼接下,把1换成n
-
String str = "gyEntcardprint.cardid=&gyEntcardprint.name=&pageModel.nextPageNo="+1+"&pageModel.pageSize=12&cardtype=103";
-
responseStr = postDownloadRes("wssb/websearch/SearchCardAction.do?operate=searchGyEntCard&operPage=card_spscxkz_list&cardtype=103&pageModel.afreshQuery=true", str);
-
//System.out.println(responseStr);
-
try {
-
//第一个页面中拿到的是一个列表,是一页的数据
-
List<DataBase> list = MyParse.getData(responseStr);
-
for (DataBase dataBase : list) {
-
String str1 = "wssb/websearch/SearchCardAction.do?operate=viewGyEntCard&operPage=card_spscxkz_view&recid="+dataBase.getId();
-
String responseStr1 = getRequest(str1);
-
System.out.println(responseStr1);
-
MyParse.getTotalData(responseStr1,dataBase.getId());
-
//存id和公司名到第一张表里
-
// insert(dataBase);
-
}
-
} catch (Exception e) {
-
e.printStackTrace();
-
}
-
//这部分注释的是json解析的部分,之前访问过的网址返回的是json数据(嵌套了有多层)
-
// JsonArray member = responseStr.getAsJsonArray("zsList");
-
// for (int i = 0; i
< member.size(); i++) {
-
// JsonElement elements = member.get(i);
-
// JsonElement name = elements.getAsJsonObject().get("name");
-
// JsonElement id = elements.getAsJsonObject().get("id");
-
// DataBase db = new DataBase(id.toString(), name.toString());
-
// System.out.println(name);
-
// System.out.println(id);
-
// insert(db);
-
// }
-
// }
-
-
}
-
}
-
主函数部分就是打开连接,模拟浏览器与服务器交互,接收从服务器返回的数据,再调用MyParse类中的getData等从数据中拿到想要的数据:
2.解析部分:
-
import model.DataBase;
-
import org.jsoup.Jsoup;
-
import org.jsoup.nodes.Document;
-
import org.jsoup.nodes.Element;
-
import org.jsoup.select.Elements;
-
import service.dao.DBUtils;
-
-
import java.util.ArrayList;
-
import java.util.List;
-
-
/**
-
* @Author tang_zhen
-
* @Date 2018/3/8
-
* @Description
-
*/
-
public class MyParse {
-
/**
-
* 获取每个公司的id和姓名
-
* @param html
-
* @return
-
* @throws Exception
-
*/
-
public static List
<DataBase> getData(String html) throws Exception {
-
//获取的数据,存放在集合中
-
List
<DataBase> data = new ArrayList
<DataBase>();
-
//System.out.println(html.length()+"HTML长度");
-
//System.out.println(html);
-
//采用Jsoup解析
-
Document doc = Jsoup.parse(html);
-
//System.out.println(doc.text() + "doc内容");
-
//获取html标签中的内容
-
Elements elements = doc.select("tr[class=Items]");
-
System.out.println(elements.size() + "****条");
-
for (Element element:elements)
-
{
-
Element link = element.select("a").first();
-
String text = element.select("a").get(1).text();
-
-
String linkHref = link.attr("href");
-
String[] newLinkHrefArray = linkHref.split("\'");
-
String newLinkHref =newLinkHrefArray[1];
-
-
// System.out.println(newLinkHref+"------"+text);
-
DataBase dataBase = new DataBase();
-
dataBase.setId(newLinkHref);
-
dataBase.setName(text);
-
data.add(dataBase);
-
// insert(dataBase);
-
}
-
return data;
-
}
-
-
/**
-
* 根据id获取弹窗上详细的数据
-
* @param html
-
* @param id
-
*/
-
public static void getTotalData(String html,String id) {
-
List
<DataBase> data = new ArrayList
<DataBase>();
-
//System.out.println(html.length()+"HTML长度");
-
//采用Jsoup解析
-
Document doc = Jsoup.parse(html);
-
//System.out.println(doc.text() + "doc内容");
-
//获取html标签中的内容
-
Elements elements = doc.select("tr");
-
// System.out.println(elements.size() + "****条");
-
DataBase dataBase=new DataBase();
-
for (Element element:elements)
-
{ //jsoup的具体解析你们可以百度一下,根据内容不一样,获取的方式也不太一样,我这个内容算是比较简单的了,
-
// 复杂的html内容获取某个数据,一行可能都写不下
-
if(element.select("td").first().text().equals("生产者名称"))
-
{
-
String name = element.select("td").get(1).text();
-
if (name==null) name="";
-
dataBase.setName(name);
-
}
-
if(element.select("td").first().text().equals("住所"))
-
{
-
String homeAddress = element.select("td").get(1).text();
-
if(homeAddress==null) homeAddress="";
-
dataBase.setHomeAddress(homeAddress);
-
}
-
if(element.select("td").first().text().equals("生产地址"))
-
{
-
String address = element.select("td").get(1).text();
-
if (address==null) address="";
-
dataBase.setAddress(address);
-
}
-
-
if(element.select("td").first().text().equals("食品类别"))
-
{
-
String foodType = element.select("td").get(1).text();
-
if(foodType==null) foodType="";
-
dataBase.setFoodType(foodType);
-
}
-
if(element.select("td").first().text().equals("发证日期"))
-
{
-
String dateOfIssue = element.select("td").get(1).text();
-
if (dateOfIssue==null) dateOfIssue="";
-
dataBase.setDateOfIssue(dateOfIssue);
-
//截止日期
-
String cutOffDate = element.select("td").get(3).text();
-
if(cutOffDate==null) cutOffDate="";
-
dataBase.setCutOffData(cutOffDate);
-
}
-
dataBase.setId(id);
-
}
-
//将bean中的数据存入数据库
-
DBUtils.insert(dataBase);
-
}
-
}
3.数据库部分
主要是jdbc的内容,大家应该也都会:
最后是效果:

上图是打印出来的服务器返回的html,下图是存入数据库的数据截图:

另外,我觉得有必要贴一下返回的html的部分内容,这样如果想知道如何利用jsoup解析html的可以对照着html的结构看下我的代码是如何解析的:
-
<table width="99%" border="0" cellpadding="0" cellspacing="1" id="wrap_1" align="center">
-
<tr>
-
<td class="td_content">
-
<table width="100%" border="0" cellpadding="0" cellspacing="1" id="content">
-
<tr>
-
<td width="15%" class="bai_right">证书名称
td>
-
<td class="bai_left" colspan="3">
<input type="hidden" name="cardtype" value="" id="cardnametype">
-
食品生产许可证
-
td>
-
tr>
-
<tr>
-
<td width="15%" class="bai_right">证书编号
td>
-
<td class="bai_left" colspan="3" >QS4203 2401 0460
td>
-
tr>
-
<tr>
-
<td width="15%" class="bai_right">生产者名称
td>
-
<td class="bai_left" colspan="3">
房县味味食品有限公司
td>
-
tr>
-
<tr>
-
<td width="15%" class="bai_right">社会信用代码
td>
-
<td width="35%" class="bai_left" >X1631412-7
td>
-
<td width="15%" class="bai_right">法定代表人
td>
-
<td width="35%" class="bai_left" >林益华
td>
-
tr>
-
<tr>
-
<td width="15%" class="bai_right">住所
td>
-
<td class="bai_left" colspan="3">
湖北省十堰市房县红塔镇西城工业园高碑村四组
td>
-
tr>
-
<tr>
-
<td width="15%" class="bai_right">生产地址
td>
-
<td class="bai_left" colspan="3">湖北省十堰市房县红塔镇西城工业园高碑村四组
td>
-
tr>
-
<tr>
-
<td width="15%" class="bai_right">食品类别
td>
-
<td class="bai_left" colspan="3">
td>
-
tr>
-
<tr>
-
<td width="15%" class="bai_right">日常监督管理机构
td>
-
<td width="35%" class="bai_left">
td>
-
<td width="15%" class="bai_right">日常监督管理人员
td>
-
<td width="35%" class="bai_left">
td>
-
tr>
-
<tr>
-
<td width="15%" class="bai_right">签发人
td>
-
<td width="35%" class="bai_left">
td>
-
<td width="15%" class="bai_right">发证机关
td>
-
<td width="35%" class="bai_left">
td>
-
tr>
-
<tr>
-
<td width="15%" class="bai_right">发证日期
td>
-
<td width="35%" class="bai_left">2012-08-08
td>
-
<td width="15%" class="bai_right">截止日期
td>
-
<td width="35%" class="bai_left">2018-07-30
td>
-
tr>
-
table>
- 项目总结
其实整个项目就是个小程序,小爬虫,总体来说技术不算难,结构也很简单,大部分用到的技术和知识网上也挺多的,不管咋说,作为一个菜鸟程序猿,毕竟还是用自己所学的技术解决掉了一个比较现实的问题吧。然后就是,我发现代码跑起来是真的慢啊!爬一页数据,大概要两秒多?我猜问题主要是出在了数据库那,因为我是用完一个连接就直接关闭了,早知道慢成这样就用个数据库的连接池了.....
PS:代码里面的URL都不是完整的,如果你们要实验,还是换个网站吧,这个毕竟是政府网站,虽然数据也是公开的数据,但是连接太多对服务器是有压力的,崩了就不好了,万一被查水表呢。还有就是有的网站可能会拒绝连接,有的防止类似的爬虫爬取页面的时候会做一些措施,多次连接IP会被拉黑。有啥问题直接留言,第一次写博客,大家多多包涵,之前都是在有道云笔记里记东西。