一个简单的爬取查询数据的springboot项目
一、项目建模

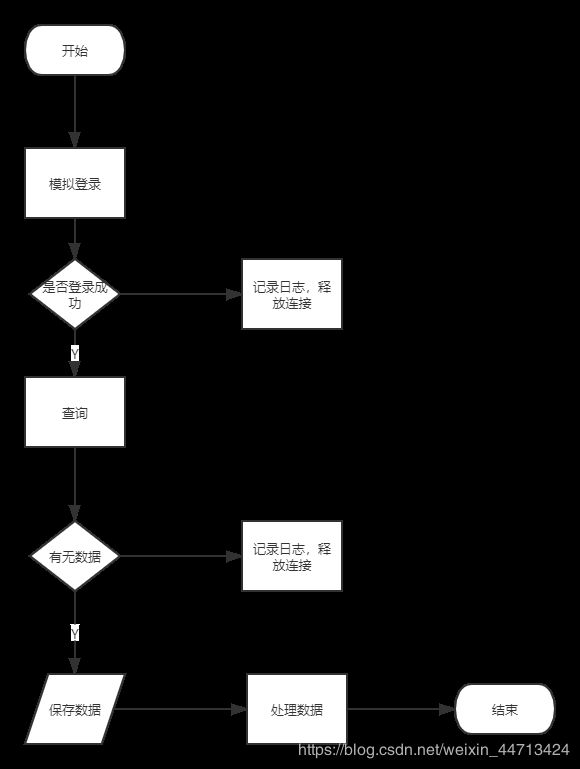
二、执行流程
单个实例执行流程:
从PoolingHttpClientConnectionManager连接池中得到CloseableHttpClient 的一个客户端实例来访问目标网址,首先模拟登录,登录成功后保存状态,发送进销存查询请求,通过页面抓取或发送导出文件请求的方式来获取数据,紧接着处理数据,将数据按照自定义模板生成。
三、最终效果
Windows10自带的录屏 win+G打开xbox的录屏,设置一下对所有应用捕获,然后在线转换gif 免费直接下载超好用
四、项目细节
1.HttpClient
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</dependency>
这部分都是参考HttpClient整理资料和HttpClient高级进阶,自己去细看理解。
HttpClient执行Http请求的步骤:
- 创建HttpClient
- 创建Request
- 使用HttpClient来执行Request请求,得到相应的Response
- 处理Response
- 关闭HttpClient
(1)、创建HttpClient
目前最新版的HttpClient的实现类为CloseableHttpClient。创建CloseableHttpClient实例有两种方式:
(1)使用CloseableHttpClient的工厂类HttpClients的方法来创建实例。最简单的实例化方式是调用HttpClients.createDefault()。
//使用自定义配置
public static HttpClientBuilder custom() {
return HttpClientBuilder.create();
}
//使用默认配置
public static CloseableHttpClient createDefault() {
return HttpClientBuilder.create().build();
}
//使用一个预设策略的系统HttpClient对象
public static CloseableHttpClient createSystem() {
return HttpClientBuilder.create().useSystemProperties().build();
}
/**
* if (this.systemProperties) {
* String s = System.getProperty("http.keepAlive", "true");
* if ("true".equalsIgnoreCase(s)) {
* s = System.getProperty("http.maxConnections", "5");
* int max = Integer.parseInt(s);
* poolingmgr.setDefaultMaxPerRoute(max);
* poolingmgr.setMaxTotal(2 * max);
* }
* }
*/
//使用极简HttpClient对象,只是封装了最基本的HTTP过程,提供最直接的客户端服务器交互,不支持代理,不支持在各种情况下的重试(重定向,权限校验,IO异常等)
public static CloseableHttpClient createMinimal() {
return new MinimalHttpClient(new PoolingHttpClientConnectionManager());
}
//自定义HttpClientConnectionManager的极简HttpClient对象
public static CloseableHttpClient createMinimal(HttpClientConnectionManager connManager) {
return new MinimalHttpClient(connManager);
}
更多相关: 关于MinimalHttpClient
HttpClient4.5基础
(2)使用CloseableHttpClient的builder类HttpClientBuilder,先对一些属性进行配置(采用装饰者模式,不断的.setxxxxx().setxxxxxxxx()就行了)(这里所说的装饰者模式,我觉得不对,参考装饰者模式或装饰者模式2,装饰者模式更多地应用在拓展子类行为上),再调用build方法来创建实例。上面的HttpClients.createDefault()实际上调用的也就是HttpClientBuilder.create().build()。
build()方法最终是根据各种配置来new一个InternalHttpClient实例(CloseableHttpClient实现类)。IternalHttpClient的定义如下:
class InternalHttpClient extends CloseableHttpClient implements Configurable {
private final Log log = LogFactory.getLog(this.getClass());
private final ClientExecChain execChain;
private final HttpClientConnectionManager connManager;
private final HttpRoutePlanner routePlanner;
private final Lookup<CookieSpecProvider> cookieSpecRegistry;
private final Lookup<AuthSchemeProvider> authSchemeRegistry;
private final CookieStore cookieStore;
private final CredentialsProvider credentialsProvider;
private final RequestConfig defaultConfig;
private final List<Closeable> closeables;
其中需要注意的有HttpClientConnectionManager、HttpRoutePlanner和RequestConfig。
(i)HttpClientConnectionManager
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1IpLOeMn-1582271452679)(C:\Users\user\Desktop\crawler\HttpClientConnectionManager.png)]
HttpClientConnectionManager,顾名思义,这是Http请求的管理者,该接口有两个实现类。
1.BasicHttpClientConnectionManager
public class BasicHttpClientConnectionManager implements HttpClientConnectionManager, Closeable {
private final Log log;
private final HttpClientConnectionOperator connectionOperator;//实际调度者
private final HttpConnectionFactory<HttpRoute, ManagedHttpClientConnection> connFactory;
private ManagedHttpClientConnection conn;//一个Connection
private HttpRoute route;//一个route
private Object state;
private long updated;
private long expiry;
private boolean leased;
private SocketConfig socketConfig;
private ConnectionConfig connConfig;
private final AtomicBoolean isShutdown;
synchronized HttpClientConnection getConnection(HttpRoute route, Object state) {
。。。
if (this.conn == null) {
//若连接为空,则由HttpConnectionFactory去新建一个连接
this.conn = (ManagedHttpClientConnection)this.connFactory.create(route, this.connConfig);
}
}
public synchronized void releaseConnection(HttpClientConnection conn, Object state, long keepalive, TimeUnit timeUnit) {
Args.notNull(conn, "Connection");
//判断是否是相同连接
Asserts.check(conn == this.conn, "Connection not obtained from this manager");
。。。
public void connect(HttpClientConnection conn, HttpRoute route, int connectTimeout, HttpContext context) throws IOException {
Args.notNull(conn, "Connection");
Args.notNull(route, "HTTP route");
Asserts.check(conn == this.conn, "Connection not obtained from this manager"); HttpHost host;
if (route.getProxyHost() != null) {
host = route.getProxyHost();
} else {
host = route.getTargetHost();
}
InetSocketAddress localAddress = route.getLocalSocketAddress();
//由HttpClientConnectionOperator调度去执行连接
this.connectionOperator.connect(this.conn, host, localAddress, connectTimeout, this.socketConfig, context);
BasicHttpClientConnectionManager每次只管理一个Connection。不过,虽然它是thread-safe的,但由于它只管理一个连接,所以只能被一个线程使用,由Operator去调度执行。它在管理连接的时候如果发现有相同route的请求,会复用之前已经创建的连接,如果新来的请求不能复用之前的连接,它会关闭现有的连接并重新打开它来响应新的请求。
HttpClientConnectionOperator只有一个实现类DefaultHttpClientConnectionOperator
public void connect(ManagedHttpClientConnection conn, HttpHost host, InetSocketAddress localAddress, int connectTimeout, SocketConfig socketConfig, HttpContext context) throws IOException {
Lookup<ConnectionSocketFactory> registry = this.getSocketFactoryRegistry(context);
ConnectionSocketFactory sf = (ConnectionSocketFactory)registry.lookup(host.getSchemeName());//从Context中获取SocketFactory,可以看到,根据Scheme(是否是Https)不一样会有不同
if (sf == null) {
throw new UnsupportedSchemeException(host.getSchemeName() + " protocol is not supported");
} else {
InetAddress[] addresses = host.getAddress() != null ? new InetAddress[]{host.getAddress()} : this.dnsResolver.resolve(host.getHostName());
int port = this.schemePortResolver.resolve(host);
for(int i = 0; i < addresses.length; ++i) {
InetAddress address = addresses[i];
boolean last = i == addresses.length - 1;
Socket sock = sf.createSocket(context);
sock.setSoTimeout(socketConfig.getSoTimeout());
sock.setReuseAddress(socketConfig.isSoReuseAddress());
sock.setTcpNoDelay(socketConfig.isTcpNoDelay());
sock.setKeepAlive(socketConfig.isSoKeepAlive());
if (socketConfig.getRcvBufSize() > 0) {
sock.setReceiveBufferSize(socketConfig.getRcvBufSize());
}
if (socketConfig.getSndBufSize() > 0) {
sock.setSendBufferSize(socketConfig.getSndBufSize());
}
int linger = socketConfig.getSoLinger();
if (linger >= 0) {
sock.setSoLinger(true, linger);
}
conn.bind(sock);
InetSocketAddress remoteAddress = new InetSocketAddress(address, port);
if (this.log.isDebugEnabled()) {
this.log.debug("Connecting to " + remoteAddress);
}
try {
sock = sf.connectSocket(connectTimeout, sock, host, remoteAddress, localAddress, context);
conn.bind(sock);//将Socket绑定到Connection
...
ConnectionOperator 是来处理Connection和Socket的关系,而HttpClientConnection是怎么来的呢?
HttpClientConnection继承自HttpConnection,HttpConnection由HttpConnectionFactory接口生成,
HttpConnectionFactory有一个实现类ManagedHttpClientConnectionFactory,它是来生成ManagedHttpClientConnection。
public ManagedHttpClientConnection create(HttpRoute route, ConnectionConfig config) {
ConnectionConfig cconfig = config != null ? config : ConnectionConfig.DEFAULT;
CharsetDecoder charDecoder = null;
CharsetEncoder charEncoder = null;
Charset charset = cconfig.getCharset();
CodingErrorAction malformedInputAction = cconfig.getMalformedInputAction() != null ? cconfig.getMalformedInputAction() : CodingErrorAction.REPORT;
CodingErrorAction unmappableInputAction = cconfig.getUnmappableInputAction() != null ? cconfig.getUnmappableInputAction() : CodingErrorAction.REPORT;
if (charset != null) {
charDecoder = charset.newDecoder();
charDecoder.onMalformedInput(malformedInputAction);
charDecoder.onUnmappableCharacter(unmappableInputAction);
charEncoder = charset.newEncoder();
charEncoder.onMalformedInput(malformedInputAction);
charEncoder.onUnmappableCharacter(unmappableInputAction);
}
String id = "http-outgoing-" + Long.toString(COUNTER.getAndIncrement());
return new LoggingManagedHttpClientConnection(id, this.log, this.headerLog, this.wireLog, cconfig.getBufferSize(), cconfig.getFragmentSizeHint(), charDecoder, charEncoder, cconfig.getMessageConstraints(), this.incomingContentStrategy, this.outgoingContentStrategy, this.requestWriterFactory, this.responseParserFactory);
}
2.PoolingHttpClientConnectionManager
public CPool(ConnFactory<HttpRoute, ManagedHttpClientConnection> connFactory, int defaultMaxPerRoute, int maxTotal, long timeToLive, TimeUnit timeUnit) {
super(connFactory, defaultMaxPerRoute, maxTotal);
this.timeToLive = timeToLive;
this.timeUnit = timeUnit;
}
public AbstractConnPool(ConnFactory<T, C> connFactory, int defaultMaxPerRoute, int maxTotal) {
this.connFactory = (ConnFactory)Args.notNull(connFactory, "Connection factory");
this.defaultMaxPerRoute = Args.positive(defaultMaxPerRoute, "Max per route value");
this.maxTotal = Args.positive(maxTotal, "Max total value");
this.lock = new ReentrantLock();
this.condition = this.lock.newCondition();
this.routeToPool = new HashMap();
this.leased = new HashSet();
this.available = new LinkedList();
this.pending = new LinkedList();
this.maxPerRoute = new HashMap();
}
对于PoolingHttpClientConnectionManager, 涉及到对象池化的概念。
在常用的Apache Commons Pool 中可以是这样定义的:
PoolableObjectFactory用于管理被池化的对象的产生、激活、挂起、校验和销毁;
ObjectPool用于管理要被池化的对象的借出和归还,并通知PoolableObjectFactory完成相应的工作;
我们来看看PoolingHttpClientConnectionManager是如何来定义对象池的。正常的Pool管理中有一个Factory,从代码中可以看出来,是InternalConnectionFactory。同时还有一个ObjectPool,在这里是CPool,但是它基本是个空的封装,继承自AbstractConnPool。 其实PoolingHttpClientConnectionManager看上去结构简单,也能做很多事情,但是最终还是落到了CPool上。而CPool又落到了AbstractConnPool上。
public PoolingHttpClientConnectionManager(HttpClientConnectionOperator httpClientConnectionOperator, HttpConnectionFactory<HttpRoute, ManagedHttpClientConnection> connFactory, long timeToLive, TimeUnit timeUnit) {
this.log = LogFactory.getLog(this.getClass());
this.configData = new PoolingHttpClientConnectionManager.ConfigData();
this.pool = new CPool(new PoolingHttpClientConnectionManager.InternalConnectionFactory(this.configData, connFactory), 2, 20, timeToLive, timeUnit);//默认连接池配置
this.pool.setValidateAfterInactivity(2000);
this.connectionOperator = (HttpClientConnectionOperator)Args.notNull(httpClientConnectionOperator, "HttpClientConnectionOperator");
this.isShutDown = new AtomicBoolean(false);
}
在PoolingHttpClientConnectionManager的配置中有两个最大连接数量,分别控制着总的最大连接数量和每个route的最大连接数量。如果没有显式设置,默认每个route只允许最多2个connection,总的connection数量不超过20。这个值对于很多并发度高的应用来说是不够的,必须根据实际的情况设置合适的值,思路和线程池的大小设置方式是类似的,如果所有的连接请求都是到同一个url,那可以把MaxPerRoute的值设置成和MaxTotal一致,这样就能更高效地复用连接。
更多参考HttpClient源码解析系列:第四篇:Connection是怎么生成和管理的
(ii)HttpRoutePlanner
HttpClient不仅支持简单的直连、复杂的路由策略以及代理。HttpRoutePlanner是基于http上下文情况下,客户端到服务器的路由计算策略,一般没有代理的话,就不用设置这个东西。这里有一个很关键的概念—Route:在HttpClient中,一个Route指运行环境机器->目标机器host的一条线路,也就是如果目标url的host是同一个,那么它们的route也是一样的。
(iii)RequestConfig
RequestConfig是对request的一些配置。里面比较重要的有三个超时时间,默认的情况下这三个超时时间都为0(如果不设置request的Config,会在execute的过程中使用HttpClientParamConfig的getRequestConfig中用默认参数进行设置),这也就意味着无限等待,很容易导致所有的请求阻塞在这个地方无限期等待。这三个超时时间为:
a、connectionRequestTimeout—从连接池中取连接的超时时间
这个时间定义的是从ConnectionManager管理的连接池中取出连接的超时时间, 如果连接池中没有可用的连接,则request会被阻塞,最长等待connectionRequestTimeout的时间,如果还没有被服务,则抛出ConnectionPoolTimeoutException异常,不继续等待。
b、connectTimeout—连接超时时间
这个时间定义了通过网络与服务器建立连接的超时时间,也就是取得了连接池中的某个连接之后到接通目标url的连接等待时间。发生超时,会抛出ConnectionTimeoutException异常。
c、socketTimeout—请求超时时间
这个时间定义了socket读数据的超时时间,也就是连接到服务器之后到从服务器获取响应数据需要等待的时间,或者说是连接上一个url之后到获取response的返回等待时间。发生超时,会抛出SocketTimeoutException异常。
(2)、创建一个Request对象
HttpClient支持所有的HTTP1.1中的所有定义的请求类型:GET、HEAD、POST、PUT、DELETE、TRACE和OPTIONS。对使用的类为HttpGet、HttpHead、HttpPost、HttpPut、HttpDelete、HttpTrace和HttpOptions。Request的对象建立很简单,一般用目标url来构造就好了。下面是一个HttpPost的创建代码:
HttpPost httpPost = new HttpPost(url);
一个Request还可以addHeader、setEntity、setConfig等,一般这三个用的比较多。
RequestConfig这个类比较关键,就是request的配置,除了上面说到的三个超时时间外,还有一些可能有助于理解处理过程的配置:
staleConnectionCheckEnabled:这个配置默认为true,HttpClient的execute方法中有下面的代码,也就是说如果这个设置为true的话,是会自动关闭那些状态为stale的managed connection所管理的connection和socket(和remote ip)
(3)、执行Request请求
执行Request请求就是调用HttpClient的execute方法。最简单的使用方法是调用execute(final HttpUriRequest request)。
HttpClient允许http连接在特定的Http上下文中执行,HttpContext是跟一个连接相关联的,所以它也只能属于一个线程,如果没有特别设定,在execute的过程中,HttpClient会自动为每一个connectionnew一个HttpClientHttpContext。
HttpClientContext localcontext = HttpClientContext.adapt(context!=null?context:newBasicHttpContext());
整个execute执行的常规流程为:
new一个http context
|
取出Request和URL
|
根据HttpRoute的配置看是否需要重写URL
|
根据URL的host、port和scheme设置target
|
在发送前用http协议拦截器处理request的各个部分
|
取得验证状态、user token来验证身份
|
从连接池中取一个可用的连接
|
根据request的各种配置参数以及取得的connection构造一个connManaged
|
打开managed的connection(包括创建route、dns解析、绑定socket、socket连接等)
|
请求数据(包括发送请求和接收response两个阶段)
|
查看keepAlive策略,判断连接是否要复用,并设置相应标识
|
返回response
|
用http协议拦截器处理response的各个部分
(3)、处理Response
HttpReaponse是将服务端发回的Http响应解析后的对象。CloseableHttpClient的execute方法返回的response都是CloseableHttpResponse类型。可以getFirstHeader(String)、getLastHeader(String)、headerIterator(String)取得某个Header name对应的迭代器、getAllHeaders()、getEntity、getStatus等,一般这几个方法比较常用。
在这个部分中,对于entity的处理需要特别注意一下。
一般来说一个response中的entity只能被使用一次,它是一个流,这个流被处理完就不再存在了。
先response.getEntity()再使用HttpEntity#getContent()来得到一个java.io.InputStream,然后再对内容进行相应的处理。
有一点非常重要,想要复用一个connection就必须要让它占有的系统资源得到正确释放。释放资源有两种方法:
a、关闭和entity相关的content stream
如果是使用outputStream就要保证整个entity都被write out,如果是inputStream,则再最后要记得调用inputStream.close()。或者使用EntityUtils.consume(entity)或EntityUtils.consumeQuietly(entity)来让entity被完全耗尽(后者不抛异常)来做这一工作。EntityUtils中有个toString方法也很方便的(调用这个方法最后也会自动把inputStream close掉的),不过只有在可以确定收到的entity不是特别大的情况下才能使用。
做过实验,如果没有让整个entity被fully consumed,则该连接是不能被复用的,很快就会因为在连接池中取不到可用的连接超时或者阻塞在这里(因为该连接的状态将会一直是leased的,即正在被使用的状态)。所以如果想要复用connection,一定一定要记得把entity fully consume掉,只要检测到stream的eof,是会自动调用ConnectionHolder的releaseConnection方法进行处理的(注意,ConnectionHolder并不是一个public class,虽然里面有一些跟释放连接相关的重要操作,但是却无法直接调用)。
b、关闭response
执行response.close()虽然会正确释放掉该connection占用的所有资源,但是这是一种比较暴力的方式,采用这种方式之后,这个connection就不能被重复使用了。
从源代码中可以看出,response.close()调用了connectionHolder的abortConnection方法,它会close底层的socket,并且release当前的connection,并把reuse的时间设为0。这种情况下的connection称为expired connection,也就是client端单方面把连接关闭。还要等待closeExpiredConnections方法将它从连接池中清除掉(从连接池中清除掉的含义是把它所对应的连接池的entry置为无效,并且关掉对应的connection,shutdown对应socket的输入和输出流。这个方法的调用时间是需要设置的)。
关闭stream和response的区别在于前者会尝试保持底层的连接alive,而后者会直接shut down并且丢弃connection。
socket是和ip以及port绑定的,但是host相同的请求会尽量复用连接池里已经存在的connection(因为在连接池里会另外维护一个route的子连接池,这个子连接池中每个connection的状态有三种:leased、available和pending,只有available状态的connection才能被使用,而fully consume entity就可以让该连接变为available状态),如果host地址一样,则优先使用该connection。
如果希望重复读取entity中的内容,就需要把entity缓存下来。最简单的方式是用entity来new一个BufferedHttpEntity,这一操作会把内容拷贝到内存中,之后使用这个BufferedHttpEntity就可以了。
(4)、关闭HttpClient
调用httpClient.close()会先shut down connection manager,然后再释放该HttpClient所占用的所有资源,关闭所有在使用或者空闲的connection包括底层socket。由于这里把它所使用的connection manager关闭了,所以在下次还要进行http请求的时候,要重新new一个connection manager来build一个HttpClient(也就是在需要关闭和新建Client的情况下,connection manager不能是单例的)。
简单的用HttpClient实现GET、POST等我就不演示了,大佬写好的例子百度一搜就有,直接套用就是了。
接下来,应该先是持久层开发。
2.配置文件读取
因为是一个简单的项目,没有用数据库,这里直接读取的是json配置文件的数据。
创建实体类Customer,然后配置好json文件再解析,这里我用的是fastjson解析
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.61</version>
</dependency>
{
"customers": [
{
"orgcode": "W702067",
"orgname": "青岛百洋医药股份有限公司",
"params": {
"user": "240",
"password": "Welcome103"
},
"website": "http://www.baheal.com/Flow/Home/Index",
"dailyTime": "0/30 * 19 * * ?",
"merge": false,
"status": true,
"type": "N",
"action": "cn.eli486.imp.Demo"
},
{
"orgcode": "W169027",
"orgname": "聚善堂(福建)医药集团有限公司",
"params": {
"txtadmin": "57",
"txtpwd": "1"
},
"website": "http://218.86.35.195:8008/default5.aspx",
"dailyTime": "0/20 * 19 * * ?",
"merge": false,
"status": true,
"type": "N",
"action": "cn.eli486.imp.Demo3"
}
]
}
//加载json获取定时任务
// File f = new File (this.getClass ().getResource ("/customer.json").getPath ());
ClassPathResource resource = new ClassPathResource ("customer.json");
StringBuilder builder =new StringBuilder ();
InputStreamReader inputStreamReader=new InputStreamReader (resource.getInputStream (),"utf-8");
BufferedReader bufferedReader=new BufferedReader (inputStreamReader);
String s = null;
while ((s=bufferedReader.readLine ())!=null) {
builder.append (s);
}
bufferedReader.close ();
JSONObject parse = JSON.parseObject (builder.toString ());
JSONArray customers = parse.getJSONArray ("customers");
String customersStr = customers.toJSONString ();
List<Customer> customersList = JSON.parseArray (customersStr, Customer.class);
this.mapCustomers = new HashMap<> ();
for (Customer customer : customersList
) {
this.mapCustomers.put (customer.getOrgcode (), customer);
}
这里解析配置文件要注意的是获取resources路径下文件,原来用this.getClass ().getResource ("/customer.json").getPath ()运行时总报找不到那个文件异常,查了之后才知道要用resource.getInputStream ()来获取。
3.查询数据处理
接下来应该算是业务层开发,我们要对查询到的数据进行保存处理。
因为是要保存到Excel中,所以导入操作Excel相应的jar包,主要是poi和jxl
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>4.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>4.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/net.sourceforge.jexcelapi/jxl -->
<dependency>
<groupId>net.sourceforge.jexcelapi</groupId>
<artifactId>jxl</artifactId>
<version>2.6.12</version>
<exclusions>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
</exclusions>
</dependency>
首先要考虑存储方式。原来是以数组的形式将每行数据保存起来,表头封装成一个对象或者存在是一个数组中,根据对象属性去填充各行的数据。但表头是不确定的,每次修改表头就要重写一个对象或者更换数组,那么怎样存储才便于插入和删除呢,这里我选择了双向链表。
public class Title<T>{
/**
* 内部构造节点类
*
* @param
*/
private class Node<T> {
private T data;
private Node<T> next; // 指向下一个节点的引用
private Node<T> prev; // 指向前一个节点的引用
public Node(T data) {
this.data = data;
}
}
/**
* 模拟头结点
*/
private Node<T> head;
/**
*模拟尾部节点
*/
private Node<T> last;
/**
* 暂定一个临时节点,用作指针节点
*/
private Node<T> other;
private int length;
/**
* 链表是否为空
*
* @return boolean
*/
public boolean isEmpty() {
return length == 0;
}
/**
* 普通添加,往链表尾部添加
*
* @param data
*/
public void append(T data) {
// 链表为空,新创建一个链表
if (isEmpty()) {
head = new Node<T>(data);
last = head;
length++;
} else {
other = new Node<T>(data);
other.prev = last;
// 将新的节点与原来的尾部节点进行结构上的关联
last.next = other;
// other将成为最后一个节点
last = other;
length++;
}
}
/**
* 在指定的数据后面添加数据
*
* @param data
* @param insertData
*/
public void addAfter(T data, T insertData) {
other = head;
// 我们假定这个head是不为空的。
while (other != null) {
if (other.data.equals(data)) {
Node<T> t = new Node<T>(insertData);
t.prev = other;
// 对新插入的数据进行一个指向的定义
t.next = other.next;
other.next = t;
if (t.next == null) {
last = t;
}
length++;
}
other = other.next;
}
}
/**
* 删除,删除指定的数据
*
* @param data
*/
public void remove(T data) {
// 我们假定这个head是不为空的。
other = head;
while (other != null) {
if (other.data.equals(data)) {
other.prev.next = other.next;
length--;
}
other = other.next;
}
}
/**
* 测试打印数据
*/
public void printList() {
other = head;
for (int i = 0; i < length; i++) {
System.out.print(other.data + " ");
other = other.next;
}
}
public int len() {
return length;
}
/**
* 以数组的形式返回节点数据
*/
public Object[] show() {
Object[] data = new String[length];
other = head;
for (int i = 0; i < length; i++) {
data[i]=other.data;
other = other.next;
}
return data;
}
/**
* 建立map
* 存储title的位置-表头名称
*/
public Map<Integer,String> local() {
Map<Integer, String> map = new HashMap<> ();
Object[] data = new String[length];
other = head;
int loc = 0;
for (int i = 0; i < length; i++) {
data[i]=other.data;
map.put(i, (String) data[i]);
other = other.next;
}
return map;
}
更多可以参考双向链表,当然肯定也有别的选择方案。
4.定时任务配置
因为无验证码的网站登录不会被拦截,只要传入用户名密码等参数就可以直接抓到数据,那么我们可以考虑将此做出定时任务去执行无需人工操作。
具体采用哪种可以自行决定spring boot 几种定时任务的实现方式
我这用的就是springboot自带的定时任务注解@Scheduled,主要实现参考spring定时任务实现动态定时任务(启停,周期修改)
public class DailyTask implements Runnable {
private String cron;
private String classname;
private Customer customer;
private boolean status;
public DailyTask (Customer customer) {
this.customer = customer;
this.classname = customer.getAction ();
this.cron = customer.getDailyTime ();
this.status = customer.isStatus ();
}
@Override
public void run () {
try {
ExcelDemo excelDemo = (ExcelDemo) Class.forName (classname).newInstance ();
excelDemo.setMerge (customer.isMerge ());
CloseableHttpClient client = WebUtil.getHttpClient ();
Set<String> strings = customer.getParams ().keySet ();
Iterator<String> iterator = strings.iterator ();
if(iterator.hasNext ()) {
String next = iterator.next ();
//区分多账号
if (next.contains ("@@")) {
String[] para1 = next.split ("@@");
String[] para2 = customer.getParams ().get (next).split ("@@");
for (int i = 0; i < para1.length; i++) {
Map<String, String> params = new HashMap<> ();
params.put (para1[i], para2[i]);
excelDemo.exec (client, params, customer.getOrgcode (), customer.getOrgname ());
}
} else {
Map<String, String> params = new HashMap<> ();
params.putAll (customer.getParams ());
excelDemo.exec (client, params, customer.getOrgcode (), customer.getOrgname ());
}
}
} catch (Exception e) {
e.printStackTrace ();
}
}
5.前端页面
前端主要是Thymeleaf搭建的,主要说一下验证码页面遇到的问题。
我是根据网站验证码图片地址,抓取保存到resources目录下
HttpGet get = new HttpGet (url);
try {
HttpResponse response = client.execute (get);
if (HttpStatus.SC_OK != response.getStatusLine ().getStatusCode ()) {
return;
}
HttpEntity entity = response.getEntity ();
if (entity == null) {
return;
}
File storeFile = new File (fileName);
FileOutputStream output = new FileOutputStream (storeFile);
entity.writeTo (output);
output.close ();
但在页面执行任务时,发现总是登录失败,debug看了是验证码错误,我每次点击生成验证码,得到的是上一次的验证码图片,只有刷新项目文件夹才生成新的,这是为什么呢。百度了半天,跟session缓存问题差不多,这是项目缓存的原因,我的问题这样解决了–>Springboot 上传图片到项目路径下不能访问,需要重启
@Configuration
public class ResourceConfigAdapter extends WebMvcConfigurerAdapter {
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
//获取文件的真实路径 work_project代表项目工程名 需要更改
String path = System.getProperty("user.dir")+"\\work_project\\src\\main\\resources\\static\\pciture\\";
String os = System.getProperty("os.name");
if (os.toLowerCase().startsWith("win")) {
registry.addResourceHandler("/picture/**").
addResourceLocations("file:"+path);
}else{//linux和mac系统 可以根据逻辑再做处理
registry.addResourceHandler("/picture/**").
addResourceLocations("file:"+path);
}
}
}
至此就算简单完成了这个web项目,当然还有很多不足,如果要爬取更多的网站,并发安全问题、缓存问题等都没细细考虑,前端页面也可以添加更多功能,如任务进度条、执行日志展示、对数据修改等,与数据库连接来搭建也不会太难。这里推荐另一个适合学习的博客搭建项目,SpringBoot开发博客系统,感兴趣可以试试,我先去学学。
记录问题:
在用iterator遍历HashMap集合时,出现异常concurrentmodificationexception
Set<String> strings = customer.getParams ().keySet ();
Iterator<String> iterator = strings.iterator ();
while (iterator.hasNext ()) {
String next = iterator.next ();
//以@@来分隔多账号
if (next.contains ("@@")) {
String[] para1 = next.split ("@@");
String[] para2 = customer.getParams ().get (next).split ("@@");
for (int i = 0; i < para1.length; i++) {
Map<String, String> params = new HashMap<> ();
params.put (para1[i], para2[i]);
excelDemo.exec (client, params, customer.getOrgcode (), customer.getOrgname ());
}
} else {
//这里要new一个新的map,要不然每个实例直接用登录参数进行修改页面展示也会变
Map<String, String> params = new HashMap<> ();
params.putAll (customer.getParams ());
//在子类中有修改Map中的值所以出现异常
excelDemo.exec (client, params, customer.getOrgcode (), customer.getOrgname ());
}
}
百度一下大多数是对集合list、map等进行了删改才出现异常,debug试了下,synchronized锁住方法块并没有解决问题,最后还是把customer的params存储类型换成ConcurrentHashMap才成功。
还有一个由于devtools导致的,就是同一个类转换报claacastexcepetion,这是由于devtools用连个不同的ClassLoader去加载而造成的。