MySQL高可用架构之MHA
实验前提
此实验要基于gtid主从复制,并且是一主多从。可查看基于gtid的主从复制
| 主机名 | ip | 设置 |
|---|---|---|
| server1 | 172.25.55.1 | 主库 |
| server2 | 172.25.55.2 | 从库1 |
| server3 | 172.25.55.3 | 从库2 |
| server4 | 172.25.55.4 | MHA Manger |
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
一、server1配置
[root@server1 ~]# vim /etc/my.cnf
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
log_bin=binlog
[root@server1 ~]# systemctl restart mysqld
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (0.18 sec)
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
Query OK, 0 rows affected (0.09 sec)
mysql> set global rpl_semi_sync_master_enabled=1;
Query OK, 0 rows affected (0.01 sec)
mysql> set global rpl_semi_sync_master_timeout=1000000000000;
Query OK, 0 rows affected (0.00 sec)

[root@server1 ~]# yum install mha4mysql-node-0.58-0.el7.centos.noarch.rpm -y
二、server2配置
[root@server2 ~]# vim /etc/my.cnf
server_id=2
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
log_bin=binlog
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (0.12 sec)
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
Query OK, 0 rows affected (0.09 sec)
mysql> set global rpl_semi_sync_slave_enabled=1;
Query OK, 0 rows affected (0.00 sec)
mysql> set global rpl_semi_sync_master_timeout=1000000000000;
Query OK, 0 rows affected (0.00 sec)

[root@server2 ~]# yum install mha4mysql-node-0.58-0.el7.centos.noarch.rpm -y
三、server3配置
[root@server3 ~]# vim /etc/my.cnf
server_id=3
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
log_bin=binlog
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
Query OK, 0 rows affected (0.15 sec)
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
Query OK, 0 rows affected (0.11 sec)
mysql> set global rpl_semi_sync_slave_enabled=1;
Query OK, 0 rows affected (0.00 sec)
mysql> set global rpl_semi_sync_master_timeout=1000000000000;
Query OK, 0 rows affected (0.00 sec)

[root@server1 ~]# yum install mha4mysql-node-0.58-0.el7.centos.noarch.rpm -y
四、server4配置
[root@server4 ~]# ls
mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
mha4mysql-manager-0.58.tar.gz
mha4mysql-node-0.58-0.el7.centos.noarch.rpm
perl-Config-Tiny-2.14-7.el7.noarch.rpm
perl-Email-Date-Format-1.002-15.el7.noarch.rpm
perl-Log-Dispatch-2.41-1.el7.1.noarch.rpm
perl-Mail-Sender-0.8.23-1.el7.noarch.rpm
perl-Mail-Sendmail-0.79-21.el7.noarch.rpm
perl-MIME-Lite-3.030-1.el7.noarch.rpm
perl-MIME-Types-1.38-2.el7.noarch.rpm
perl-Parallel-ForkManager-1.18-2.el7.noarch.rpm
[root@server4 ~]# yum install *.rpm -y
[root@server4 ~]# mkdir /etc/masterha
[root@server4 ~]# vim /etc/masterha/app1.cnf
[server default]
manager_workdir=/etc/masterha //设置manager的工作目录
manager_log=/var/log/masterha.log //设置manager的日志
master_binlog_dir=/var/log/mysql //设置master 保存binlog的位置,以便MHA可以找到master的日志,我这里的也就是mysql的数据目录
#master_ip_failover_script=/usr/local/bin/master_ip_failover //设置自动failover时候的切换脚本
#master_ip_online_change_script=/usr/local/bin/master_ip_online_change //设置手动切换时候的切换脚本
password=Redhat_123 //设置mysql中root用户的密码,这个密码是前文中创建监控用户的那个密码
user=root
ping_interval=1 //设置监控主库,发送ping包的时间间隔,默认是3秒,尝试三次没有回应的时候自动进行railover
remote_workdir=/tmp //设置远端mysql在发生切换时binlog的保存位置
repl_password=Redhat_123 //设置复制用户的密码
repl_user=rep //设置复制环境中的复制用户名
#report_script=/usr/local/send_report //设置发生切换后发送的报警的脚本
#secondary_check_script=/usr/local/bin/masterha_secondary_check -s server03 -s server02
#shutdown_script="" //设置故障发生后关闭故障主机脚本(该脚本的主要作用是关闭主机放在发生脑裂,这里没有使用)
ssh_user=root //设置ssh的登录用户名
[server1]
hostname=172.25.55.1
port=3306
[server2]
hostname=172.25.55.2
port=3306
candidate_master=1 //设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
check_repl_delay=0 //默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
[server3]
hostname=172.25.55.3
port=3306
上面文件的模版在这里:
[root@server4 ~]# tar zxf mha4mysql-manager-0.58.tar.gz
[root@server4 ~]# cd mha4mysql-manager-0.58

[root@server4 samples]# masterha_check_ssh --conf=/etc/masterha/app1.cnf

让主从库的三台虚拟机和代理虚拟机,四台虚拟机达到免密访问。
[root@server4 samples]# ssh-keygen
[root@server4 ~]# ssh-copy-id 172.25.55.1:(用生成的钥匙加密)
[root@server4 ~]# ssh-copy-id 172.25.55.2:
[root@server4 ~]# ssh-copy-id 172.25.55.3:
主从免密检测
[root@server4 ~]# scp -r .ssh/ 172.25.55.1:(将生成的密码发送给每个)
[root@server4 ~]# scp -r .ssh/ 172.25.55.2:
[root@server4 ~]# scp -r .ssh/ 172.25.55.3:
[root@server4 samples]# masterha_check_ssh --conf=/etc/masterha/app1.cnf
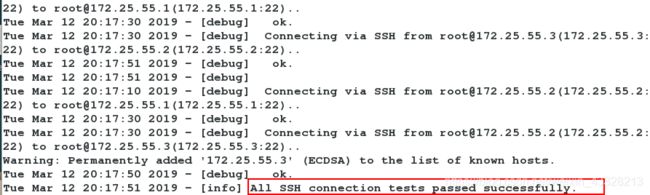
server1主库授权
mysql> grant all on *.* to root@'%' identified by 'Redhat_123';
Query OK, 0 rows affected, 1 warning (0.10 sec)
server2/server3
mysql> set GLOBAL read_only=1;
Query OK, 0 rows affected (0.00 sec)
[root@server4 conf]# masterha_check_repl --conf=/etc/masterha/app1.cnf

测试
故障切换(手动切换)
[root@server1 ~]# systemctl stop mysqld
[root@server4 conf]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=172.25.55.1 --dead_master_port=3306 --new_master_host=172.25.55.2 --new_master_port=3306

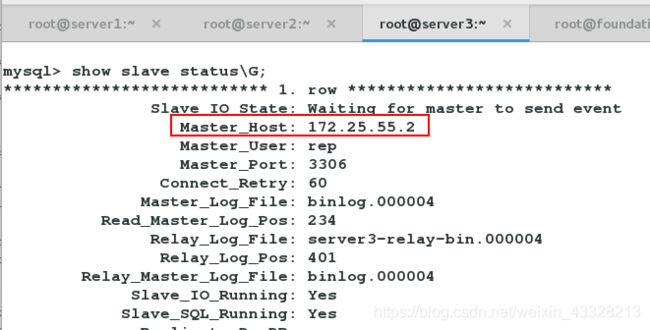
热切
为自动切换的效果,我们将server1打开,并设置为server2的从库。
mysql> CHANGE MASTER TO MASTER_HOST='172.25.55.2', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rep', MASTER_PASSWORD='Redhat_123';
Query OK, 0 rows affected, 2 warnings (0.34 sec)
mysql> start slave;
Query OK, 0 rows affected (0.07 sec)
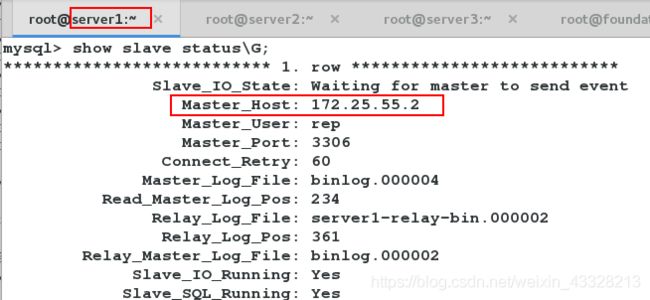

[root@server4 masterha]# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.25.55.1 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000


此时,server2的数据库会自动变为server1的从库。
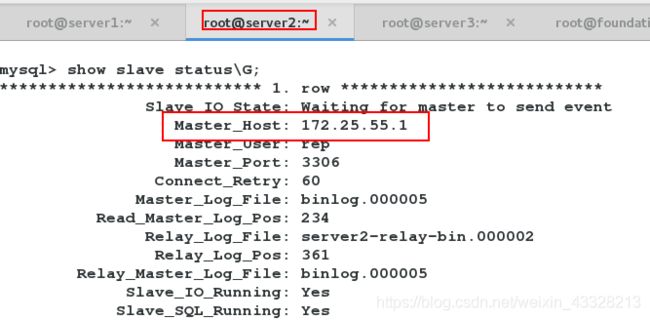
自动切换
[root@server4 masterha]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &> /dev/null &
[root@server1 ~]# systemctl stop mysqld(关闭主库)
查看此时的状态,主库已经变成172.25.55.2的数据库。
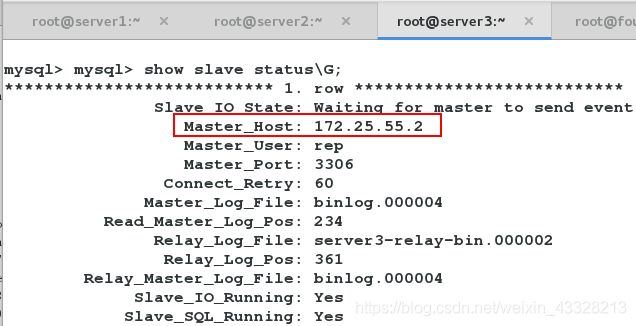
虚拟ip
[root@server4 bin]# vim /etc/masterha/app1.cnf
取消五六行注释
master_ip_failover_script=/usr/local/bin/master_ip_failover
master_ip_online_change_script=/usr/local/bin/master_ip_online_change
[root@server4 bin]# cd /usr/local/bin/
[root@server4 bin]# vim master_ip_failover
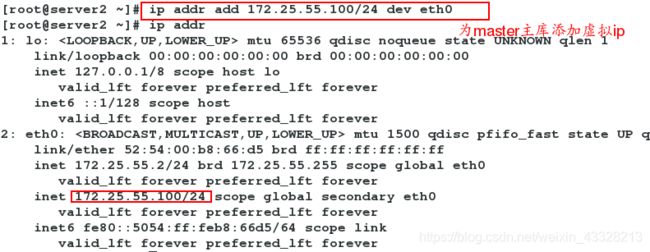
12 my $vip= '172.25.55.100/24';
13 my $ssh_start_vip="/sbin/ip addr add $vip dev eth0";
14 my $ssh_stop_vip ="/sbin/ip addr del $vip dev eth0";
[root@server4 bin]# vim master_ip_online_change
7 my $vip = '172.25.55.100/24'; # Virtual IP
8
9 my $ssh_start_vip="/sbin/ip addr add $vip dev eth0";
10 my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0";
将server1打开,添加为server2的slave。
mysql> CHANGE MASTER TO MASTER_HOST='172.25.55.2', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='rep', MASTER_PASSWORD='Redhat_123';
mysql> start slave;
Query OK, 0 rows affected (0.08 sec)
查看server1的slave状态。
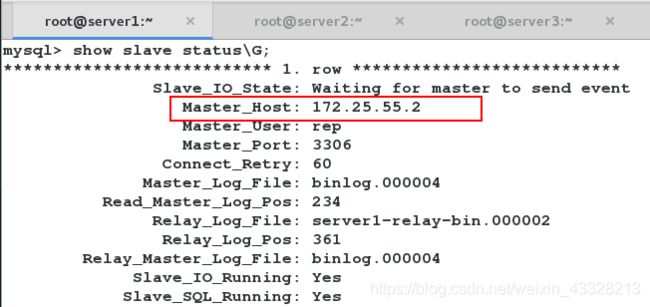
为master主库172.25.55.2添加虚拟ip 。
热切到172.25.55.1虚拟机上
[root@server4 bin]# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.25.55.1 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000

此时,主库是172.25.55.1.
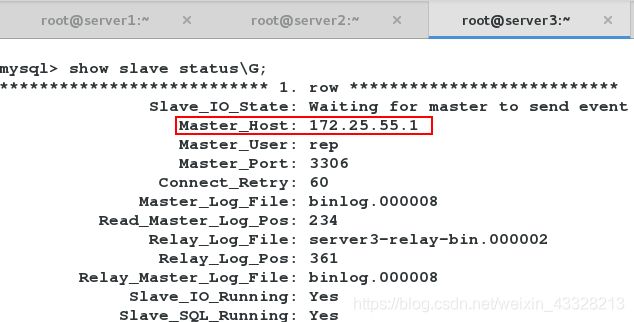
虚拟ip漂到172.25.55.1

自动切换
[root@server4 bin]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &> /dev/null &
关闭server1的mysql。
此时,查看server3的slave状态,显示目前的master已经变172.25.55.2。

查看server2的ip,此时虚拟ip已经漂移过来。

通过虚拟ip ,客户端只需要访问虚拟ip就一直访问的是主库,不需要管数据库之间的切换。